







在 Hadoop集群安装部署---单节点伪分布式 基础之上进行扩展
一:slave环境配置
1、设置静态ip(manual)
master:
IP地址:192.168.77.70
子网掩码:255.255.255.0
网关:192.168.77.2
slave:
IP地址:192.168.77.80
子网掩码:255.255.255.0
网关:192.168.77.2
2、修改主机名:
vi /etc/sysconfig/network
master:
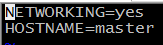
slave:
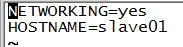
3、ip地址与主机名对应:
vi /etc/hosts
master:

slave:

 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 1653
1653











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









