







关于kube-scheduler的文章有很多,官方文档也已经给出很详细说明,我写这篇文章的主要目的是梳理知识点和记录一下自己的想法。
1. kube-scheduler的调度过程
kube-scheduler的职责是将Pod调度到集群中的节点上。这里要注意啦,只负责Pod的调度。那么问题来了,删除pod需要经过kube-scheduler吗?答案是不需要,kelete会监听APIServer,直接删除pod。kube-scheduler的调度过程主要是:
-
监听未分配的Pod:kube-scheduler会通过Watch API与APIServer持续监听集群中未分配(unscheduled)的Pod。他会把结果放入scheduling queue等待被调度。
-
评分节点:对于每个未分配的Pod,kube-scheduler根据Pod的资源需求、亲和性/反亲和性规则、节点选择器等信息,对集群中的节点进行评分。这个阶段主要是过滤和打分。
-
选择节点:根据评分结果,kube-scheduler选择一个最适合的节点来运行该Pod。选择的节点通常是得分最高的节点,但也可能受到其他因素的影响,比如亲和性规则、节点负载等。
-
更新调度结果:一旦选择了节点,kube-scheduler会更新Pod的调度信息,将Pod绑定到选定的节点上。
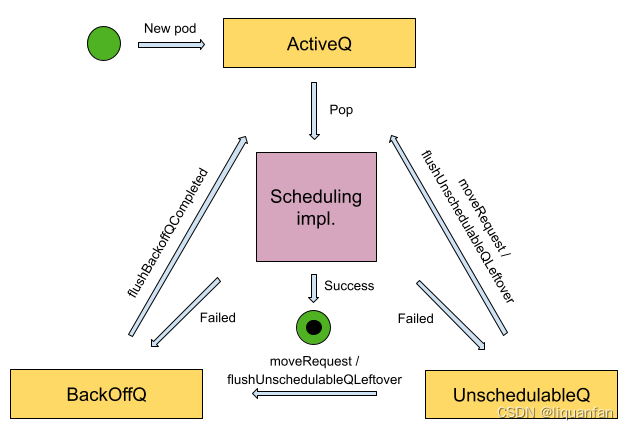
2. Scheduling Queue
上面这个链接已经有很详细的说明了,我简单翻译一下。
1. active(activeQ):提供即时调度的 Pod。
2. unschedulable(unschedulableQ):用于存放等待某些条件发生的 Pod,无法立即进行调度。
3. backoff(podBackoffQ):对于未能成功调度的 Pod 进行指数级延迟处理(例如,卷仍在创建中),但预期最终可以被调度成功。
此外,调度队列机制还有两个后台定期刷新的 goroutine,负责将 Pod 移动到活动队列:
1. flushUnschedulableQLeftover:每30秒运行一次,将未能通过任何事件移动的 Pod 从 unschedulable 队列中移动出来,以便再次尝试调度。Pod 必须在队列中至少等待30秒才能被移动。在最坏的情况下,可能需要60秒才能将 Pod 移动出去。
2. flushBackoffQCompleted:每秒运行一次,将已经经过足够长时间的 pod 从 backoff 队列移动到 active 队列。
3. kube-scheduler的调度策略
