







导航
前言:
需求是这样的,女神遇到了一个具体问题。就是sqlserver数据库中有些数据是json字符串。
但是由于她们公司的sqlserver数据库版本比较低,没有自带的解析方法。
所以需要用自定义函数查询。
开始干活:
0.预告
我在本帖子中会创建两个自定义函数。
一个名字叫做parseJSON是通用json解析函数。另外一个需要根据业务情况,为带有json的业务表做一个专用的自定义函数。
1.首先先建立一个“通用的json解析自定义函数”。(这个代码是网络上找到的成熟代码)
直接粘贴代码
CREATE FUNCTION [dbo].[parseJSON] ( @JSON NVARCHAR(MAX) )
。。。。
这个自定义函数内容太多了,为了阅读方便,我贴在帖子尾部了。
END
2. 重点讲解一下 函数 “parseJSON( )”的用法
首先通过代码阅读了解到,函数 “parseJSON( )”的返回结果是一个表(结果集)。
我们可以通过sql测试它。
假设我们要解析的json是:
{"channelCode":"A003","random":"124317f0-8e42-4c9c-88b0-cabacc8a8079"}
我们可以直接用sql对这个json字符串进行解析。
函数 “parseJSON( )”的参数要求“输入json字符串”,位置放在 “from”后面当作 “表”用。一定要加 “dbo.”
代码如下
select *
from dbo.parseJSON('{"channelCode":"A003","random":"124317f0-8e42-4c9c-88b0-cabacc8a8079"}')
;
得到的结果如下图是一个固定结构的表。
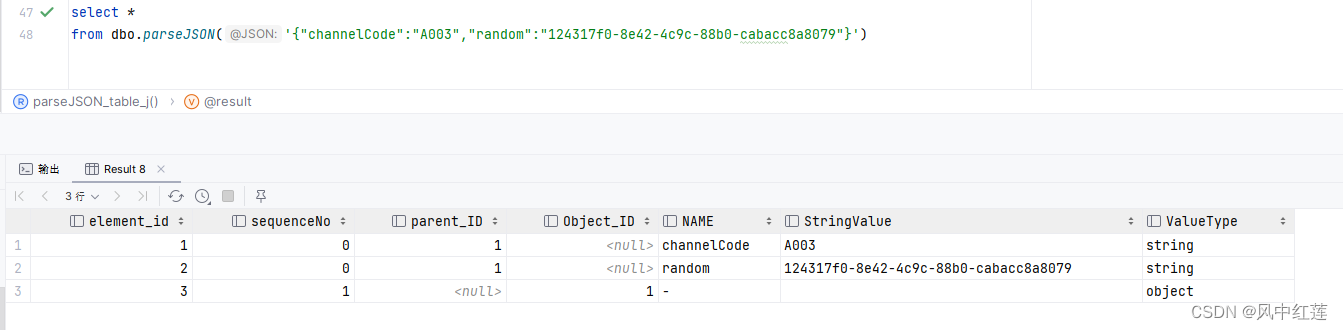
由此可以看到,json被打开,内部的key和value分别放在两个不同的列。
我们可以根据where条件去查询它,比如如下语句:
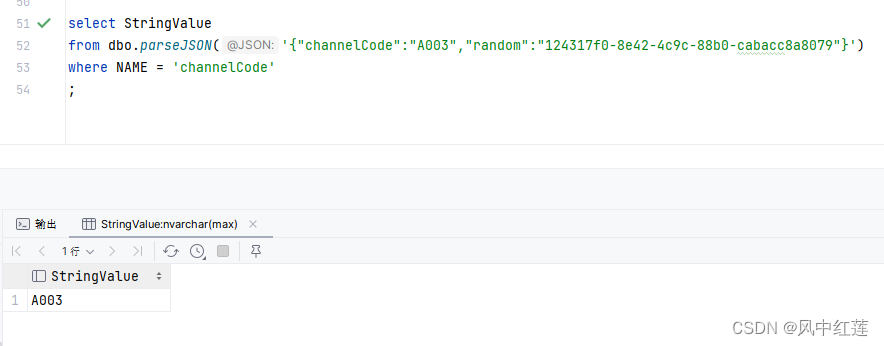
select StringValue
from dbo.parseJSON('{"channelCode":"A003","random":"124317f0-8e42-4c9c-88b0-cabacc8a8079"}')
where NAME = 'channelCode'
;
得到结果是:
3.学会了函数 “parseJSON( )”的用法,那么如何方便的在以后的查询语句中使用它呢?
