







这次的代码是在前一次代码的基础上做一些点滴的修改.实现更好的封装,更漂亮的抽象.同时也是我们这个web server的最后一个版本了.这次的版本应该修改的幅度是最大的.
EPOLLONESHOT
即使我们使用
ET模式,一个socket上的某个事件还是可能被触发多次,这个并发程序中就会引起一个问题,比如说一个线程(或进程,下同)在读取完某个socket上的数据后开始处理这些数据,而在数据处理的过程中该socket上又有新数据可读(EPOLLIN)再次被触发,此时另外一个线程被唤醒来读取这些新的数据,于是就出现了两个线程同时操作一个socket的局面,这当然不是我们期望的,我们期望的是一个socket连接在任一时刻都只被一个线程处理,这一点可以使用epoll的EPOLLONESHOT事件实现. –[linux高性能服务器编程]
对于EOLLONESHOT这个事件,你可以认为,一旦某个线程接收到了注册了EPOLLONESHOT的文件描述符的信号,从这个时候器,这个文件描述符相当于从epoll的监听队列中移除了,这样的话,别的事件就不会来打搅你了.总之每次你处理完这个事件,你都要重置这个文件描述符上的EPOLLONESHOT事件,相当于重新注册一遍这个文件描述符.这样的话,当这个文件描述符上事件可读或者别的什么,可以被再次触发.
代码相当简单,你可以查看我的源码,这里就不贴了.
Buffer
前面的几个版本中,我们直接在HttpHandle这个类中放置字符数组和index来处理输入和输出,这样非常不便于管理,所以为了实现更好的抽象,我们重新设计了一个Buffer类.实现参考了muduo库,然后针对我们这个类做了特别的改进.(这个类在linux多线程服务端编程这本书里有很详细的介绍,你可以看一下.)
我们来看一下这个类:
class Buffer
{
public:
static const size_t kCheapPrepend = 8;
static const size_t kInitialSize = 1024;
private:
std::vector<char> buffer_; /* 用于vector来存储字符 */
size_t readerIndex_; /* 读指示器 */
size_t writerIndex_; /* 写指示器 */
static const char kCRLF[]; /* 其实就是\r\n啦! */
};看一下它的构造函数:
explicit Buffer(size_t initialSize = kInitialSize)
: buffer_(kCheapPrepend + initialSize)
, readerIndex_(kCheapPrepend)
, writerIndex_(kCheapPrepend)
{
}需要注意的是buffer_是一个字符vector,initialSize指的是初始化的大小.于别处不同是,readerIndex_和writeIndex_并不是从0开始的,而是在这前面留了一小撮的空间,在我们这个应用里可能没有什么卵用,但是,别的应用中,用处还是挺大的.
接下来是返回可读取的字节数的函数:
// 不修改类的成员变量的值的函数都要用const修饰,这是一种好的习惯
size_t readableBytes() const { /* 可读的字节数目 */
return writerIndex_ - readerIndex_;
}获取可写入的字节数目.
size_t writableBytes() const { /* 可写的字节数目 */
return buffer_.size() - writerIndex_;
}peek函数返回可以读的地址,需要注意的是返回的是一个const对象,即可以读但是不可以修改.
const char* peek() const { /* 偷看 */
return begin() + readerIndex_; // 从这里开始读
}为了方便request的处理,这个BUffer类设计了一个findEOF函数,具体的功能是返回从当前可读位置开始的第一个\n字符的地址.
const char* findEOF() const {
const void* eol = memchr(peek(), '\n', readableBytes());
return static_cast<const char*>(eol);
}基于这个函数,我们可以实现getLine函数:
bool getLine(char *dest, size_t len) { /* 读取一行数据 */
const char* end = findEOL();
if (end == 0) return false; /* 没有找到换行符 */
const char* start = peek();
assert(end >= start); /* 保证size是一个正数,然后下面static_cast转换的时候才会正确 */
ptrdiff_t size = end - start - 1;
if (len < static_cast<size_t>(size)) {
return false; /* 空间不够 */
}
std::copy(start, end - 1, dest); /* 去掉\r\n */
dest[size] = 0;
retrieveUntil(end + 1); /* 丢弃掉包括\n在内的数据,因为已经被读了 */
return true;
}这个函数很简单,那就是读取一行数据到dest所指的字符数组里面.并且将buffer的readerIndex_后移(通过函数retrieveUntil实现),如果没有发现\n或者dest的len不够,那就返回false不会对缓冲区做任何修改.
