









目录
4、Inception Network(GoogleNet)
(本文是DeepLearning.AI 课程笔记)
一、卷积基本概念
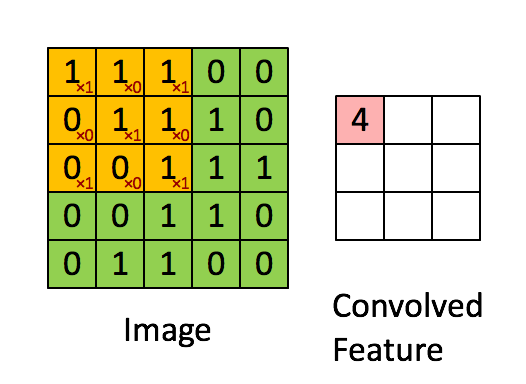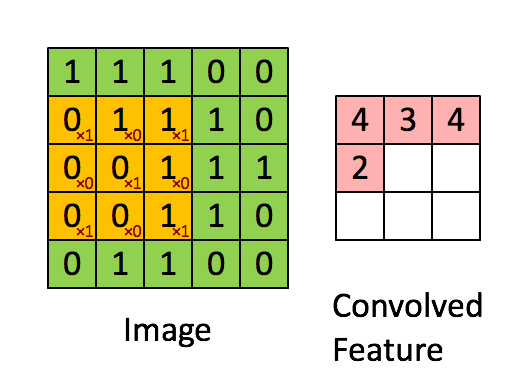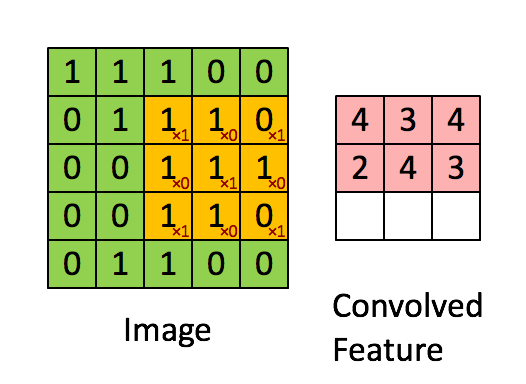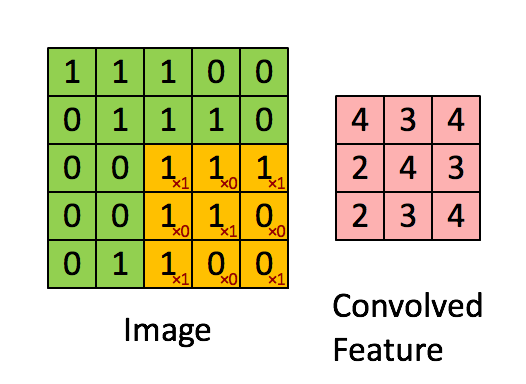
CNN的convolution(卷积) layer通过filter (过滤器,也称kernal,不同的filter可检测不同图像特征,如垂直边,水平边等) 对图像进行特征提取。例如,对一个图像用一个
的垂直边filter做卷积计算:

图像中数字是像素值,其中图像左上角一个和filter一样大的框的像素值经过和filter卷积计算(每个数字和filter对应位置的数字相乘,全部数字再相加)得出
图像左上角数字(
),图相框向右前进一格计算出第一行第二个数字...向下前进一格计算第二行数字....,其他同理。再如:

这个filter能检测出左侧图像中间的垂直边。这个filter旋转90度可得到水平边filter。filter值可作为参数通过数据自动学习。
Padding (填充) ----- 在卷积计算过程中的问题是,1)图像像素会缩小, 2)边缘的像素计算次数少于中间的像素,导致边缘像素重要程度不如中间像素。padding能解决这两个问题。一个 像素的图像和一个
的filter卷积, 得到一个
像素的图像。经过在图像周围padding一个像素(像素值为0),图像变成
,经过卷积,像素为

Padding的两个选项: “Valid Convolution” 是不填充,"Same Convolution"是填充使输出像素等于输入像素。
Stride(步长) ------ 在卷积计算中,每次filter前进的像素数称为步长,如果filter每次前进一个像素,则步长为1.
当输入像素为,filter的size为
, padding为p,stride为s时,输出像素为:
例如一个像素的图像,filter是
,padding = 0, stride = 1的卷积计算,输出像素为

