







庖丁解牛
20世纪80年代初,一家神奇的公司在硅谷诞生了,它就是Sun Microsystems。这个名字与太阳无关,而是源自互联网的伊甸园—Stanford University Network的首字母。在不到30年的时间里,SUN公司创造了无数传世作品。其中,Java、Solaris和基于SPARC的服务器至今还闻名遐迩。后来,人们总结SUN公司衰落的原因时,有一条竟然是技术过剩。
Network File System(NFS)协议也是SUN公司设计的。顾名思义,NFS就是网络上的文件系统。它的应用场景如图1所示,NFS服务器提供了/code和/document两个共享目录,分别被挂载到多台客户端的本地目录上。当用户在这些本地目录读写文件时,实际是不知不觉地在NFS服务器上读写。

图1
NFS自1984年面世以来,已经流行30年。理论上它适用于任何操作系统,不过因为种种原因,一般只在Linux/UNIX环境中存在。我在很多数据中心见到过NFS应用,其中不乏通信、银行和电视台等大型机构。无论SUN的命运如何 多舛,NFS始终处乱不惊,这么多年来只出过3个版本,即1984年的NFSv2、1995年的NFSv3和2000年的NFSv4。目前,大多数NFS环境都还是NFSv3,本文介绍的也是这个版本。NFSv2还在极少数环境中运行(我只在日本见到过),可以想象这些环境有多老了。而NFSv4因为深受CIFS影响,实施过程相对复杂,所以普及速度较慢。
如何深入学习NFS协议呢?其实所有权威资料都可以在RFC 1813中找到,不过这些文档读起来就像面对一张冷冰冰的面孔,令人望而却步。《鸟哥的Linux私房菜》中对NFS的介绍虽称得上友好,但美中不足的是不够深入,出了问题也不知道如何排查。我曾经为此颇感苦恼,因为工作中碰到的NFS问题太多了,走投无路时就只能硬啃RFC—既然网络协议都那么复杂,我也不指望有捷径了。直到有一天偶然打开挂载时抓的包,才意识到Wireshark可以改变这一切:它使整个挂载过程一目了然,所有细节都一览无遗。分析完每个网络包,再回顾RFC 1813便完全不觉得陌生。
如果你对NFS有兴趣,不妨一起来分析这个网络包。在我的实验室中,NFS客户端和文件服务器的IP分别是10.32.106.159和10.32.106.62。我在运行挂载命令(mount)时抓了包,然后用 “portmap || mount || nfs”进行过滤(见图2)。
[root@shifm1 tmp]# mount 10.32.106.62:/code /tmp/code
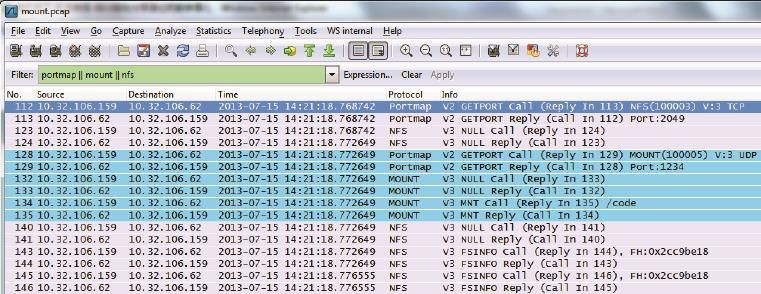
图2
从图2中的Info一栏可以看到,Wireshark已经提供了详细的解析。不过我们还可以翻译成更直白的对话(为了方便第一次接触NFS的读者,我还作了一些注释)。

图3
客户端:“我想连接你的NFS进程,应该用哪个端口呀?”
服务器:“我的NFS端口是2049。” (1)
包号123和124(见图4):

图4
客户端:“那我试一下NFS进程能否连上。”
服务器:“收到了,能连上。” (2)
包号128和129(见图5):

图5
客户端:“我想连接你的mount服务,应该用哪个端口呀?”
服务器:“我的mount的端口号是1234。” (3)
包号132和133(见图6):

图6
客户端:“那我试一下mount进程能否连上。”
服务器:“收到了,能连上。” (4)
包号134和135(见图7):
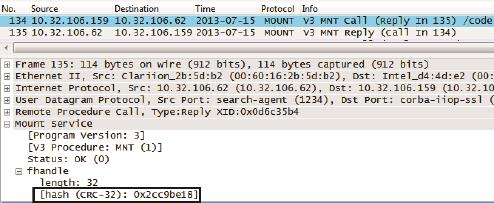
图7
客户端:“我要挂载/code共享目录。”
服务器:“你的请求被批准了。以后请用file handle 0x2cc9be18 来访问本目录。” (5)
包号140和141(见图8):

图8
服务器:“收到了,能连上。” (6)
包号143和144(见图9):

图9
客户端:“我想看看这个文件系统的属性。”
服务器:“给,都在这里。” (7)
包号145和146(见图10):

图10
以上便是NFS挂载的全过程。细节之处很多,所以在没有Wireshark的情况下很难排错,经常不得不盲目地检查每一个环节,比如先用rpcinfo命令获得服务器上的端口列表(见图11),再用Telnet命令逐个试探(见图12)。即使这样也只能检查几个关键进程能否连上,排查范围非常有限。
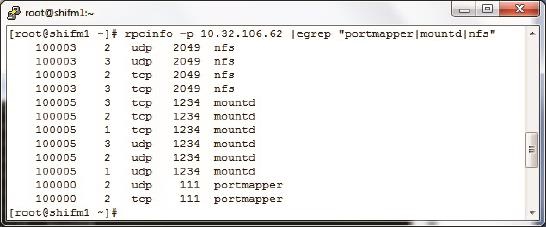
图11

图12
用上Wireshark之后就可以很有针对性地排查了。例如,看到portmap请求没有得到回复,就可以考虑防火墙对111端口的拦截;如果发现mount请求被服务器拒绝了,就应该检查该共享目录的访问控制。
既然说到访问控制,我们就来看看NFS在安全方面的机制,包括对客户端的访问控制和对用户的权限控制。
NFS对客户端的访问控制是通过IP地址实现的。创建共享目录时可以指定哪些IP允许读写,哪些IP只允许读,还有哪些IP连挂载都不允许。虽然配置不难,但这方面出的问题往往很“诡异”,没有Wireshark是几乎无法排查的。比如,我碰到过一台客户端的IP明明已经加到允许读写的列表里,结果却只能读。这个问题难住了很多工程师,因为在客户端和服务器上都找不到原因。后来我们在服务器上抓了个包,才知道在收到的包里,客户端的IP已经被NAT设备转换成别的了。
NFS的用户权限也经常让人困惑。比如在我的实验室中,客户端A上的用户admin在/code目录里新建一个文件,该文件的owner正常显示为admin。但是在客户端B上查看该文件时,owner却变成nasadmin,过程如下所示。

图13
客户端B(见图14):

图14
这是为什么呢?借助Wireshark,我们很容易就能看到原因。图15显示了用户admin在创建/tmp/code/abc.txt时的包。
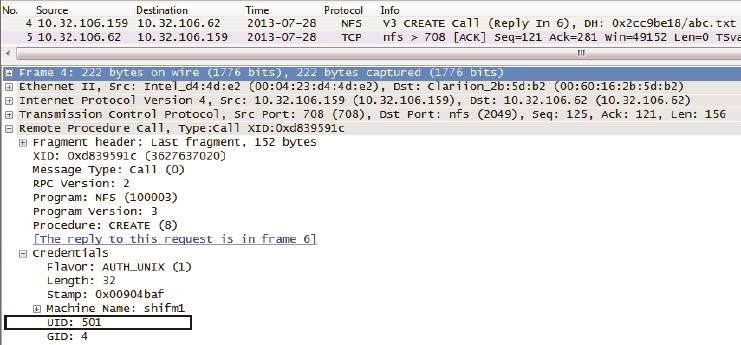
图15
由图15中的Credentials信息可知,用户在创建文件时并没有使用admin这个用户名,而是用了admin的UID 501来代表自己的身份(用户名与UID的对应关系是由客户端的/etc/passwd决定的)。也就是说NFS协议是只认UID不认用户名的。当admin通过客户端A创建了一个文件,其UID 501就会被写到文件里,成为owner信息。
而当客户端B上的用户查看该文件属性时,看到的其实也是“UID: 501”。但是因 为客户端B上的/etc/passwd文件和客户端A上的不一样,其UID 501对应的用户名叫nasadmin,所以文件的owner就显示为nasadmin了。同样道理,当客户端B上的用户nasadmin在共享目录上新建一个文件时,客户端A上的用户看到的文件owner就会变成admin。为了防止这类问题,建议用户名和UID的关系在每台客户端上都保持一致。
弄清楚了NFS的安全机制后,我们再来看看读写过程。经验丰富的工程师都知道,性能调优是最有技术含量的。借助Wireshark,我们可以看到NFS究竟是如何读写文件的,这样才能理解不同mount参数的作用,也才能有针对性地进行性能调优。图16展示了读取文件abc.txt的过程。
[root@shifm1 tmp]# cat /tmp/code/abc.txt
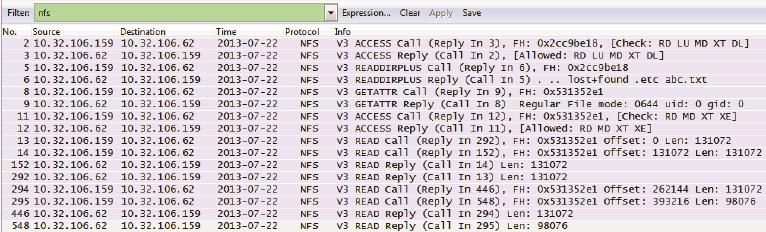
图16
包号2和3(见图17):

图17
客户端:“我可以进入0x2cc9be18(也就是/code的file handle)吗?”
服务器:“你的请求被接受了,进来吧。”
包号5和6(见图18):

图18
客户端:“我想看看这个目录里的文件及其file handle。”
服务器:“文件名及file handle的信息在这里。其中abc.txt的file handle是0x531352e1。” (9)
包号8和9(见图19):

图19
客户端:“0x531352e1(也就是abc.txt)的文件属性是什么?“
服务器:“权限、uid、gid, 文件大小等信息都给你。”包号11和12(见图20):

图20
客户端:“我可以打开0x531352e1(也就是abc.txt)吗?”
服务器:“你的请求被允许了。你有读、写、执行等权限。”包号13、14、152、292(见图21):

图21
客户端:“从0x531352e1的偏移量为0处(即从abc.txt的开头位置)读131072字节。”
客户端:“从0x531352e1的偏移量为131072处(即接着上一个请求读完的位置)再读131072字节。”
服务器:“给你131072字节。”
服务器:“再给你131072字节。”
(继续读,直到读完整个文件。)
就这样,NFS完成了文件的读取过程。从最后几个包可见,Linux客户端读NFS共享文件时是多个READ Call连续发出去的(本例中是连续两个)。这个方式跟Windows XP读CIFS共享文件有所不同。Windows XP不会连续发READ Call,而是先发一个Call,等收到Reply后再发下一个。相比之下,Linux这种读方式比Windows XP更高效,尤其是在高带宽、高延迟的环境下。这就像叫外卖一样,如果你今晚想吃鸡翅、汉堡和可乐三样食物,那合理的方式应该是打一通电话把三样都叫齐了。而不是先叫鸡翅,等鸡翅送到了再叫汉堡,等汉堡送到后再叫可乐。除了读文件的方式,每个READ Call请求多少数据也会影响性能。这台Linux默认每次读131072字节,我的实验室里还有默认每次读32768字节的客户端。在高性能环境中,要手动指定一个比较大的值。比如在我的Isilon实验室中,常常要调到512KB。这个值可以在mount时通过rsize参数来定义,比如“mount -o rsize=524288 10.32.106.62:/code /tmp/code”。
分析完读操作,接下来我们再看看写文件的过程。把一个名为abc.txt的文件写到NFS共享的过程如下(见图22)。
[root@shifm1tmp]# cp abc.txt code/abc.txt
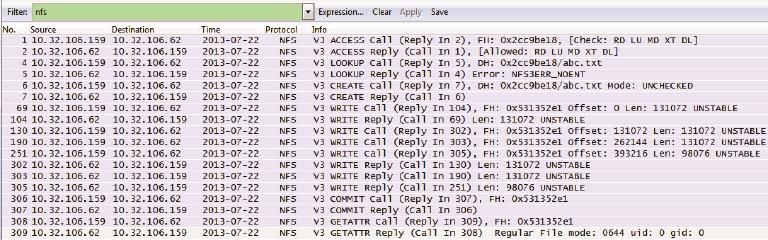
图22

图23
客户端:“我可以进入0x2cc9be18(即/code目录)吗?”服务器:“你的请求被接受了,进来吧。”
包号4和5(见图24):

图24
客户端:“请问这里有叫abc.txt的文件么?”
服务器:“没有。” (10)
包号6和7(见图25):

图25
客户端:“那我想创建一个叫abc.txt的文件。”
服务器:“没问题,这个文件的file handle是0x531352e1。”
包号64、104、130、190(见图26):

图26
客户端:“从0x531352e1的偏移量为0处(即abc.txt的文件开头)写131072字节。”
服务器:“第一个131072字节写好了。”
客户端:“从0x531352e1的偏移量为131072处(即接着上一个写完的位置)再写131072字节。”
客户端:“从0x531352e1的偏移量为262144处(即接着上一个写完的位置)再写131072字节。”
(继续写,直到写完整个文件。)
包号306和307(见图27):

图27
客户端:“我刚才往0x531352e1(也就是abc.txt)写的数据都存盘了吗?”
服务器:“都存好了。” (11)
包号308和309(见图28):

图28
客户端:“那我看看0x531352e1(也就是abc.txt)的文件属性。”
服务器:“文件的权限、uid、gid、文件大小等信息都给你。”
这个例子的写操作也是多个WRITE Call连续发出去的,这是因为我们在挂载时没有指定任何参数,所以使用了默认的async写方式。和async相对应的是sync方式。假如mount时使用了sync参数(见图29),客户端会先发送一个WRITE Call,等收到Reply后再发下一个Call,也就是说WRITE Call和WRITE Reply是交替出现的。除此之外,还有什么办法在包里看出一个写操作是async还是sync呢?答案就是每个WRITE Call上的“UNSTABLE”和“FILE_SYNC”标志,前者表示async,后者表示sync。图30显示了用sync参数后的网络包。

图29
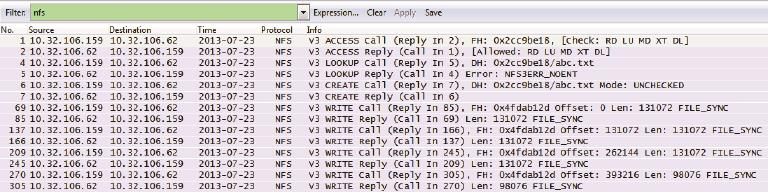
图30
从图30中不仅可以看到FILE_SYNC标志,还可以看到WRITE Call和WRITE Reply是交替出现的(也就是说没有连续的Call)。不难想象,每个WRITE Call写多少数据也是影响写性能的重要因素,我们可以在mount时用wsize参数来指定每次应该写多少。不过在有些客户端上启用sync 参数之后,无论wsize定义成多少都会被强制为4KB,从而导致写性能非常差。那为什么还有人用sync方式呢?答案是有些特殊的应用要求服务器收到sync的写请求之后,一定要等到存盘才能回复WRITE Reply,sync操作正符合了这个需求。由此我们也可以推出COMMIT对于sync写操作是没有必要的。
非常值得一提的是,经常有人在mount时使用noac参数,然后发现读写性能都有问题。而根据RFC的说明,noac只是让客户端不缓存文件属性而已,为什么会影响性能呢?光看文档也许永远发现不了原因。抓个包吧,Wireshark会告诉我们答案。

图31
在图32中,从Write Call里的FILE_SYNC可以知道,虽然在mount时并没有指定sync参数,但是noac把写操作强制变成sync方式了,性能自然也会下降。
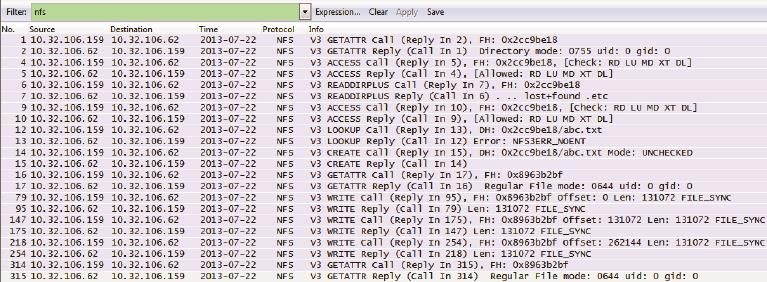
图32
再看读文件时的情况(见图33):
[root@shifm1 tmp]# mount -o noac 10.32.106.62:/code /tmp/code
[root@shifm1 tmp]# cat /tmp/code/abc.txt
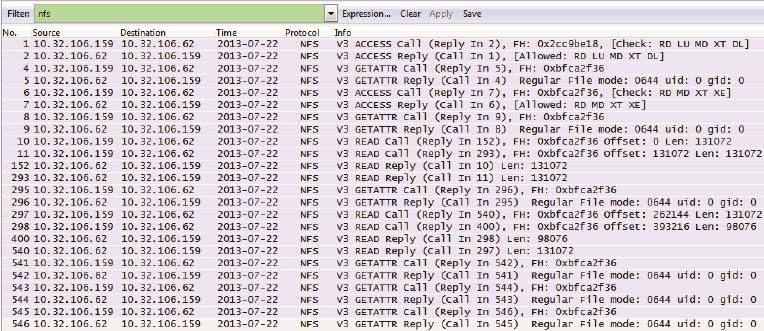
图33
从图33中可以看到,在读文件过程中,客户端频繁地通过GETATTR查询文件属性,所以读性能也受到了影响,在高延迟的网络中影响尤为明显。
纵观全文,我们分析了挂载过程的每个步骤,理清了NFS的安全机制,还研究了读写过程的各种细节,几乎把NFS协议的方方面面都覆盖了。如果你认真读完本文,可以说对NFS的理解已经达到很高的境界,以后碰到类似noac这般隐蔽的问题也难不倒你。假如真能遇到棘手的难题,我建议用Wireshark分析。一旦用它解决了第一个问题,恭喜你,很快就会中毒上瘾的。中毒之后会有什么症状呢?你可能碰到什么问题都想抓个包分析,就像小时候刚学会骑车一样,到小区门口打个酱油都要骑车去。
从Wireshark看网络分层
对于刚上网络课的学生来说,最难理解的莫过于网络分层了。
“只不过是传输一些数据,为什么要分那么多层次呢?”这是大学里一直困扰我的问题。虽然课本在此处花费了不少笔墨,但还是过于抽象,我始终无法想像一个网络包里的层次究竟是什么样子。这对一名网络工程师来说是不可接受的,就像连器官都分不清楚的医生,谁能放心让他做手术呢?幸好后来遇到Wireshark,才算解开了这个疑问。
前文已经介绍过NFS协议,我们便以它为例来学习网络分层。图1是客户端10.32.106.159往服务器10.32.106.62上写文件时抓的网络包。
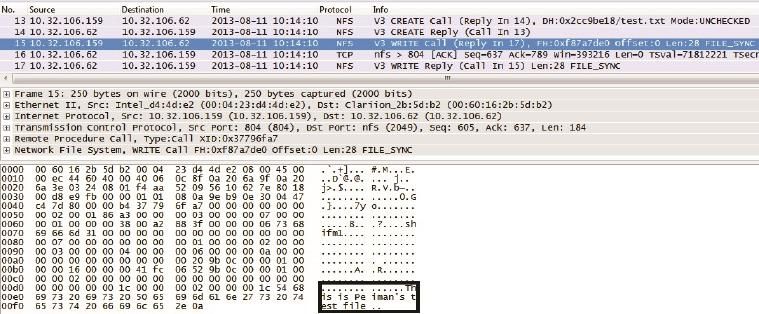
图1
这5个包大概做了下面这些事。
客户端:“我想创建test.txt。”
服务器:“创建成功啦(该文件的file handle是0xf87a7de0,点开包才能看到)。”
客户端:“我想写28个字节到该文件里(这些字节显示在图1的右下角)。”
服务器:“收到啦。”
服务器:“写好啦。”
其中第3个包(编号为15)的详情如图2所示。Wireshark已经形象地把这个包的内容用分层的结构显示出来。
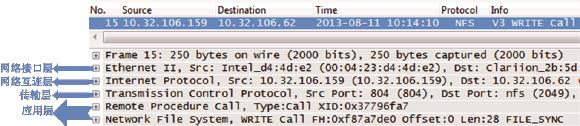
图2
• 应用层:由于NFS是基于RPC的协议,所以Wireshark把它分成NFS和RPC两行来显示。仔细检查这一层的详细信息,会发现它只专注于文件操作,比如读或者写,而对于数据传输一无所知。点开“+”号便能看到这个写操作的详情,比如用户的UID、文件的file handle和要写的字节数等。
• 传输层:这一层用到了TCP 协议。应用层所产生的数据就是由TCP来控制传输的。点开TCP层前的“+”号,我们可以看到Seq号和Ack号等一系列信息,它们用于网络包的排序、重传、流量控制等。虽然名曰“传输层”,但它并不是把网络包从一个设备传到另一个,而只是对传输行为进行控制。真正负责设备间传输的是下面两层。TCP是非常有用的协议,也是本书的重点。
• 网络互连层(网络层):在这个包中,本层的主要任务是把TCP层传下来的数据加上目标地址和源地址。有了目标地址,数据才可能送达接收方;而有了源地址,接收方才知道发送方是谁。
• 网络接口层(数据链路层):从中可以看到相邻两个设备的MAC地址,因此该网络包才能以接力的方式送达目标地址。
从这个例子中,我们可以看到网络分层就像是有序的分工。每一层都有自己 的责任范围,上层协议完成工作后就交给下一层,最终形成一个完整的网络包。这个过程可以用图3表示。
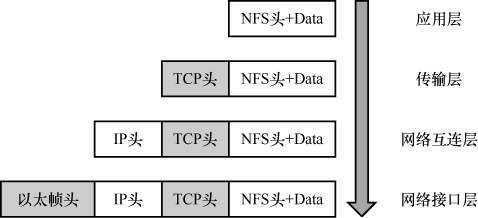
图3
现在回想起来,如果当时老师能打开Wireshark,让我们看到这些实实在在的分层,我也不会困惑那么久了(假如那天我没有逃课的话)。不过教科书上有一个例子,倒的确是很有助于理解分层的,这么多年之后我还记得它—有位经理想给另一个城市的经理寄个文件,过程大概如图4所示。
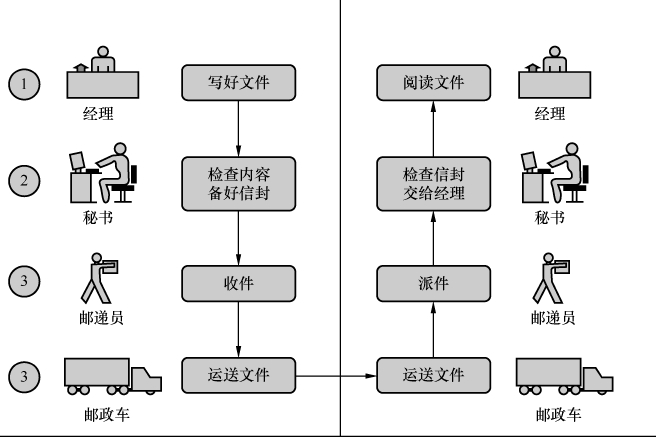
图4
这个场景中的4个角色可以对应网络的4个层次,每个角色都有自己的分工,最终完成文件的送达。分工会带来很多好处,因为每个人都可以专注自己擅长的领域,更好地服务他人。经理不一定要学会开车,就像写NFS代码的程序员可以 完全不懂路由协议。秘书可以服务多名经理,正如TCP层可以支持很多应用层协议。
如果让邮递员包揽秘书的工作,是否也可以呢?说不定也能做到,虽然听上去很滑稽。历史上还真存在过这种情况—TCP和IP刚发明的时候就是合在一层的,后来才拆成两层。那么,如果在经理和秘书之间加个助理,专门负责检查错别字,会有问题吗?与很多官僚作风严重的机构一样,多盖一个章就要多花一些时间。还记得20世纪那场OSI七层模型与TCP/IP模型的竞争吗?最终胜出的就是分层更简单的TCP/IP模型。要知道网络分层的目的并不仅仅是完成任务,而是要用最好的方式来完成。
理解了分层的基本概念,我们再来看看复杂一点的情况。如果这个写操作比较大, 变成8192字节,TCP层又该如何处理?是否也是简单地加上TCP头就交给网络互连层(网络层)呢?答案是否定的。因为网络对包的大小是有限制的,其最大值称为MTU,即“最大传输单元”。大多数网络的MTU是1500字节,但也有些网络启用了巨帧(Jumbo Frame),能达到9000字节。一个8192字节的包进入巨帧网络不会有问题,但到了1500字节的网络中就会被丢弃或者切分。被丢弃意味着传输彻底失败,因为重传的包还会再一次被丢弃。而被切分则意味着传输效率降低。
由于这个原因,TCP不想简单地把8192 字节的数据一口气传给网络互连层,而是根据双方的MTU决定每次传多少。知道自己的MTU容易,但对方的MTU如何获得呢?如图5所示,在TCP连接建立(三次握手)时,双方都会把自己的MSS(Maximum Segment Size)告诉对方。MSS加上TCP头和IP头的长度,就得到MTU了。

