







一、SparkSQL运行架构
Spark SQL对SQL语句的处理,首先会将SQL语句进行解析(Parse),然后形成一个Tree,在后续的如绑定、优化等处理过程都是对Tree的操作,而操作的方法是采用Rule,通过模式匹配,对不同类型的节点采用不同的操作。
二、SparkSQL CLI
2.1 配置并启动
2.1.1 创建并配置hive-site.xml
在运行Spark SQL CLI中需要使用到Hive Metastore,故需要在Spark中添加其uris。具体方法是在SPARK_HOME/conf目录下创建hive-site.xml文件,然后在该配置文件中,添加hive.metastore.uris属性
| <configuration> <property> <name>hive.metastore.uris</name> <value>thrift://hadoopadmin:9083</value> <description>Thrift URI for the remote metastore. Used by metastore client to connect to remote metastore.</description> </property> </configuration> |
2.1.2 启动Hive
在使用Spark SQLCLI之前需要启动Hive Metastore(如果数据存放在HDFS文件系统,还需要启动Hadoop的HDFS),使用如下命令可以使HiveMetastore启动后运行在后台,可以通过jobs查询:
| $nohup hive --service metastore > metastore.log 2>&1 & |
2.1.3 启动Spark集群和Spark SQL CLI
| $cd /app/hadoop/spark-1.1.0 $sbin/start-all.sh $bin/spark-sql --master spark://hadoop1:7077 --executor-memory 1g |
这时就可以使用HQL语句对Hive数据进行查询,另外可以使用COMMAND,如使用set进行设置参数:默认情况下,SparkSQL Shuffle的时候是200个partition,可以使用如下命令修改该参数:
| spark-sql>SET spark.sql.shuffle.partitions=20; |
2.2 实战Spark SQL CLI
2.2.1 设置任务个数
设置任务个数,在这里修改为20个
| spark-sql>SET spark.sql.shuffle.partitions=20; |
2.2.2 运行SQL语句
第一步:应用数据库(注:不要一激动就忘了。否则会报错找不到源文件)
| spark-sql>SET spark.sql.shuffle.partitions=20; |
第二步:运行SQL语句
| spark-sql>select c.theyear,count(distinct a.ordernumber),sum(b.amount) from tbStock a join tbStockDetail b on a.ordernumber=b.ordernumber join tbDate c on a.dateid=c.dateid group by c.theyear order by c.theyear; |
2.2.3 查看运行结果
(小技巧:在编写SQL语句时,先列出问题中所涉及的所有名词SELECT,之后根据逻辑关系写GROUP(①select出现的②聚合函数))
三、Spark Thrift Server
3.1 简介
Ø ThriftServer是一个JDBC/ODBC接口
用户可以通过JDBC/ODBC连接ThriftServer来访问SparkSQL的数据
Ø 不同的用户之间可以共享数据
ThriftServer会启动了一个SparkSQL的应用程序
而通过JDBC/ODBC连接进来的客户端共同分享这个SparkSQL应用程序的资源
Ø ThriftServer还开启一个侦听器
等待JDBC客户端的连接和提交查询。
3.2 配置并启动
3.2.1 创建并配置hive-site.xml
(如果Spark SQL CLI已创建可追加)SPARK_HOME/conf目录下
设置hadoop1为Metastore服务器,hadoop2为Thrift Server服务器,配置内容如下:
| <configuration> <property> <name>hive.metastore.uris</name> <value>thrift://hadoop1:9083</value> <description>Thrift URI for the remote metastore. Used by metastore client to connect to remote metastore.</description> </property>
<property> <name>hive.server2.thrift.min.worker.threads</name> <value>5</value> <description>Minimum number of Thrift worker threads</description> </property>
