






- 数据库问题分析
- 关于数据库日志报错
- 关于数据库事务ID
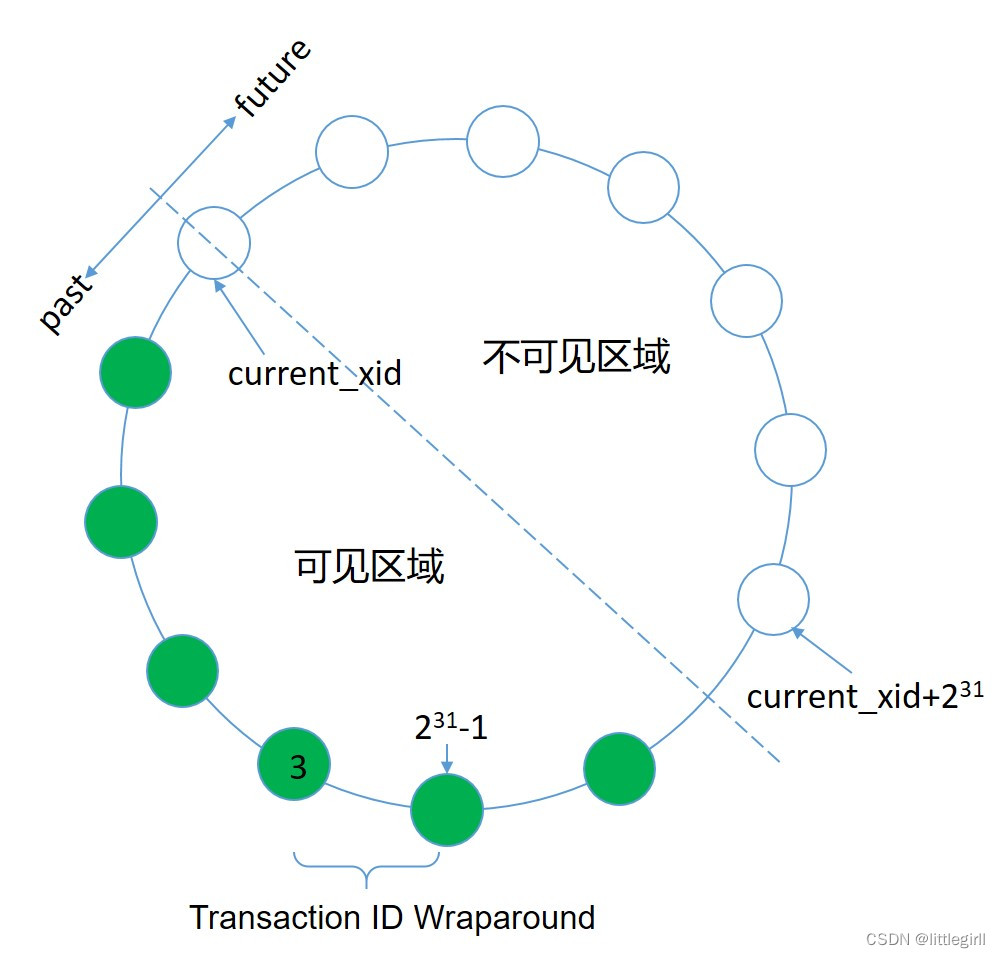
关于数据库的事务ID解释如下:
MVCC模型使用事务ID(XID)来确定哪些行在查询或事务开始时可见。XID是一个32位的值,数据库理论上可以运行超过40亿个事务。数据库对XID使用了模2运算,这允许事务ID回卷,每当事务ID达到最大值时会重新从0开始计算。如图所示,当事务号为231-1时,下一个事务号取值为3,而不是继续增加。对于任何给定的XID,可能有大约20亿个过去的XID和20亿个未来的XID。为了防止这种情况,数据库有一种特殊的XID,称为FrozenXID,它总是被认为比任何常规的XID都要古老。在20亿个事务中,一行的xmin必须替换为FrozenXID,使得数据对所有的后续事务都可见,这是VACUUM命令执行的功能之一。
至少每20亿个事务清空一次数据库可以防止XID的重写。数据库会监视事务ID,并在需要VACUUM操作时发出警告。所以在日志中看到了因为事务ID的回卷导致的告警如下,如果没有及时处理,则数据库会不再接收新的操作。
WARNING: database "dgtfc" must be vacuumed within number_of_transactions transactions
FATAL: database is not accepting commands to avoid wraparound data loss in database "dgtfc"
- 关于数据库日志报错
基于以上对数据库事务号的说明,当数据库的事务号出现了回卷时,数据库日志报如下信息:
WARNING: database "dgtfc" must be vacuumed within number_of_transactions transactions
FATAL: database is not accepting commands to avoid wraparound data loss in database "dgtfc"
这个时候需要手动介入解决数据库事务号回卷问题。解决的方法可以采取:1. 对全库做vacuum freeze。2.对数据库中的表(在pg_class系统表中的age(relfrozenxid)的值达到或者接近21亿)做vacuum freeze
- 报错原因分析及解决