由于函数 “parseJSON( )”的返回结果是一个表。而我们实际上多数情况下希望在select中向查询普通字段一样查询json内的参数。
所以我们需要用一些“土办法”。
这里我选择的方案是,针对具体的业务表,做一个专用与这个表以后查询的专用函数。
预先准备测试用的数据表和数据
教学用测试表的表结构:
-- 创建一个带有json数据的表测试表table_j
create table table_j
(
id int not null,
val varchar(800)
)
go
教学用测试数据:
-- 插入3条测试数据
INSERT INTO dbo.table_j (id, val)
VALUES (1, N'{"channelCode":"A001","random":"5e590a2b-a295-4ac6-af0b-92528a84a3ee"}');
INSERT INTO dbo.table_j (id, val)
VALUES (2, N'{"channelCode":"A002","random":"de823b5a-19db-4492-a144-2f66945b1ce4"}');
INSERT INTO dbo.table_j (id, val)
VALUES (3, N'{"channelCode":"A003","random":"124317f0-8e42-4c9c-88b0-cabacc8a8079"}');
开始制作“专用函数”
我们设计一个函数 叫 “ parseJSON_table_j( ) ”,
设计他有两个参数,
参数1 用来做查询数据的唯一id。
参数2 用来告诉我们要查json内的哪个值。
(这里假定我们是知道表结构并知道哪个字段存储了json数据。)
-- 为了方便使用 专门为测试表测试表table_j 做了第二个自定义函数
-- 它的功能是 通过测试表table_j的唯一key 查询对应json数据里面 某一个节点的值
-- 返回字符串类型
CREATE FUNCTION dbo.parseJSON_table_j(
@param1_id INT, -- 唯一标识
@param2_jsonkey nvarchar(max) -- json中的节点名称
)
RETURNS nvarchar(max)
AS
BEGIN
DECLARE @json nvarchar(max)
DECLARE @result nvarchar(max)
-- 这里直接硬编码写死了(表名 table_j )和(存放json字符串的字段 val),在实际使用中要根据查询json所在表进行修改。
select @json = val from table_j where id = @param1_id
select @result = StringValue
from dbo.parseJSON(@json)
where NAME = @param2_jsonkey
RETURN @result
END
如何使用“专用函数”
直接通过传参是方式可以查询。比如下面的sql脚本:
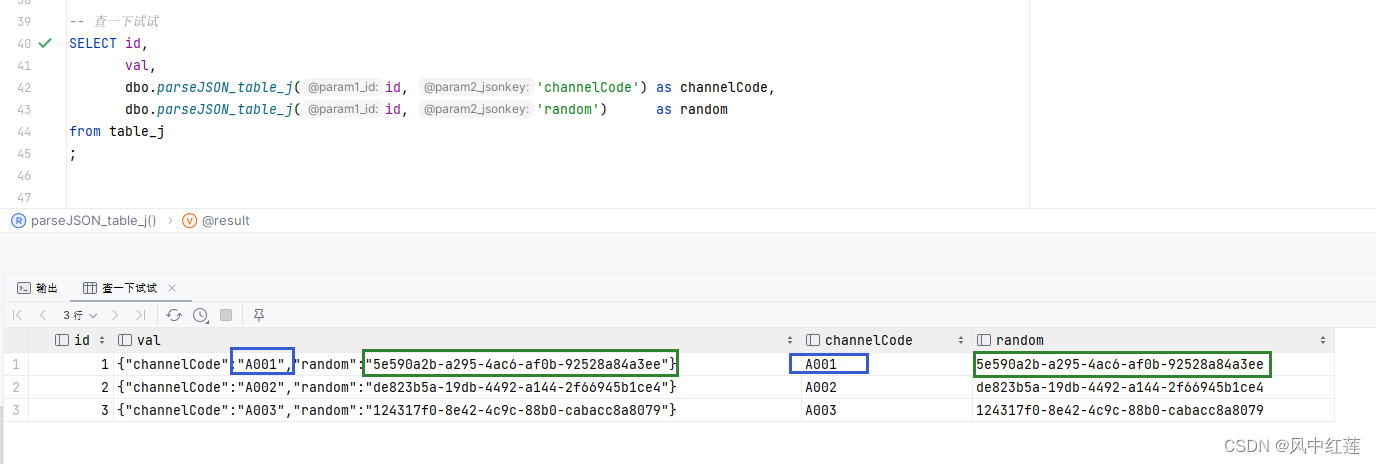
-- 查一下试试
SELECT id,
val,
dbo.parseJSON_table_j(id, 'channelCode') as channelCode,
dbo.parseJSON_table_j(id, 'random') as random
from table_j
;
得到的结果如下,完美的把json字符串解析到了查询语句中。
最后,上价值!!!