图5
在第一个包里,客户端声明自己的MSS是8960,意味着它的MTU就是8960+20(TCP头)+20(IP头)=9000。在第二个包里,服务器声明自己的MSS 是1460,意味着它的MTU就是1460+20+20=1500。图6是TCP连接建立之后的写操作,我们来看看究竟是哪个MTU起了作用。
客户端在包号46创建了abc.txt,然后通过48、49、51、52、54和55共6个包完成了这个8192字节的写操作。这些包的大小符合接收方的MTU 1500字节(见图6中划线的Total Length: 1500),而不是发送方本身支持的9000字节。也就是说,接收方的MTU起了决定作用。
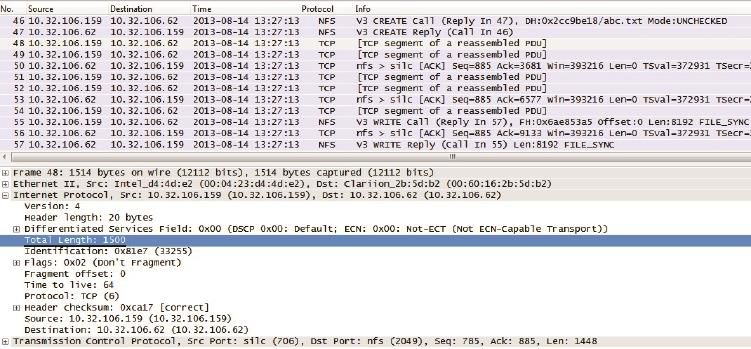
图6
假如把客户端和服务器的MTU互换一下,这时客户端最大能发出多少字节的包呢?答案还是1500。因为无论接受方的MTU有多大,发送方都不能发出超过自己MTU的包。我们可以得到这样的结论:发包的大小是由MTU较小的一方决定的。
这个例子告诉我们,分层之间的关系还不仅是分工。某些分层的协议,比如TCP,甚至会主动为下一层着想,从而避免很多问题。当然这个方案还不算完美。如果网络路径上存在着一个MTU小于1500的设备,这个包还是可能被丢弃或者切分。正如Wikipedia所说,“There is no simple method to discover the MTU of links”。
一个分层的概念就写了这么多,你或许早就开始纳闷:为什么网络要设计得如此复杂?又是分层又是分组的。其实当我被各种难题搞得焦头烂额的时候,也有过这个想法,但无奈这就是现实—假如没有这么复杂的设计,网络就不会如此强大,也达不到今天的规模。从另一个角度考虑,正是复杂的设计才让我们有了这份工作,感谢祖师爷们赐饭。
TCP的连接启蒙
听说现在的年青人可以用手机摇到妹子,可惜在我们那个年代,手机的主要功能只有两个—电话和短信。人们凭直觉决定该打电话还是发短信,却很少去深究这两者的本质差别。
打电话时要先拨号,等接通之后才开始讲话。如果有人还没拨号就对着电话自言自语,旁人一定会觉得很诡异。而发短信时根本不用考虑对方在干嘛,直接发出去就是了。这两种方式的本质差别就是,打电话时要先“建立连接”(即拨号),而短信不需要。建立连接需要花费一些时间,但也意味着更加可靠。我们可以在电话上确保对方已经听明白。而短信就不行了,发送之后并不知道对方是否及时收到,也不知道有没有产生误解。有一个笑话这样调侃短信所引发的事故—出差的丈夫一大早就给妻子发了条短信“I had a wonderful night, and really wish you were here”。不幸的是,他少打了最后一个“e”,这个误会估计需要一个面对面的连接才能化解。
网络的传输层和手机一样用于传递信息。它也有两种方式—TCP和UDP,其中TCP是基于连接的,而UDP不需要连接。它们各自支持一些应用层协议,但也有些协议是两者都支持的,比如DNS。我们正好可以用DNS来比较TCP和UDP的差别。在我的实验室中,客户端10.32.106.159向DNS服务器10.32.106.103发起一个DNS查询,以期获得paddy_cifs.nas.com所对应的IP地址。
1.DNS默认使用UDP的情况下(见图1):

图1

图2
2.用set vc强制DNS使用TCP的情况下(见图3):

图3
这个过程的所有网络包如图4所示:

图4
从这两种情况的截图可以看到,真正起查询作用的只有两个DNS包。
客户端:“paddy_cifs.nas.com的IP是多少啊?”
服务器:“是10.32.106.77。”
在使用UDP的情况下,的确只用这两个包就完成了DNS查询。但在使用TCP时,要先用3个包(包号1、2、3)来建立连接。查询结束后,又用了4个包(包号7、8、9、10)来断开连接。Wireshark把这两种情况的差别完全显示出来了。我们可以从中看到连接的成本远远超过DNS查询本身,这对繁忙的DNS服务器 来说无疑是巨大的压力。如果你的DNS还在使用TCP,该考虑更改了。
连接当然要付出代价,但带来的好处也很多,这就是为什么多数应用层协议还是基于TCP的原因。在以后的章节里,你将从Wireshark看到TCP的巨大优势,不过在此之前,一定要理解TCP的工作原理。Wireshark上能看到很多TCP参数,理解了它们就是学习TCP最好的开始。图5是10.32.106.159往10.32.106.62传数据的过程。我已经把一些参数用黑框标志出来,以便阅读时参照。

图5
Seq:表示该数据段的序号,如图5中的Seq=3681。
TCP提供有序的传输,所以每个数据段都要标上一个序号。当接收方收到乱序的包时,有了这个序号就可以重新排序了。我们不一定要知道Seq号的起始值是怎么算出来的,但必须理解它的增长方式。如图6所示,数据段1的起始Seq号为1,长度为1448(意味着它包含了1448个字符),那么数据段2的Seq号就为1+1448=1449。数据段2的长度也是1448,所以数据段3的Seq号为1449+1448=2897。也就是说,一个Seq号的大小是根据上一个数据段的Seq号和长度相加而来的。

图6
图5的Wireshark截屏也显示了相同的情况,51号包的Seq=3681,Len=1448,所以52号包的Seq=3681+1448=5129。这个Seq号是由这两个包的发送方,也就是10.32.106.159维护的。
由于TCP是双向的,在一个连接中双方都可以是发送方,所以各自维护了一个Seq号。53号包和56号包的Seq号是10.32.106.62维护的,由于53号包的Seq=885,Len=0,所以56号包的Seq=885+0=885。
Len:该数据段的长度,如图5中的Len=1448,注意这个长度不包括TCP头。图5中虽然10.32.106.62发出的两个包Len=0,但其实是有TCP头的。头部本身携带的信息很多,所以不要以为Len=0就没意义。
Ack:确认号,如图5中的Ack=6577,接收方向发送方确认已经收到了哪些字节。
比如甲发送了“Seq: x Len: y”的数据段给乙,那乙回复的确认号就是x+y,这意味着它收到了x+y之前的所有字节。同样以图5为例,52号包的Seq=5129, Len=1448,所以来自接收方的53号包的Ack=5129+1448=6577,表示收到了6577之前的所有字节。理论上,接收方回复的Ack号恰好就等于发送方的下一个Seq号,所以我们可以看到54号包的Seq也等于5129+1448=6577。
你也许想问51号包为什么没有对应的确认包呢?其实53号包确认6577的时候,表示序号小于6577的所有字节都收到了,相当于把51号发送的字节也一并确认了,也就是说TCP的确认是可以累积的。
在一个TCP连接中,因为双方都可以是接收方,所以它们各自维护自己的Ack号。本例中10.32.106.62没有发送任何字节,所以10.32.106.159发出的Ack号一直不变。
你可能要花些心思来学习这几个参数,不过付出是值得的。因为一旦理解了它们,接下来学习TCP的特性就会水到渠成。比如当包乱序时,接收方只要根据Seq号从小到大重新排好就行了,这样就保证了TCP的有序性。再比如有包丢失时,接收方通过前一个Seq+Len的值与下一个Seq的差,就能判断缺了哪些包,这保证了TCP的可靠性。我们举个例子来说明这两种状况,以下3个包到达了接收方(见表1):
表1
| 第一个包 | 第二个包 | 第三个包 |
| Seq:301 Len:100 | Seq:101 Len:100 | Seq:401 Len:100 |
很明显,从Seq号可见它们的顺序是乱的。重新排序之后应该是下面这个样 子(见表2):
表2
| Seq:101 Len:100 | Seq:301 Len:100 | Seq:401 Len:100 |
排序完之后还是有问题。第一个包的Seq+Len=101+100=201,意味着下一个包本应该是Seq:201,而不是实际收到的Seq:301。由此接收方可以推断,“Seq:201”这个包可能已经丢失了。于是它回复Ack:201给发送方,提醒它重传Seq:201。
除了这几个参数,TCP头还附带了很多标志位,在Wireshark上经常可以看到下面这些。
• SYN:携带这个标志的包表示正在发起连接请求。因为连接是双向的,所以建立连接时,双方都要发一个SYN。
• FIN:携带这个标志的包表示正在请求终止连接。因为连接是双向的,所以彻底关闭一个连接时,双方都要发一个FIN。
• RST:用于重置一个混乱的连接,或者拒绝一个无效的请求。
如图7所示,我故意尝试连接一台Linux服务器的445端口(一般只有Windows上才开启这个端口,Wireshark上把该端口显示为microsoft-ds),结果就被RST了。当然这个实验属于“没事找抽型”,实际环境中的RST往往意味着大问题。如果你在Wireshark中看到一个RST包,务必睁大眼睛好好检查。

图7
了解了这些参数和标志位,我们就可以学习TCP是如何管理连接的了。图8是一个标准的连接建立过程:

图8
这三个包就是传说中的“三次握手”。事实上,握手时Seq号并不是从0开始的。我们之所以在Wireshark上看到Seq=0,是因为Wireshark启用了Relative Sequence Number。如果你想关闭这个功能,可以在Edit-->Preferences-->protocols-->TCP里设置。
握手过程可以用图9来表示。
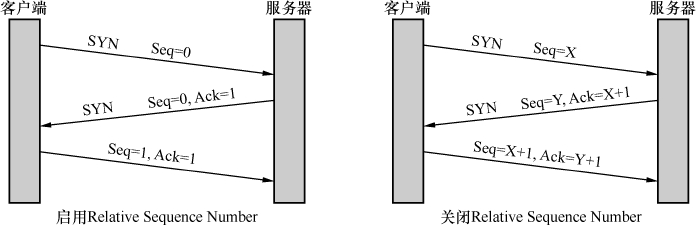
图9
如果用文字来表达,过程就是这样的。
客户端:“我能跟你建立连接吗?我的初始发送序号是X。如果你答应就Ack=X+1。”
服务器:“收到啦,Ack=X+1。我也想跟你建立连接。我的初始发送序号是Y,你如果答应连接就Ack=Y+1。”
客户端:“收到啦,Ack=Y+1。”
为什么要用三个包来建立连接呢,用两个不可以吗?其实也是可以的,但两个不够可靠。我们可以设想一个情况来说明这个问题:某个网络有多条路径,客户端请求建立连接的第一个包跑到一条延迟严重的路径上了,所以迟迟没有到达服务器。因此,客户端只能当作这个请求丢失了,不得不再请求一次。由于第二个请求走了正确的路径,所以很快完成工作并关闭了连接。对于客户端来说,事情似乎已经结束了。没想到它的第一个请求经过跋山涉水,还是到达了服务器。如图10所示,服务器并不知道这是一个旧的无效请求,所以按照惯例回复了。假如TCP只要求两次握手,服务器上就这样建立了一个无效的连接。而在三次握手的机制下,客户端收到服务器的回复时,知道这个连接不是它想要的,所以就发 一个拒绝包。服务器收到这个包后,也放弃这个连接。
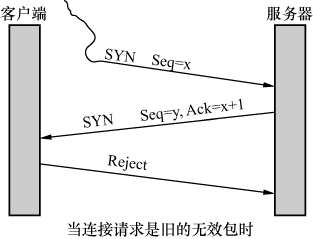
图10
经过三次握手之后,连接就建立了。双方可以利用Seq、Ack和Len等参数互传数据。传完之后如何断开连接呢?图11就是TCP断开连接的“四次挥手”过程。

图11
客户端:“我希望断开连接(请注意FIN标志)。”
服务器:“知道了,断开吧。”
服务器:“我这边的连接也想断开(请注意FIN标志)。”客户端:“知道了,断开吧。”
就这样,双方都关闭了连接。其实用四次挥手来断开连接也不完全可靠,但世界上不存在100%可靠的通信机制。假如对这个话题感兴趣,可以研究一下著名的“两军问题”,维基百科上有详细介绍,地址为http://en.wikipedia.org/wiki/ Two_Generals'_ Problem。
工作中如果碰到断开连接的问题,可以使用netstat命令来排查,无论在Windows还是Linux上,这个命令都能把当前的连接状态显示出来。不过老话常说,最推荐的工具还是Wireshark。
快递员的工作策略——TCP窗口
假如你是一位勤劳的快递员,要送100个包裹到某公司去,怎样送货才科学?
最简单的方式是每次送1个,总共跑100趟。当然这也是最慢的方式,因为往返次数越多,消耗的时间就越长。除了需要减肥的快递员,一般人不会选择这种方式。最快的方式应该是一口气送100个,这样只要跑一趟就够了。可惜现实没有这么美好,往往存在各种制约因素:公司狭小的前台只容得下20个包裹,要等签收完了才能接着送;更令人郁闷的是,电瓶车只能装10个包裹。综合这两个因素,不难推出电瓶车的运力是效率瓶颈,而前台的空间则不构成影响。
快递送货的策略非常浅显,几乎人人可以理解,而TCP传输大块数据的策略却很少人懂。事实上这两者的原理是相似的。
TCP显然不用电瓶车送包,但它也有“往返”的需要。因为发包之后并不知道对方能否收到,要一直等到确认包到达,这样就花费了一个往返时间。假如每发一个包就停下来等确认,一个往返时间里就只能传一个包,这样的传输效率太低了。最快的方式应该是一口气把所有包发出去,然后一起确认。但现实中也存在一些限制:接收方的缓存(接收窗口)可能一下子接受不了这么多数据;网络的带宽也不一定足够大,一口气发太多会导致丢包事故。所以,发送方要知道接收方的接收窗口和网络这两个限制因素中哪一个更严格,然后在其限制范围内尽可能多发包。这个一口气能发送的数据量就是传说中的TCP发送窗口。
发送窗口对性能的影响有多大?一图胜千言,图1显示了发送窗口为1个MSS(即每个TCP包所能携带的最大数据量)和2个MSS时的差别。在相同的往返时间里,右边比左边多发了两倍的数据量。而在真实环境中,发送窗口常常可以达到数十个MSS。
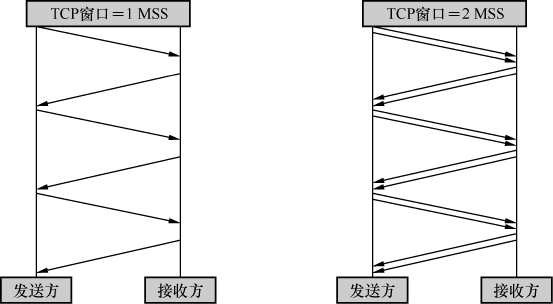
图1
图2就是在真实环境中抓的包,抓包时服务器10.32.106.73正往客户端10.32.106.103发数据。由于服务器的发送窗口很大,所以收到读请求之后,它在没有客户端确认的情况下连续发了10个包。
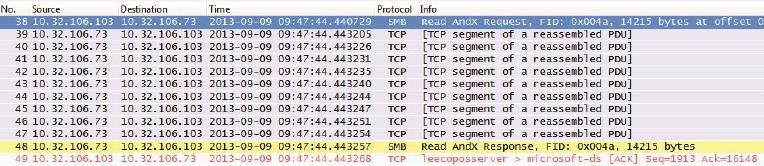
图2
接着我把客户端的接收窗口强制成2920,相当于两个TCP包能携带的数据量。从图3中可以看到客户端通过“win=2920”把自己的接收窗口告诉服务器。因此服务器把发送窗口限制为2920,每发两个包就停下来等待客户端的确认。同样一个14215字节的读操作,图2只用1个往返时间就完成了,而图3则用了6个。
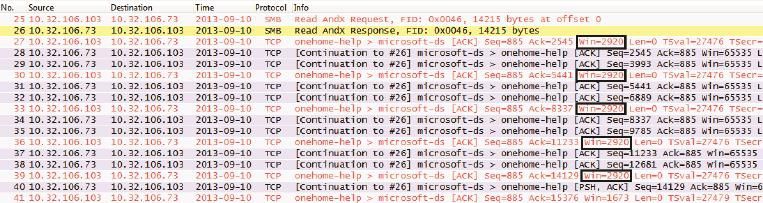
图3
为了更好地说明这个过程,我把27号包到32号包用对话的形式表示出来,括号内的文字为我添加的注释。
27号包:
客户端:“当前我的接收窗口是2920。”
28号包:
服务器:“(好,那我的发送窗口就定为2920。)先给你1460字节。”
29号包:
服务器:“再给你1460字节。(哎呀!我的发送窗口2920用完了,不能再发了。)”30号包:
客户端:“你发过来的2920字节已经处理完毕,所以现在我的接收窗口又恢复到2920。”
31号包:
服务器:“(好,那我再把发送窗口定为2920。)给你一个1460字节。”
32号包:
服务器:“再给你1460字节。(哎呀!我的发送窗口2920又用完了,不能再发了。)”
你也许有个疑问,本文的开头不是说有两个限制因素吗?这个例子只提到了接收窗口对发送窗口的限制,那网络的影响呢?由于网络的影响方式非常复杂,所以本文暂时跳过。下一篇文章将作详细介绍。
不知道出于何种原因,TCP发送窗口的概念被广泛误解,比如,很多人会把接收窗口误认为发送窗口。我经常想在论坛上回答相关提问,却不知道该从何答起,因为有些提问本身就基于错误的概念。下面是一些经常出现的问题。
1.如图4的底部所示,每个包的TCP层都含有“window size:”(也就是win=)的信息。这个值表示发送窗口的大小吗?
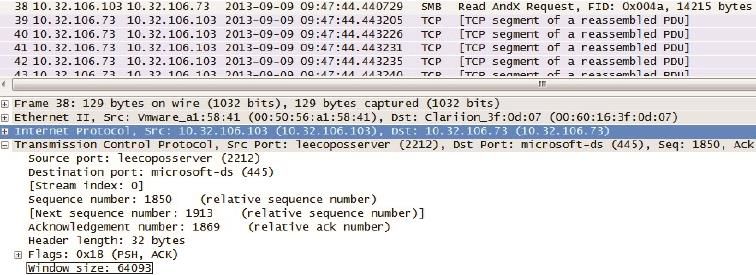
图4
这不是发送窗口,而是在向对方声明自己的接收窗口。在此例子中,10.32.106.103向10.32.106.73声明自己的接收窗口是64093字节。10.32.106.73收到之后,就会把自己的发送窗口限制在64093字节之内。很多教科书上提到的滑动窗口机制,说的就是这两个窗口的关系,本文就不再赘述了。
假如接收方处理数据的速度跟不上接收数据的速度,缓存就会被占满,从而导致接收窗口为0。如图5的Wireshark截屏所示,89.0.0.85持续向89.0.0.210声明自己的接收窗口是win=0,所以89.0.0.210的发送窗口就被限制为0,意味着那段时间发不出数据。