分布式数据库内的操作一分析操作为主,数据以批量写入,多次查询。在这样的环境下数据库的事务号消耗很慢,因为select语句并不会导致数据行事务号的改变。但现场数据库从日志分析时发现数据库内有大量的单条insert操作,并且操作频繁,从而导致数据库事务号的迅速增长,大概每3个星期就会导致日志中报错的现象。解决方法:1.建议将单条insert语句改为批量入库的方式(java批量提交、copy命令)。2.定时执行对全库的vacuum操作。
经沟通目前部分数据入库的操作已经采用了批量的方式,部分数据实时性高所以未做改动[沐浴阳光1] 。针对这种情况,决定采用定时执行vacuum的方式,操作系统配置crontab作业,每周六0点执行vacuumdb –F dgtfc
同时对数据库日志的筛选,将insert操作频繁的表进行梳理,建议从业务层面修改这部分表的数据入库操作为批量提交。[沐浴阳光2]
全库做vaccum操作虽然对空间的回收和事务号的回收效果最好,但对资源的使用及表的加锁会影响到同时的其他用户操作和作业调度执行,所以也可以考虑只对insert操作频繁的表做vaccum,虽然效果不如全库做vacuum好,但是可以缩短对数据库的影响,后续可以在对表的梳理的前提下调整vacuum策略,改为对表做事务号的回收操作,以减少影响[沐浴阳光3] 。
- 使用建议
根据以上分析,造成数据库事务号消耗迅速的主要原因是应用使用了大量的单条insert语句实现数据入库,从入库效率、查询效率及事务号消耗三个方面,建议在规划数据库表的存储方面及数据入库方式等方面遵循下面的建设原则
- 关于表的存储模式:
- 新创建的表使用追加优化表+列存方式,一方面提高数据入库效率,同时可以压缩减少数据库空间使用。
创建表的语法:
create table test_ao(id int) with (appendonly=true,compresslevel=5, compresstype=zlib,orientation=column) distributed by (id);
- appendonly=true是表示AO(Append-optimized)存储表的表示,参数为true和false,例如appendonly=true或appendonly=false
- compresslevel是压缩率,取值为1~9,一般选择5就足够了,值越高压缩率越高
- orientation是对列进行压缩,写法只有orientation=column
- 关于表的数据分布:
- 对任何表,明确指定分布键,或者使用随机分布,而不是依赖缺省的行为。
- 只要有可能,应该只使用一个字段作为分布键,而不是使用组合字段作为分布键。
- 应该尽可能的避免使用日期或者时间字段来作为分布键。因为,一般不会使用这种字段来与其他的表进行关联查询。