我家女神天下第一美,不接受任何反驳。
女神的毒唯,爱宠,我家小公主,妞妞镇楼。(话说谁能告诉我毒唯是什么。。。。。。。。)

附录:函数 “parseJSON( )”的代码
CREATE FUNCTION [dbo].[parseJSON](@JSON NVARCHAR(MAX))
RETURNS @hierarchy TABLE
(
element_id INT IDENTITY (1, 1)
NOT NULL, /* internal surrogate primary key gives the order of parsing and the list order */
sequenceNo [int] NULL, /* the place in the sequence for the element */
parent_ID INT,/* if the element has a parent then it is in this column. The document is the ultimate parent, so you can get the structure from recursing from the document */
Object_ID INT,/* each list or object has an object id. This ties all elements to a parent. Lists are treated as objects here */
NAME NVARCHAR(2000),/* the name of the object */
StringValue NVARCHAR(MAX) NOT NULL,/*the string representation of the value of the element. */
ValueType VARCHAR(10) NOT NULL /* the declared type of the value represented as a string in StringValue*/
)
AS
BEGIN
DECLARE @FirstObject INT , --the index of the first open bracket found in the JSON string
@OpenDelimiter INT ,--the index of the next open bracket found in the JSON string
@NextOpenDelimiter INT ,--the index of subsequent open bracket found in the JSON string
@NextCloseDelimiter INT ,--the index of subsequent close bracket found in the JSON string
@Type NVARCHAR(10) ,--whether it denotes an object or an array
@NextCloseDelimiterChar CHAR(1) ,--either a '}' or a ']'
@Contents NVARCHAR(MAX) , --the unparsed contents of the bracketed expression
@Start INT , --index of the start of the token that you are parsing
@end INT ,--index of the end of the token that you are parsing
@param INT ,--the parameter at the end of the next Object/Array token
@EndOfName INT ,--the index of the start of the parameter at end of Object/Array token
@token NVARCHAR(max) ,--either a string or object
@value NVARCHAR(MAX) , -- the value as a string
@SequenceNo INT , -- the sequence number within a list
@name NVARCHAR(200) , --the name as a string
@parent_ID INT ,--the next parent ID to allocate
@lenJSON INT ,--the current length of the JSON String
@characters NCHAR(36) ,--used to convert hex to decimal
@result BIGINT ,--the value of the hex symbol being parsed
@index SMALLINT ,--used for parsing the hex value
@Escape INT --the index of the next escape character
DECLARE @Strings TABLE /* in this temporary table we keep all strings, even the names of the elements, since they are 'escaped' in a different way, and may contain, unescaped, brackets denoting objects or lists. These are replaced in the JSON string by tokens representing the string */
(
String_ID INT IDENTITY (1, 1),
StringValue NVARCHAR(MAX)
)
SELECT--initialise the characters to convert hex to ascii
@characters = '0123456789abcdefghijklmnopqrstuvwxyz',
@SequenceNo = 0, --set the sequence no. to something sensible.