同时为了方便写缓冲区的输入,特别添加了appendStr函数:
void appendStr(const char* format, ...) { /* 格式化输入 */
char extralbuf[256];
memset(extralbuf, 0, sizeof extralbuf);
va_list arglist;
va_start(arglist, format);
vsnprintf(extralbuf, sizeof extralbuf, format, arglist);
va_end(arglist);
append(extralbuf, strlen(extralbuf));
}上面的函数调用append才正在将数据添加到缓冲区中:
void append(const char* data, size_t len) {
//mylog("before append");
ensureWritableBytes(len);
std::copy(data, data + len, beginWrite());
hasWritten(len);
}hasWrittern函数具体的作用是将writeIndex_指针后移.这里比较有意思的一个函数是ensureWritableBytes函数.它可以实现缓冲区的动态扩展.
void ensureWritableBytes(size_t len) { /* 保证有足够的写入空间 */
if (writableBytes() < len) {
makeSpace(len);
}
assert(writableBytes() >= len);
}如果可供写入的空间不足够的话,要makeSpace.
void makeSpace(size_t len) {
if (writableBytes() + prependableBytes() < len + kCheapPrepend) {
buffer_.resize(writerIndex_ + len); /* 重新分配存储空间 */
}
else { /* 如果剩余的空间大小足够了! */
assert(kCheapPrepend < readerIndex_);
size_t readable = readableBytes(); /* 可读的字节数目 */
std::copy(begin() + readerIndex_,
begin() + writerIndex_,
begin() + kCheapPrepend);
readerIndex_ = kCheapPrepend;
writerIndex_ = readerIndex_ + readable;
assert(readable == readableBytes());
}
}如果可供写的空间不够,就调用vector的resize函数重新分配空间,否则的话,空间是足够了,我们要将前面的已经空闲的,但是未被使用的空间回收,具体而言,就是将实际有用的数据往前面挪.
好了,具体的一些细节你可以查看具体的代码实现,这里就不在赘述.
HttpRequest
为了更好地处理连接,我们将处理对方发送的request的部分拆分了出来,组成了一个HttpRequest类,我们来分析一下这个类:
class HttpRequest
{
public:
enum HttpRequestParseState /* HttpRequest所处的状态 */
{
kExpectRequestLine,
kExpectHeaders,
kExperctBody,
kGotAll,
kError
};
public:
bool keepAlive_; /* 是否继续保持连接 */
bool sendFile_; /* 是否要发送文件 */
bool static_; /* 是否为静态页面 */
std::string method_; /* 方法 */
std::string path_; /* 资源的路径 */
std::string fileType_; /* 资源的类型 */
private:
static const char rootDir_[]; /* 网页的根目录 */
static const char homePage_[]; /* 所指代的网页 */
... ...
};这里不得不提的是这几个状态,刚开始的时候HttpRequest是处于 kExpectRequestLine状态,也就是渴求请求行,所谓的请求行,就是这个玩意:
GET / Http/1.1\r\n获得了请求行之后,立马转入kExpectHeaders,也就是渴求请求头状态,这个玩意就是请求行之后的数据,以一行\r\n作为终止符.我举一个栗子:
Accept: image/gif.image/jpeg,*/*\r\n
Accept-Language: zh-cn\r\n
Connection: Keep-Alive\r\n
Host: localhost\r\nUser-Agent: Mozila/4.0(compatible;MSIE5.01;Window NT5.0)\r\n
Accept-Encoding: gzip,deflate\r\n
\r\n注意,这里我将不可见字符都写出来了.
