







 超级会员免费看
超级会员免费看
 本文详细分析了 Flink-Streaming-Platform-Web 中的任务列表模块,包括页面交互、新增、修改任务的流程。重点讲解了提交作业时的sql语句执行过程,涉及核心模块的检查、配置参数检测以及任务状态更新。最后,提供了相关参考链接。
本文详细分析了 Flink-Streaming-Platform-Web 中的任务列表模块,包括页面交互、新增、修改任务的流程。重点讲解了提交作业时的sql语句执行过程,涉及核心模块的检查、配置参数检测以及任务状态更新。最后,提供了相关参考链接。
目录
1. 任务列表模块分析
任务列表模块如下图所示,其中新增和修改任务操作,对应到 job_config表里面插入、更新一条记录。在插入、更新时对任务配置进行检测。
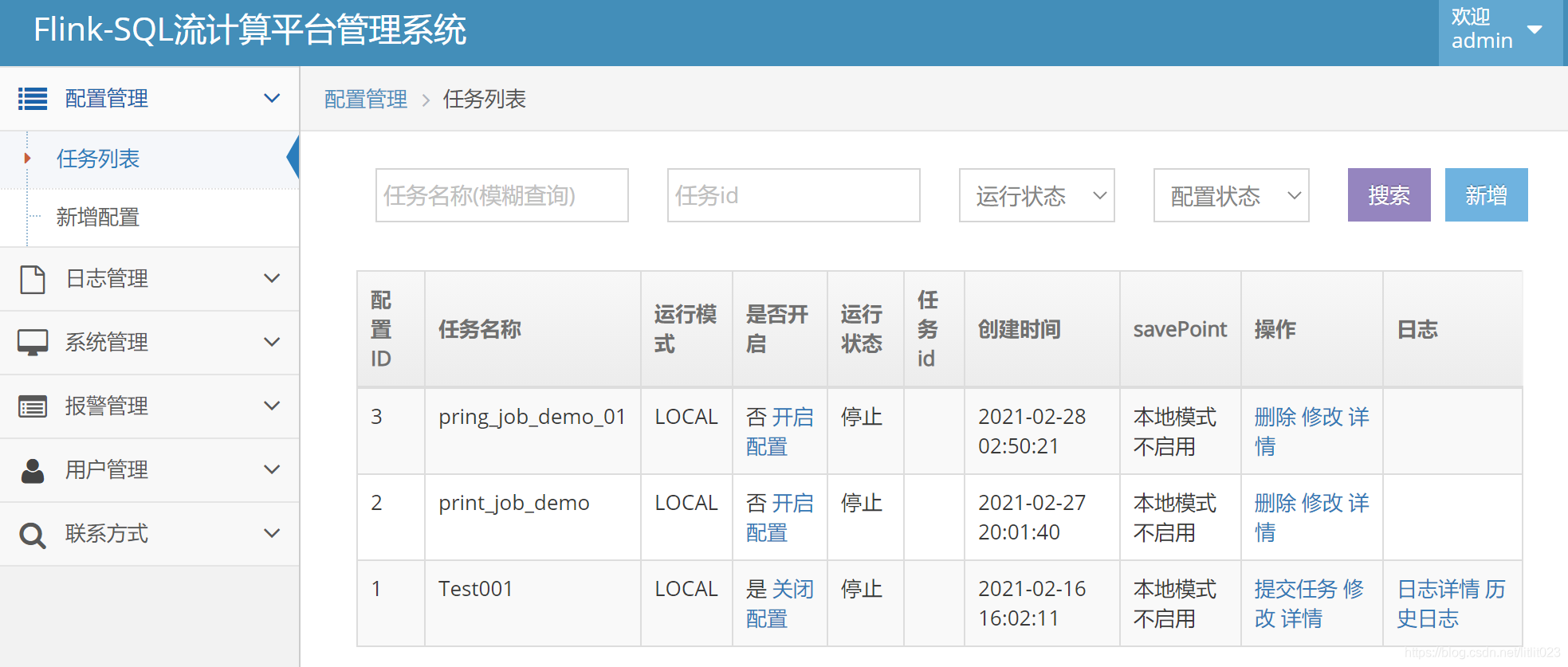
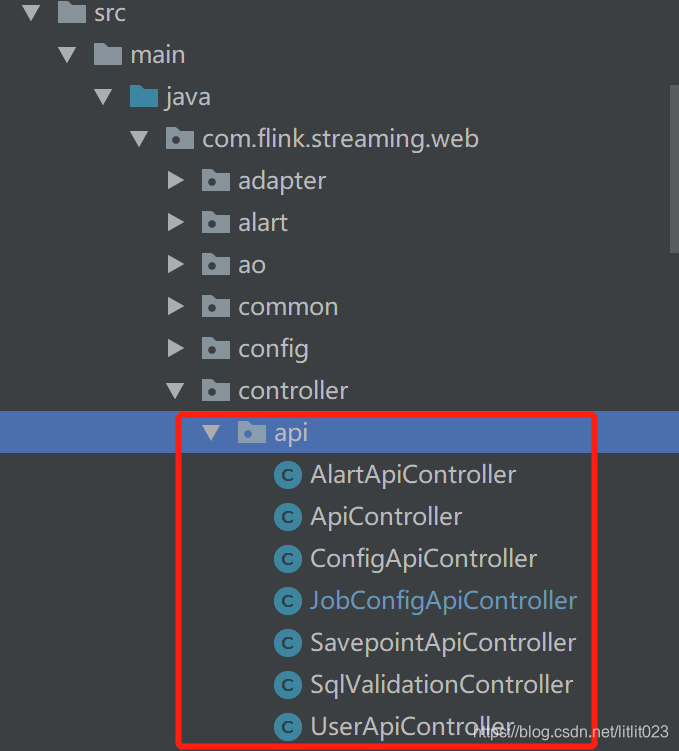
1.0 页面交互部分代码结构
0、与页面交互的Controller API,代码位于:
-> flink-streaming-web 模块
-> controller包
-> api 包里面
1.1 新增任务流程
-> addPage.ftl 页面
-> $.post("../api/addConfig"
-> JobConfigApiController.addConfig()方法
-> JobConfigApiController.checkUpsertJobConfigParam() 检测传过来的参数
[主要检测任务名称命名规则、sql语句不为空、checkpointPath、第三方jarPath路径]
-> 调用JobconfigServiceImpl.addJobConfig()方法将一条记录插入到 job_config 表 【插入前会检测是否已存在同名的 job。同时根据部署模式来检测对应的参数值是否有空缺】
1.2 修改任务流程
-> editPage.flt
-> $.post("../api/editConfig"
-> JobConfigApiController.editConfig()方法
-> JobConfigApiController.checkUpsertJobConfigParam() 检测传过来的参数 【添加和更新job config都会调用该方法】
-> 根据id从mysql中获取该任务的一条记录(并判断记录是否为null,判断任务是否处于open状态)
-> JobConfigServiceImpl.updateJobConfigById(jobConfigDTO)中,根据 deploy mode,检测页面上系统配置flink配置文件
如 flink_home、flink_streaming_platform_web_home、flink_rest_http_address、yarn_rm_http_address
-> 保存任务记录
1.3 提交作业
-> listPage.ftl
-> $.post("../api/start"
-> JobConfigApiController.start()
-> JobServerAO getJobServerAO(id) 根据id从 job_config 表中获取该条记录。根据该条记录的 deployMode,返回 jobStandaloneServerAO 或者 jobYarnServerAO对象实例