再如,stride = 2时,输出像素为

卷积filter大小为3、步长为2、填充为0的二维卷积(蓝色为输入,绿色为输出):
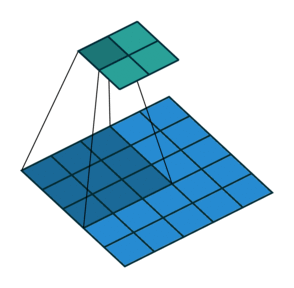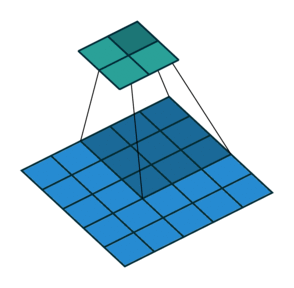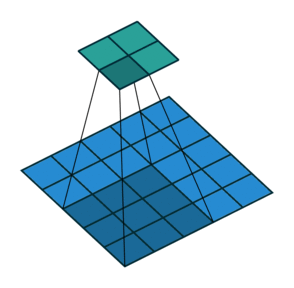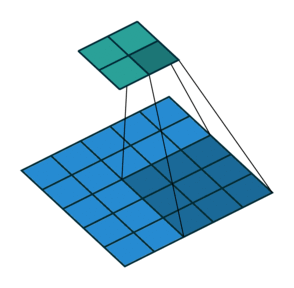
卷积filter大小为3、步长为1、填充为1的二维卷积(蓝色为输入,绿色为输出):

一个RGB图像的卷积计算举例如下,这个图像像素是,有Red,Green,Blue三个channel(通道),filter的channel数和图像一致。这个filter检测红色channel的垂直边界,生成
输出:

如果要同时检测垂直边和水平边,可使用两个filter,生成输出:

filter可类比为线性组合 的参数。这个
输出是像素的线性组合,还需对这个输出进行非线性的激活函数计算,形成一个conv layer。

这个conv layer的参数个数是( (filter的参数个数)+ 1 (bias) )* 2(filter个数) = 56。
Pooling(池化) layer,可以减少图像size,增加计算速度。Max pooling取每个窗口像素最大值,Average pooling取每个窗口全部像素平均值。Max pooling能提取一个区域的主要特征。pooling layer不含参数。hyperparameters包含stride, 窗口size, max/average。 一般选窗口,步长为2,长宽都减少1/2.

二、CNN结构
CNN包含了三种layer,conv(卷积) layer,pooling(池化) layer, fully connected(全连接) layer。
| summary | parameter | hyperparameter | |
| CONV (conv layer) | 卷积计算和激活函数组成,通过和不同filter的卷积计算,提取图像不同特征,filter值可学习得到 | filter的值,如 | filter数量、大小,stride(步长),padding(same, valid) size,激活函数 |
| POOL (pooling layer ) | 减少图像size,增加计算速度。Max pooling取每个窗口像素最大值,Average pooling取每个窗口全部像素平均值。Max pooling能提取一个区域的主要特征。 | none | 窗口大小,stride(步长),max/average |
| FC (fully connected layer) | 普通的神经网络layer,每个单元和前一层的每个单元相连 | 单元数量,激活函数 |
CNN结构举例:一般一个CNN会有数个 CONV - POOL,再连接数个FC layer,
如 input --CONV(ReLU) -- (Max)POOL-- CONV(ReLU) -- (Max)POOL -- FC(ReLU) -- FC -- output, 如图:

一个像素为的RGB图像,使用
的filter(同一个filter同时过滤三个channels),假如要提取8个特性,则有8个filters。则这个图像变为
。这个layer的参数包括filters 200个参数,和每个filter计算ReLU 增加的一个bias,总共有208个。再经过MAX POOL,图像变为
。经过下一个CONV的16个filters,图像变为
,经过MAX POOL,变为
。在与FC连接之前,要对多维数据扁平化,也就是将(Width,Height, Channels)的多维数据压缩为长度为
的一维数组。再与FC连接,此时和普通CNN相同。这个CNN的layer形状和参数为:
| Activation Shape | Activation Size | Parameters | |
| Input | (32, 32, 3) | 0 | |
| CONV1 (filters=8, size=5, stride=1) | (28, 28, 8) | ||
| POOL1 (size=2, stride=2) | (14, 14, 8) | 0 | |
| CONV2 (filters=16, size=5, stride=1) | (10, 10, 16) | ||
| POOL2 (size=2, stride=2) | (5, 5, 16) | 0 | |
| FC3 | (120, 1) | 120 | |
| FC4 | (84, 1) | 84 | |
| Softmax | (10, 1) | 10 |
为什么用卷积神经网络而不是传统神经网络?
1、参数复用,减少参数数量:假如图像连接shape为(120, 1)的FC而不是CONV,需要的参数数量为:
个,而用CONV1,参数数量仅为208. 在图像中减少因参数过多造成的过拟合。 一个filter检测一种特性,如垂直边,这种特性可能在图像中多处出现,复用filter可训练更好的模型。
2、连接稀疏性: 传统神经网络是全连接,输出的每个unit都会被输入的全部unit影响,而图像的每个区域都有不同的特性,通常不希望被其他区域影响。CNN的CONV输出只跟输入的局部区域有关联。
三、CNN举例
1. AlexNet
AlexNet将ImageNet LSVRC-2010比赛中的120万张高分辨率图像分为1000个不同的类别。在测试数据上,取得了37.5%和17.0%的前1和前5的错误率。