图5
2.我如何在包里看出发送窗口的大小呢?
很遗憾,没有简单的方法,有时候甚至完全没有办法。因为,当发送窗口是由接收窗口决定的时候,我们还可以通过“window size:”的值来判断。而当它由网络因素决定的时候,事情就会变得非常复杂(下篇文章将会详细介绍)。大多数 时候,我们甚至不确定哪个因素在起作用,只能大概推理。以图5为例,接收方声明它的接收窗口等于0,那接收窗口肯定起了限制作用(因为不可能再小了),因此可以大胆地判断发送窗口就是0。再回顾本文开头10.32.106.73向10.32.106.103传数据的两个例子。第一个例子中,我们只能推理出10.32.106.73的发送窗口不小于那10个包(39~48号)携带的数据总和,但具体能达到多少却不得而知,因为窗口还没用完时读操作就完成了。第二个例子比较容易分析,因为传了两个包就停下来等确认,所以发送窗口是那两个包携带的数据量2920。
3.发送窗口和MSS有什么关系?
发送窗口决定了一口气能发多少字节,而MSS决定了这些字节要分多少个包发完。举个例子,在发送窗口为16000字节的情况下,如果MSS是1000字节,那就需要发送16000/1000=16个包;而如果MSS等于8000,那要发送的包数就是16000/8000=2了。
4.发送方在一个窗口里发出n个包,是不是就能收到n个确认包?
不一定,确认包一般会少一些。由于TCP可以累积起来确认,所以当收到多个包的时候,只需要确认最后一个就可以了。比如本文中10.32.106.73向10.32.106.103传数据的第一个例子中,客户端用一个包(包号49)确认了它收到的10个包(39~48号包)。
5.经常听说“TCP Window Scale”这个概念,它究竟和接收窗口有何关系?
在TCP刚被发明的时候,全世界的网络带宽都很小,所以最大接收窗口被定义成65535字节。随着硬件的革命性进步,65535字节已经成为性能瓶颈了,怎么样才能扩展呢?TCP头中只给接收窗口值留了16 bit,肯定是无法突破65535 (216 −1)的。
1992年的RFC 1323中提出了一个解决方案,就是在三次握手时,把自己的Window Scale信息告知对方。由于Window Scale放在TCP头之外的Options中,所以不需要修改TCP头的设计。Window Scale的作用是向对方声明一个Shift count,我们把它作为2的指数,再乘以TCP头中定义的接收窗口,就得到真正的 TCP接收窗口了。
以图6为例,从底部可以看到10.32.106.159告诉10.32.106.103说它的Shift count是5。25 等于32,这就意味着以后10.32.106.159声明的接收窗口要乘以32才是真正的接收窗口值。
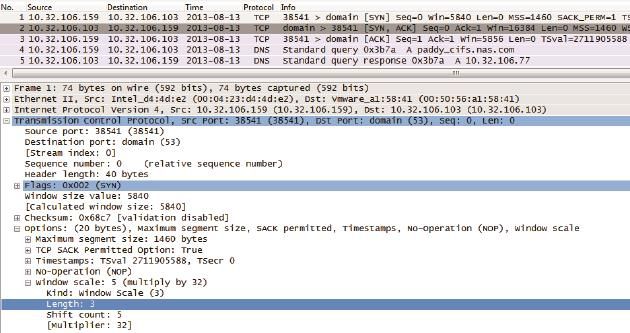
图6
接下来我们再看图7中的3号包。10.32.106.159声明它的接收窗口为“Window size value: 183”,183乘以32得到5856,所以Wireshark就显示出“Win=5856”了。要注意Wireshark是根据Shift count计算出这个结果的,如果抓包时没有抓到三次握手,Wireshark就不知道该如何计算,所以我们有时候会很莫名地看到一些极小的接收窗口值。还有些时候是防火墙识别不了Window Scale,因此对方无法获得Shift count,最终导致严重的性能问题。
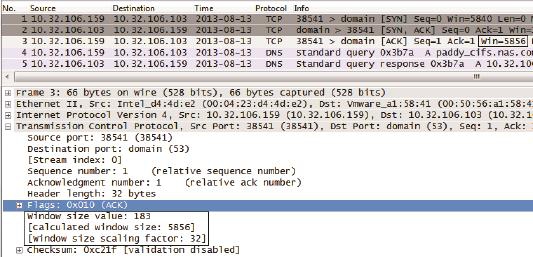
图7
重传的讲究
阅读本文之前,务必保证心情愉快,以免产生撕书的冲动;同时准备浓缩咖啡一杯,防止看到一半睡着了。因为这部分内容是TCP中最枯燥的,但也是最有价值的。
前文说到,发送方的发送窗口是受接收方的接收窗口和网络影响的,其中限制得更严的因素就起决定作用。接收窗口的影响方式非常简单,只要在包里用“Win=”告知发送方就可以了。而网络的影响方式非常复杂,所以留到本文专门介绍。
网络之所以能限制发送窗口,是因为它一口气收到太多数据时就会拥塞。拥塞的结果是丢包,这是发送方最忌惮的。能导致网络拥塞的数据量称为拥塞点,发送方当然希望把发送窗口控制在拥塞点以下,这样就能避免拥塞了。但问题是连网络设备都不知道自己的拥塞点,即便知道了也无法通知发送方。这种情况下发送方如何避免触碰拥塞点呢?
方案1.发送方知道自己的网卡带宽,能否以此推测该连接的拥塞点?
不能。因为发送方和接收方之间还有路由器和交换机,其中任何一个设备都可能是瓶颈。比如发送方的网卡是10Gbit/s,而接收方只有1Gbit/s,如果按照10Gbit/s计算肯定会出问题。就算用1Gbit/s来计算也没有意义,因为网络带宽是多个连接共享的,其他连接也会占用一定带宽。
方案2.逐次增加发送量,直到网络发生拥塞,这样得到的最大发送量能定为该连接的拥塞点吗?
这是一个好办法,但没这么简单。网络就像马路一样,有的时候很堵,其他时候却很空(北京的马路除外)。所以拥塞点是一个随时改变的动态值,当前试探出的拥塞点不能代表未来。
难道就没有一个完美的方案吗?很遗憾,还真的没有。自网络诞生数十年以 来,涌现过无数绝顶聪明的工程师,就是没有一个人能解决这个问题。幸好经过几代人的努力,总算有了一个最靠谱的策略。这个策略就是在发送方维护一个虚拟的拥塞窗口,并利用各种算法使它尽可能接近真实的拥塞点。网络对发送窗口的限制,就是通过拥塞窗口实现的。下面我们就来看看拥塞窗口如何维护。
1.连接刚刚建立的时候,发送方对网络状况一无所知。如果一口气发太多数据就可能遭遇拥塞,所以发送方把拥塞窗口的初始值定得很小。RFC的建议是2个、3个或者4个MSS,具体视MSS的大小而定。
2.如果发出去的包都得到确认,表明还没有达到拥塞点,可以增大拥塞窗口。由于这个阶段发生拥塞的概率很低,所以增速应该快一些。RFC建议的算法是每收到n个确认,可以把拥塞窗口增加n个MSS。比如发了2个包之后收到2个确认,拥塞窗口就增大到2+2=4,接下来是4+4=8, 8+8=16……这个过程的增速很快,但是由于基数低,传输速度还是比较慢的,所以被称为慢启动过程。
3.慢启动过程持续一段时间后,拥塞窗口达到一个较大的值。这时候传输速度比较快,触碰拥塞点的概率也大了,所以不能继续采用翻倍的慢启动算法,而是要缓慢一点。RFC建议的算法是在每个往返时间增加1个MSS。比如发了16个MSS之后全部被确认了,拥塞窗口就增加到16+1=17个MSS,再接下去是17+1=18, 18+1=19……这个过程称为拥塞避免。从慢启动过渡到拥塞避免的临界窗口值很有讲究。如果之前发生过拥塞,就把该拥塞点作为参考依据。如果从来没有拥塞过就可以取相对较大的值,比如和最大接收窗口相等。全过程可以用图1表示。
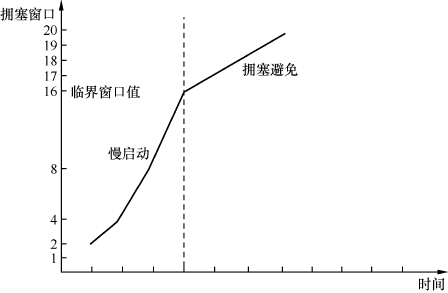
图1
无论是慢启动还是拥塞避免阶段,拥塞窗口都在逐渐增大,理论上一定时间之后总会碰到拥塞点的。那为什么我们平时感觉不到拥塞呢?原因有很多,如下所示。
• 操作系统中对接收窗口的最大设定多年没有改动,比如Windows在不启用“TCP window scale option”的情况下,最大接收窗口只有64KB。而近年来网络有了长足进步,很多环境的拥塞点远在64KB以上。也就是说发送窗口已经被限制在64KB了,永远触碰不到拥塞点。
• 很多应用场景是交互式的小数据,比如网络聊天,所以也不会有拥塞的可能。
• 在传输数据的时候如果采用同步方式,可能需要的窗口非常小。比如采用了同步方式的NFS写操作,每发一个写请求就停下来等回复,而一个写请求可能只有4KB。
• 即便偶尔发生拥塞,持续时间也不足以长到能感受出来,除非抓了网络包进行数据分析、对比。
拥塞之后会发生什么情况呢?对发送方来说,就是发出去的包不像往常一样得到确认了。不过收不到确认也可能是网络延迟所致,所以发送方决定等待一小段时间后再判断。假如迟迟收不到,就认定包已经丢失,只能重传了。这个过程称为超时重传。如图2所示,从发出原始包到重传该包的这段时间称为RTO。RTO
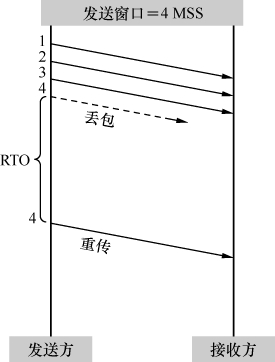
图2
的取值颇有讲究,理论上需要几个公式计算出来。根据多一道公式就会丢失一半读者的原理,本文将对此只字不提,我们只需要知道存在这么一段时间就可以了。有些操作系统上提供了调节RTO大小的参数。
重传之后的拥塞窗口是否需要调整呢?非常有必要,为了不给刚发生拥塞的网络雪上加霜,RFC建议把拥塞窗口降到1个MSS,然后再次进入慢启动过程。这一次从慢启动过渡到拥塞避免的临界窗口值就有参考依据了。Richard Stevens在《TCP/IP Illustrated》中把临界窗口值定为上次发生拥塞时的发送窗口的一半。而RFC 5681则认为应该是发生拥塞时没被确认的数据量的1/2,但不能小于2个MSS。比如说发了19个包出去,但只有前3个包收到确认,那么临界窗口值就被定为后16个包携带的数据量的1/2。我没有细究过为什么Stevens和RFC会有这个分歧,不过Stevens是在1999年意外去世的,而RFC 5681直到2009才发布,也许是Stevens在书中引用了更早版本的RFC。虽然Stevens是我最喜欢的技术作家,但在这个细节上我认为RFC 5681更加科学。
图3显示了发生超时重传时拥塞窗口的变化。
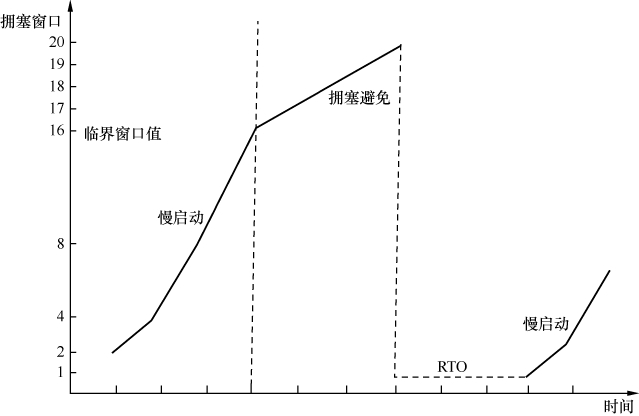
图3
不难想象,超时重传对传输性能有严重影响。原因之一是在RTO阶段不能传数据,相当于浪费了一段时间;原因之二是拥塞窗口的急剧减小,相当于接下来 传得慢多了。以我的个人经验,即便是万分之一的超时重传对性能的影响也非同小可。我们在Wireshark中如何检查重传情况呢?单击Analyze-->Expert Info Composite菜单,就能在Notes标签看到它们了,如图4所示。点开+号还能看到具体是哪些包发生了重传。
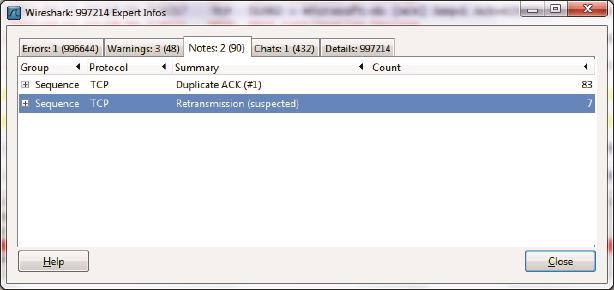
图4
图5是我处理过的一个真实案例。我从Notes标签中看到Seq号为1458613的包发生了超时重传。于是用该Seq号过滤出原始包和重传包(只有在发送方抓的包才看得到原始包),发现RTO竟长达1秒钟以上。这对性能的影响实在太大了,幸好这台发送方提供了缩小RTO的参数,调整后性能提高了不少。当然治标又治本的方式是找出瓶颈,彻底消除重传。

图5
有时候拥塞很轻微,只有少量的包丢失。还有些偶然因素,比如校验码不对的时候,会导致单个丢包。这两种丢包症状和严重拥塞时不一样,因为后续有包能正常到达。当后续的包到达接收方时,接收方会发现其Seq号比期望的大,所以它每收到一个包就Ack一次期望的Seq号,以此提醒发送方重传。当发送方收到3个或以上重复确认(Dup Ack)时,就意识到相应的包已经丢了,从而立即重传它。这个过程称为快速重传。之所以称为快速,是因为它不像超时重传一样需要等待一段时间。
图6是我处理过的另一个真实案例。客户端发送了1182、1184、1185、1187、1188 共5个包,其中1182在路上丢了。幸好到达服务器的4个包触发了4个Ack=991851,所以客户端意识到丢包了,于是在包号1337快速重传了Seq=991851。

图6
为什么要规定凑满3个呢?这是因为网络包有时会乱序,乱序的包一样会触发重复的Ack,但是为了乱序而重传没有必要。由于一般乱序的距离不会相差太大,比如2号包也许会跑到4号包后面,但不太可能跑到6号包后面,所以限定成3个或以上可以在很大程度上避免因乱序而触发快速重传。如图7中的左图所示,2号包的丢失凑满了3个Dup Ack,所以触发快速重传。而右图的2号包跑到4号包后面,却因为凑不满3个Ack而没有触发快速重传。
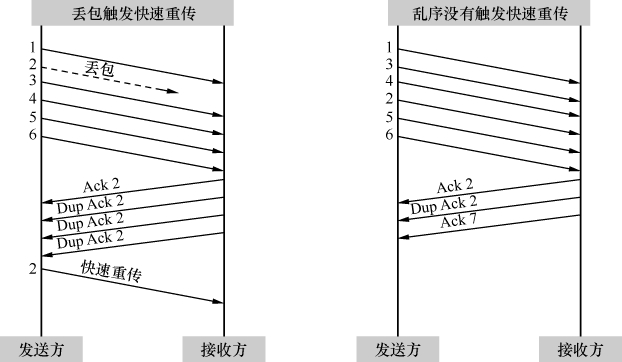
图7
如果在拥塞避免阶段发生了快速重传,是否需要像发生超时重传一样处理拥塞窗口呢?完全没有必要—既然后续的包都到达了,说明网络并没有严重拥塞,接下来传慢点就可以了。对此Richard Stevens 和RFC 5681的建议也略有不同。后者认为临界窗口值应该设为发生拥塞时还没被确认的数据量的1/2(但不能小于 2个MSS)。然后将拥塞窗口设置为临界窗口值加3个MSS,继续保留在拥塞避免阶段。这个过程称为快速恢复,其拥塞窗口的变化大概可以用图8表示。
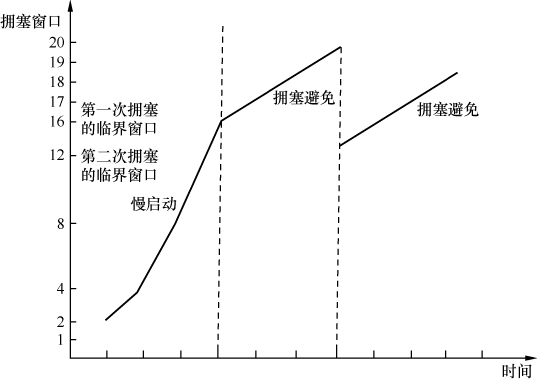
图8
不知道你是否想到过一个更复杂的情况—很多时候丢的包并不只一个。比如图9中2号和3号包丢失,但1、4、5、6、7、8号都到达了接收方并触发Ack 2。对于发送方来说,只能通过Ack 2知道2号包丢失了,但并不知道还有哪些包丢失。在重传了2号包之后,接下来应该传哪一个呢?
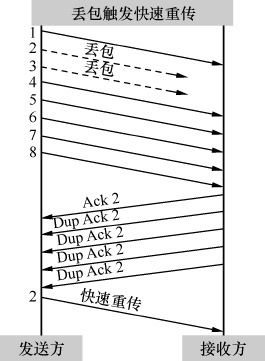
图9
方案1.不管三七二十一,把3、4、5、6、7、8号等6个包都重传一遍。这 个方案简单直接,但是丢一个包的后果就是多个包被重传,效率较低。早期的TCP协议就是这样处理的。
方案2.接收方收到重传过来的2号包之后,会回复一个Ack 3,因此发送方可以推理出3号包也丢了,把它也重传一遍。当接收方收到重传的3号包之后,因为丢包的窟窿都补满了,所以回复一个Ack 9,从此发送方就可以传新的包(包号9、10、11、……)了。这个方案称为NewReno,由RFC 2582和RFC 3782定义。NewReno在本例中看上去很理想,但我们可以想见当丢包量很大的时候,就需要花费多个RTT(往返时间)来重传所有丢失的包。
方案3.接收方在Ack 2号包的时候,顺便把收到的包号告诉发送方。所以这些Ack包应该是这样的:
收到4号包时,告诉发送方:“我已经收到4号,请给我2号。”
收到5号包时,告诉发送方:“我已经收到4、5号,请给我2号。”
收到6号包时,告诉发送方:“我已经收到4、5、6号,请给我2号。”
……
因此发送方对丢包细节了如指掌,在快速重传了2号包之后,它可以接着传3号,然后再传9号包。这个非常直观的方案称为SACK,由RFC 2018定义。
图10是在真实环境中抓到的SACK实例。把“SACK=992461-996175”和“Ack=991851”两个条件综合起来,发送方就知道992461~996175已经收到了,而前面的991851~992460反而没收到。
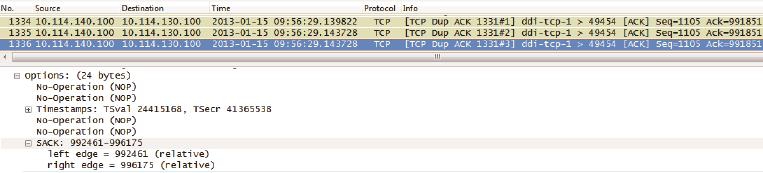
图10
本文的信息量有点大,你也许需要一些时间来消化它。有些部分一时理解不了也无妨,即便只记住本文导出的几个结论,在工作中也是很有用的。
• 没有拥塞时,发送窗口越大,性能越好。所以在带宽没有限制的条件下,应该尽量增大接收窗口,比如启用Scale Option(Windows上可参考KB 224829)。
• 如果经常发生拥塞,那限制发送窗口反而能提高性能,因为即便万分之一的重传对性能的影响都很大。在很多操作系统上可以通过限制接收窗口的方法来减小发送窗口,Windows上同样可以参考KB 224829。
• 超时重传对性能影响最大,因为它有一段时间(RTO)没有传输任何数据,而且拥塞窗口会被设成1个MSS,所以要尽量避免超时重传。
• 快速重传对性能影响小一些,因为它没有等待时间,而且拥塞窗口减小的幅度没那么大。
• SACK和NewReno有利于提高重传效率,提高传输性能。
• 丢包对极小文件的影响比大文件严重。因为读写一个小文件需要的包数很少,所以丢包时往往凑不满3个Dup Ack,只能等待超时重传了。而大文件有较大可能触发快速重传。下面的实验显示了同样的丢包率对大小文件的不同影响:图11中的test是包含很多小文件的目录,而图12的hi是一个大文件。发生丢包时前者耗时增加了7倍多,而后者只增加了不到4倍。
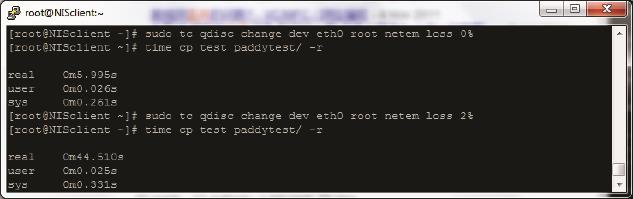
图11
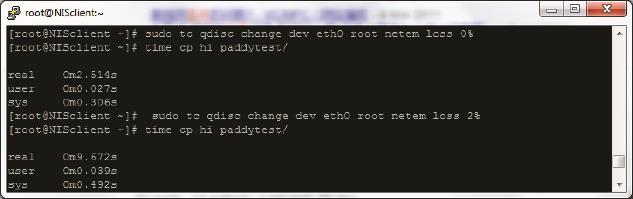
图12
延迟确认与Nagle算法
不知道前两篇的内容有没有令你感到头疼?幸好,这一篇终于可以讨论跟TCP窗口无关的话题了。
发送窗口一般只影响大块的数据传输,比如读写大文件。而频繁交互的小块数据不太在乎发送窗口的大小,因为发包量本来就少。日常生活中这样的场景很多,比如用Putty之类的SSH客户端连上一台Linux服务器,然后随便输入一些字符,在网络上就交互了很多小块数据了。当网络状况良好时,我们会感觉一输入字符就立即显示出来。究其原因,是因为每输入一个字符就被打成TCP包传到服务器上,然后服务器也随即进行回复。
假如把这个过程的包抓下来,会看到很多小包频繁来往于客户端和服务器之间。这种方式其实是很低效的,因为一个包的TCP头和IP头至少就40字节,而携带的数据却只有一个字符。这就像快递员开着大货车去送一个小包裹一样浪费。
我做了一个实验来研究这个现象。先在Putty上缓慢地输入3个字符“j”,每次按键的间隔在300毫秒以上,这时候Wireshark抓到了前9个包。接着我快速敲击键盘,Wireshark又抓了后面的包,Wireshark截屏如图1所示。

