






现在已经有不少小伙伴的公司开始接入了大模型并开始建立知识库了,其中会涉及到将公司的文档进行切片的步骤,我们询问AI时,会优先查询知识库的内容并输出,那如何测试AI的回答有没有命中知识库呢?如果命中了,那匹配度有多少呢?
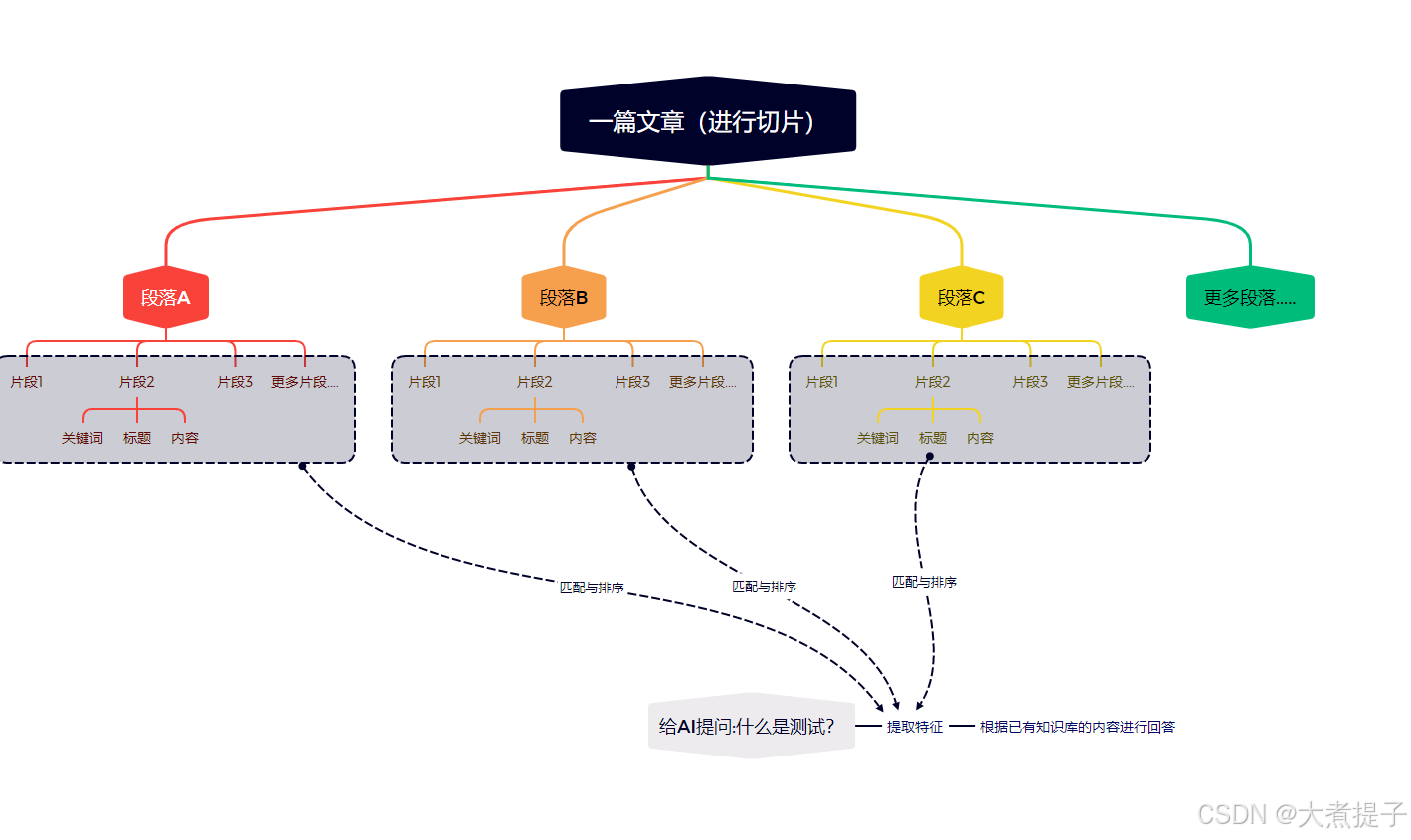
首先我们了解一下知识库的结构:
我们先将一份大的文档按照标题切割成小段落