/* firstly we process all strings. This is done because [{} and ] aren't escaped in strings, which complicates an iterative parse. */
@parent_ID = 0;
WHILE 1 = 1 --forever until there is nothing more to do
BEGIN
SELECT @start = PATINDEX('%[^a-zA-Z]["]%',
@json COLLATE SQL_Latin1_General_CP850_Bin);--next delimited string
IF @start = 0
BREAK --no more so drop through the WHILE loop
IF SUBSTRING(@json, @start + 1, 1) = '"'
BEGIN
--Delimited Name
SET @start = @Start + 1;
SET @end = PATINDEX('%[^\]["]%',
RIGHT(@json,
LEN(@json + '|') - @start) COLLATE SQL_Latin1_General_CP850_Bin);
END
IF @end = 0 --no end delimiter to last string
BREAK --no more
SELECT @token = SUBSTRING(@json, @start + 1, @end - 1)
--now put in the escaped control characters
SELECT @token = REPLACE(@token, FROMString, TOString)
FROM (SELECT '\"' AS FromString,
'"' AS ToString
UNION ALL
SELECT '\\',
'\'
UNION ALL
SELECT '\/',
'/'
UNION ALL
SELECT '\b',
CHAR(08)
UNION ALL
SELECT '\f',
CHAR(12)
UNION ALL
SELECT '\n',
CHAR(10)
UNION ALL
SELECT '\r',
CHAR(13)
UNION ALL
SELECT '\t',
CHAR(09)) substitutions
SELECT @result = 0,
@escape = 1
--Begin to take out any hex escape codes
WHILE @escape > 0
BEGIN
SELECT @index = 0,
--find the next hex escape sequence
@escape = PATINDEX('%\x[0-9a-f][0-9a-f][0-9a-f][0-9a-f]%',
@token COLLATE SQL_Latin1_General_CP850_Bin)
IF @escape > 0 --if there is one
BEGIN
WHILE @index < 4 --there are always four digits to a \x sequence
BEGIN
SELECT --determine its value
@result = @result + POWER(16,
@index)
* (CHARINDEX(SUBSTRING(@token,
@escape + 2 + 3
- @index, 1),
@characters) - 1),
@index = @index + 1;
END
-- and replace the hex sequence by its unicode value
SELECT @token = STUFF(@token, @escape, 6,
NCHAR(@result))
END
END
--now store the string away
INSERT INTO @Strings
(StringValue)
SELECT @token
-- and replace the string with a token
SELECT @JSON = STUFF(@json, @start, @end + 1,
'@string'
+ CONVERT(NVARCHAR(5), @@identity))
END
-- all strings are now removed. Now we find the first leaf.
WHILE 1 = 1 --forever until there is nothing more to do
BEGIN
SELECT @parent_ID = @parent_ID + 1
--find the first object or list by looking for the open bracket
SELECT @FirstObject = PATINDEX('%[{[[]%',
@json COLLATE SQL_Latin1_General_CP850_Bin)--object or array
IF @FirstObject = 0
BREAK
IF (SUBSTRING(@json, @FirstObject, 1) = '{')
SELECT @NextCloseDelimiterChar = '}',
@type = 'object'
ELSE
SELECT @NextCloseDelimiterChar = ']',
@type = 'array'
SELECT @OpenDelimiter = @firstObject
WHILE 1 = 1 --find the innermost object or list...
BEGIN
SELECT @lenJSON = LEN(@JSON + '|') - 1
--find the matching close-delimiter proceeding after the open-delimiter
SELECT @NextCloseDelimiter = CHARINDEX(@NextCloseDelimiterChar,
@json,
@OpenDelimiter
+ 1)
--is there an intervening open-delimiter of either type
SELECT @NextOpenDelimiter = PATINDEX('%[{[[]%',
RIGHT(@json,
@lenJSON
-
@OpenDelimiter) COLLATE SQL_Latin1_General_CP850_Bin)--object
IF @NextOpenDelimiter = 0
BREAK
SELECT @NextOpenDelimiter = @NextOpenDelimiter
+ @OpenDelimiter
IF @NextCloseDelimiter < @NextOpenDelimiter
BREAK
IF SUBSTRING(@json, @NextOpenDelimiter, 1) = '{'
SELECT @NextCloseDelimiterChar = '}',
@type = 'object'
ELSE
SELECT @NextCloseDelimiterChar = ']',
@type = 'array'
SELECT @OpenDelimiter = @NextOpenDelimiter
END
---and parse out the list or name/value pairs
SELECT @contents = SUBSTRING(@json, @OpenDelimiter + 1,
@NextCloseDelimiter
- @OpenDelimiter - 1)
SELECT @JSON = STUFF(@json, @OpenDelimiter,
@NextCloseDelimiter - @OpenDelimiter + 1,
'@' + @type
+ CONVERT(NVARCHAR(5), @parent_ID))
WHILE (PATINDEX('%[A-Za-z0-9@+.e]%',
@contents COLLATE SQL_Latin1_General_CP850_Bin)) <> 0
BEGIN
IF @Type = 'Object' --it will be a 0-n list containing a string followed by a string, number,boolean, or null
BEGIN
SELECT @SequenceNo = 0,
@end = CHARINDEX(':', ' ' + @contents)--if there is anything, it will be a string-based name.