图1
客户端:“我想给你发个加密后的字符‘j’。”
服务器:“我收到字符‘j’了,你可以把它显示出来。”
客户端:“知道了。”
接下来的4、5、6号包,以及7、8、9号包也是一样的情况
我的客户端10.32.200.43放在上海,而服务器10.32.23.55位于悉尼,它们之间的往返时间大概是150毫秒。由于这些包是在客户端收集的,所以1号包和2号包相差150毫秒是正常现象。奇怪的是客户端收到2号包之后,竟然等待了大约200毫秒才发出3号包。本来是1毫秒之内可以完成的事,为什么要等这么久呢?再看看5号和6号之间,以及8号和9号之间,也是大概相差200毫秒。
这其实就是TCP处理交互式场景的策略之一,称为延迟确认。该策略的原理是这样的:如果收到一个包之后暂时没什么数据要发给对方,那就延迟一段时间(在Windows上默认为200毫秒)再确认。假如在这段时间里恰好有数据要发送,那确认信息和数据就可以在一个包里发出去了。第12号包就恰好符合这个策略,客户端收到11号包之后,等了41毫秒左右时我又输入一个字符。结果这个字符和对11号包的确认信息就一起装在12号包里了。
延迟确认并没有直接提高性能,它只是减少了部分确认包,减轻了网络负担。有时候延迟确认反而会影响性能。微软的KB 328890 提供了关闭延迟确认的步骤。我在另一台客户端10.32.200.131上实施这些步骤后,结果如图2所示,果然不到1毫秒就发确认了(参见6号包和7号包的时间差)。

图2
仔细看图1和图2,会发现每个SSH Request都是52字节,这表明它只包含了一个加密的字符。虽然在图1的12号到18号包之间的100毫秒里(还不到一个往返时间),我一共输入了7个字符,但这些字符也被逐个打成小包了。能不能设计一个缓冲机制,把一个往返时间里生成的小数据收集起来,合并成一个大包呢?Nagle算法就实现了这个功能。这个算法的原理是:在发出去的数据还没有被确认之前,假如又有小数据生成,那就把小数据收集起来,凑满一个MSS或者等收到确认后再发送。图3是我启用Nagle之后的新实验,第一个包把我输入的第一个字符发出去了。在收到确认包之前的150毫秒里,我又输入6个字符。这6个字符并没有被逐个发送,而是被收集起来,等收到2号包之后,从3号包里一起发送。这就是为什么3号包携带的数据长度是312字节。
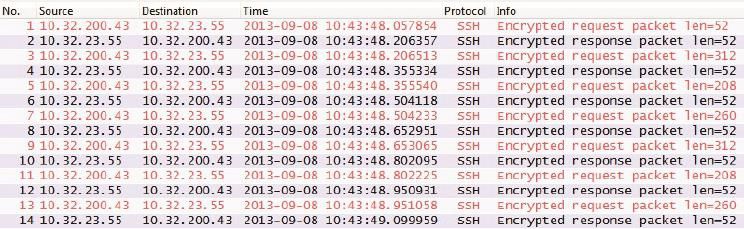
图3
和延迟确认一样,Nagle也没有直接提高性能,启用它的作用只是提高传输效率,减轻网络负担。在某些场合,比如和延迟确认一起使用时甚至会降低性能。微软也有篇KB指导如何关闭Nagle,但是一般没有这个必要,原因之一是很多软件已经默认关闭Nagle了。比如打开Putty,到“Connection”选项里可见“Disable Nagle’s algorithm”默认就是选中的,如图4所示。
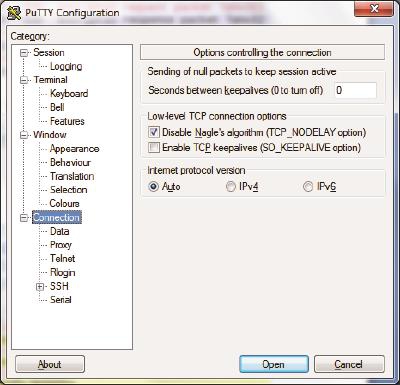
图4
我启用Nagle的另一个原因是,很多高手说自己解决过Nagle所导致的问题。我希望自己也能碰上一回,这样以后伪装成高手时就有谈资了,可惜目前为止还没机会碰到。我曾经拿到过图5所示的一个包,据说是Nagle导致了写文件很慢。之所以定位到Nagle,是因为客户端收到“SetInfo Response”之后,要等上100多毫秒再发送下一个“SetInfo Request”。他们怀疑是客户端在这100多毫秒里忙于收集小数据。

图5
我一开始非常高兴,以为终于碰到一回了。仔细一看非常失望,因为这个症状并不符合Nagle的定义。Nagle是在没收到确认之前先收集数据,一旦收到确认就立即把数据发出去,而不是等100多毫秒之后再发。如果说这个现象是延迟确认还更接近一点,但也不正确。它实际是应用层的一个bug导致的,换了个SMB版本后问题就消失了,我就这样错失了一次伪装成高手的机会。
百家争鸣
离职不久的老同事给我发来一条短信:“阿满,能否解释一下Westwood和Vegas等TCP算法的差别?”
这个问题让我颇感意外。真是士别三日,当刮目相看,怎么才跳槽没几天就研究到如此高端洋气上档次的方向了?不过转念一想,假如新工作是设计一个网络平台,那还是很有必要知道这些知识的,因为不同的场景适合不同的TCP算法。而要了解这些算法,就得从TCP最原始的设计开始讲起。最早系统性地阐述了慢启动、拥塞避免和快速重传等算法的并非RFC,而是1993年年底出版的奇书《TCP/IP Illustrated, Volume 1: The Protocols》,作者是我以前提到过的一位教父级人物——Richard Stevens。直到1997年,这本书中的内容才被复制到了RFC 2001中。我第一次读到这些算法时拍案叫绝,完全不知道还有优化之处。比如书中介绍了一个叫“临界窗口值”的概念,当拥塞窗口处于临界窗口值以下时,就用增速较快的慢启动算法;当拥塞窗口升到临界窗口值以上时,则改用增速较慢的拥塞避免算法。从图1可见,临界窗口前后的斜率有明显的变化。这个机制有利于拥塞窗口在最短时间到达高位,然后保持尽可能长的时间才触碰拥塞点,思路还是很科学的。
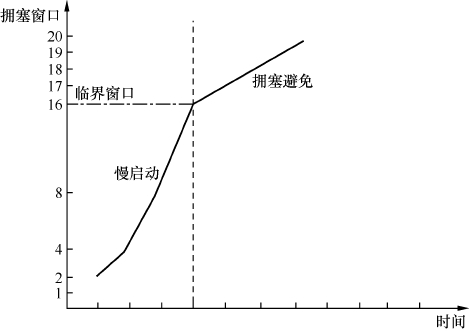
图1
那临界窗口应该如何取值才合理呢?我能想到的,就是在带宽大的环境中取得大一些,在带宽小的环境中取得小一些。RFC 2001也是这样建议的,它把临界窗口值定义为发生丢包时拥塞窗口的一半大小。我们可以想象在带宽大的环境中,发生丢包时的拥塞窗口往往也比较大,所以临界窗口值自然会随之加大。可以用下面的例子来加以说明。
图2在拥塞窗口为16个MSS时发生了丢包,而图3在拥塞窗口为8个MSS时就丢包了,说明当时图2中的带宽很可能比图3中的大。根据RFC 2001,我们希望接下来图2的拥塞窗口能快速恢复到临界窗口值16/2=8个MSS,然后再缓慢增加;也希望图3中的拥塞窗口能快速恢复到临界窗口值8/2=4个MSS,然后再缓慢增加。这样做的结果就是图2的拥塞窗口比图3的增长得更快,更配得起它的带宽。以上这些分析,看上去很有道理吧?
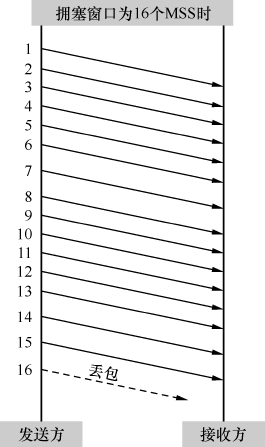
图2
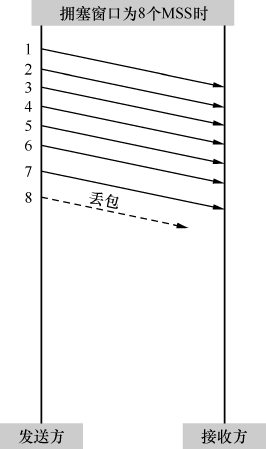
图3
有些聪明人就不认同以上分析。比如有一位叫Saverio Mascolo的意大利人看了这个算法之后,觉得太简单粗暴了。真实环境的丢包状况比上面的例子复杂得多,比如在相同大小的拥塞窗口中,有时候丢包的比例大,有时候丢包的比例小,统一按照拥塞窗口的一半取值是不理想的。我们可以看看下面这个例子。
图4和图5在发生丢包时的拥塞窗口都是16个MSS,不过图4丢了4个包,而图5丢了12个。如果按照RFC 2001的算法,两边的临界窗口值都应该被定义为16/2=8个MSS。这显然是不合理的,因为图4丢了4个包,图5丢了12个,说明当时图4的带宽很可能比图5的大,应该把临界窗口值设得比图5的大才对。归纳一下,理想的算法应该是先推算出有多少包已经被送达接收方,从而更精确地估算发生拥塞时的带宽,最后再依据带宽来确定新的拥塞窗口。那么如何知道哪些包被送达了呢?熟悉TCP协议的读者应该想到了—可以根据接收方回应的Ack来推算。于是不安分的Saverio先生依据这个理论提出了Westwood算法(当然实施起来不是我说的这么简单),后来又升级为Westwood+。
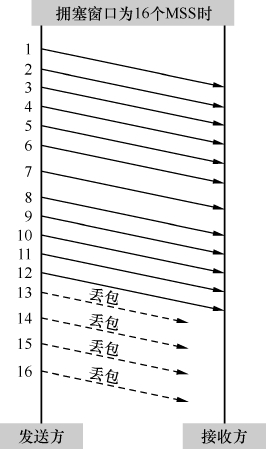
图4
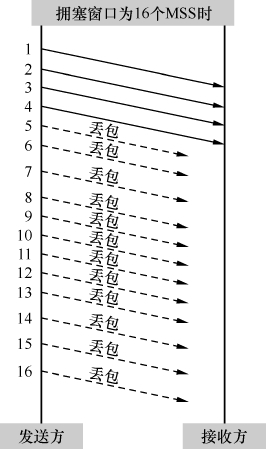
图5
从设计理念就可以看出,当丢包很轻微时,由于Westwood能估算出当时拥塞并不严重,所以不会大幅度减小临界窗口值,传输速度也能得以保持。在经常发生非拥塞性丢包的环境中(比如无线网络),Westwood最能体现出其优势。目前关于Westwood的研究有很多,我甚至能找到不少中文论文,实际中也有应用,比如部分Linux版本就用到了它。我一向有“人肉”IT界牛人的习惯,Saverio先生当然也在列。不过当我打开他的主页时,发现都是意大利文,只好作罢。
这里要插播一个有趣的情况。RFC 2581也同样改进了RFC 2001中关于临界 窗口值的计算公式,把原先“拥塞窗口的一半”改为FlightSize的一半,其中FlightSize的定义是“The amount of data that has been sent but not yet acknowledged(已发送但未确认的数据量)。”如果根据这个定义,我们会惊奇地算出图4的临界窗口值为4/2=2 MSS,而图5的临界窗口值为12/2=6 MSS。这跟“图4应该大于图5”的期望是完全相反的,难道RFC 2581有错误?这可是经过无数人检验过的著名文档。我曾经忐忑不安地把这个问题发给过几位国外同行,说“Could you confirm if there is any problem with my brain or RFC 2581?”幸好得到的答复大多认为我的大脑是正常的,他们也认为这个算法有问题。最后有一位大牛现身,说我们对RFC 2581的要求太高了,当初设计的时候根本没考虑这么多。引进FlightSize只是为了得到一个安全的临界窗口值,而不是像Westwood+一样追求比较理想的窗口。
接下来我们说说Vegas算法。如果说Westwood只是对TCP进行了细节性的、改良性的优化,Vegas则引入了一个全新的理念。本书之前介绍过的所有算法,都是在丢包后才调节拥塞窗口的。Vegas却独辟蹊径,通过监控网络状态来调整发包速度,从而实现真正的“拥塞避免”。它的理论依据也并不复杂:当网络状况良好时,数据包的RTT(往返时间)比较稳定,这时候就可以增大拥塞窗口;当网络开始繁忙时,数据包开始排队,RTT就会变大,这时候就需要减小拥塞窗口了。该设计的最大优势在于,在拥塞真正发生之前,发送方已经能通过RTT预测到,并且通过减缓发送速度来避免丢包的发生。
与别的算法相比,Vegas就像一位敏感、稳重、谦让的君子。我们可以想象当环境中所有发送方都使用Vegas时,总体传输情况是更稳定、更高效的,因为几乎没有丢包会发生。而当环境中存在Vegas和其他算法时,使用Vegas的发送方可能是性能最差的,因为它最早探测到网络繁忙,然后主动降低了自己的传输速度。这一让步可能就释放了网络的压力,从而避免其他发送方遭遇丢包。这个情况有点像开车,如果路上每位司机的车品都很好,谦让守规矩,则整体交通状况良好;而如果一位车品很好的司机跟一群车品很差的司机一起开车,则可能被频繁加塞,最后成了开得最慢的一个。
除了本文提到的Westwood和Vegas,还有很多有意思的TCP算法。比如Windows操作系统中用到的Compound算法就同时维持了两个拥塞窗口,其中一 个类似Vegas,另一个类似RFC 2581,但真正起作用的是两者之和。所以说Compound走的是中庸之道,在保持谦让的前提下也不失进取。在Windows 7上,默认情况下Compound算法是关闭的,我们可以通过下面的命令来启用它。
netsh interface tcp set global congestionprovider=ctcp
启用之后如果觉得不合适,可以通过以下命令来关闭。
netsh interface tcp set global congestionprovider=none
图6是在我的实验机上启用的过程。
图6
Linux操作系统则在不同的内核版本中使用不同的默认TCP算法,比如Linux kernels 2.6.18用到了BIC算法,而Linux kernels 2.6.19则升级到了CUBIC算法。后者比前者的行为保守一些,因为在网络状况非常糟糕的状况下,保守一点的性 能反而更好。
在过去几十年里,虽然TCP从来没有遇到过对手,不过它自己已经演化出无数分身,形成百家争鸣的局面。本文无法一一列举所有的算法,点到的也如蜻蜓点水,假如你想为自己的网络平台选取其中一种,还需要多多研究。
简单的代价——UDP
说到UDP,就不得不拿TCP来对比。谁叫它们是竞争对手呢?
前文提到过UDP无需连接,所以非常适合DNS查询。图1和图2是分别在基于UDP和TCP时执行DNS查询的两个包,前者明显更加直截了当,两个包就完成了。
基于UDP的查询:

图1
基于TCP的查询:

图2
UDP为什么能如此直接呢?其实是因为它设计简单,想复杂起来都没办法—在UDP协议头中,只有端口号、包长度和校验码等少量信息,总共就8个字节。小巧的头部给它带来了一些优点。
• 由于UDP协议头长度还不到TCP头的一半,所以在同样大小的包里,UDP包携带的净数据比TCP包多一些。
• 由于UDP没有Seq号和Ack号等概念,无法维持一个连接,所以省去了建立连接的负担。这个优势在DNS查询中体现得淋漓尽致。
当然简单的设计不一定是好事,更多的时候会带来问题。
1.UDP不像TCP一样在乎双方MTU的大小。它拿到应用层的数据之后,直接打上UDP头就交给下一层了。那么超过MTU的时候怎么办?在这种情况下,发送方的网络层负责分片,接收方收到分片后再组装起来,这个过程会消耗资源,降低性能。图3是一个32 KB的写操作,根据发送方的MTU被切成了23个分片。
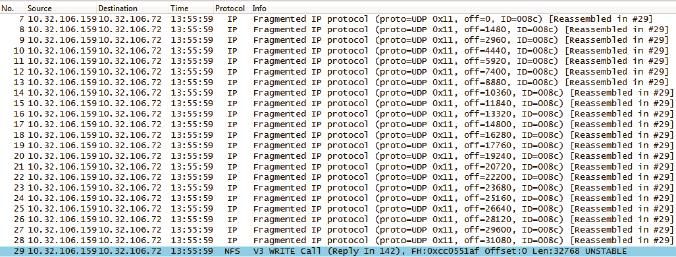
图3
2.UDP没有重传机制,所以丢包由应用层来处理。如下面的例子所示,某个写操作需要6个包完成。当基于UDP的写操作中有一个包丢失时,客户端不得不重传整个写操作(6个包)。相比之下,基于TCP的写操作就好很多,只要重传丢失的那1个包即可。
基于UDP的NFS写操作(见图4):
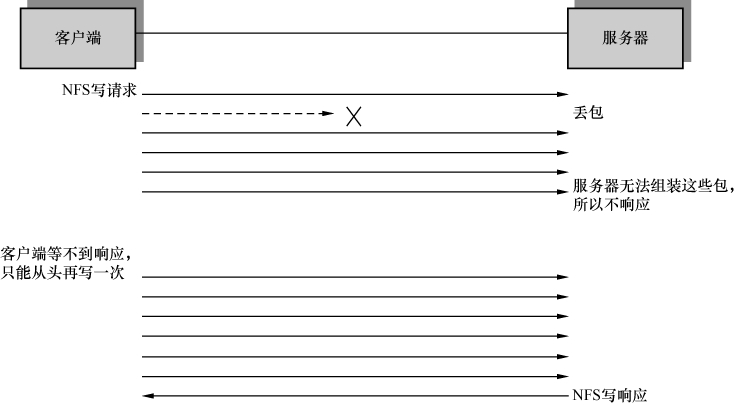
图4
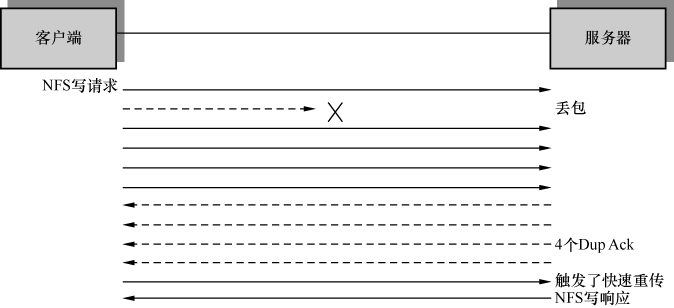
图5
也许从这个例子你还感受不到明显的差别,试想一下,在高性能环境中,一个写操作需要数十个包来完成,UDP的劣势就体现出来了。
3.分片机制存在弱点,会成为黑客的攻击目标。接收方之所以知道什么时候该把分片组装起来,是因为每个包里都有 “More fragments”的flag。1表示后续还有分片,0则表示这是最后一个分片,可以组装了。如果黑客持续快速地发送flag为1的UDP包,接收方一直无法把这些包组装起来,就有可能耗尽内存。图6左边是NFS写操作中7~28号分片的flag,右边是29号分片(最后一个分片)的flag。

图6
关于UDP就简单介绍这么多。虽然我觉得这个协议实在没多少可谈的,但关于UDP和TCP的争论一直是某些论坛的热门话题。了解了UDP的工作方式,也算学会一门伪装成大牛的手艺。下次再有人宣称“UDP的性能比TCP更好”时,你可以不紧不慢地告诉他,“也不尽然,我来给你举一个NFS丢包的例子……”。
剖析CIFS协议
前文介绍过一个文件共享协议,即Sun设计的NFS。理论上NFS可以应用在任何操作系统上,但是因为历史原因,现实中只在Linux/UNIX上流行。那Windows上一般使用什么共享协议呢?它就是微软维护的SMB协议,也叫Common Internet File System(CIFS)。CIFS协议有三个版本:SMB、SMB2和SMB3,目前SMB 和SMB2比较普遍。
在Windows上创建CIFS共享非常简单,只要在一个目录上右键单击,在弹出的菜单中选择属性-->共享,再配置一下权限就可以了。如图1所示,在其他电脑上只要输入IP和共享名就可以访问它了。
图1
我在读大学的时候,曾经把整个D盘共享出来,没想到几天后就有雷锋在里面放了几部小电影。CIFS在企业环境中应用非常广泛,比如映射网络盘或者共享打印机;同事间共享资料也可以采用这种方式。由于使用CIFS的用户实在太多,微软的技术支持部门每天都会收到很多关于CIFS问题的咨询(我读大学时曾在那里兼职过一年)。
要想成为CIFS方面的专家,就必须了解它的工作方式。比如在我的实验室中,客户端10.32.200.43打开共享文件\\10.32.106.72\dest\abc.txt时,底层究竟发 生了什么?借助Wireshark,我们可以把这个过程看得清清楚楚。
首先,CIFS只能基于TCP,所以必定是以三次握手开始的。从图2可见,CIFS服务器上的端口号为445。

图2
接下来的第一个CIFS操作是Negotiate(协商)。协商些什么呢?请关注图3的底部,可见客户端把自己支持的所有CIFS版本,比如SMB2和NT LM 0.12(为了便于和SMB2对比,接下来我们称它为SMB)等都发给服务器。
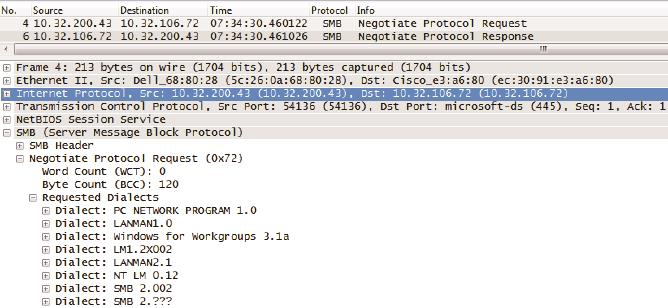
图3
服务器从中挑出自己所支持的最高版本回复给客户端。从图4中可知,服务器选择的是NT LM 0.12(SMB),这说明了该服务器不支持SMB2。
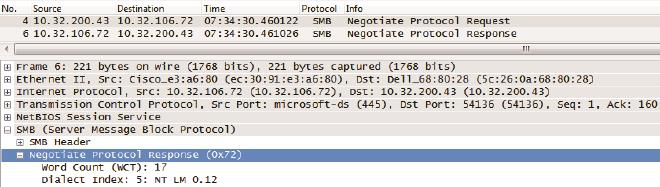
图4
理解了协商过程就可以处理CIFS版本相关的问题了。比如我接到过新加坡某银行的咨询,他们想知道如何让客户端A和服务器C之间用SMB2通信,而客户端B和服务器C之间用SMB通信。我的建议是在A和C上都启用SMB2,而在B上只启用SMB,这样就能协商出想要的结果。
协商好版本之后,就可以建立CIFS Session了,如图5所示。

图5
Session Setup的主要任务是身份验证,常用的方式有Kerberos和NTLM(本例就是用到NTLM)。这两种方式都非常复杂且有趣,我会另写一篇文章专门介绍。假如有用户抱怨访问不了CIFS服务器,问题很可能就发生在Session Setup。
Session Setup过后,意味着已经打开\\10.32.106.72了。接下来要做的是打开\dest共享。如图6所示,这个操作称为Tree Connect。
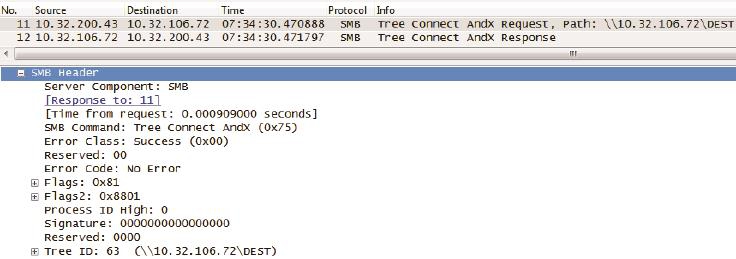
图6
点开这两个Tree Connect包,最有价值的信息当属服务器返回的Tree ID(如图6底部所示)。从此之后客户端就能利用这个ID去访问/dest共享的子目录和子文件。这一步看似简单,但初学者也会有一些疑问。
常见问题1:如果用户无权访问此目录,会不会在Tree Connect这一步失败?
答案:不会。Tree Connect并不检查权限,所以即便是无权访问的用户也能 得到Tree ID。检查权限的工作由接下来的Create操作完成。
常见问题2:某用户已经打开了\\10.32.106.72\dest\abc.txt,如果还想再打开\\10.32.106.72\source\abc.txt,需要再建一个TCP连接吗?
答案:没有必要,在一个TCP连接上能维持多个打开的Tree Connect。
过了Tree Connect是不是该开始读abc.txt了?其实还差很多步骤,接下来客户端还要在服务器上查询很多信息。看了图7你就能理解为什么人们都嫌CIFS协议啰嗦了。
图7
其实从13号到68号包都是类似图7所示的网络包,图7只显示了一小部分,我不想把所有内容都贴出来浪费纸张。这些包查询了文件的基本属性、标准属性、扩展属性,还有文件系统的信息等。幸好SMB2对此有所改进。
再多的属性也有查完的时候,到了69号包终于看到Create Request \abc.txt了(见图8)。

图8
Create是CIFS中非常重要的一个操作。无论是新建文件、打开目录,还是读写文件,都需要Create。有时候我们因为没有权限遭遇“Access Denied”错误,或者覆盖文件时收到“File Already Exists”提醒,都是来自Create这个操作。经 常有人会咨询的几个关于Create的问题如下所示。
常见问题1:如果\dest的权限里禁止某用户访问,但\dest\abc.txt的权限里允许该用户访问,那他打开\\10.32.106.72\dest\abc.txt时会不会失败?
答案:如果该用户先打开\\10.32.106.72\dest,就会在“NT Create \dest”这一步收到Access Denied报错,当然就无法再进一步打开abc.txt了。而如果直接在地址栏输入\\10.32.106.72\dest\abc.txt,则可以跳过“NT Create \dest”这一步,所以不会有任何报错。也就是说可以直接打开子文件abc.txt,却打不开上级文件夹\dest,这个结果可能是很多人意想不到的。
常见问题 2:Windows的Backup Operators组中的用户有权限备份所有文件,但不一定有权限读文件。那服务器是怎么知道一个用户是想备份还是想读的?
答案:备份和读这两个行为的确非常相似,都是依靠Read操作来完成的。它们的不同点在于,备份的时候在Create请求中的“Backup Intent”设为1,而读的时候“Backup Intent”设为0(如图9所示)。服务器就是依靠Backup Intent来决定是否允许访问的。
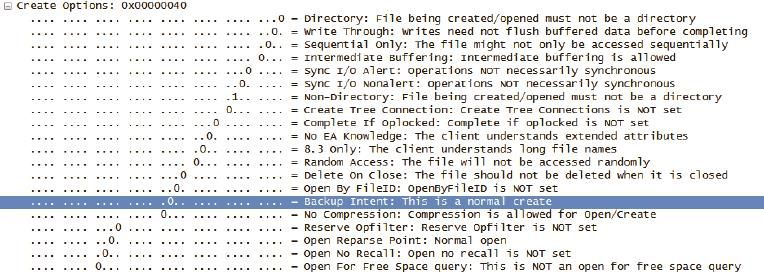
图9
常见问题3:如果多个用户一起访问相同文件,CIFS如何处理冲突?
答案:在Create请求中有Access Mask和Share Access Mask两个选项。前者 表示该用户对此文件的访问方式(读、写、删等),后者表示该用户允许其他用户对此文件的访问方式。举个例子,用户A发送的Create请求中,Access Mask是“读+写”,Share Access Mask是“读”,表示自己要读和写,并同时允许其他人只读。假如接下来用户B也发送Access Mask为“读+写”的Create请求,就会收到“Sharing Violation”错误,因为A不允许其他人写。
图10中的Access Mask只是读。
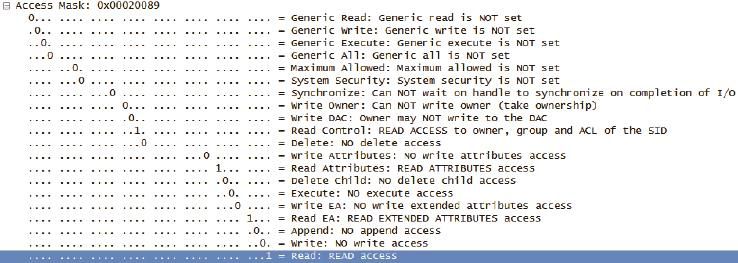
图10
注意:这里讨论的访问冲突指的是CIFS协议层的。有些应用软件还有专门的机制防止访问冲突,比如Word和Excel,但Notepad就没有。
常见问题 4:CIFS如何保证缓存数据的一致性?
答案:客户端可以暂时把文件缓存在本地,等用完之后再同步回服务器端。这是提高性能的好办法,就像我们写论文时,都喜欢把图书馆的资料借回来,以备随时查阅。假如不这样做,就得频繁地跑图书馆查资料,时间都浪费在路上了。当只有一个用户在访问某文件时,在客户端缓存该文件是安全的,但是在有多个用户访问同一文件的情况下则可能出现问题。CIFS采用了Oplock(机会锁)来解决这个问题。Oplock有Exclusive、Batch 和 Level 2三种形式。Exclusive允许读写缓存,Batch允许所有操作的缓存,而Level 2只允许读缓存。Oplock也是在Create中实现的,如图11底部所示,该客户端被授予Batch级别的机会锁,表示他可以缓存所有操作。
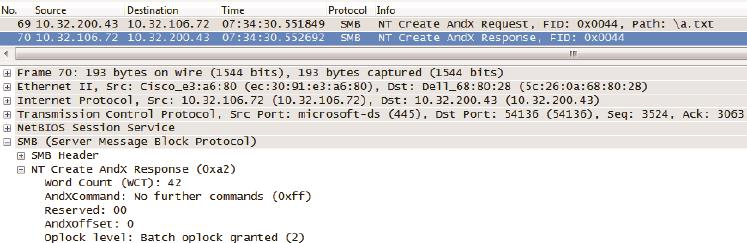
图11
为了更好地理解Oplock的工作方式,我们假设一个场景来说明。
1.用户A用Exclusive/Batch锁打开某文件,然后缓存了很多修改的文件内容。
2.用户B想读同一个文件,所以发了Create请求给服务器。
3.如果此时服务器忽视A的Oplock,直接回复B的请求,那B就读不到被A修改后的内容(也就是出现数据不一致)。因此服务器通知A释放Exclusive/Batch锁,换成Level 2锁。
4.A立即把缓存里的修改量同步到服务器上。
5.服务器给B回复Create响应,同时授予其Level 2锁。B接下来再发读请求,从而得到A修改后的文件内容。
到了Create这一步,距离TCP连接的建立已经过去0.093秒。虽然听上去很短,但在局域网中已经算是很长一段时间了。这段时间足够我实验室的NFS服务器响应45个64KB的读操作,而本例中的读操作却刚要开始,可见CIFS协议有多啰嗦。这让我想起一个经典问题,“为什么复制一个1MB的文件比复制1024 个1KB的文件快很多,虽然它们的总大小是一样的?”原因就是读写每个文件之前要花费很多时间在琐碎的准备工作上。一个1MB的文件只需要准备一次,而1024个1KB的文件却需要1024次。
从包号71开始,读操作终于出现了。如图12所示,CIFS的读行为看上去和NFS非常相似,都是从某个offset开始读一定数量的字节。文件的内容“I need a vacation!”能从包里直接看出,说明传输时没有加密。
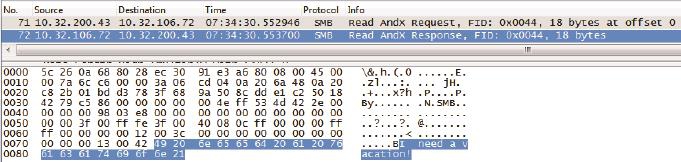
图12
还有很多有趣的行为是从这两个包里看不出来的,必须设计一些实验才能归纳出来。比如下面几个常见问题,可能很多读者会感兴趣。
常见问题1:同样是用SMB协议读一个文件,Windows XP和Windows 7的表现有何不同?
答案:通常一个新的操作系统发布时,微软都会罗列它的种种好处,但大家基本上听听就过去了,没有人会去较真。我仔细对比了Windows XP和Windows 7的读行为之后,发现Windows 7的确有所改进。Windows XP发了一个读请求之后就会停下来等回复,收到回复后再发下一个读请求。而Windows 7则可以一口气发出多个读请求,就像NFS一样。下面是在这两种操作系统上读同一个文件的过程,两者的差别在Wireshark中一目了然。
Windows XP的Request和Response是交替的(见图13):
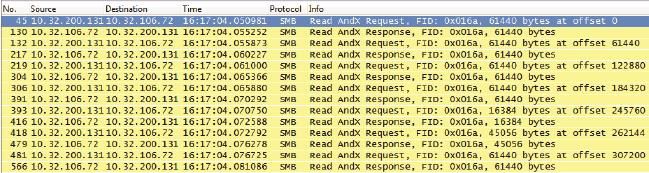
图13
Windows 7的Requests是多个一起发出的(见图14):
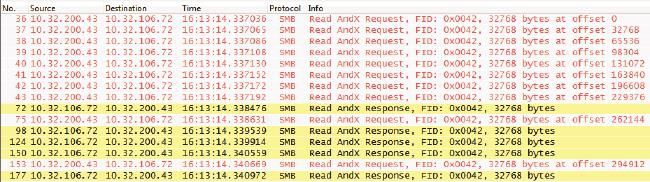
图14
这两种读方式在延迟小的网络中体现不出差别,在带宽小的环境中差别也不大(因为发送窗口小,一个读请求本来就要多个往返才能传完)。但在高延迟、大带宽的环境中就很不一样了,Windows 7的性能会比Windows XP好很多。在网络有丢包的情况下差别还会更大,因为Windows XP比Windows 7更容易碰到超时重传。
常见问题2:利用Windows Explorer从CIFS共享上复制文件,为什么比Robocopy和EMCopy之类的工具慢很多?
答案:如果复制一个大文件可能是看不出差别的,但如果是复制一个包含大量小文件的目录,的确是比这些工具慢很多。这是因为Windows Explorer是逐个文件复制的(单线程),而这些工具能同时复制多个文件(多线程)。比如上文提到的前0.093秒里虽然交互多次,但占用带宽极少,多个文件并行操作的效率会高很多。下面两个图是EMCopy的单线程和双线程复制同一文件夹的结果,后者明显要快得多。
单线程的复制(见图15):
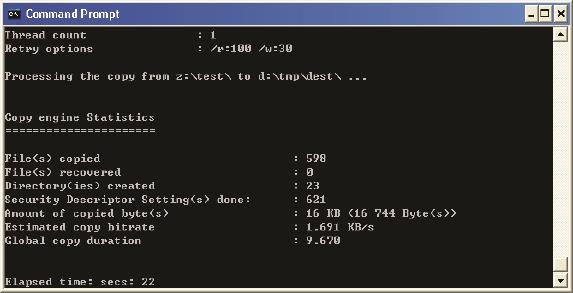
图15
双线程的复制(见图16):
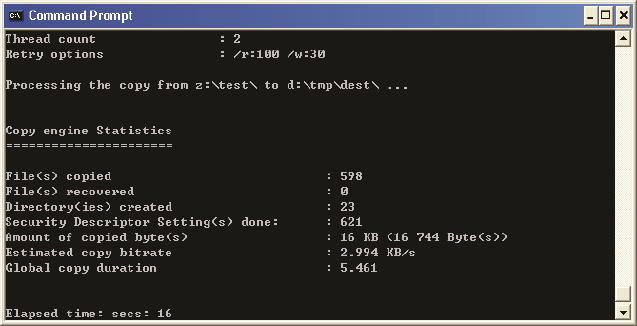
图16
常见问题3:从CIFS共享里复制一个文件,然后粘贴到同一个目录里,为什么还不如粘贴到客户端的本地硬盘快?
答案:前者需要把数据从服务器复制到客户端的内存里,然后再从客户端的内存写到服务器上,相当于读+写两个操作。而后者只是从服务器读到客户端内存里,然后写到本地硬盘,相当于网络上只有读操作,这样就快了一些。图17是前者的网络包。

图17
SMB3对此有了本质上的改进,可以完全实现服务器端的本地复制,这样前者反而比后者快了。
常见问题4:在CIFS共享上剪切一个文件,然后粘贴到同一共享的子目录里,为什么就比粘贴到本地硬盘快呢?
答案:在相同的文件系统上剪切、粘贴,本质上只有“rename”操作,并没有读和写,所以是非常快的。请看图18的抓包,该操作是把abc.txt剪切到一个叫\test的子目录。

图18
常见问题5:为什么在Windows 7上启用SMB2之后,读性能提高了很多?
答案:这是因为SMB2 没有SMB那么啰嗦。从图19可见,读之前的查询用了不到10个包,而SMB往往要用数十个包来查询各种信息。