-> 调用 jobServerAO.start(Long id, Long savepointId, String userName)
检查该 job是否运行提交运行【是否已开启,是否已经处于启动、运行状态】
从 system_config 表中,获取 type=SYS 的配置参数 K-V,结果是多条,转化为 map<k,v>
调用jobServerAO.checkSysConfig()检测系统参数【FLINK_HOMES是否存在,deployMode=LOCAL&&配置了flink_rest_http_address,或者deployMode=STANDALONE&&配置了flink_rest_ha_http_address】
将要运行的job的 sql 内容,保存成文件,放到 flink_streaming_platform_web_home/sql下 (文件命名格式是 flink_sql_jobid.sql)
构造 job运行时参数 jobRunParamDTO
构造运行时日志
更新 job_config 表中,任务的运行状态为Running
-> jobServerAO.aSyncExec(jobRunParamDTO, jobConfigDTO, jobRunLogId)
线程池异步提交 job
构造 flink run 命令字符串 /work/flink/flink-1.12.0/bin/flink run -d -c com.flink.streaming.core.JobApplication /work/flink/flink-streaming-platform-web/lib/flink-streaming-core-1.2.0.RELEASE.jar -sql /work/flink/flink-streaming-platform-web/sql/job_sql_4.sql
-> CommandAdapterImpl.startForLocal(String command, StringBuilder localLog, Long jobRunLogId)
执行linux命令,提交任务Process pcs = Runtime.getRuntime().exec(command);从执行结果中获取 appid,并不断从命令行输入日志中,将日志内容保存到数据库中
结果如下所示:
-> flinkHttpRequestAdapter.getJobInfoForStandaloneByAppId(appId, jobConfig.getDeployModeEnum());
通过http请求flink,获得任务运行日志 http://vm01:8091/jobs/jobid
返回作业运行的 jid、state、error 信息
-> jobServerAO.updateStatusAndLog()
更新作业运行状态,和日志信息,分别保存到 job_config、job_run_log
//通过执行任务提交命令/work/flink/flink-1.12.0/bin/flink run -d -c com.flink.streaming.core.JobApplication /work/flink/flink-streaming-platform-web/lib/flink-streaming-core-1.2.0.RELEASE.jar -sql /work/flink/flink-streaming-platform-web/sql/job_sql_4.sql