SELECT @start = PATINDEX('%[^A-Za-z@][@]%',
' ' + @contents COLLATE SQL_Latin1_General_CP850_Bin)--AAAAAAAA
SELECT @token = SUBSTRING(' ' + @contents,
@start + 1,
@End - @Start - 1),
@endofname = PATINDEX('%[0-9]%',
@token COLLATE SQL_Latin1_General_CP850_Bin),
@param = RIGHT(@token,
LEN(@token)
- @endofname + 1)
SELECT @token = LEFT(@token, @endofname - 1),
@Contents = RIGHT(' ' + @contents,
LEN(' ' + @contents
+ '|') - @end
- 1)
SELECT @name = stringvalue
FROM @strings
WHERE string_id = @param --fetch the name
END
ELSE
SELECT @Name = NULL,
@SequenceNo = @SequenceNo + 1
SELECT @end = CHARINDEX(',', @contents)-- a string-token, object-token, list-token, number,boolean, or null
IF @end = 0
BEGIN
SELECT @end = PATINDEX('%[A-Za-z0-9@+.e][^A-Za-z0-9@+.e]%',
@Contents + ' ' COLLATE SQL_Latin1_General_CP850_Bin)
+ 1
END
SELECT @start = PATINDEX('%[^-A-Za-z0-9@+.e][-A-Za-z0-9@+.e]%',
' ' + @contents COLLATE SQL_Latin1_General_CP850_Bin)
--select @start,@end, LEN(@contents+'|'), @contents
SELECT @Value = RTRIM(SUBSTRING(@contents, @start,
@End - @Start)),
@Contents = RIGHT(@contents + ' ',
LEN(@contents + '|') - @end)
IF SUBSTRING(@value, 1, 7) = '@object'
INSERT INTO @hierarchy
(NAME,
SequenceNo,
parent_ID,
StringValue,
Object_ID,
ValueType)
SELECT @name,
@SequenceNo,
@parent_ID,
SUBSTRING(@value, 8, 5),
SUBSTRING(@value, 8, 5),
'object'
ELSE
IF SUBSTRING(@value, 1, 6) = '@array'
INSERT INTO @hierarchy
(NAME,
SequenceNo,
parent_ID,
StringValue,
Object_ID,
ValueType)
SELECT @name,
@SequenceNo,
@parent_ID,
SUBSTRING(@value, 7, 5),
SUBSTRING(@value, 7, 5),
'array'
ELSE
IF SUBSTRING(@value, 1, 7) = '@string'
INSERT INTO @hierarchy
(NAME,
SequenceNo,
parent_ID,
StringValue,
ValueType)
SELECT @name,
@SequenceNo,
@parent_ID,
stringvalue,
'string'
FROM @strings
WHERE string_id = SUBSTRING(@value,
8, 5)
ELSE
IF @value IN ('true', 'false')
INSERT INTO @hierarchy
(NAME,
SequenceNo,
parent_ID,
StringValue,
ValueType)
SELECT @name,
@SequenceNo,
@parent_ID,
@value,
'boolean'
ELSE
IF @value = 'null'
INSERT INTO @hierarchy
(NAME,
SequenceNo,
parent_ID,
StringValue,
ValueType)
SELECT @name,
@SequenceNo,
@parent_ID,
@value,
'null'
ELSE
IF PATINDEX('%[^0-9]%',
@value COLLATE SQL_Latin1_General_CP850_Bin) > 0
INSERT INTO @hierarchy
(NAME,
SequenceNo,
parent_ID,
StringValue,
ValueType)
SELECT @name,
@SequenceNo,
@parent_ID,
@value,
'real'
ELSE
INSERT INTO @hierarchy
(NAME,
SequenceNo,
parent_ID,
StringValue,
ValueType)
SELECT @name,
@SequenceNo,
@parent_ID,
@value,
'int'
IF @Contents = ' '
SELECT @SequenceNo = 0
END
END
INSERT INTO @hierarchy
(NAME,
SequenceNo,
parent_ID,
StringValue,
Object_ID,
ValueType)
SELECT '-',
1,
NULL,
'',
@parent_id - 1,
@type
--
RETURN
END
引用
[1]: 部分代码来自如下地址 :Sqlserver2008解析json字符串新增到临时表中














 3862
3862











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