图19
网络江湖
有人的地方就有恩怨,有恩怨的地方就有江湖,IT圈也是如此。过去十几年里,我们见证了摩托罗拉和诺基亚在手机行业的沉浮;微软和苹果在个人电脑领域的竞争;还有Windows和Linux操作系统在数据中心领域的角逐。在以后的岁月里,不知道还有多少业内的腥风血雨等着我们。
俗话说内行看门道,外行看热闹。作为技术人员,我们能看到的明争暗斗比其他人更多,甚至能从协议细节中看到高手过招的痕迹。比如说Windows和Linux之争,也能体现在它们的共享协议CIFS和NFS上。本书之前已经分别解析过它们的工作方式,这里再来探讨它们的历史和发展趋势。
早期CIFS协议的设计比NFS落后不少,甚至可以看到一些“不专业”的痕迹。我个人意见最大的有两点。
• 早期CIFS协议非常啰嗦,这一点在前面的《剖析CIFS协议》一文中已有详解。比如打开一个文件之前竟然需要50多个包的来回,部分网络包如图1所示。
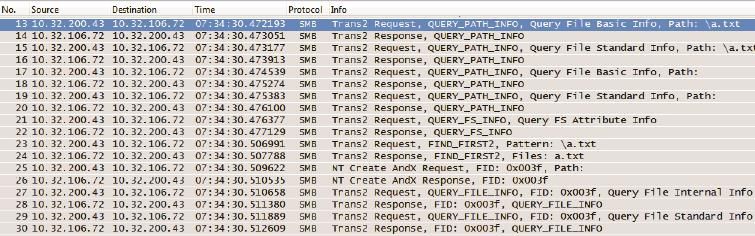
图1
• 早期CIFS协议的读写操作都是同步方式的。如图2所示,它只会在收
到上一个读响应(Read AndX Response)之后,才发出下一个读请求(Read AndX Request)。这种方式的带宽利用率很低,因为很可能TCP发送窗口还没有用完,一个操作就完成了。CIFS的设计人员当时可能没有考虑到网络带宽的快速发展。
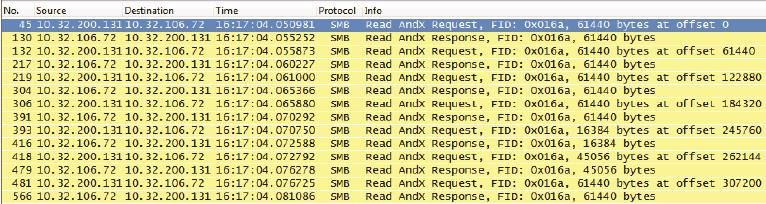
图2
早期的NFS上就没有这个问题,如图3所示,多个读请求被一起发出去了(也可以说是异步的)。

图3
幸好CIFS很快就向NFS学习,等到Windows 7出来的时候,这两个问题都解决了。当然早期的NFS协议也有落后的地方,比如对文件属性的管理过于简单。但到了NFSv4面世的时候,也已经和CIFS趋同了。这些江湖暗斗只有专业人士才能感觉到。
竞争往往能激发意想不到的创造力,这两个协议的新特性就是如此产生的。无论是早期的CIFS还是NFS,每个操作都是在各自的网络包中完成的。即便不太罗嗦的NFS协议在读一个文件之前,也需要通过READDIRPLUS操作获得其File Handle(FH),再通过GETATTR操作获得该File Handle的属性,最后通过ACCESS和READ操作打开文件。图4显示了READ之前的三个操作至少花费了三个RTT(往返时间)。

图4
相比起CIFS,这已经可以算是极简主义了。不过NFSv4中又提出了一个全新的理念,称为“COMPUND CALL”(复合请求)。客户端可以把多个请求放在一个包中发给服务器,然后服务器也在一个包中集中回复,这样就能在一个往返时间里完成多项操作了。
道理听起来似乎很简单,但真正做起来并不容易。以图4中的READDIRPLUS + GETATTR + ACCESS + READ为例,如果用COMPUND方式,发送方在没有收到READDIRPLUS回复之前,怎么知道GETATTR操作应该指定什么File Handle呢?NFSv4用了类似编程时用到的“变量”思维来实现,首先是READDIRPLUS操作所得到的File Handle被作为变量传给GETATTR请求;接着GETATTR操作得到的文件属性又传给ACCESS和READ。变量的传递完全发生在服务器端,所以客户端不需要参与,也就没有来回发包的需要。
图5是一个包含了7个操作请求的NFSv4包,COMPUND方式对效率的提高幅度由此可见一斑。我认为这个思路值得很多应用层协议参考。
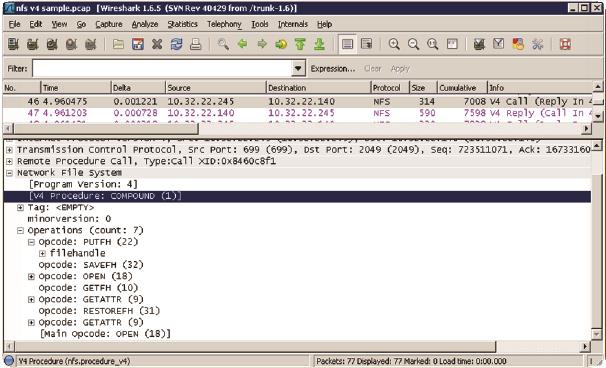
图5
说完NFS的最新进展,我们再回头看看CIFS已经发展成什么样了。虽说现在的微软已经没有当年风光了,但是在对CIFS协议的改进上,绝对称得上亮丽的一笔,在我看来已经远远把NFS抛到脑后了。在Windows 8和Windows 2012所支持的最新CIFS版本SMB3上,出现了很多适应当前需求的革命性创新。
不知道你是否记得《剖析 CIFS 协议》一文中提到的“常见问题3”及其答案?当我通过CIFS复制abc.txt,然后粘贴到同一目录生成abc-Copy.txt时,网络包如图6所示。

图6
这说明复制粘贴过程实际是这样的。
1.客户端发送读请求给服务器。
2.服务器把文件内容回复给客户端(这些文件内容被暂时存在客户端内存中)。
3.客户端把内存中的文件内容写到服务器上的新文件abc-Copy.txt中。
4.服务器确认写操作完成。
在这个过程中,文件内容通过第2步和第3步在网络上来回跑了两次,是很浪费带宽资源的。为此SMB3设计了一个叫“Offload Data Transfer”的功能,能够把过程变成这样。
1.客户端向服务器发送复制请求。
2.服务器给了客户端一张token。
3.客户端利用这张token给服务器发写请求。
4.服务器按要求写新文件。
5.服务器告诉客户端复制已经完成。
图7显示了这两种复制方式的差别,实心箭头表示文件内容的流向。
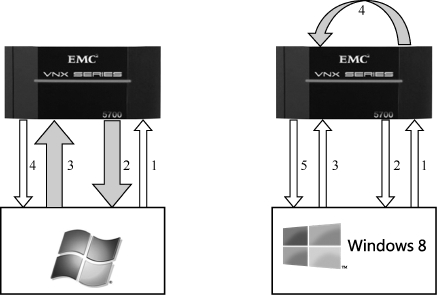
图7
可见在SMB3的复制过程中,我们只是在网络上传输了一些指令,而文件内容并没有出现在网络上,因为复制数据完全由服务器自己完成了。假如是复制一个大文件,那对性能的提升幅度是非常可观的,你甚至可以在数秒钟里复制几个GB的数据,远超网络的瓶颈。在虚拟化的应用场合中,通过这个机制克隆一台虚拟机也可以变得很快。SMB3的另一个破天荒改进是在CIFS层实现了负载均衡。与其他CIFS版本不同,一个SMB3 Session可以基于多个TCP连接。如图8所示,Windows 8服务器上的两个网卡,可以分别和文件服务器上的两个网卡建立TCP连接,然后一个SMB3 Session就基于这两个连接之上。当其中一个TCP连接出现故障,比如网卡坏掉时,SMB3连接还可以继续存在。
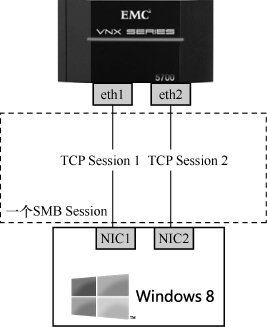
图8
考虑到现在全球化的大公司越来越多,有了很多总部和分部,所以远距离的文件传输就成了大问题。比如说,中国总部的机房中存在一个大文件,从澳大利亚分部访问该文件是非常慢的。尤其是当分部中有很多用户需要访问同一个文件时,相同的内容就需要在有限的带宽中传输多次。SMB3提出了一个叫BranchCache的机制来解决这个问题。当澳大利亚分部的第一个用户访问该文件时,文件从中国传输过去,然后就被缓存起来(比如存到分部的专用服务器上)。接下来澳大利亚分部如果有其他用户访问该文件,就可以通过文件签名从缓存服务器上找到了。
这个机制听上去有点“脑洞大开”的意思,不过我在实验室中实施过这个功能,用户体验还是非常好的,当然也增加了实施和购买专用服务器的开支。
最后不得不提的是SMB3的一个“Continuous Availability”特性。以前很多厂商的文件服务器号称支持Active/Standby(当前待机)模式,即文件服务器的两个机头共享硬盘,当一个机头宕机时,能即时切换到待机的机头上。“即时”这个词实际上是有虚假宣传嫌疑的,因为SMB3之前的CIFS版本把文件锁之类的信息放在机头的内存中,新的机头起来时无法获得这些信息,所以是没办法无缝地提供访问的,必须让客户端重新访问一次。
SMB3对此的解决方案是把文件锁之类的信息存到硬盘上,所以新机头起来时便可以获得这些信息,这样,提供无缝服务就成了一种可能。为了方便理解,我也做了一个示意图,如图9所示。
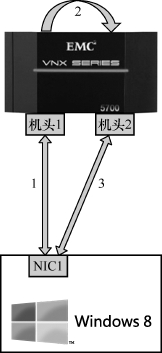
图9
1.Windows 8客户端通过机头1访问文件,生成的文件锁等信息被保存在硬盘中。
2.机头1发生故障,切换到机头2上,机头2从硬盘中获取信息。
3.Windows 8仍然能锁定该文件,因为机头2继承了机头1的信息。
DNS小科普
有一些技术,人们即便每天都在使用,也未必能意识到它的存在。
DNS就是这样一种技术。当我在浏览器上输入一个域名时,比如www.example.com,其实不是根据该域名直接找到服务器,而是先用DNS解析成IP地址,再通过IP地址找到服务器。有时候甚至不用输入任何域名,也会在不知不觉间用到DNS。比如打开公司电脑,用域账号登录操作系统,就是依靠DNS找到Domain Controller来验证身份。毫不夸张地说,如果有一天突然失去DNS,世界会立即陷入混乱。
我家里的笔记本IP为192.168.1.101,DNS服务器IP为106.186.28.239。如果在打开www.example.com的过程中抓了包,就能看到图1所示的解析过程。

图1
笔记本:“请问www.example.com的A记录是什么?”
服务器:“是93.184.216.119。”
获得IP之后,笔记本就可以和93.184.216.119建立HTTP连接了。这个例子中提到的A(Address)记录,指的是从域名解析到IP 地址。如果你经常处理DNS包,还会看到不少其他类型的记录。
• PTR记录 :与A记录的功能相反,它能从IP地址解析到域名。PTR有什么作用呢?比如IT部门发现最近公司里的机器10.32.106.47和YouTube之间数据流量很大,用nslookup一查PTR记录就知道原来是阿满在上班时间偷看视频了(见图2)。
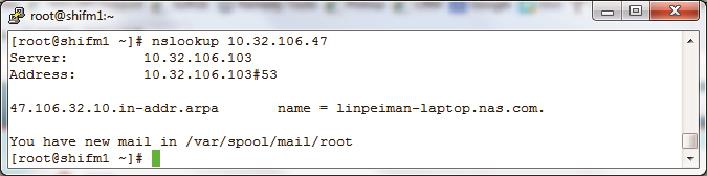
图2
网络包显示如下(见图3):
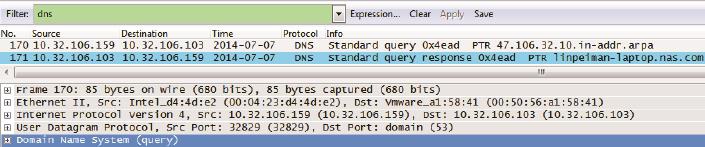
图3
• SRV记录 :Windows的域管理员要特别关心SRV记录,因为它指向域里的资源。比如我想知道我们公司的域nas.com里有哪些DC,只要随便在一台电脑上查询_ldap._tcp.dc._msdcs.nas.com这个SRV记录就可以了。如果你也想查贵司的DC,请把nas.com改成正确域名即可。图4是查询过程的截图。

图4

图5
• CNAME记录 :又称为Alias记录,就是别名的意思。比如我的服务器10.32.106.73同时提供网页(www)、邮件(mail)和地图(map)服务。图6是该服务器在DNS中的配置,其中www的A记录指向了10.32.106.73,还有两个别名记录mail和map指向了www。客户端访问这3个域名时,都会被定向到10.32.106.73上面。
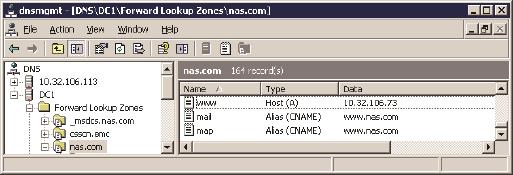
图6
别名是如何起作用的呢?当客户端查询mail.nas.com或者map.nas.com时,DNS服务器通过www.nas.com找到10.32.106.73,然后把结果返回给客户端。图7是访问mail.nas.com时抓的包。

图7
那直接把10.32.106.73配给mail和map可以吗?当然是可以的,但如果某天要改变这个IP地址,就不得不在DNS上修改www、mail和map这3项记录了。而在使用别名的情况下,只要修改www一项的IP就行了,mail和map都没有必要改动。别名的使用节省了管理时间,站长们应该会喜欢这个功能。
了解完DNS的基本功能之后,我们再来看看它的工作方式。
刚才说到我的笔记本在解析www.example.com时用到了DNS服务器106.186.28.239。其实这台服务器非常可疑,因为我查到它属于美国一家私有云提供商,不知道通过什么方式配到我电脑上的。世界上还有很多这样不权威的DNS服务器,就连电信和有线通等宽带提供商的DNS服务器也是不权威的。所谓“不权威”,并不是指它们一定不值得信任,而是因为它们本身不包含DNS的注册信息。当收到新的DNS查询时,它们要从权威DNS服务器(属于一个叫ICANN的非营利性组织)那里查到结果,然后再返回给客户端。
从本文的第一个抓包中,我们只知道不权威DNS服务器成功解析了www. example.com,却不知道它是怎么做到的。有可能是它收到我的请求之后,悄悄地查询了权威DNS服务器,然后告诉我答案。这种工作方式称为递归查询,其特点是客户端(我的笔记本)完全依赖服务器(那台可疑的DNS服务器)直接返回结果。
除了递归之外,还有一种叫迭代查询的方式,其特点是客户端先查到根服务器的地址,再从根服务器查到权威服务器,然后从权威服务器查……直到返回想要的结果。用dig命令加上“+trace”参数可以强迫客户端采用迭代查询。图8就是查询的整个过程。可见迭代查询要比递归查询麻烦得多,但最后解析到的结果倒是一致的。
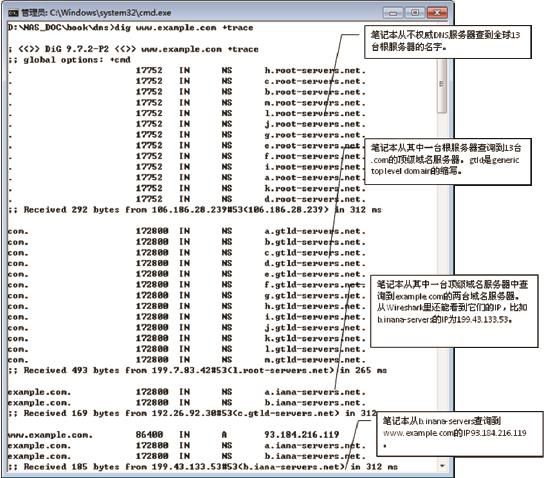
图8
这个迭代查询的网络包如图9所示。从中可以看到笔记本192.168.1.101发出了7个查询,才得到最终的结果。
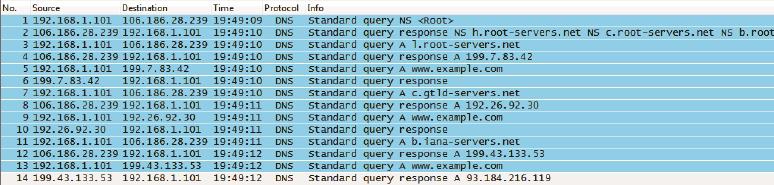
图9
如果这两个抓包还不足以说明递归和迭代的差别,我们可以用生活中的例子来类比。
• 递归查询 :老板给我发个短信:“阿满,附近哪个川菜馆最正宗?”我屁颠屁颠地去问我的吃货朋友二胖,二胖又问了他的女友川妹子;川妹子把答案告诉二胖,二胖再告诉我,最后我装作很专业的样子回复了老板。这个过程对老板来说就是递归查询。
• 迭代查询 :老板说:“阿满,推荐一下附近的洗脚店呗?”我立即严辞拒绝:“这个我不知道,不过你可以问问公关部的张总。”老板去找到张总,又被指引到销售部的小李,最终从小李那里问到了。这个过程就是迭代查询,因为是老板自己一步一步地查到答案。
说完DNS的工作方式,我们再来认识它的一个很有用的特性。我的DNS中有两个叫“Isilon-Cluster”的同名A记录,分别对应着IP地址10.32.106.51和10.32.106.52。当我连续执行两次“nslookup Isilon-Cluster.nas.com”时,抓到的网络包如图10所示。

图10
可见两次返回的IP地址是一样的,但顺序却是相反的。如果我执行第三次 nslookup,结果又会跟第一次一样,这就是DNS的循环工作(round-robin)模式。这个特性可以广泛应用于负载均衡。比如某个网站有10台Web服务器,管理员就可以在DNS里创建10个同名记录指向这些服务器的IP。由于不同客户端查到的结果顺序不同,而且一般会选用结果中的第一个IP,所以大量客户端就会被均衡地分配到10台Web服务器上。随着分布式系统的流行,这个特性的应用场景将会越来越多,比如本例中的分布式存储设备Isilon。
说了这么多DNS的好话,那它有没有缺点呢?当然有,而且还不少。
• 就像雕牌洗衣粉被周佳牌模仿一样,DNS上也存在山寨域名。比如招商银行的域名是www.cmbchina.com,但是www.cmbchina.com.cn和www.cmbchina.cn却不一定属于招行。如果这两个域名被指向外表和招行一样的钓鱼网站,就可能会骗到部分用户的银行账号和密码。
• 如果DNS服务器被恶意修改也是很危险的事情。比如登录招行网站时虽然用了正确域名www.cmbchina.com,但由于DNS服务器是黑客控制的,很可能解析到一个钓鱼网站的IP。
• 即便是配了正规的DNS服务器,也是有可能中招的。比如正规的DNS服务器遭遇缓冲投毒之后,也会变得不可信。
• DNS除了能用来欺骗,还能当做攻击性武器。著名的DNS放大攻击就很让人头疼。下面是我在执行“dig ANY isc.org”(解析isc.org的所有信息)时抓的包,可见6号包发出去的请求只有25字节(见图11底部的Length: 25),而11号包收到的回复却能达到3111字节(见图12底部的Length 3111),竟然放大了124倍。
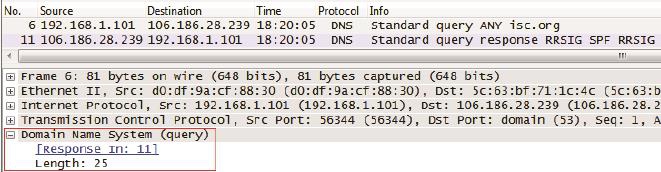
图11
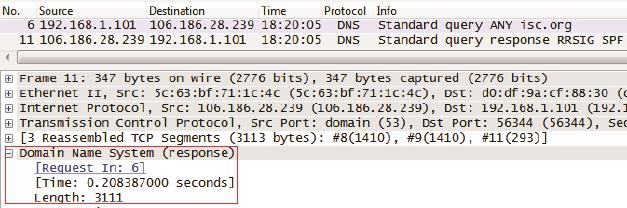
图12
假如在6号包里伪造一个想要攻击的源地址,那该地址就会莫名收到DNS服务器3111字节的回复。利用这个放大效应,黑客只要控制少量电脑就能把一个大网站拖垮了。
一个古老的协议——FTP
你也许难以想象,FTP协议在1971年就出现了。在那时,现代的网络模型还没有形成,所以FTP完全称得上网络界的活化石。
它的发明人也很有意思,是印度工程师Abhay Bhushan。要知道早期的网络协议起草者几乎是清一色的欧美工程师,Bhushan能够占得一席之地绝对称得上传奇。虽然看起来文质彬彬,但实际上Bhushan热爱运动,尤其擅长马拉松和铁人三项(我印象中计算机科学之父Alan Turing也是位长跑健将)。
一个古老的协议能有如此活力,一定是有深层原因的。FTP的过人之处,就在于它用最简单的方式实现了文件的传输—客户端只需要输入用户名和密码,就可以和服务器互传文件了;有的甚至连用户名和密码都不用(匿名FTP)。FTP常被用来传播文件,尤其是免费软件;另一个广泛应用是采集日志,我们可以让服务器发生故障之后,自动通过FTP把日志传回厂商。这些场合之所以适合FTP而不是NFS或者CIFS,就是因为它实现起来更加简单。
一个软件使用起来简单,并不意味着它的底层设计也很简单。如果你抓了一个FTP的网络包,乍一看会觉得非常复杂,尤其是在端口号的管理上。在我的实验室中,我从Windows客户端登录了一次FTP服务器,然后下载了一个叫linpeiman.txt的文件。我们先来看看登录的过程(见图1)。
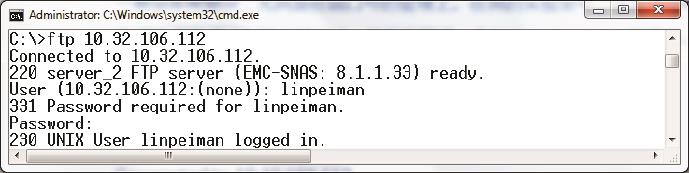
图1
接下来看看登录过程的网络包,前三个包无需解析(见图2),就是由客户端发起的三次握手。唯一值得记住的是FTP服务器的控制端口21。