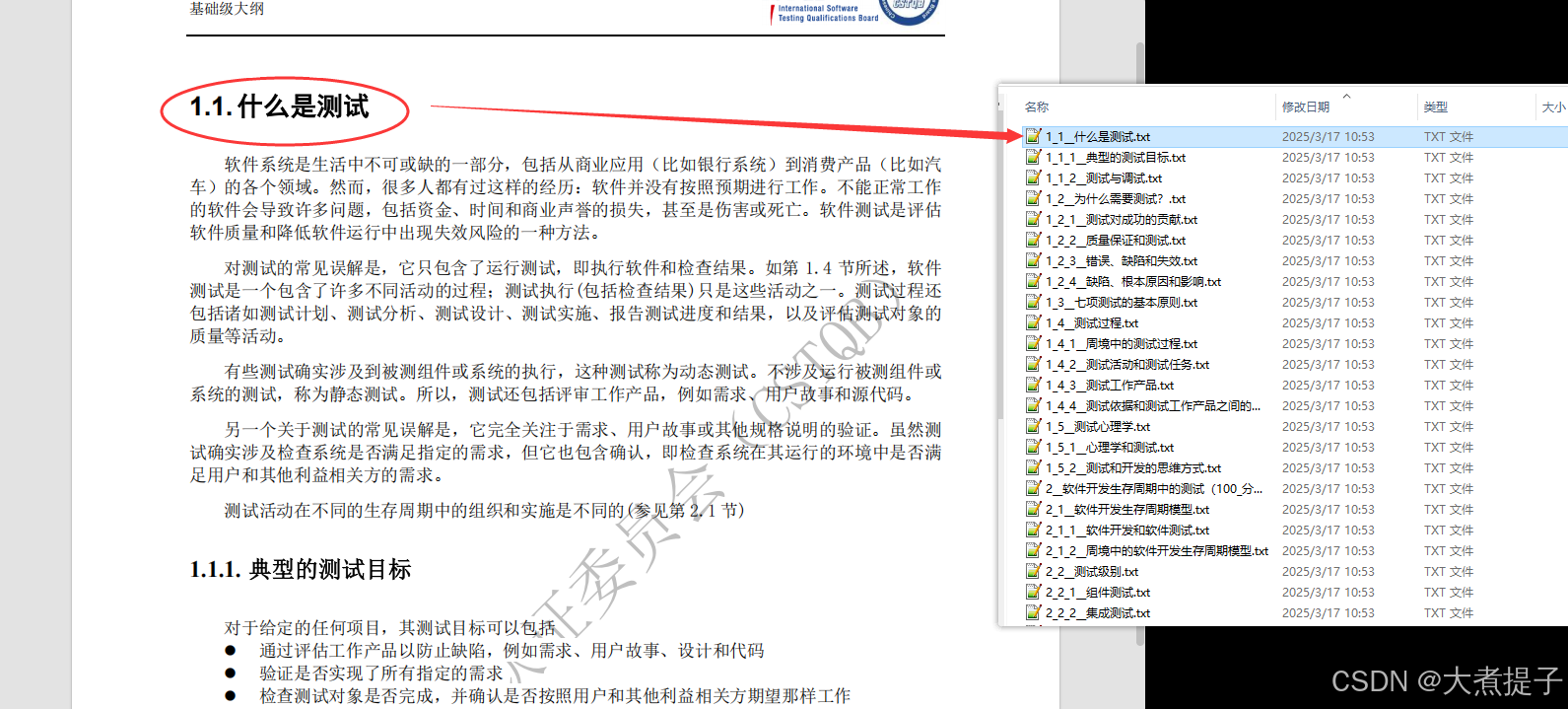
然后将每个小段落上传到知识库中
上传后,我们开发同学将该段落交给AI进行切片,并提取了段落里的内容变成了一些“特征”
比如上面这段文字,切成了多个片段


那么当我们直接问AI“什么是测试”时,AI 会将问题切成tokens:“什么”,“是”,“测试”,然后去匹配知识库里的切片,然后采用一定的排序机制,选取匹配度比较高的切片,并用对应的内容进行回答