在kubernetes早期的版本中是通过Predicates 和 Priorities 的函数来进行节点过滤和节点打分的。下面的函数有的在新的版本已经找不到了。可以选择忽略。
Predicates的函数包括:
NoVolumeZoneConflict:检查Pod请求的存储卷是否在同一可用区中。MaxVolumeCount:检查存储卷的数量是否超过限制。CheckNodeMemoryPressure、CheckNodeDiskPressure:检查节点是否有内存或磁盘压力。PodFitsResources:检查节点上是否有足够的资源来运行Pod。PodFitsHostPorts:检查节点上的网络端口是否可以满足Pod的需求。
Priorities的一组函数,用于为符合条件的节点打分,以决定最终选择哪个节点,例如:
LeastRequestedPriority:优先选择请求资源少的节点,以实现负载均衡。BalancedResourceAllocation:尽可能平衡CPU和内存资源的使用。SelectorSpreadPriority:尽量将属于同一Service、ReplicaSet、StatefulSet的Pod分散到不同的节点上。NodeAffinityPriority:根据Pod的节点亲和性规则,为节点打分。InterPodAffinityPriority:根据Pod间的亲和性和反亲和性规则,为节点打分。
新的kernetes版本中,引入了schedule framework, 官方文档给出了详细的说明Scheduling Framework | Kubernetes
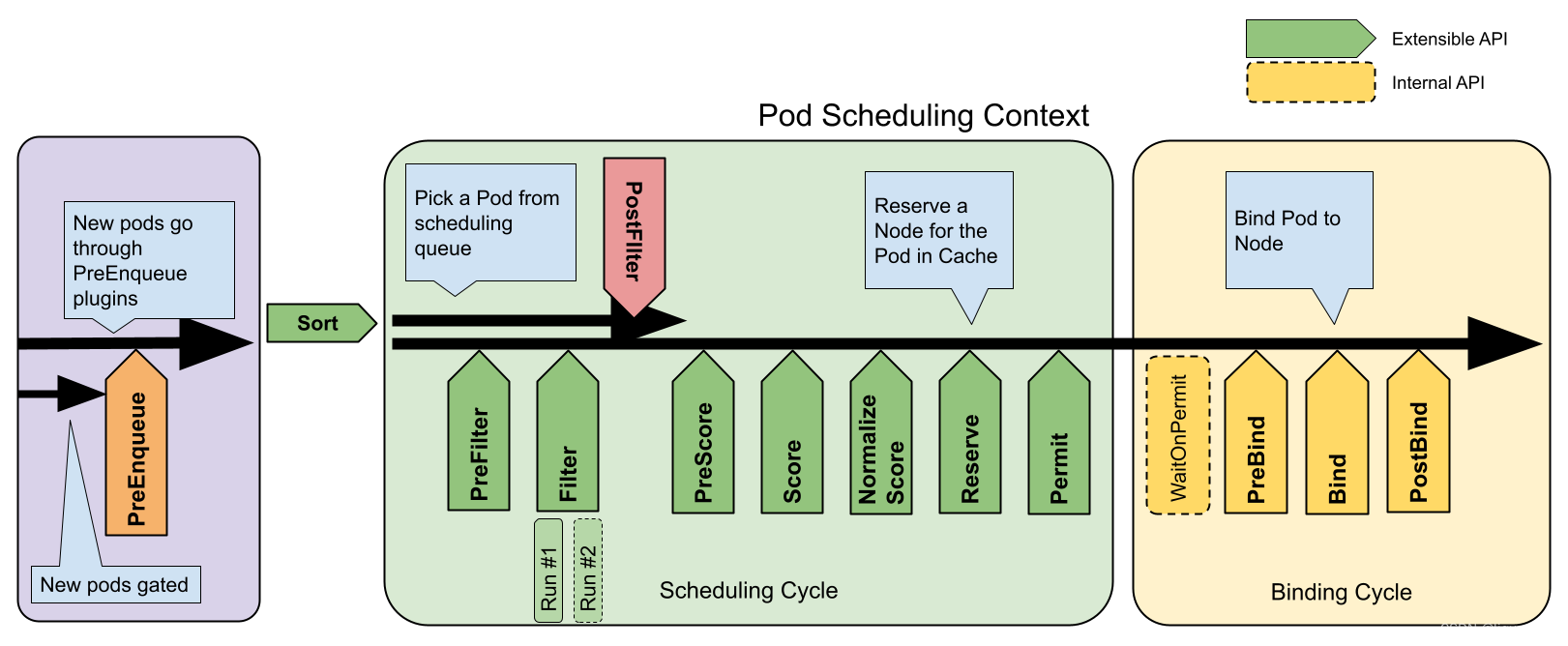
主要分为两个步骤,一个是Scheduling cycle, 一个是Binding cycle. Scheduling cycle是串行运行的,防止同一个pod被多次调度。 由于资源不足导致schedule失败的pod会被放入unschedulableQ中。Binding cycle是可以并行执行的。执行失败会被放到podBackoffQ 中。
4.kube-scheduler的代码调用关系
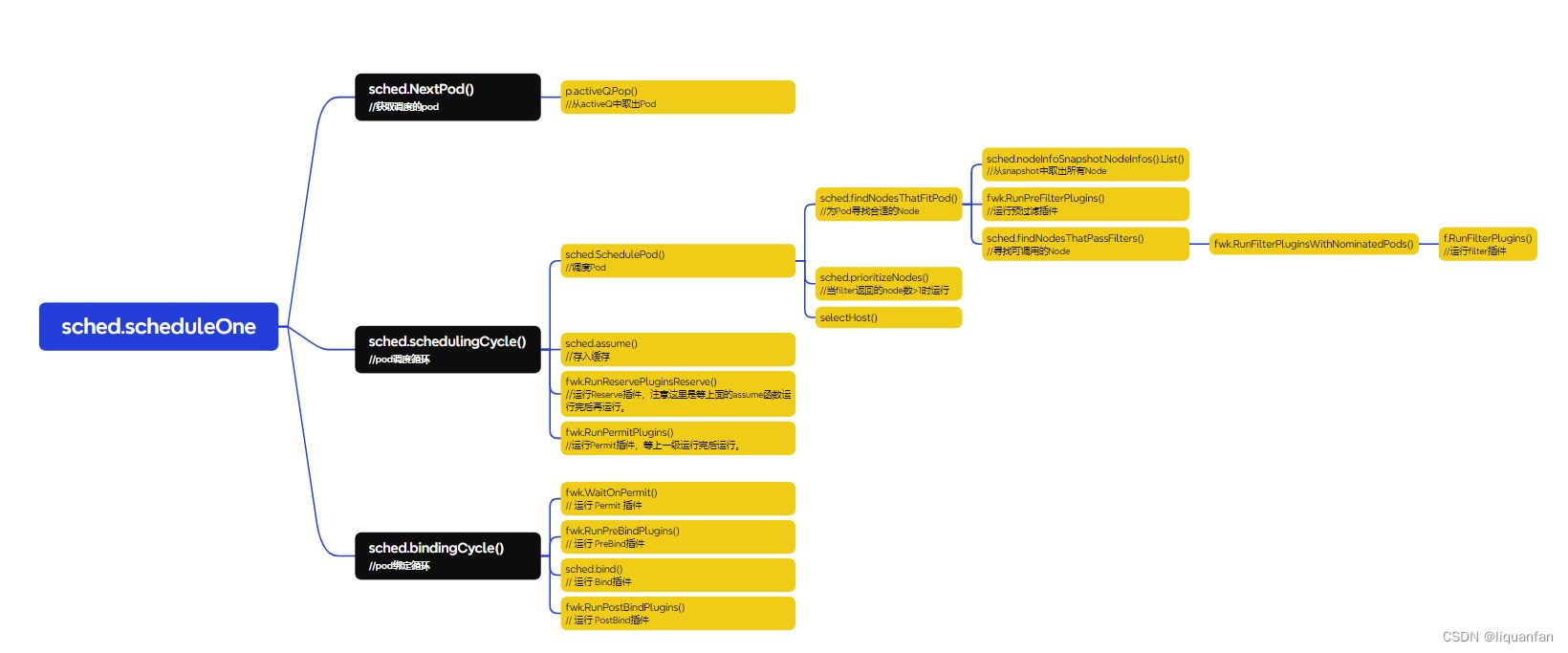
这个我用xmind画的,截取出来有点不清楚,下次截个清晰的更换掉。
5. 如何扩展kube-scheduler的插件
我们以score插件为例。
- 编写自定义的评分插件代码,实现 Score Plugin 接口。