图2
现在来分析5、7、8、10、11号包的过程(见图3)。

图3
5号包:
服务器:“我准备好接受访问啦,顺便说一下我是一台EMC公司的存储,版本号8.1.1.33。”
7号包:
客户端:“我想以用户名linpeiman登录。”
8号包:
服务器:“那你把linpeiman的密码告诉我。”
10号包:
客户端:“密码是123456。”
11号包:
服务器:“密码正确,linpeiman登录成功。”
从以上分析可见,FTP是用明文传输的,连我的密码123456都可以被Wireshark解析出来。如果对安全的要求非常高,就不能采用这种方式。接下来再看下载文件的过程(见图4)。
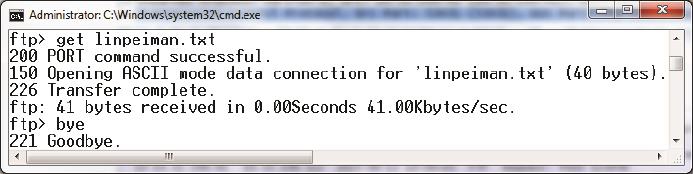
图4
现在分析下载过程的网络包(见图5)。

图5
13号包:
客户端:“我想从IP=10.32.200.41,端口为208×256+185=53433连接你的数据端口(公式中的256为约定好的常数)。”
14号包:
服务器:“可以的,我同意了。”
15号包:
客户端:“那我想下载文件linpeiman.txt。”
22号包:
服务器:“给你传了。”
上面这些包并没有真正传输文件内容,我们接着看(见图6)。

图6
16、17、18号包也是三次握手,不过这次发起者是FTP服务器。服务器的端口号采用了20,客户端的端口则为之前协商好的53433。
19号包:
服务器:“给你文件内容(文件内容“Life is tough. Wireshark makes it easy.”可见于图6中的底部)。”
20、21、23、24号包为四次挥手过程,表示数据传输结束,TCP连接关闭了。
从以上分析可见,客户端连接FTP服务器的21端口仅仅是为了传输控制信息,我们称之为“控制连接”。当需要传输数据时,就重新建立一个TCP连接,我们称之为“数据连接”。随着文件传输结束,这个数据连接就自动关闭了。不但在下载文件时如此,就连执行ls命令来列举文件时,也需要新建一个数据连接。在我看来这不是一种高效的方式,因为三次握手和四次挥手就用掉7个包,而ls命令的请求和响应往往只需要2个包,就像开着卡车去送快递一样不经济。图7显示了这个例子的两个连接情况。
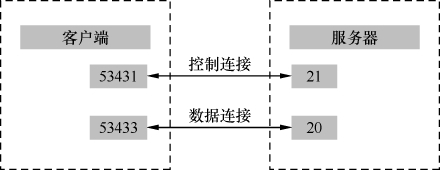
图7
我花了很长时间来思考Bhushan先生为何把FTP的控制连接和数据连接分开 来,不过至今还是不能领悟。我唯一能想到的好处是连接分开后,就有机会在路由器上把控制连接的优先级提高,免得被数据传输影响了控制。举个例子,当文件下载到一半时我们突然反悔了,就可以Abort(终止)这次下载。如果Abort请求是通过优先级较高的控制连接发送的,也许能完成得更加及时。当然我的猜测可能是错的,20世纪70年代的路由器也许根本不支持优先级。
如果你为FTP配置过防火墙,还会发现这种方式带来了一个更加严重的问题—由于数据连接的三次握手是由服务器端主动发起的(我们称之为主动模式),如果客户端的防火墙阻挡了连接请求,传输不就失败了吗?碰到这种情况时,我建议你试一下FTP的被动模式。图8是在被动模式下抓到的包。由于被动模式的登录过程和主动模式一样,所以我们从登录后开始讲起。

图8
24号包:
客户端:“我想用被动模式传输数据。”
25号包:
服务器:“你可以连接到IP=10.32.106.112,端口号为240×256+217=61657(公式中的256为约定好的常数)。”
29号包:
客户端:“我想下载linpeiman.txt。”
30号包:
服务器:“给你传了。”
上面这些包并没有真正传输文件内容,我们接着看(见图9)。
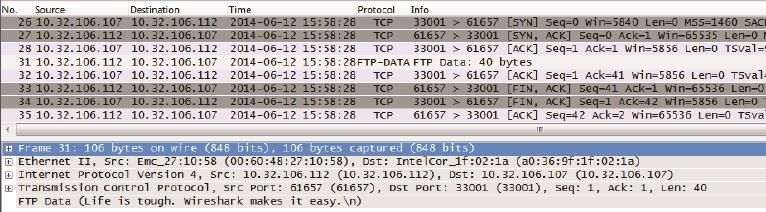
图9
26、27、28号包是数据连接的三次握手,可见这一次由客户端主动发起(所以对服务器来说是被动的),连接的服务器端口为之前协商好的61557。
31、32、33、34、35号包完成了文件内容的传输,然后关闭数据连接。同样从图9底部可以见到该文件的内容:Life is tough. Wireshark makes it easy.
最后我在FTP命令行中打了个“bye”命令(见图10)。

图10
Goodbye过程的网络包如图11所示。

图11
39号包:
客户端:“我要退出啦。”
40号包:
服务器:“好的,Goodbye!”(FTP是我所知道最讲礼仪的协议。)
41、42、43、44号包是四次挥手过程,断开控制连接,完成了一次FTP的生命周期。
你也许想问,那如何指定客户端采用主动还是被动模式呢?很多FTP客户端软件都有这个选项。比如图12是WinSCP上的截图,选中Passive mode即表示被动模式。
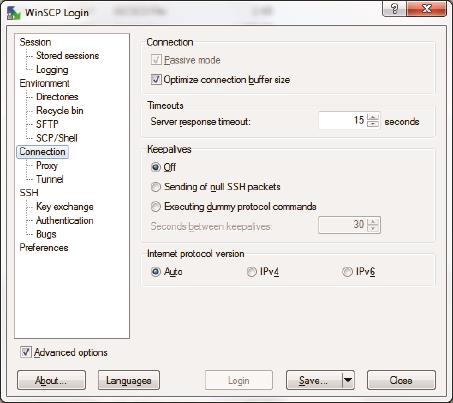
图12
理论上所有FTP客户端都应该支持这两种模式,但Windows自带的ftp命令似乎只支持主动模式。图13是我试图采用被动模式的命令。
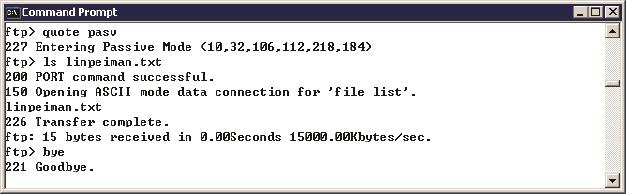
图13
从图13中看,当我输入“quote pasv”命令时,的确显示进入被动模式(Entering Passive Mode)。接下来我们看看图14的网络包。12号和13号包也的 确显示进入被动模式,但是再接下来的网络包却完全是主动模式的样子。
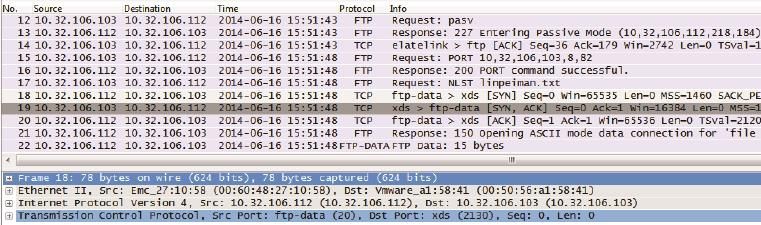
图14
从结果看,12号和13号包完全没有起作用。这很可能是Windows的一个bug,我在Windows 7和Windows 2003都看到了相同的结果。那微软的测试部门为什么没有发现呢?如果没有用Wireshark来抓包检查,测试人员是很难测出这个问题的,我也是在写这篇文章的时候碰巧看到。从这个不经意的发现,就可以知道Wireshark的价值。
上网的学问——HTTP
2012年7月27日,伦敦奥运会开幕式上,一位长者带着上世纪才能见到的老式电脑出现了。他发布了一条推特—“This is for everyone”,随即显示在体育馆的大屏幕上,传遍世界(见图1)。
图1
他就是57岁的Tim Berners-Lee爵士——万维网的发起者,也是第一位实现HTTP的工程师。英国人不但借此传播了开放和分享的互联网精神,也展示了其在IT历史上的地位—从奠定现代计算机基础的Alan Turing,到发明分组交换的Donald Davies,再到万维网之父Tim Berners-Lee,每一个重大环节都有英国人的参与。假如北京奥运会上也要推出我们的IT界代表人物,我想大家心中已有合适的人选,他也可以在台上尝试发一条推特。
Tim所实现的HTTP便是我们今天浏览网页所用的网络协议。他当年建立的网站至今还能访问,域名为http://info.cern.ch/。虽然这个页面已经更新过,但我们还可以在http://www.w3.org/History/19921103-hypertext/hypertext/WWW/News/9201.html看到当年的内容。
HTTP的工作方式算不上复杂,先由客户端向服务器发起一个请求,再由服 务器回复一个响应。根据不同需要,客户端发送的请求会用到不同方法,有GET、POST、PUT和HEAD等。比如在网站上登录账号时就可能用到POST方法。
我在打开网页http://www.rfc-editor.org/info/rfc2616时抓了包,我们就以此为例,来看看HTTP是如何工作的(见图2)。

图2
1.由于HTTP协议基于TCP,所以上来就是三次握手。从图2的底部可以看到,服务器的端口号为80。
2.在图3中,4号包是客户端向服务器发送的“GET /info/rfc2616 HTTP1.1”请求,即通过1.1版的HTTP协议,获取/info目录里的rfc2616文件。说白了就是想下载页面内容。

图3
3.7号包是服务器对该请求的响应,即把/info/rfc2616的内容发给客户端。
4.9号包是客户端向服务器请求“GET /style/rfc-editor.css”。该css文件定义了页面的格式。
5.11号包是服务器对该请求的响应,把/style/rfc-editor.css的内容发给客户端。
就这样,客户端通过两个GET方法得到了页面内容和格式,从而打开了网页。如果点开每一个HTTP包前的+号,还能看到其协议头和详细信息。以4号包为例,它的HTTP协议头在Wireshark中如图4所示。其包含的信息大概可以归纳为:我要通过1.1版的HTTP协议,从服务器www.rfc-editor.org的/info目录里得到rfc2616的内容。
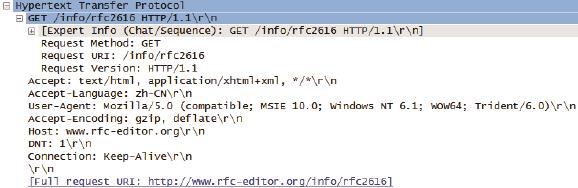
图4
HTTP算不上一个复杂的协议,出问题的时候也能在浏览器上看到错误信息,所以我们用到Wireshark的机会并不多。不过随着技术的进步,HTTP越来越多地应用到不需要浏览器的场景中,比如现在如火如荼的云存储技术就有Wireshark的用武之地。
由于海量文件不适合传统的目录结构,所以云存储一般使用对象存储的方式—客户端访问文件时并不使用其路径和文件名,而是使用它的对象ID。身份验证也是通过HTTP协议实现的。工程师们处理此类问题时就能用上Wireshark了。图5是Wireshark解析后的HTTP读文件过程(只要在Wireshark上右键单击其中一个包,在弹出的菜单中选择“Follow TCP Stream”就可以打开这个窗口)。我们可以从中看到该文件的对象ID“59J5T5KV78EP0e7AJIV55UO93DVG4140QGQQ000ED7PR8EJH3OGUV”,还有身份验证时用到的用户名“paddy”和加密后的密码。我们甚至可以看到服务器回复的文件内容“I am Paddy Lin…”在这个过程中一旦发生问题,比如身份验证出错了,都能从Wireshark中看到。
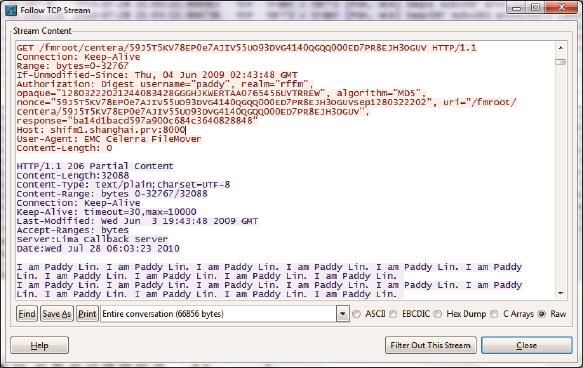
图5
上面两个例子都用到了GET方法,因为它是最常用的。事实上HTTP协议最早的版本就只支持GET,Tim开发的第一个网页也是如此。这在今天的开发者看来简直是小菜一碟,甚至给人一种“时无英雄”的错觉。但如果放眼整个IT历史,现在看起来很了不起的技术都是从简单发展而来的。以云存储为例,底层用到的技术并不新颖,但组合起来的云概念就是科技前沿了。
用Wireshark来解决HTTP问题是很痛快,因为整个通信过程一览无遗。但仔细一想却叫人直冒冷汗—如果连传输的文件内容都可以清楚地看到,那我上网时的聊天记录,甚至密码是否也会被发现?很不幸,答案是肯定的。如果没有使用加密软件,那么黑客(或者你的领导)就可以从网络包中看到你上班时聊了些什么,在哪些帖子上祝福楼主一生平安,搜索了什么关键词,甚至知道你登录论坛的用户名和密码。
图6是我在Google上搜索时抓的包。从4号包可以看到我用到的关键词“Max is the best boss in the world”(Max是我老板的名字,希望他此时正在监控我的网络)。如果IT部门把这类包收集起来,就能统计出员工们上班时都在搜索什么,再通过IP地址还能查到每一项是谁搜的。

图6
至于更敏感的用户名和密码,这里也有个血淋淋的例子。我在登录www.mshua.net(这是我经常登录的园艺论坛)时抓了包。当客户端用POST方法把用户名和密码传给服务器时,已经在网络上暴露了身份。请看图7底部的用户名“username=wiresharktest”和密码“password=P@ssw0rd”,可以想见这个明文账号和密码随时可能落入坏人手中。事实也是如此,上个月我登录时,就发现几位平时一本正经的网友在发成人图片,显然他们的密码已经被盗了。为了防止好奇的读者用这个账号浏览不健康信息,我已经把密码改掉了。

图7
那要如何保护自己的信息呢?HTTPS就是一个不错的选择。比如用Google搜索时在http后加个s,变成https://www.google.com.hk/,就不用担心老板知道你在搜些什么了。图8就是使用HTTPS搜索时抓的包,注意服务器端口是443,关键词也被加密到了“Encrypted Application Data”里。
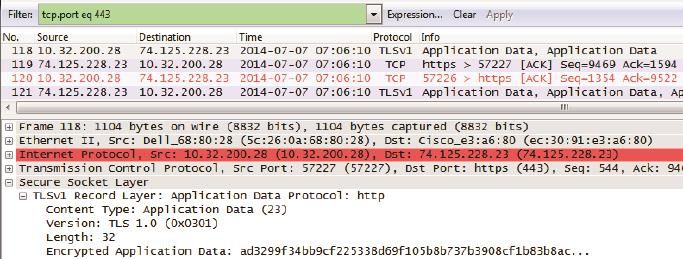
图8
大多数人并不需要理解HTTPS的加密算法,所以本文将不在此多费笔墨(其实是因为我自己也不懂)。但因为加密包会给诊断问题带来不少障碍,所以管理员有必要知道如何对它进行解码。图9是4个HTTPS包,我们除了能看到“Application Data Protocol”是HTTP之外,几乎对它们一无所知,因为所有信息都被加密了。

图9
要对这些加密包进行解码,只需要以下几个步骤(本例所用的网络包和密钥来自http://wiki.wireshark.org/SSL 上的snakeoil2_070531.tgz文件,建议你也下载来试试)。
1.解压snakeoil2_070531.tgz并记住key文件的位置,比如C:\tmp\rsasnakeoil 2.key。
2.用Wireshark打开rsasnakeoil2.cap。
3.单击Wireshark的Edit-->Preferences-->Protocols-->SSL-->RSA keys list。然后按照IP Address,Port,Protocol,Private Key 的格式填好,如图10所示。