我们来看看AI根据知识库回答的结果:
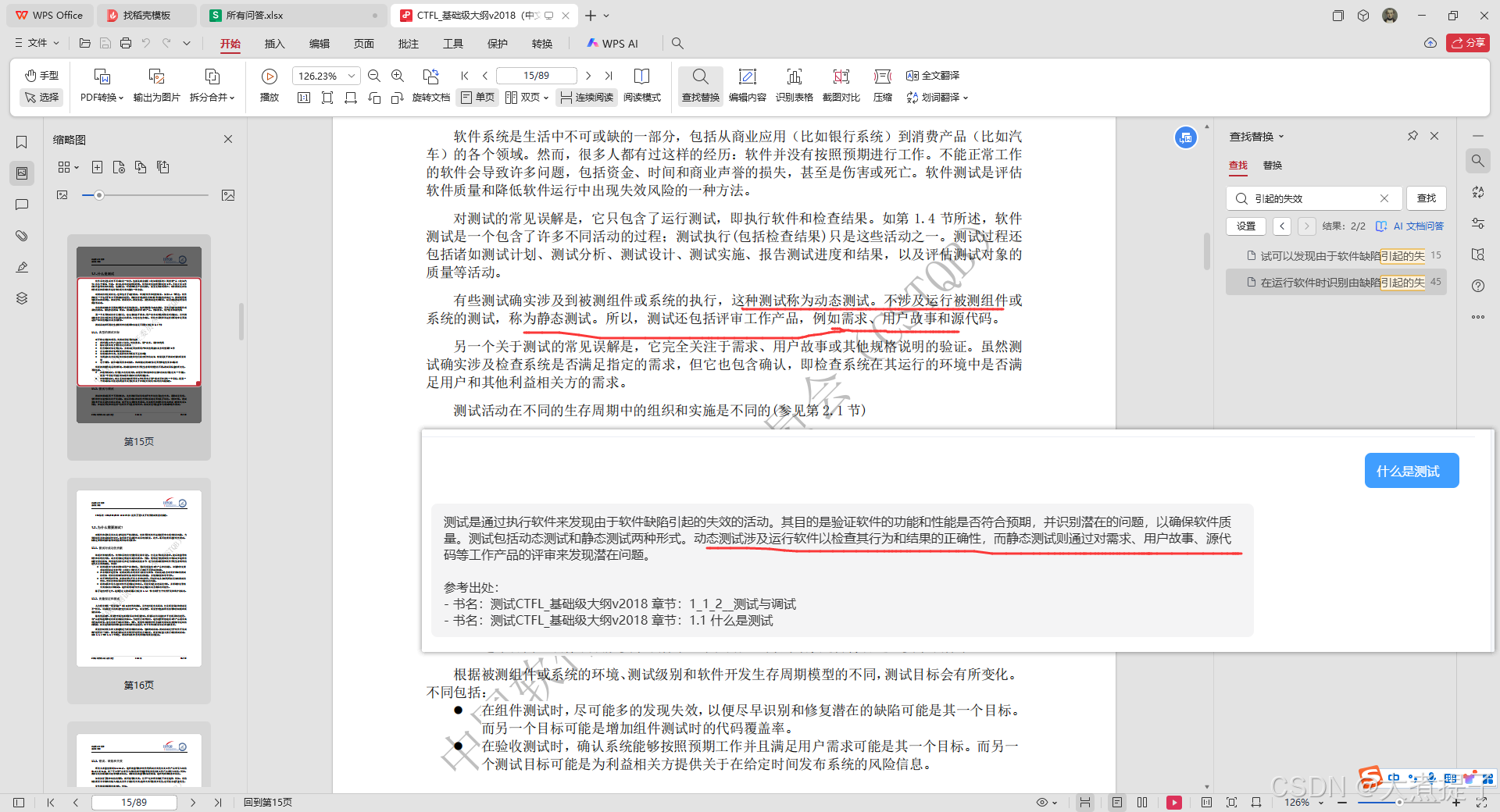
可以看到AI参考了知识库里的部分内容对语句进行了优化并给出了回答,虽然回答的不是很正确
接下来我们开发同学可能会调整提示词,也可能更换大模型,但是站在用户的角度,我们需要测试AI的回答是否足够专业和标准,那么对于我来说,AI回答的内容与录入的文档内容大量匹配,就算是标准。那么如何测试呢?