如果parse成功了,,那么就要HttpRequest立马转入kGotAll状态,表示万事俱备,否则,前面的kExpectHeaders以及kExpectRequestLine有任何一个出错,都将进入kError状态.
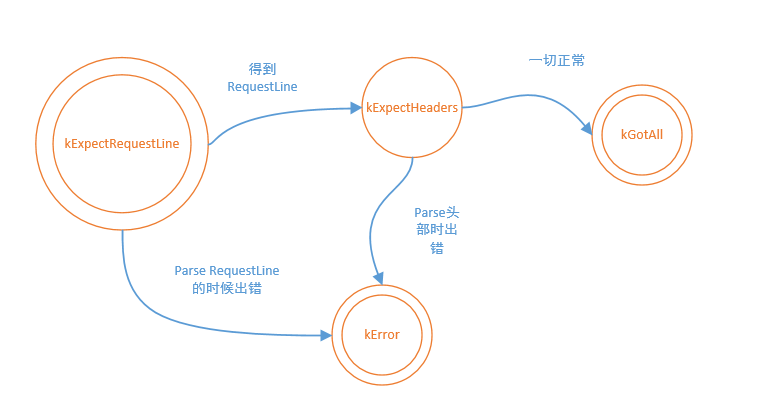
你可能会有疑问,为什么我们要用状态机的方式来处理连接?
很简单,因为用户的行为可能非常奇葩,他有可能不按套路出牌,最为重要的一点是,我们有的时候并不能一次性就全部读取到用户的request,他可能将一个request分成若干次来发送,每次我们读取不到完整的一行数据的时候,我们便要返回,继续去监听用户发送数据,然后继续返回到我们的HttpRequest,继续运行,这也就导致了我们必须记住之前执行到了那个状态,以便继续往下执行.用状态机是最好的解决办法.
用于处理用户发送的request的函数:
HttpRequest::HttpRequestParseState HttpRequest::parseRequest(Buffer& buf)
{
bool ok = true;
bool hasMore = true;
while (hasMore) {
if (state_ == kExpectRequestLine) {
const char* crlf = buf.findCRLF(); /* 找到回车换行符 */
if (crlf) { /* 如果找到了! */
ok = processRequestLine(buf);
}
else {
hasMore = false; /* 没有找到,可能表示对方还没有发送完整的一行数据,要继续去监听客户的写事件 */
}
if (ok) /* 请求行parse没有出错 */
state_ = kExpectHeaders;
else {
state_ = kError; /* 出现错误 */
hasMore = false;
}
}
else if (state_ == kExpectHeaders) { /* 处理头部的信息 */
if (true == (ok = processHeaders(buf))) {
state_ = kGotAll;
hasMore = false;
}
else {
/* 这里做了简化处理,头部不会出错,只要没有得到\r\n这样的结尾行都表示用户数据还没有发送完毕 */
hasMore = false;
}
}
else if (state_ == kExperctBody) { /* 暂时还未实现 */
}
}
return state_;
}接下来的都是一些小鱼小虾,比如说processRequestLine函数:
bool HttpRequest::processRequestLine(Buffer& buf)
{
bool succeed = false;
char line[256];
char method[64], path[256], version[64];
buf.getLine(line, sizeof line);
sscanf(line, "%s %s %s", method, path, version);
setMethod(method, strlen(method));
setPath(path, strlen(path));
/* version就不处理了 */
return true;
}还比如说processHeaders函数:
bool HttpRequest::processHeaders(Buffer& buf) /* 处理其余的头部信息 */
{ /* 其余的玩意,我就不处理啦! */
char line[1024];
char key[256], value[256];
while (buf.getLine(line, sizeof line)) {
if (strlen(line) == 0) { /* 只有取到了最后一个才能返回true */
return true;
}
if (strstr(line, "keep-alive")) {
keepAlive_ = true; /* 保持连接 */
}
}
return false;
}难度不大,这里不再一一赘述.