- 为了改善大表之间的关联性能,应该考虑将大表之间关联的字段作为分布键。注意,这里说的是大表之间的关联,但凡涉及与小表关联的场景,完全不应该作为选择分布键的考虑因素。
创建表的语法:
GP的分布键作用是保证数据能够均匀分布在不同的存储节点上,充分利用并行计算带来的高性能。GP的分布策略包括HASH分布和随机分布。
HASH分布的关键字是:distributed by(列名)
随机分布的关键字是:distributed by randonly
在创建表或者修改表定义的时候,必须使用distributed by来执行分布键,从而使数据均匀的存储在不同的segment上。
(1)、声明hash分布
create table 表名(
id integer primary key, {主键约束}
name text not null, {非空约束}
price numeric check(price>0), {检查约束}
type integer unique {唯一约束}
)distributed by(id);
(2)、声明随机分布
create table 表名(
id integer primary key, {主键约束,这里就不能在声明主键约束}
name text not null, {非空约束}
price numeric check(price>0), {检查约束}
type integer unique {唯一约束,这里就不能在声明唯一约束}
)distributed by randonly; {指定随机分布}
- 对插入频繁的表定期做vacuum
通过对数据库日志和应用的分析两个方面,可以得到对数据库事务号影响最大的若干表的名称,为了提高数据库事务号回收的效率,可以在业务低峰期定期对这些表做回收事务号的操作,例如:在每周6的下午2点做表的vacuum
在mppadmin用户的crontab配置:
0 14 * * 6 source /home/mppadmin/mpp/mpp_path.sh;vacuum freeze table_name
- 周六凌晨库内作业阻塞
基于3.1小节对日志报错的原理分析和对数据库做定时vacuum操作。因为vacuum回收事务号的是一个占用系统I/O资源并且对表加锁的操作,一般会安排在业务低峰期执行。但现场数据库在凌晨有库内批量的调度作业运行,所以导致了9月9日批量操作的阻塞现象。
目前通过对数据库资源和压力的监控结果分析发现,数据库一般在下午时段压力较上午会有所减少,计划将周六0点开始的vacuum操作改为下午时段进行。以下为3个节点两天的nmon监控结果:
node125(管理/计算节点)
CPU:
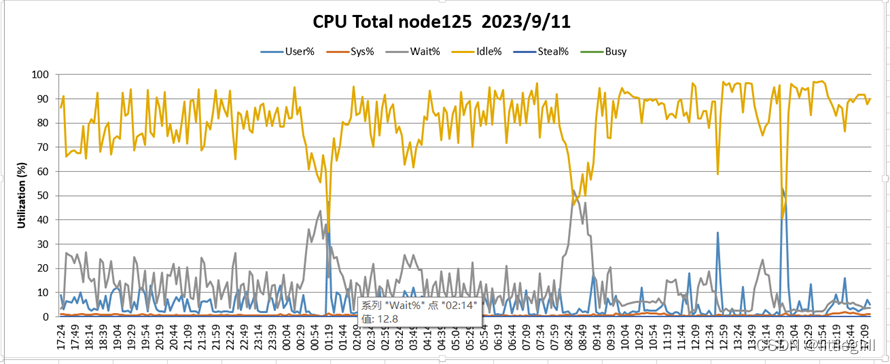
9.11监控结果