1、我们不能每次都问相同的内容,所以我们要换不同的问法,但是问题的意思又要差不多,这里我们让deepseek帮我们生成不同的提问:
def get_question_from_deepseek(title):
# DeepSeek API 相关设置
DEEPSEEK_API_URL = "https://api.deepseek.com/v1/chat/completions"
DEEPSEEK_API_KEY = DeepSeek API Key # DeepSeek API Key
headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer {DEEPSEEK_API_KEY}"
}
data = {
"model": "deepseek-chat", # 确保模型名称正确
"messages": [
{
"role": "user",
"content": f"将下面的问题换种提问方法,但是不能偏离原问题太多,请给出五种不同的提问:{title},按照这个格式来展示,其他的内容不要展示:1.XXXXXXXXXXXXXXXXXXX\n2.XXXXXXXXXXXXXXXXXXX\n3.XXXXXXXXXXXXXXXXXXX\n4.XXXXXXXXXXXXXXXXXXX\n5.XXXXXXXXXXXXXXXXXXX"
}
]
}
try:
response = requests.post(DEEPSEEK_API_URL, headers=headers, json=data)
if response.status_code == 200:
result = response.json()
article = result["choices"][0]["message"]["content"]
return article
else:
print(f"DeepSeek 请求失败,状态码:{response.status_code},错误信息:{response.text}")
except requests.RequestException as e:
print(f"DeepSeek 请求发生错误:{e}")
return None可以看到deepseek根据原问题产生了很多变种问题。

接下来我们根据每个变种问题,对AI进行提问,并将回答结果拿出来保存
2、将AI回答与知识库切片进行特征提取
import jieba # 引入中文分词库
import logging
import re
def preprocess_text(text):
"""
文本预处理函数,去除标点符号并转换为小写,同时进行中文分词
:param text: 输入的文本
:return: 处理后的文本
"""
text = re.sub(r'[^\w\s]', '', text) # 去除标点符号
text = text.lower() # 转换为小写
# 中文分词
words = jieba.lcut(text)
return " ".join(words)
可以看到AI的回答和知识库里的标准回答都被切割成tokens,接下来我们就将它们转成高维向量,并计算余弦,先在这里科普一下余弦:

3、计算匹配度
接下来直接贴代码:将提取的特征词转成向量并计算余弦相似度
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.metrics.pairwise import cosine_similarity