<property> <name>hive.server2.thrift.max.worker.threads</name> <value>500</value> <description>Maximum number of Thrift worker threads</description> </property>
<property> <name>hive.server2.thrift.port</name> <value>10000</value> <description>Port number of HiveServer2 Thrift interface. Can be overridden by setting $HIVE_SERVER2_THRIFT_PORT</description> </property>
<property> <name>hive.server2.thrift.bind.host</name> <value>hadoop2</value> <description>Bind host on which to run the HiveServer2 Thrift interface.Can be overridden by setting$HIVE_SERVER2_THRIFT_BIND_HOST</description> </property> </configuration> |
3.2.2 启动Hive
在hadoopadmin节点中,在后台启动Hive Metastore(如果数据存放在HDFS文件系统,还需要启动Hadoop的HDFS):
| $nohup hive --service metastore > metastore.log 2>&1 & |
3.2.3 启动Spark集群和Thrift Server
第一步:在hadoop1节点启动Spark集群
| SPARK_HOME/sbin]$./start-all.sh |
第二步:在hadoop2节点上进入SPARK_HOME/sbin目录,使用如下命令启动Thrift Server
| SPARK_HOME/sbin]$ ./start-thriftserver.sh --master spark://hadoop1:7077 --executor-memory 1g |
3.3 实战Spark Thrift Server
3.3.1 远程客户端连接
可以在任意节点启动bin/beeline,用!connect jdbc:hive2://hadoop2:10000连接ThriftServer,因为没有采用权限管理,所以用户名用运行bin/beeline的用户hadoop,密码为空:
| $cd /app/hadoop/spark-1.1.0/bin $./beeline beeline>!connect jdbc:hive2://hadoop2:10000 |
3.3.2 缓存表数据
第一步:缓存数据
| beeline>cache table tbStock; beeline>select count(*) from tbStock; |
第二步:运行程序
| beeline>select count(*) from tbStock;; |
第三步:在另外节点再次运行
在hadoop3节点启动bin/beeline,用!connectjdbc:hive2://hadoop2:10000连接ThriftServer,然后直接运行对tbStock计数(注意没有进行数据库的切换):
| beeline>select count(*) from tbStock;; |
查看UI中的stage:Locality Level是PROCESS,显然是使用了缓存表。
结论:
从上可以看出,ThriftServer可以连接多个JDBC/ODBC客户端,并相互之间可以共享数据。顺便提一句,ThriftServer启动后处于监听状态,
用户可以使用ctrl+c退出ThriftServer;
而beeline的退出使用!q命令。
3.3.3 在IDEA中JDBC访问
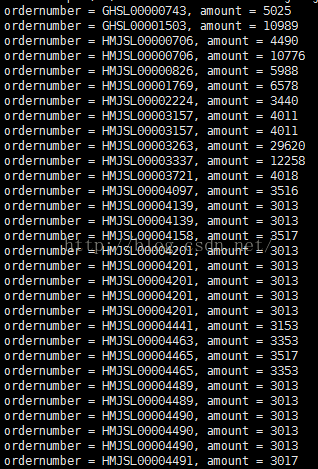
有了ThriftServer,开发人员可以非常方便的使用JDBC/ODBC来访问SparkSQL。下面是一个scala代码,查询表tbStockDetail,返回amount>3000的单据号和交易金额:
第一步:在IDEA创建class6包和类JDBCofSparkSQL
在IDEA中创建class6包并新建类JDBCofSparkSQL。该类中查询tbStockDetail金额大于3000的订单:
| package class6 import java.sql.DriverManager