package main import ( "k8s.io/apimachinery/pkg/api/resource" "k8s.io/kubernetes/plugin/pkg/scheduler/api" "k8s.io/kubernetes/plugin/pkg/scheduler/framework" "k8s.io/kubernetes/plugin/pkg/scheduler/framework/plugins/defaultbinder" ) type CustomCPUUsageScore struct { framework.ScorePlugin } func (pl *CustomCPUUsageScore) Name() string { return "CustomCPUUsageScore" } func (pl *CustomCPUUsageScore) Score(_ framework.FrameworkHandle, state *framework.CycleState, pod *v1.Pod, nodeName string) (int, error) { // 获取节点的 CPU 使用率 cpuUsage := getNodeCPUUsage(nodeName) // 计算评分,这里假设 CPU 使用率越低,评分越高 score := 100 - int(cpuUsage) return score, nil } func getNodeCPUUsage(nodeName string) int { // 实现获取节点 CPU 使用率的逻辑,这里假设我们有一个 getNodeCPUUsage 函数可以获取节点的 CPU 使用率 // 实际情况中,需要根据你的环境和需求来获取节点的 CPU 使用率 // 这里只是一个示例,实际情况可能需要调用相应的 API 来获取节点的 CPU 使用率 cpuUsage := 50 // 假设节点的 CPU 使用率为 50% return cpuUsage }2. 注册自定义的评分插件到 kube-scheduler 中。通过修改 kube-scheduler 的配置文件。
apiVersion: kubescheduler.config.k8s.io/v1 kind: KubeSchedulerConfiguration profiles: - schedulerName: default-scheduler plugins: score: enabled: - name: CustomCPUUsageScore3、重启kube-scheduler,验证是否生效。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