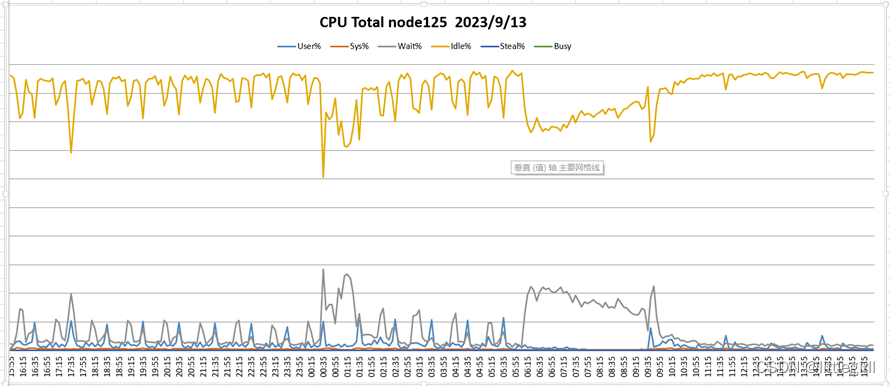
9.13监控结果

磁盘:
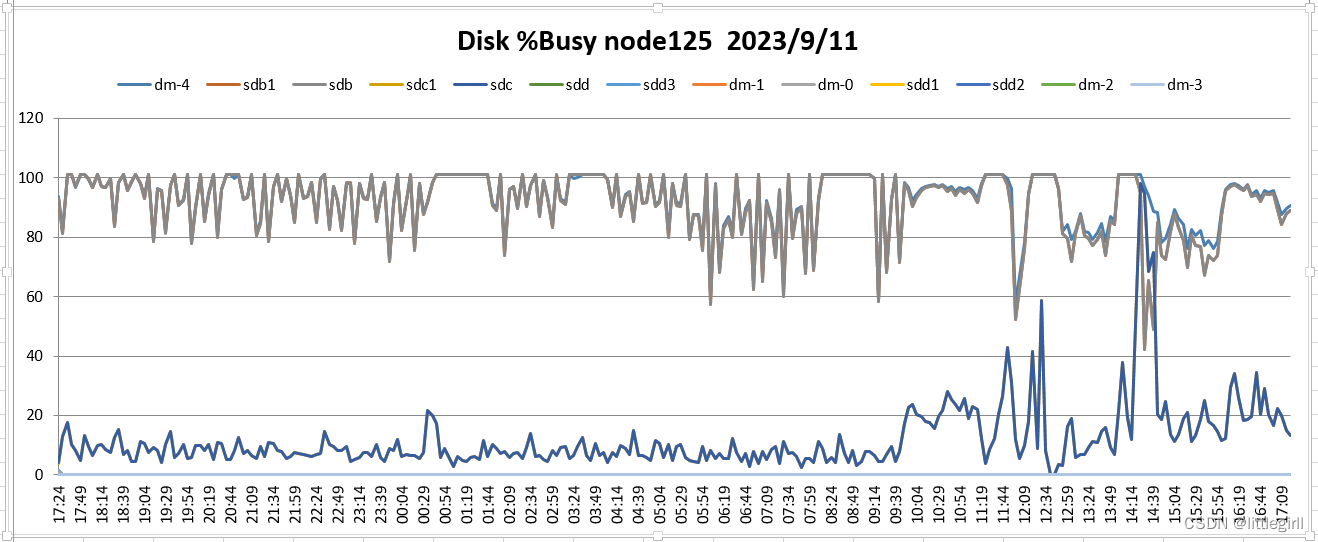
9.11监控结果

9.13监控结果

进程:
9.11监控结果

9.13监控结果

内存:
9.11监控结果

9.13监控结果

node126(管理/计算节点)
CPU:
9.11监控结果

9.13监控结果

磁盘:
9.11监控结果

9.13监控结果

进程:
9.11监控结果

9.13监控结果

内存:
9.11监控结果

9.13监控结果

node127(计算节点)
CPU:
9.11监控结果

9.13监控结果

磁盘