def calculate_similarity(ai_answer, knowledge_slice):
"""
计算 AI 回答与知识库切片的匹配度
:param ai_answer: AI 回答的文本
:param knowledge_slice: 知识库切片的文本
:return: 匹配度得分
"""
# 文本预处理
ai_answer = preprocess_text(ai_answer)
knowledge_slice = preprocess_text(knowledge_slice)
# 检查处理后的文本是否为空
if not ai_answer or not knowledge_slice:
logging.warning("处理后的文本为空,请检查输入。")
return 0
# 特征提取,调整 token_pattern 参数
vectorizer = TfidfVectorizer(token_pattern=r"(?u)\b\w+\b")
vectors = vectorizer.fit_transform([ai_answer, knowledge_slice])
feature_names = vectorizer.get_feature_names_out()
# 确保只输出一次特征名称
logging.info("提取的特征: %s", feature_names)
# 打印提取的特征(仅在调试时输出)
# logging.debug("提取的特征: %s", vectorizer.get_feature_names_out())
# 计算余弦相似度
similarity = cosine_similarity(vectors[0], vectors[1])[0][0]
return similarity
def split_and_match(ai_answer, knowledge_slice):
"""
根据句号对回答和知识库内容进行切割,并依次匹配
:param ai_answer: AI 回答的文本
:param knowledge_slice: 知识库切片的文本
:return: 每句话之间的匹配度列表
"""
# 根据句号切割句子
ai_sentences = re.split(r'[。]', ai_answer)
knowledge_sentences = re.split(r'[。]', knowledge_slice)
similarities = []
for ai_sentence in ai_sentences:
if ai_sentence.strip():
sentence_similarities = []
for knowledge_sentence in knowledge_sentences:
if knowledge_sentence.strip():
similarity = calculate_similarity(ai_sentence, knowledge_sentence)
sentence_similarities.append(similarity)
similarities.append(sentence_similarities)
return similarities
def check_ai_answer_matching(ai_answer, knowledge_slice):
"""
封装函数,传入 AI 回答和知识库切片,返回匹配结果
:param ai_answer: AI 回答的文本
