







一、hashtable概述
hash table可提供对于任何有名项的存取和删除操作。由于操作对象是有名项,所以hashtable可以被视为一种字典结构。这种结构的用意在于提供常数时间的基本操作。
常用的hash函数有取余函数等,而解决hash冲突的方法有线性探测法、二次探测法、开链法。
线性探测法:当hash函数计算出元素的存放位置时,若该位置已有元素,则尝试将元素放在该元素的下一位置,若仍被占,继续尝试下一位置,即每次加1;
二次探测法:若计算出来元素的位置为h,若h以被占,则依序尝试h+12,h+22,h+32,h+42,h+52…….
开链法:为每个位置的元素维护一个链表,hash值相同的元素直接插入到链表末端。
SGI STL内的hashtable以开链法解决hash冲突,这里的“链”被称为桶,如下图所示:

bucket维护的linked list并非采用STL的list或slist,bucket聚合体以vector完成,以便有动态扩充能力。
二、hashtable内部介绍
hash table的节点定义如下:
template <class Value>
struct __hashtable_node
{
__hashtable_node* next;
Value val;
};hashtable迭代器必须永远维系与整个buckets vector的关系,并记录当前所指的节点。其前进操作是首先尝试从目前所指的节点出发,前进一个位置,由于节点被安置在list内,所以利用节点的next指针即可达成前进操作。如果目前节点正巧是list的尾端,就跳至下一个bucket身上,那正是指向下一个bucket的头部节点。hashtable的迭代器没有后退操作,hashtable也没有定义所谓的逆向迭代器。
开链法不要求表格大小必须为质数,但是SGI STL仍然以质数来设计表格大小,并先将28个质数(逐渐呈现大约两倍的关系)计算好,以备随时访问。质数表如下{53,97,193,389,769,……},在设置表格大小时,找到大于或等于n的那个质数。
三、hashtable运用实例
目前STL中仅收录了unordered_set,unordered_map可供使用。hash_set,hash_map并未包含在STL库中,所以应尽量使用unordered_set,unordered_map来做hash处理。
// unordered_set示例程序
#include<unordered_set>
#include<iostream>
#include<ctime>
using namespace std;
void PrintfContainerElapseTime(char *pszContainerName, char *pszOperator, long lElapsetime)
{
printf("%s 的 %s操作 用时 %d毫秒\n", pszContainerName, pszOperator, lElapsetime);
}
int main()
{
const int MAXN = 50000, MAXQUERY = 5000;
int a[MAXN], query[MAXQUERY];
for (int i = 0; i < MAXN; ++i)
{
a[i] = (rand()*rand()) % MAXN;
}
for (int i = 0; i < MAXQUERY; ++i)
{
query[i] = (rand()*rand()) % MAXQUERY;
}
unordered_set<int> nhash_set;
unordered_multiset<int> nhash_mset;
nhash_set.insert(a, a + MAXN), nhash_mset.insert(a, a + MAXN);
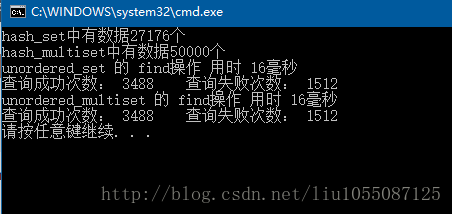
cout << "hash_set中有数据" << nhash_set.size() << "个" << endl;
cout << "hash_multiset中有数据" << nhash_mset.size() << "个" << endl;
int nFindSucceedCount, nFindFailedCount;
nFindSucceedCount = nFindFailedCount = 0;
clock_t clockBegin = clock();
for (int i = 0; i < MAXQUERY; ++i)
if (nhash_set.find(query[i]) != nhash_set.end())
++nFindSucceedCount;
else
++nFindFailedCount;
clock_t clockEnd = clock();
PrintfContainerElapseTime("unordered_set", "find", clockEnd - clockBegin);
printf("查询成功次数: %d 查询失败次数: %d\n", nFindSucceedCount, nFindFailedCount);
nFindSucceedCount = nFindFailedCount = 0;
clockBegin = clock();
for (int i = 0; i < MAXQUERY; ++i)
if (nhash_mset.find(query[i]) != nhash_mset.end())
++nFindSucceedCount;
else
++nFindFailedCount;
clockEnd = clock();
PrintfContainerElapseTime("unordered_multiset", "find", clockEnd - clockBegin);
printf("查询成功次数: %d 查询失败次数: %d\n", nFindSucceedCount, nFindFailedCount);
return 0;
}运行结果:
//unordered_map 示例程序
#include<unordered_map>
#include<iostream>
#include<ctime>
#include<string>
using namespace std;
void PrintfContainerElapseTime(char *pszContainerName, char *pszOperator, long lElapsetime)
{
printf("%s 的 %s操作 用时 %d毫秒\n", pszContainerName, pszOperator, lElapsetime);
}
int main()
{
const int MAXN = 50000, MAXQUERY = 5000;
unordered_map<int, string> nhash_map;
unordered_multimap<int, string> nhash_mmap;
int query[MAXQUERY];
for (int i = 0; i < MAXN; ++i)
{
nhash_map.insert(make_pair((rand()*rand()) % MAXN, "hello " + to_string((rand()*rand()) % MAXN)));
nhash_mmap.insert(make_pair((rand()*rand()) % MAXN, "hello" + to_string((rand()*rand()) % MAXN)));
}
for (int i = 0; i < MAXQUERY; ++i)
{
query[i] = (rand()*rand()) % MAXQUERY;
}
cout << "unordered_map中有数据" << nhash_map.size() << "个" << endl;
cout << "unordered_multimap中有数据" << nhash_mmap.size() << "个" << endl;
int nFindSucceedCount, nFindFailedCount;
nFindSucceedCount = nFindFailedCount = 0;
clock_t clockBegin = clock();
for (int i = 0; i < MAXQUERY; ++i)
if (nhash_map.find(query[i]) != nhash_map.end())
++nFindSucceedCount;
else
++nFindFailedCount;
clock_t clockEnd = clock();
PrintfContainerElapseTime("unordered_map", "find", clockEnd - clockBegin);
printf("查询成功次数: %d 查询失败次数: %d\n", nFindSucceedCount, nFindFailedCount);
nFindSucceedCount = nFindFailedCount = 0;
clockBegin = clock();
for (int i = 0; i < MAXQUERY; ++i)
if (nhash_mmap.find(query[i]) != nhash_mmap.end())
++nFindSucceedCount;
else
++nFindFailedCount;
clockEnd = clock();
PrintfContainerElapseTime("unordered_multimap", "find", clockEnd - clockBegin);
printf("查询成功次数: %d 查询失败次数: %d\n", nFindSucceedCount, nFindFailedCount);
return 0;
}运行结果:
















 473
473

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