9.11监控结果

9.13监控结果

进程:
9.11监控结果

9.13监控结果

内存:
9.11监控结果

9.13监控结果

从两天的nmon监控结果看:
Cpu:资源充足,平均cpu使用率低于10%
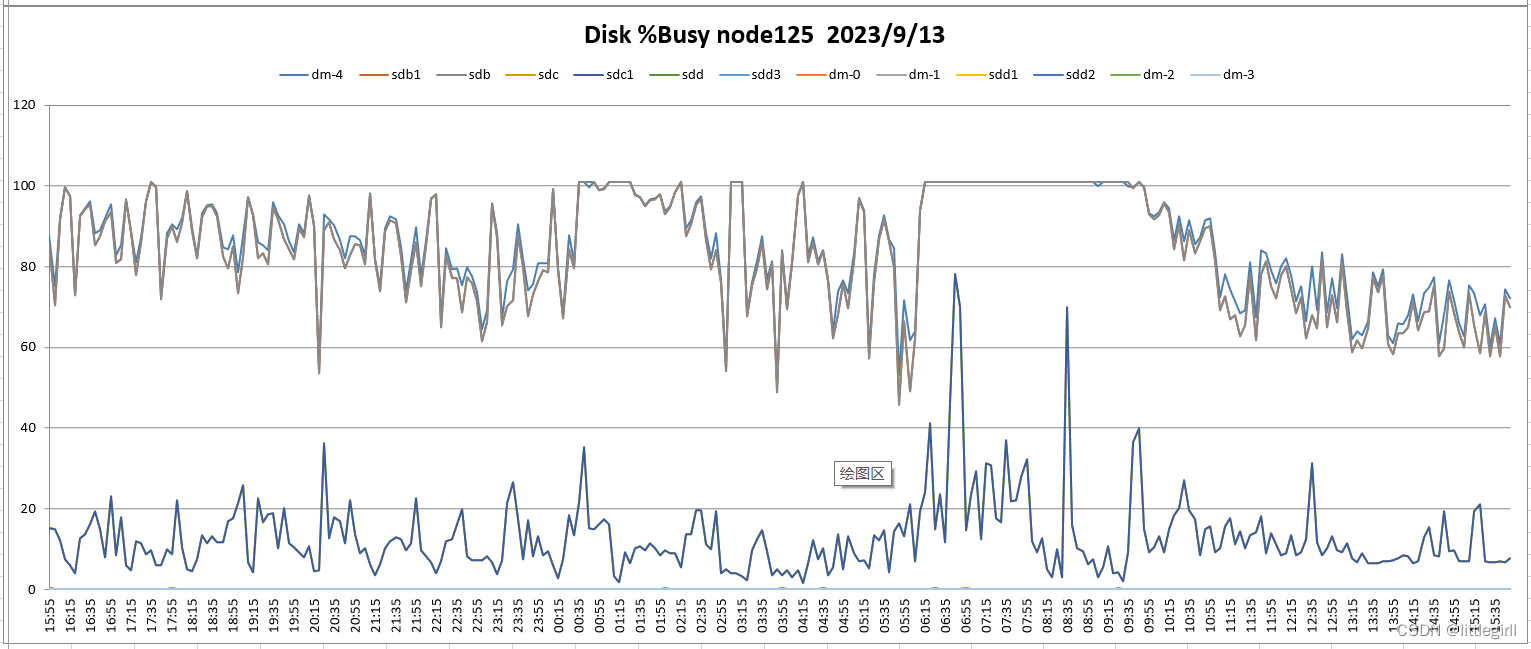
磁盘:资源紧张,大部分时间使用率在100%。每天在11:00以后,相对上午使用情况有所缓解[沐浴阳光4]
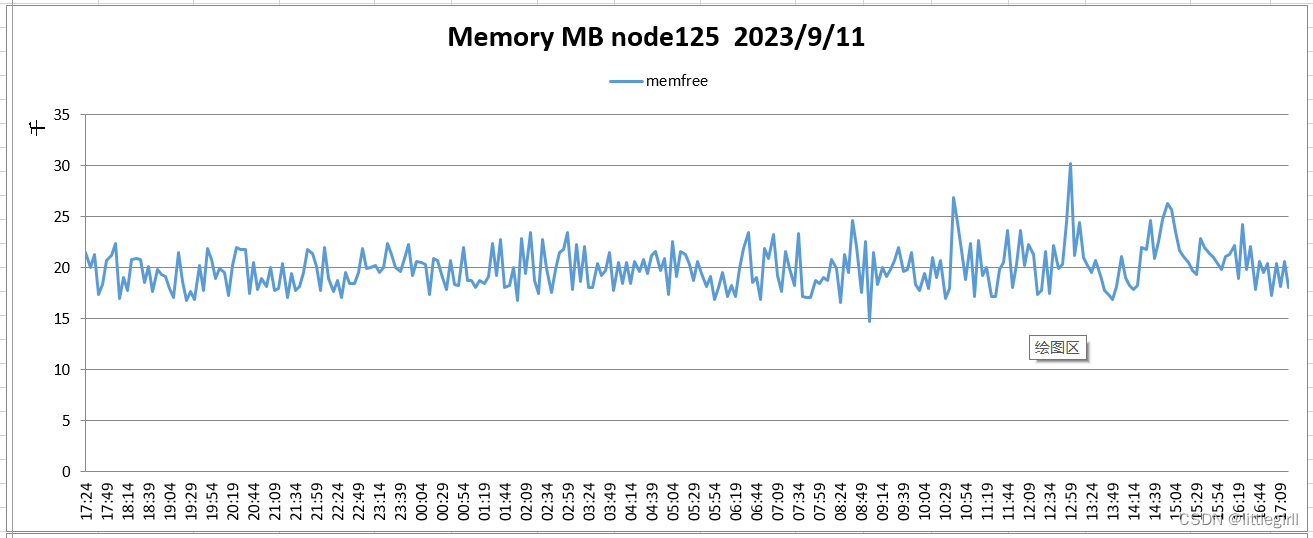
内存:平均剩余20GB左右
- 关于9.13日凌晨作业阻塞
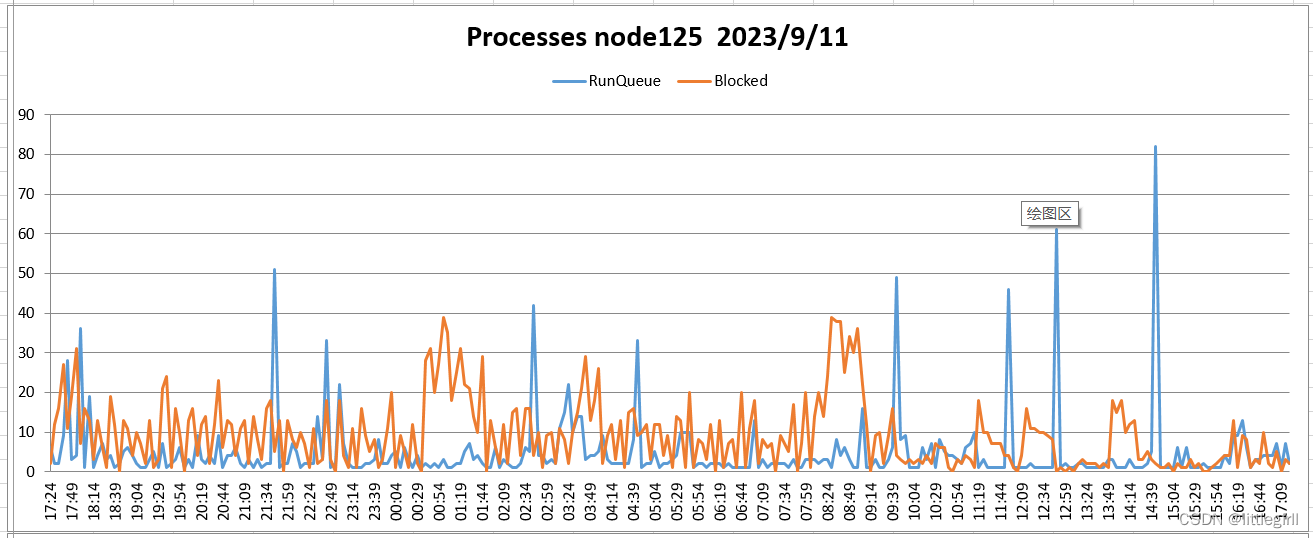