object JDBCofSparkSQL { def main(args: Array[String]) { Class.forName("org.apache.hive.jdbc.HiveDriver") val conn = DriverManager.getConnection("jdbc:hive2://hadoop2:10000/hive", "hadoop", "") try { val statement = conn.createStatement //statement.executeQuery(“use hive;”) val rs = statement.executeQuery("select ordernumber,amount from tbStockDetail where amount>3000") while (rs.next) { val ordernumber = rs.getString("ordernumber") val amount = rs.getString("amount") println("ordernumber = %s, amount = %s".format(ordernumber, amount)) } } catch { case e: Exception => e.printStackTrace } conn.close } }
|
第二步:打包并运行
| ./spark-submit—class class6. JDBCofSparkSQL –master spark://master:7077 ../SQL.jar. |
注:①启动Thrift Server是在hadoop2上(保持运行)
②上述窗口保持运行,新开窗口运行bin]$./beeline
③在运行过程中发现:跑上述程序会报错
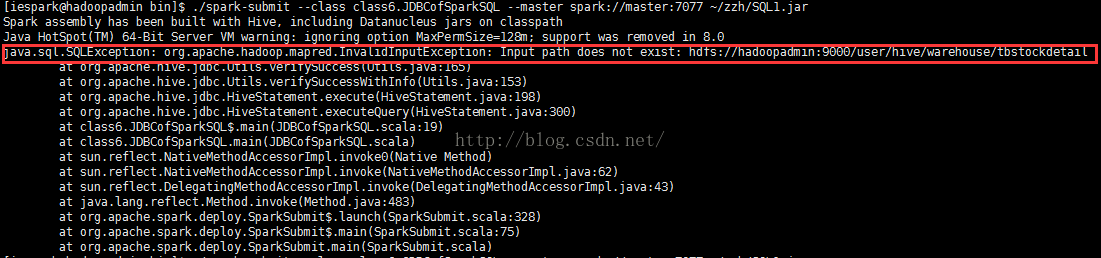
这是因为输入路径没有指定,需要在./beeline中use hive;
第三步:运行结果
四、SchemaRDD
4.1 简介
SparkSQL引入了一种新的RDD——SchemaRDD
SchemaRDD由行对象(Row)以及描述行对象中每列数据类型的Schema组成;SchemaRDD很象传统数据库中的表
SchemaRDD可以通过RDD、Parquet文件、JSON文件、或者通过使用hiveql查询hive数据来建立
SchemaRDD除了可以和RDD一样操作外,还可以通过registerTempTable注册成临时表,然后通过SQL语句进行操作。
4.2sqlContext演示
Spark1.1.0开始提供了两种方式将RDD转换成SchemaRDD:
l通过定义Case Class,使用反射推断Schema(case class方式)
l通过可编程接口,定义Schema,并应用到RDD上(applySchema方式)
前者使用简单、代码简洁,适用于已知Schema的源数据上;
后者使用较为复杂,但可以在程序运行过程中实行,适用于未知Schema的RDD上。
(演示前:启动HDFS-->Spark-->Spark-shell)
4.2.1 使用Case Class定义RDD演示
①定义Case Class,在RDD的Transform过程中使用CaseClass可以隐式转换为SchemaRDD
②再使用regidterTempTable注册成表
③注册成标之后就可以在sqlContext对表进行操作——(select/insert/join)
注:case class可以是嵌套的,也可以使用类似Sequences或 Arrays之类复杂的数据类型。
下面的例子
①定义一个符合数据文件/sparksql/people.txt类型的case clase(Person),然后将数据文件读入后隐式转换成SchemaRDD:people
②并将people在sqlContext中注册成表rddTable
③最后对表进行查询,找出年纪在13-19岁之间的人名
| 第一步:上传测试数据 $hadoop fs -mkdir /class6 $hadoop fs -copyFromLocal /home/hadoop/upload/class6/people.* /class6 $hadoop fs -ls / 第二步 定义sqlContext并引入包 //sqlContext演示 scala>val sqlContext=new org.apache.spark.sql.SQLContext(sc) scala>import sqlContext.createSchemaRDD 第三步 定义Person类,读入数据并注册为临时表 //RDD1演示 scala>case class Person(name:String,age:Int) scala>val rddpeople=sc.textFile("hdfs://hadoop1:9000/class6/people.txt").map(_.split(",")).map(p=>Person(p(0),p(1).trim.toInt)) scala>rddpeople.registerTempTable("rddTable") 第四步 在查询年纪在13-19岁之间的人员 scala>sqlContext.sql("SELECT name FROM rddTable WHERE age >= 13 AND age <= 19").map(t => "Name: " + t(0)).collect().foreach(println) 上面步骤均为trnsform未触发action动作,在该步骤中查询数据并打印触发了action动作 |
4.2.2 使用applySchema定义RDD演示
(未完待续)















 277
277











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