2. ResNets
深度网络的好处是可以表达复杂函数,不同层数的抽象程度可以不断增加。主要问题是:1)训练深度网络反向传播时每一层的梯度都呈指数级下降,容易导致梯度消失/爆炸的问题。这个问题通过BatchNorm,使用ReLU激活函数等解决。2)随着网络深度的增加,准确率达到饱和,然后迅速退化,这并不是过拟合导致的,一个合理的深度模型增加层会导致更高的错误率。残差网络可解决这个问题。残差网络增加了恒等映射的shortcut:


在前向传播中,增加了恒等映射, ,x为浅层输出,H(x)为深层输出,F(x)为夹在二者中间的的两层变换,当浅层的x代表的特征已经最优(optimal),如果任何对于特征x的改变都会让loss变大的话,F(x)会自动趋向于学习成为0,x则从恒等映射的路径继续传递。这样就在前向过程中,当浅层的输出已经最优(optimal),让深层网络后面的层能够实现恒等映射的作用。
在反向传播中,residual block的参数会明显减小,增加了损失值相对参数的敏感度,并起到了正则化作用。举例,假如x=10, H(x) = 11, 参数W为1.1,增加恒等映射,F(x)成为x的线性变换,参数变为0.1。其次,因为有恒等映射的存在,梯度传导也增加了更简便的途径,仅通过ReLU就可以传导梯度。
Deep Residual Learning for Image Recognition 文中ResNets的基本框架和plain网络的基本相同,除了在每一对3*3的滤波器上添加了一个shortcut连接。所有的shortcuts都是恒等映射,并且使用0对增加的维度进行填充(选项 A)。因此他们并没有增加额外的参数。

picture from : Deep Residual Learning for Image Recognition. 左:VGG-19模型 (196亿个FLOPs)作为参考。中:plain网络,含有34个参数层(36 亿个FLOPs)。右:残差网络,含有34个参数层(36亿个FLOPs)。虚线表示的shortcuts增加了维度。
3、NIN(Network In Network )
NIN使用了卷积:

单通道的 卷积是用filter值乘以每个像素值。多通道
卷积的filter对每个像素计算该像素全部通道的线性组合,然后激活函数计算,filter值是线性参数值。
卷积综合多通道特征图信息。通过控制filter数量可对原图像通道升维或降维。如图,三通道图像如果使用2个filter,则降维到2通道。通过降维可减少参数数量。对原图像通过非线性计算增加非线性特性。
4、Inception Network(GoogleNet)
Inception网络的作用是不需要选择,
,
filters,或Pooling,而是叠加全部filters,由网络自行决定参数。

这个架构的计算量很大,举例,32个的filters对
图像:

生成的输出块中每个像素都进行了
次乘法计算(及一次累加计算),总共
次乘法计算。为减少计算量,在CONV之前增加一个
的bottleneck filter用来降维,这个
卷积也增加了一个ReLU激活函数计算。

乘法计算减少为 次。
降维后的一个inception module如图:

pic from Going deeper with convolutions --Christian Szegedy et al. arXiv:1409.4842v1 [cs.CV] 17 Sep 2014

所有的卷积都使用了ReLU,包括Inception模块内部的卷积。网络输入是均值为0的RGB颜色空间,大小是224×224。“#3×3 reduce”和“#5×5 reduce”表示在3×3和5×5卷积之前,降维层使用的1×1滤波器的数量。在pool proj列可以看到内置的最大池化之后,投影层中1×1滤波器的数量。所有的这些降维/投影层也都使用了ReLU。
包括辅助分类器在内的附加网络的具体结构如下:
- 一个滤波器大小5×5,步长为3的平均池化层,导致(4a)阶段的输出为4×4×512,(4d)的输出为4×4×528。
- 具有128个滤波器的1×1卷积,用于降维和修正线性激活。
- 一个全连接层,具有1024个单元和修正线性激活。
- 丢弃70%输出的丢弃层。
- 使用带有softmax损失的线性层作为分类器(作为主分类器预测同样的1000类,但在推断时移除)。

含有的所有结构的GoogLeNet网络 pic from Going deeper with convolutions --Christian Szegedy et al. arXiv:1409.4842v1 [cs.CV] 17 Sep 2014
References:
【1】Convolutional Networks for Images, Speech and Time Series ---Yann LeCun,Yoshua Bengio
【2】https://blog.csdn.net/weixin_43624538/article/details/96917113
【3】https://blog.csdn.net/weixin_43624538/article/details/85049699
【4】Going deeper with convolutions --Christian Szegedy et al. arXiv:1409.4842v1 [cs.CV] 17 Sep 2014
















 1266
1266











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