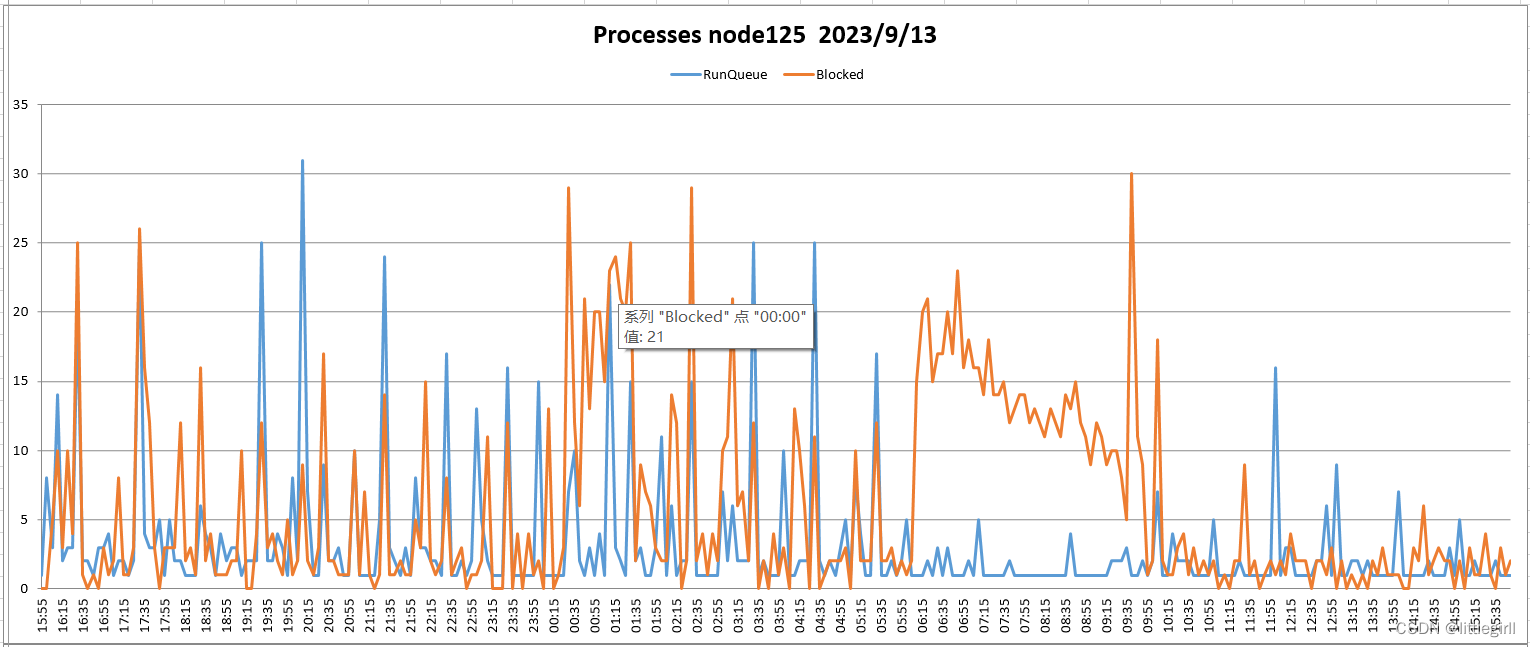
9.13日上午应用反应执行缓慢,从3.2小节的监控情况看,从5:58分开始可以观察到进程blocked队列增长为正常值的2倍,CPU使用率同时上涨,磁盘使用率两个节点达到100%,[沐浴阳光5] 但没有观察到内存的明显异常,暂时将数据库的参数max_connections从2000调整为600,降低压力,同时打开日志的打印更为详细的信息,观察情况。
- Nmon监控日志文件
9.11日
9.13日
磁盘:
9.11监控结果
9.13监控结果
进程:
9.11监控结果
9.13监控结果
内存:
9.11监控结果
9.13监控结果
从两天的nmon监控结果看:
Cpu:资源充足,平均cpu使用率低于10%
磁盘:资源紧张,大部分时间使用率在100%。每天在11:00以后,相对上午使用情况有所缓解[沐浴阳光1]
内存:平均剩余20GB左右
- 关于9.13日凌晨作业阻塞
9.13日上午应用反应执行缓慢,从3.2小节的监控情况看,从5:58分开始可以观察到进程blocked队列增长为正常值的2倍,CPU使用率同时上涨,磁盘使用率两个节点达到100%,[沐浴阳光2] 但没有观察到内存的明显异常,暂时将数据库的参数max_connections从2000调整为600,降低压力,同时打开日志的打印更为详细的信息,观察情况。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