图10
4.单击OK,这些包就成功解码了。图11就是这4个包解码后的样子,两个GET方法都可以看到。
图11
既然HTTPS包能被解码,是不是说明它也不安全呢?事实并非如此,因为解码所用到的密钥只能在服务器端导出。不同的服务器操作步骤有所不同,比如IIS服务器就可以参考这一篇文章:http://www.packetech.com/showthread.php?1585-Use-Wireshark-to-Decrypt-HTTPS。
你的老板有可能潜入Google导出密钥吗?我相信我老板做不到。
无懈可击的Kerberos
在古希腊神话中,冥界的大门由一头烈犬看守。此犬长有三个头,兢兢业业地守在冥河边,从没有灵魂能在它醒着的时候逃离。这头烈犬就是Kerberos,安全守卫的象征。古希腊人下葬时要放好蜜饼,就是为了讨好它。现代游戏里也有它的英姿,比如《英雄无敌》里以一敌多的地狱烈犬。
本文要介绍的身份认证协议也叫Kerberos,它有着非常广泛的应用,比如Windows域环境的身份认证就会用到它。我们用域账号登录电脑,就在不知不觉间完成了一次Kerberos认证过程。
Kerberos的认证结果是双向的—当账号A访问资源B时,不但B要确保A并非冒充,而且A也要查明B不是假货。我们一般只知道前者,比如前文提到的CIFS服务器就要在Session Setup中对造访者验明正身。后者则很少被提及,因为人们一般不会怀疑自己要访问的资源是假的。其实后者还是很有必要的,举一个例子:如果你老板伪造了一台网络打印机,但是你没法确认它的真假,就可能把求职信打到他办公室里去,然后就真的得出去求职了。西游记中其实也出现需要相互认证的场景,比如如来佛祖要认出假冒的访问者六耳猕猴,唐僧师徒也要识别山寨的“资源”小雷音寺。
双向认证的方式不止一种,最简单的做法是互报密码。这个过程就像电影中用暗号接头。A说:“江南风光好”,B说:“遍地红花开”。如果双方都核对无误,就可以激动地握手“同志,我可找到你了!”假如其中一方报错暗号,则接头失败。这种方式的弊端很多,最大的问题是不方便管理。比如在一个数百名员工共享几百台机器的环境中,当新加入一名员工时,就得在几百台机器上更新账号信息。相信没有管理员能忍受这样的环境。
有没有办法做得更好呢?Kerberos采用的方法是引入一个权威的第三方来负 责身份认证。这个第三方称为KDC,它知道域里所有账号和资源的密码。假如账号A要访问资源B,只要把KDC拉出来证明双方身份就行了。在这种机制下,A 和B都没必要知道对方的密码,完全依赖KDC就可以。
原理说起来简单,通过程序实行起来可就难了。事实上由于Kerberos过于复杂,从来没有一位技术作家能把它简单地表述出来。最文艺的Kerberos诠释当属麻省理工学院编的一出话剧,搜索一下“Kerberos 四幕话剧”就能找到它,但其实理解这话剧还是不容易。幸好有了Wireshark之后,可以使Kerberos的认证过程变得清晰很多。在下面的实验中,账号A是我的域账号linp1,资源B是一台叫CAVA的Windows服务器。账号A访问资源B其实就是linp1登录CAVA的过程。
第一步,账号A和KDC互相认证。
这可以看成一道有趣的小学奥数题:已知世界上只有A和KDC知道A的密码,如何利用该密码互相证明自己的身份?你也许会想到孔明和周瑜在手心对字,直接向对方亮出A的密码。但在网络环境中不能这样做,因为如果其中一方是假的,不就被套到真密码了吗?既要做到不说出密码,又要让对方知道自己拥有密码,应该怎样实现?Kerberos自有一套严密的办法。
1.账号A利用hash函数把密码转化成一把密钥,我们称它为Kclt。
2.用Kclt把当前时间戳加密,生成一个字符串。我们用“{时间戳} Kclt”来表示它。
3.把上一步生成的字符串“{时间戳} Kclt”、账号A 的信息,以及一段随机字符串发给KDC。这样就组成了Kerberos的身份认证请求AS_REQ。我们用下面这个公式来表示这个请求。AS_REQ =“{时间戳} Kclt”,“账号A的信息”,“随机字符串”
如图1所示,我实验室中的账户名字为linp1,本次生成的随机字符串是136224786。
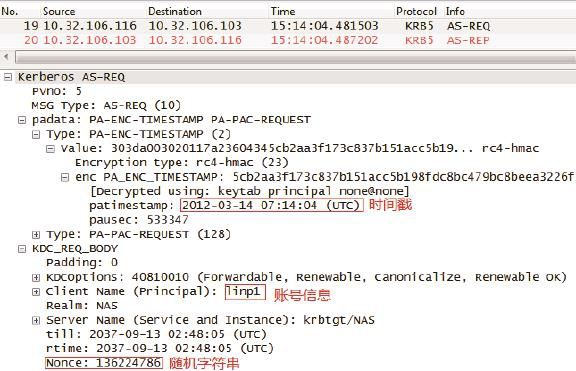
图1
4.KDC收到AS_REQ之后,先读到账号A的信息“linp1”,于是便调出A的密码,再用同样的hash函数转化为Kclt。有了Kclt就可以解开“{时间戳} Kclt”了,如果能解开则说明该请求是由账号A生成的,因为其他账号不可能有Kclt可以加密。
Kerberos为什么要选用时间戳来加密,而不是其他呢?原因就是黑客可能在网络上截获字符串“{时间戳} Kclt”,然后伪装成账户A来骗认证。这种方式称为重放攻击。重放攻击的伪装过程需要一段时间,所以KDC把解密得到的时间戳和当前时间作对比,如果相差过大就可以判断是重放攻击了。假如采用与时间无关的字符来加密,则无法避开重放攻击,这就是我们必须在域中同步所有机器时间的原因。
5.接下来轮到KDC向账号A证明自己的身份了,上文提到的随机字符串就用在这里。理论上KDC只要用Kclt加密随机字符串,再回复给账号A就可以证明自己的身份了。因为假的KDC是没有Kclt的,账户A拿到回复之后解不出那个随机字符串,就知道KDC有假。
总结以上过程,账号A和KDC都没有向对方发送密码,所以即便一方是假的也不会泄露信息。而如果双方都是真的,则实现了互相认证,可以算是完美了。不过这个机制下的KDC会非常忙碌,假设每次认证都得调出账号密码、hash、解 密……而且每个客户端一天可能要验证数十次,那域中就得配备大量的KDC才负担得起。有没有办法进一步改进呢?Kerberos为此设计了一个精巧的方法。
a.KDC生成两把一样的密钥Kclt-Kdc,作为以后账户A和KDC之间互相认证之用,这样就省去了调出账号A的密码和hash等工作。按理说其中一把Kclt-Kdc要发给账户A保管,另一把由KDC自己保管。但是保管密钥对忙碌的KDC来说也是一个负担,所以它决定委托给账户A保管,以后账号A每次需要KDC的时候,再把这把密钥还回来。这个办法听上去不太靠谱,万一有个假冒的账户A交回来一把假密钥怎么办?为了避免这个问题,KDC把自己的密码hash 成Kkdc,然后用它加密那把委托给A的密钥。Kerberos里把这个委托的密钥称为TGT(Ticket Granting Ticket),可以用下面的公式来表示。
TGT = {账户A相关信息,Kclt-kdc} Kkdc
有了这个委托保存的机制,KDC只需记得自己的Kkdc,就能解开委托给所有账号的TGT,从而获得与该账号之间的密钥。通过这个机制,KDC的工作负担就大大降低了。
总结下来,KDC回复给账户A 的AS_REP应包含以下信息(见图2)。
AS_REP=TGT, {Kclt-kdc,时间戳,随机字符串}Kclt
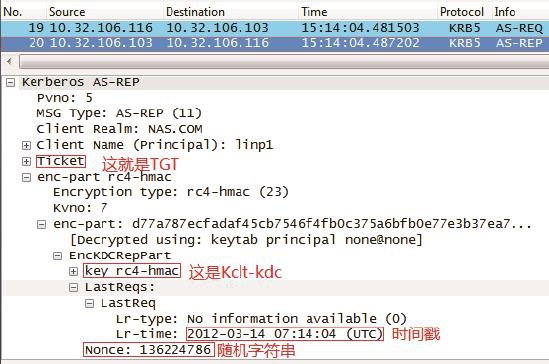
图2
b.账户A收到AS-REP之后利用Kclt解密“{Kclt-kdc,时间戳,随机字符串} Kclt”。通过解开来的随机字符串和时间戳来确定KDC的真实性,然后把Kclt-kdc 和TGT保存起来备用。
第二步,账号A请KDC帮忙认证资源B。
1.这时应该发什么给KDC呢?首先TGT是肯定要交还给KDC的,其次还有账户A的相关信息、当前时间戳,以及要访问的资源B的信息(见图3)。这个请求在Kerberos 中称为TGS-REQ,可以用下面的公式表示。
TGS_REQ = TGT,{账户A相关信息,时间戳}Kclt-kdc,“资源B相关信息”
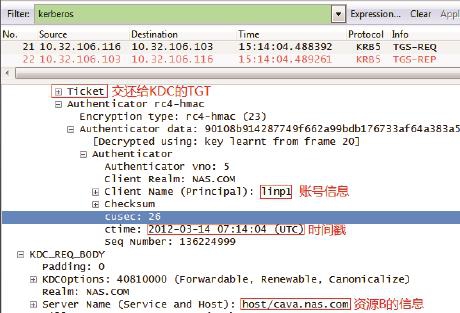
图3
2.KDC收到TGS-REQ之后,先用Kkdc解密TGT得到Kclt-kdc,再用Kclt-kdc解密出账号A的相关信息和时间戳来验证其身份。一旦认定账号A为真,就要想办法帮助A和B互相认证了。
3.KDC生成两把同样的密钥供A和B之间使用,我们就称这个密钥为Kclt-srv吧。其中一把密钥直接交给账号A,另一把委托A转交给资源B。为了确保A不会受到假的资源B所骗,Kerberos把B的密码hash成Ksrv,然后用它加密那把委托A转交给B的Kclt-srv,成为一张只有真正的B能解密的Ticket。总结起来,KDC给账号A的回复可以表示如下(见图4)。
Ticket = {账号A的信息,Kclt-srv}Ksrv
TGS_REP = {Kclt-srv}Kclt-kdc, Ticket
这里的“账号A的信息”可不仅仅包括名字,连A所在的Domain Groups都包含在里面。所以如果A属于很多个groups,TGS_REP包会非常大。
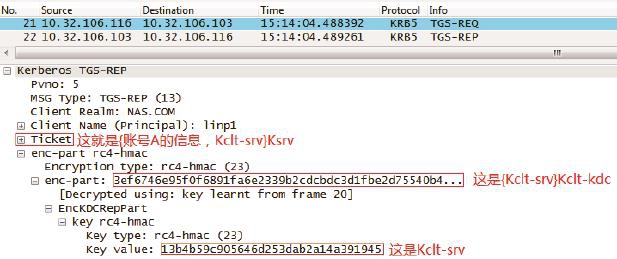
图4
4.账号A收到TGS_REP之后,先用Kclt-kdc解开{Kclt-srv}Kclt-kdc,从而得到Kclt-srv。Ticket留着发给资源B。接下来如果需要多次访问资源B,都可以使用同一个Ticket,而不需要每次都向KDC申请,这也大大降低了KDC的负担。
第三步,账号A和资源B互相认证。
1.到这一步就简单了。账号A给资源B发送“{账号A的信息,时间戳} Kclt-srv”以及上一步收到的Ticket。这个请求称为AP_REQ。
AP_REQ = “{账号A的信息,时间戳} Kclt-srv”,Ticket
2.如果资源B是假的,它是解不开Ticket的。如果资源B是真的,它可以用自己的密码生成Ksrv来解开Ticket,从而得到Kclt-srv。有了Kclt-srv就可以解开“{账号A的信息,时间戳} Kclt-srv”部分。这样资源B就可以确定账号A为真,然后 回复AP_REP来证明自己也是真的。
AP _REP = {时间戳}Kclt-srv
3.账号A利用Kclt-srv来解密AP_REP,再通过得到的时间戳来判断对方是否为真。
第三步是抓不到网络包的,因为这个实验过程是用户linp1登录Windows服务器CAVA,第三步没有发生在网络上。假如接下来用户linp1访问CAVA之外的其他资源,比如访问网络共享,我们就能在Session Setup里找到AP_REQ和AP_REP了。如图5所示,我在Session Setup AndX Request包中点开Security Blob,就把AP_REQ显示出来了。
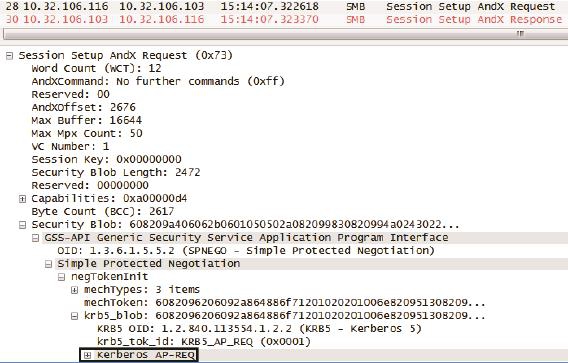
图5
如果这是你第一次认识Kerberos,我估计已经看得云里雾里了。请相信这是人类的正常反应,我给好几批工程师培训过Kerberos,几乎没有人能很快理清楚的。图6是整个认证过程的流程图,也许对理解会有所帮助。
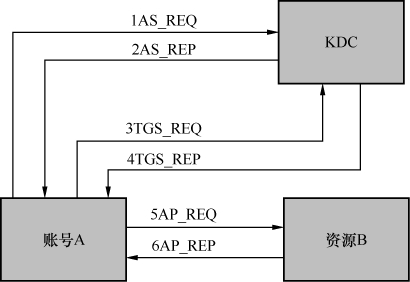
图6
当你完全理解Kerberos之后,可能会意识到一个问题:不对啊,那么多加密 信息都被Wireshark显示出来了,还有 什么安全可言?其实我是用linp1的密码生成了一个keytab文件,再用它来解密的。具体操作如下。
1.参照Wireshark的官方说明生成keytab文件,步骤请参考http://wiki. wireshark.org/Kerberos。
2.把这个文件和网络包放到同一个目录里。
3.打开Wireshark的Edit-->Preferences-->Protocols-->KRB5菜单,在图7所示的窗口勾上两个选项,然后输入keytab文件的名字。
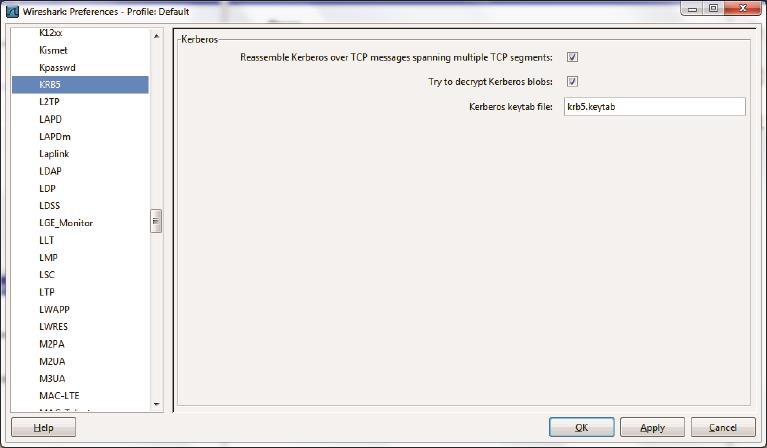
图7
4.打开网络包,就能看到解密后的内容了。
这也是我喜欢Wireshark的原因之一,即使像Kerberos这么复杂的协议,它也能完全解析出来。这简直是域管理员的福音。我稍作回忆,就能想到很多处理过的Kerberos相关例子。
案例1:某客户可以用“\\<IP地址>”访问某文件服务器,但用了“\\<域名>”则不能访问。
用了Wireshark抓包才知道,客户端用IP访问时用了NTLM作身份验证,而用域名访问时则用Kerberos。由于两种验证方法机制不同,所以结果也不一样。比如当客户端和服务器的时间没有同步时,Kerberos会认为该访问是重放攻击而拒绝访问,但NTLM不会。
案例2:一个域账号明明被加到某个组里,该组也被赋予访问文件夹的权限,但是该账号就是访问不了这个文件夹。
用Wireshark解密了AP_REQ之后,并没有看到那个组。很可能是用户登录(获得包含组信息的ticket)之后,才被加到那个组里的。让该用户注销后再登录,获得新Ticket就好了。
案例3:某台客户端加入域失败,查了很久都没找到原因。
用了Wireshark之后,在包里发现 “KRB5KRB_ERR_RESPONSE_TOO_BIG”的错误信息(见图8)。利用该报错很快就从微软的网站上找到了解决方案。
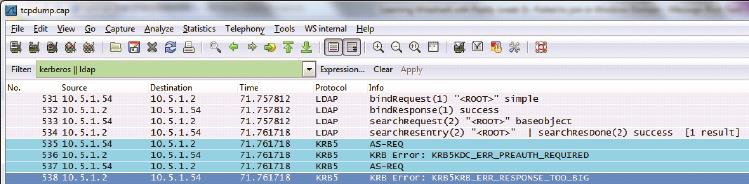
图8
TCP/IP的故事
我们生活在这样一个时代:只要连上网络,就可以和朋友交流,无论距离远近;也可以网购商品,发誓剁手都无济于事;还可以点评正在发生的大小事件,像皇上批阅奏章一样日理万机。用我们这一行的表达方式,可以说现代人的生活是基于网络的。
网络的流行很大程度上要归功于Vinton Cerf和Robert Kahn这对老搭档(见图1)。他们在20世纪70年代设计的TCP/IP协议奠定了现代网络的基石,也因此获得过计算机界的最高荣誉—图灵奖。

图1
说起来TCP/IP还不是这两位互联网之父的第一次合作。在此之前,他们一起参与了阿帕网的开发。阿帕网称得上现代网络的前身,当时谁也没有想到,颠覆阿帕网的竟是它的两位设计者。Robert后来回忆说,当他把工作重心从阿帕网转向TCP/IP时,身边的人都以为他的事业陷入低谷,而实际上那才是他事业的真正开始。
Robert为人低调,每次接受采访都一本正经。Vinton热情外向,关于他的趣事很多。比如他和女友第一次约会时去了艺术博物馆。IT男Vinton在一幅大型作品前伫立良久,最后冒出一句评语:“这画真像一只巨大的新鲜汉堡包”,我们可以想象他的画家女友当时的表情。当然,找个技术青年当男友也不是一无是处。后来在他们的婚礼上,录音机突然卡壳了。Vinton终于发挥了一把特长,和伴郎一起到小房间修录音机了。互联网造福了世界,自然也包括Vinton自己的生活。因为夫妻俩都有听力缺陷,听电话非常吃力,电子邮件就为他们带来不少便利。
现在人们说到TCP/IP时,指的已经不止是TCP和IP两个协议,而是包括了Application Layer、Transport Layer、Internet Layer和Network AccessLayer的四层模型。TCP处于Transport Layer,而IP处于Internet Layer。鲜为人知的是,一开始这两个协议并没有分层,而是合在一起的。当时的计算机科学家Jon Postel对此批评说:
“We are screwing up in our design of internet protocols by violating the principle of layering. Specifically we are trying to use TCP to do two things: serve as a host level end to end protocol, and to serve as an internet packaging and routing protocol. These two things should be provided in a layered and modular way. I suggest that a new distinct internetwork protocol is needed, and that TCP be used strictly as a host level end to end protocol.”(我们违背了分层原则,从而搞砸了网络协议的设计。具体来说,我们正在尝试使用TCP来做两件事:作为一个主机级别的端到端协议;同时也作为网络的分组和路由协议。这两件事本应该用分层和模块化的形式来实现。我建议设计一个新的网络互联协议,并且把TCP严格限制为主机级别的端到端协议。)
—Jon Postel, IEN 2, 1977
这个建议一年后被采纳了,第三版的协议决定把TCP和IP分离开来,并且延续至今。无巧不成书,Jon Postel恰好是Vinton的高中同学,也是阿帕网项目的同事。他在1998年因病去世时,Vinton为他写了一篇感人至深的讣告,并且作为RFC 2468发布。据我所知,这是唯一一篇无关技术的RFC。对一位计算机科学家来说,这也许是最有意义的纪念方式。我们今天还可以通过http://tools.ietf.org/html/rfc2468阅读它。
TCP/IP的设计非常成功。30年来,底层的带宽、延时,还有介质都发生了翻 天覆地的变化,顶层也多了不少应用,但TCP/IP却安如泰山。它不但战胜了国际标准化组织的OSI七层模型,而且目前还看不到被其他方案取代的可能。第一代从事TCP/IP工作的工程师,到了退休年龄也在做着朝阳产业。
令人费解的是,现在的大学课程还在介绍OSI七层模型。它和TCP/IP模型的对应关系如图2所示。因为OSI模型的层数太多,很多学生根本理解不了,甚至连顺序都记不住。于是老师们就用“All People Seem To Need Data Processing”来帮助记忆,因为这7个单词的首字母和OSI模型每一层的首字母是一样的。大学的应试教育由此可见一斑。更奇怪的是学生们走出校园后,会发现这个笨重的七层模型已经没有市场。虽然历史上它得到过官方的大力支持,但是市场明显更青睐TCP/IP四层模型。
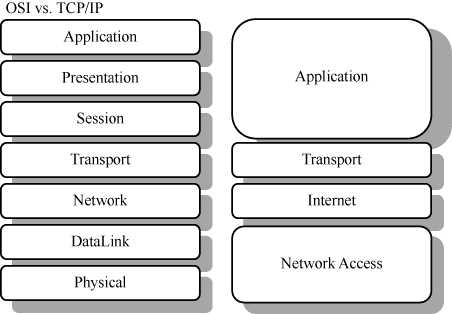
图2
按理说OSI是权威组织,它所设计的模型应该是科学的。为什么反而会不受欢迎呢?很多专家都对此有过评论,其中以普度大学特聘教授Douglas Comer的批评最为激烈。他曾经在一篇文章里这样写过:
“最近有了一些惊人的发现:我们都知道这个七层模型是由一个小组(见图3)完成的,但大家不知道的是,这个小组有一天深夜在酒吧里谈论美国的娱乐八卦。他们把迪斯尼电影里7个小矮人的名字写在餐巾纸上,有个人开玩笑说7对于网络分层是个好数字。第二天上午在标准化委员会的会议上,他们传阅了那张餐巾纸,然后一致同意昨晚喝醉时的重大发现。那天结束时,他们又给七个层次重新起了听上去更科学的名字,于是模型就诞生了。

图3
这个故事告诉我们:如果你是标准委员会中的工程师,请不要和同事喝酒—深夜在酒吧里开的一个拙劣玩笑,却可能成为业界几十年挥之不去的噩梦。”
Douglas是网络界德高望重的前辈,他回到普度大学之前曾是Cisco的Vice President of Research,同时也是久负盛名的技术作家,所以他的观点很有代表性。而当时业界普遍对待OSI模型的抵触态度,更是一个有力的佐证。幸好到了今天,OSI模型几乎名存实亡了,它对我们的影响只停留在还没来得及更新的教科书上。
(1) 在这一步,客户端找到服务器的portmap进程,向它查询NFS进程的端口号。然后服务器的portmap进程回复了2049。portmap的功能是维护一张进程与端口号的对应关系表,而它自己的端口号111是众所周知的,其他进程都能找到它。这个角色类似很多公司的前台,她知道每个员工的分机号。当我们需要联系公司里的某个人(比如NFS)时,可以先拨前台(111),查询到其分机号(2049),然后就可以拨这个分机号了。其实大多数文件服务器都会使用2049作为NFS端口号,所以即便不先咨询portmap,直接连2049端口也不会出问题。
(2) 客户端尝试连接服务器的NFS进程,由此判断2049端口是否被防火墙拦截,还有NFS服务是否已经启动。
(3) 客户端再次联系服务器的portmap,询问mount进程的端口号。与NFS不同的是,mount的端口号比较随机,所以这步询问是不能跳过的。
(4) 客户端尝试连接服务器的mount进程,由此判断1234端口是否被防火墙拦截,还有mount进程是否已经启动。
(5) 这一步真正挂载了/code目录。挂载成功后,服务器把该目录的file handle告诉客户端(要点开详细信息才能看到File handle)。
(6) 在我看来这一步没有必要,因为之前已经试连过NFS了,再测试一次有何意义?我猜是开发人员不小心重复调用了同一函数,但因为没有抓包,所以测试人员也没有发现这个问题。
(7) 客户端获得了该文件系统的大小和空间使用率等属性。我们在客户端上执行df就能看到这些信息。
(8) 这一步又是重复操作,更让我怀疑是开发人员的疏忽。这个例子也说明了Wireshark在辅助开发中的作用。
(9) 这个file handle也需要从包的详细信息里才能看到。就如之前提到过的,NFS操作文件时使用的是file handle, 所以要先通过文件名找到其file handle,而不是直接读其文件名。如果一个目录里文件数量巨大,获取file handle可能会比较费时,所以建议不要在一个目录里存放太多文件。
(10) 在创建一个文件之前,要先检查一下是否有同名文件存在。如果没有才能继续写,如果有,要询问用户是否覆盖原文件。
(11) 这是COMMIT操作。对于async方式的WRITE Call,服务器收到Call之后会在真正存盘前就回复WRITE Reply,这样做是为了提高写性能。那么,客户端怎么知道哪些WRITE Call已经真正存盘了呢?COMMIT操作就是为此而设计的。只有COMMIT过的数据才算真正写好。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