,返回的日志如下
#############ddl#############
CREATE TABLE source_table_02 (
f0 INT,
f1 INT,
f2 STRING
) WITH (
'connector' = 'datagen',
'rows-per-second'='5'
)
#############ddl#############
CREATE TABLE print_table_02 (
f0 INT,
f1 INT,
f2 STRING
) WITH (
'connector' = 'print'
)
#############dml#############
insert into print_table_02 select f0,f1,f2 from source_table_02
Job has been submitted with JobID 41f7d59c35ad45b3c652d3629cf3d92c
1.4 提交作业时,执行sql语句core模块分析
/work/flink-1.12.0/bin/flink run -d -c com.flink.streaming.core.JobApplication /work/flink/flink-streaming-platform-web/lib/flink-streaming-core-1.2.0.RELEASE.jar -Xdebug -Xrunjdwp:transport=dt_socket,address=9901-sql /work/flink/flink-streaming-platform-web/sql/job_sql_4.sql
flink-streaming-core 模块的main方法,执行传过来的sql,最终是通过 table api来执行没一条sql语句的 TableEnvironment
-> 上述命令在linux环境下执行后,会提交给flink-streaming-core模块的 JobApplication 中的main方法,将string []args 参数构建为 JobRunParam 对象。
其中解析arg [] 时用到了 ParameterTool工具类。
-> 将sql文件中的内容,读出来每一行成为List<String>。同时解析SqlParser.parseToSqlConfig(sqlList),转化为List<ddl>和List<dml>
-> env中设置udf、设置 checkpoint、设置 tableconfig
-> 执行 tenv.executeSql(sql)。ddl、view和dml操作
例如代码中分别调用执行
//执行ddl
Executes.callDdl(tEnv, sqlConfig);
//执行view
Executes.callView(tEnv, sqlConfig);
//执行dml
Executes.callDml(tEnv, sqlConfig);
2. 参考链接
https://github.com/zhp8341/flink-streaming-platform-web
https://blog.csdn.net/litlit023/article/details/113776709


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