HttpHandle
HttpHandle类也变成了一个状态机.这个类的入口点只有一个,就是process函数.
void HttpHandle::process()
{
/*-
* 在process之前,只有这么一些状态kExpectRead, kExpectWrite
*/
switch (state_)
{
case kExpectRead: { /* 既然希望读,那就processRead */
processRead();
break;
}
case kExpectWrite: { /* 既然希望写,那就processWrite */
processWrite();
break;
}
default: /* 成功,失败,这些都需要关闭连接 */
removefd(epollfd_, sockfd_);
break;
}
/*-
* 程序执行完成后,有这么一些状态kExpectRead, kExpectWrite, kError, kSuccess
*/
switch (state_)
{
case kExpectRead: {
modfd(epollfd_, sockfd_, EPOLLIN, true); /* 继续监听对方的输入 */
break;
}
case kExpectWrite: {
modfd(epollfd_, sockfd_, EPOLLOUT, true); /* 监听TCP缓冲区可写事件 */
break;
}
default: {
removefd(epollfd_, sockfd_); /* 其余的都关闭连接 */
break;
}
}
}对于连接的处理也变成了状态的转换,它的状态有:
enum HttpHandleState {
kExpectReset, /* 需要初始化 */
kExpectRead, /* 正在处理读 */
kExpectWrite, /* 正在处理写 */
kError, /* 出错 */
kSuccess, /* 成功 */
kClosed /* 对方关闭连接 */
};刚开始的时候,HttpHandle处于kExpectReset状态,当客户端connect过来之后,主线程对HttpHandle进行初始化,初始化完成之后,进入kExpectRead状态,他要一直读取到对方完整的request才能进入下一个状态kExpectWrite,这期间,如果客户端数据分多次发送,HttpHandle就在这个kExpectRead打转,当然如果此时对方关闭了连接,我们进入kClose状态,在kExpectWrite状态中,如果数据没有发送完,一直处于这个状态,发送完成的话,进入kSuccess状态,整个连接过程中,一旦出错,都会进入kError状态.
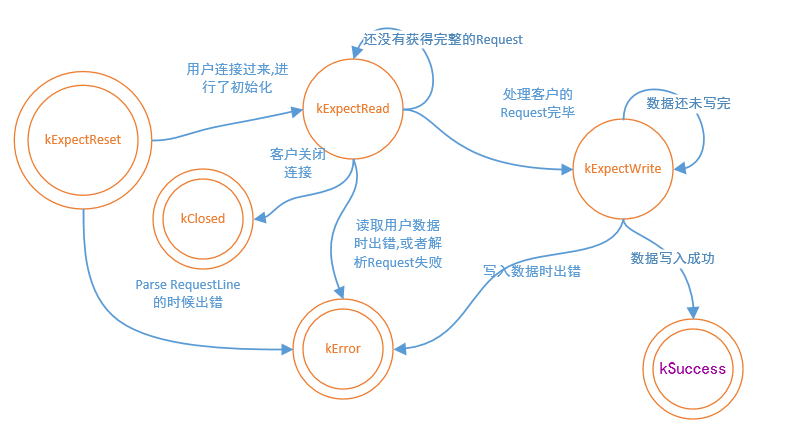
在processRead过程中:
void HttpHandle::processRead()
{
struct stat sbuf;
if (!read()) { /* 读取失败,代表对方关闭了连接 */
state_ = kClosed;
return;
}
/*-
* 试想这样一种情况,对方并没有一次性将request发送完毕,而是只发送了一部分,你应该如何来处理?正确的方式是继续去读,直到读到结尾符为止.
* 当然,我这里并没有处理request是错误的情况,这里假设request都是正确的,否则的话,就要关闭连接了.