:param knowledge_slice: 知识库切片的文本
:return: 每句话之间的匹配度列表
"""
return split_and_match(ai_answer, knowledge_slice)4、我们将比较结果进行优化并展示:
# 示例使用
if __name__ == "__main__":
ai_answer = "ISTQB®认证测试工程师基础级大纲的具体内容包括软件测试的基本概念、测试过程、静态测试、测试设计技术、测试管理、工具支持等。这些内容旨在为测试工程师提供标准化的职业发展框架,并促进一致和良好的测试实践,重点在于为测试工程师提供更多实践帮助。这是初学者学习和理解ISTQB基础级认证的重要参考资料。"
knowledge_slice = "ISTQB®认证测试工程师基础级大纲是国际软件测试认证委员会(ISTQB®)批准的第一级别(初级)国际资质文档。该大纲由ISTQB®任命的工作组编制,旨在为测试工程师提供标准化的职业发展框架,并促进一致和良好的测试实践。其内容基于先前的ISEB和ASQF大纲进行了更新和扩展,重点在于为测试工程师提供更多实践帮助。"
result = check_ai_answer_matching(ai_answer, knowledge_slice)
# 输出每句话与知识库各句的匹配度,调整输出格式
for i, sentence_similarities in enumerate(result):
formatted_similarities = [f"{sim * 100:.2f}%" for sim in sentence_similarities]
logging.info("AI回答第 %d 句话与知识库各句的匹配度: %s", i + 1, formatted_similarities)
# 取出每句话与知识库各句匹配度的最高值
max_similarities = []
for sentence_similarities in result:
max_similarity = max(sentence_similarities)
max_similarities.append(max_similarity)
# 计算所有 AI 回答的整体匹配度
overall_similarity = sum(max_similarities) / len(max_similarities)
# 输出每句话的最高匹配度
for i, max_sim in enumerate(max_similarities):
logging.info("AI回答第 %d 句话与知识库各句的最高匹配度: %.2f%%", i + 1, max_sim * 100)
# 输出整体匹配度
logging.info("所有 AI 回答的整体匹配度: %.2f%%", overall_similarity * 100)输出结果:

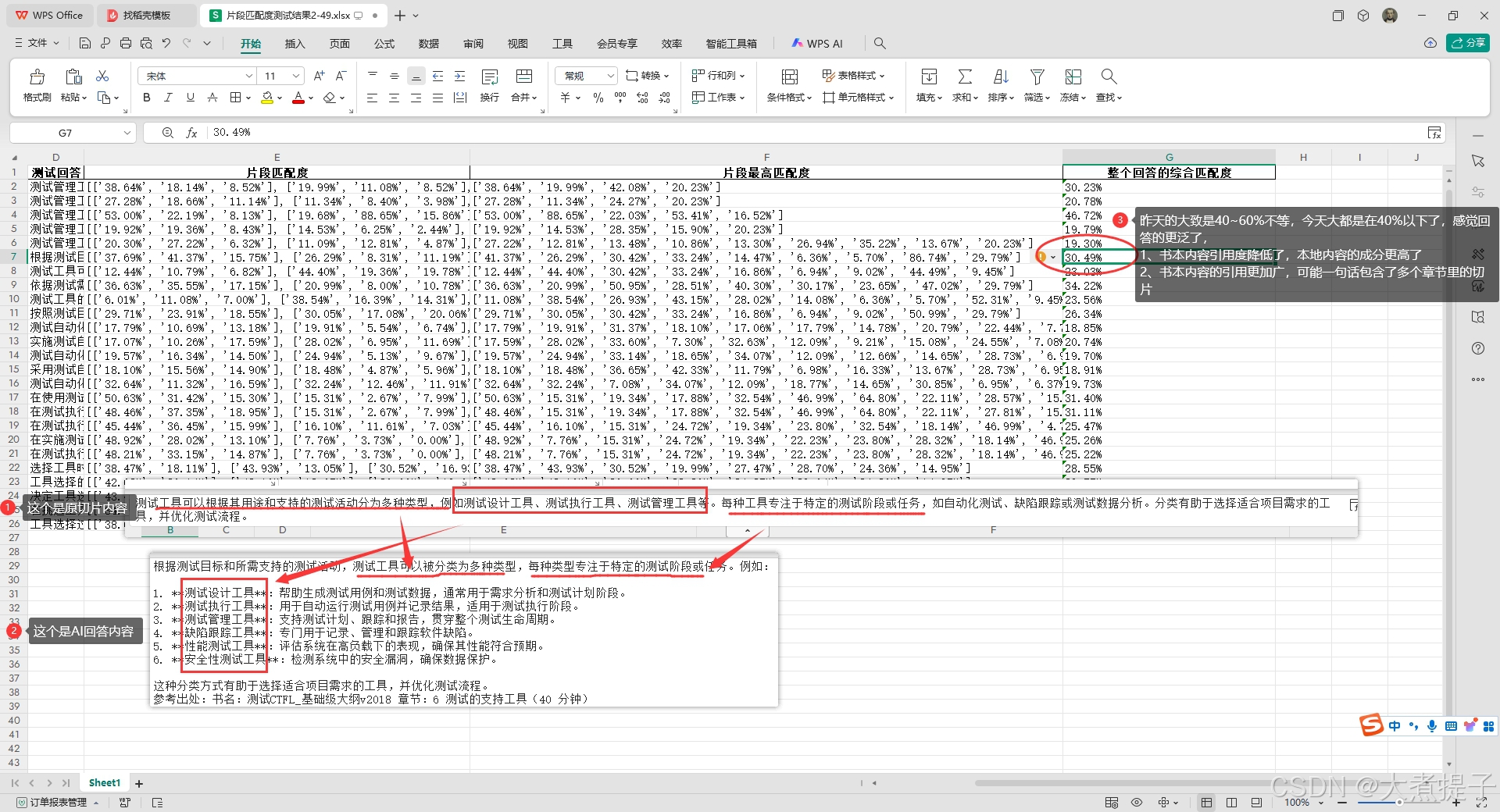
5、根据上面方法,把所有结果存在excel中,我们就可以根据AI回答来做分析了,举例:通过两天的测试,发现AI的回答更加的泛,AI自己根据生成的内容额外加了很多解释,由于回答的tokens基数增加,导致知识库里文章的内容匹配度降低,所以想要更加贴近知识库里的内容,我们可以让开发同学更换模型,或者提高向量匹配度或者采取更多其他的措施


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