*/
HttpRequest::HttpRequestParseState state = request_.parseRequest(readBuffer_);
if (state == HttpRequest::kError) /* 如果处理不成功,就要返回 */
{
state_ = kError; /* 解析出错 */
return;
}
else if (state != HttpRequest::kGotAll){ /* 没出错的话,表明对方只发送了request的一部分,我们需要继续读 */
return;
}
if (strcasecmp(request_.method_.c_str(), "GET")) { /* 只支持Get方法 */
clientError(request_.method_.c_str(), "501", "Not Implemented",
"Tiny does not implement this method");
goto end;
}
if (request_.static_) { /* 只支持静态网页 */
if (stat(request_.path_.c_str(), &sbuf) < 0) {
clientError(request_.path_.c_str(), "404", "Not found",
"Tiny couldn't find this file"); /* 没有找到文件 */
goto end;
}
if (!(S_ISREG(sbuf.st_mode)) || !(S_IRUSR & sbuf.st_mode)) {
clientError(request_.path_.c_str(), "403", "Forbidden",
"Tiny couldn't read the file"); /* 权限不够 */
goto end;
}
serveStatic(request_.path_.c_str(), sbuf.st_size);
}
else { /* Serve dynamic content */
clientError(request_.method_.c_str(), "501", "Not Implemented",
"Tiny does not implement this method");
goto end;
}
end:
state_ = kExpectWrite;
return processWrite();
}在processWrite过程中:
void HttpHandle::processWrite()
{
int res;
/*-
* 数据要作为两部分发送,第1步,要发送writeBuf_里面的数据.
*/
size_t nRemain = writeBuffer_.readableBytes(); /* writeBuf_中还有多少字节要写 */
if (nRemain > 0) {
while (true) {
size_t len = writeBuffer_.readableBytes();
//mylog("1. len = %ld", len);
res = write(sockfd_, writeBuffer_.peek(), len);
if (res < 0) {
if ((errno == EAGAIN) || (errno == EWOULDBLOCK)) { /* 资源暂时不可用 */
return;
}
state_ = kError;
return;
}
writeBuffer_.retrieve(res);
if (writeBuffer_.readableBytes() == 0) break;
}
}
/*-
* 第2步,要发送html网页数据.
*/
if (sendFile_) {
char *fileAddr = (char *)fileInfo_->addr_;
size_t fileSize = fileInfo_->size_;
while (true) {
res = write(sockfd_, fileAddr + fileWritten_, fileSize - fileWritten_);
if (res < 0) {
if ((errno == EAGAIN) || (errno == EWOULDBLOCK)) { /* 资源暂时不可用 */
return;
}
state_ = kError; /* 出现了错误 */
return;
}
fileWritten_ += res;
if (fileWritten_ == fileInfo_->size_)
break;
}
}
/* 数据发送完毕 */
reset();
if (keepAlive_) /* 如果需要保持连接的话 */
state_ = kExpectRead;
else
state_ = kSuccess;
}
代码都非常简单,应该能够读懂.
尾声
到了这里,我的代码写的就差不多了,还有一些小问题没有解决,那就是如果对方一直占用着资源怎么办?其实我们也有办法,那就是时间轮或者时间堆,如果过了一段时间客户端还没有发送数据过来的话,我们强行关闭连接,至于这些代码的实现,当做一个小小的测验,留给你吧.
其余的代码问题都不是很大,可能会有一点错误,但会慢慢纠正的.和前面一样的,参考代码在这里:https://github.com/lishuhuakai/Spweb
实践出真知
我读过UNP,APUE,CSAPP等一大堆的书,我觉得我足够聪颖,光读一读就能够透知一切,然而某一天,我发现我错了,读了这些书没多久,书里的只是只是在我的脑海里留下了一层印记,时光如同徐徐的长风,将这些印记一层层拂去,没过多久,我就忘得差不多了,然后我突然想写一些代码了,某一天我欣喜地发现,做过了一遍之后,这些东西长久地留存在我的脑海了,所以我想说的一句是,实践才能出真知.
当然光写也是挺傻逼的,有理论的指导,你才能写出更加漂亮的代码.程序员永远都需要理论和实践两条腿走路.
我起先也不知道应该做些什么,有些玩意感觉难度太大,一些又没多大意义,不过不管怎么样,总比不做要好,下一次,我想写一个ftp服务.
Over!















 5652
5652











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









