







电脑配置要求:
内存:最低8G,最好16G以上
硬盘:预留100G,实际上不妨数据大概不会超过20G
系统环境:
Windows环境:Windows10
Linux环境:CentOS-6.10-x86_64-bin-DVD1
VMware:15.5.0 build-14665864
所需文件
链接: https://pan.baidu.com/s/1X3Nfv5hBuJl6mGDNNcvnQA
提取码:dgmt
资源失效记得留言
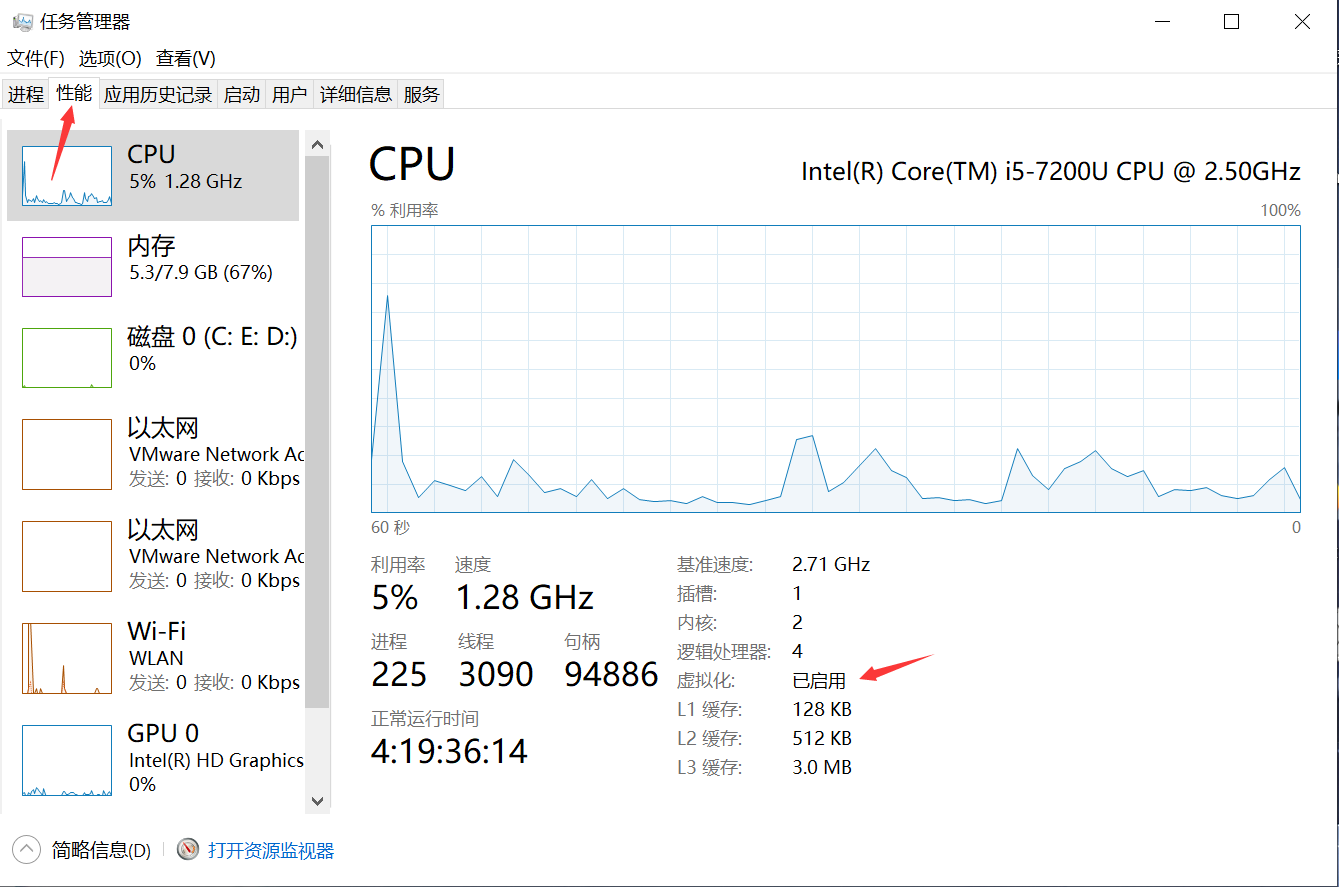
检查是否开启虚拟机
安装Linux
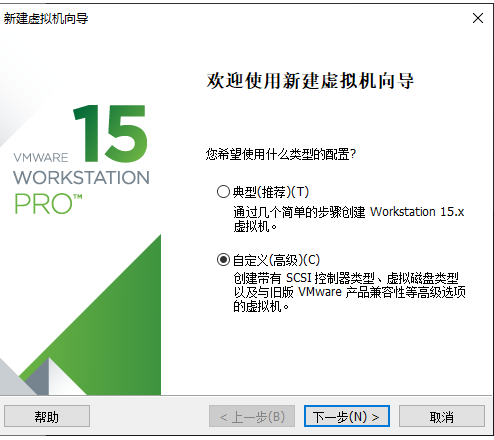
1.选择自定义
2.下一步
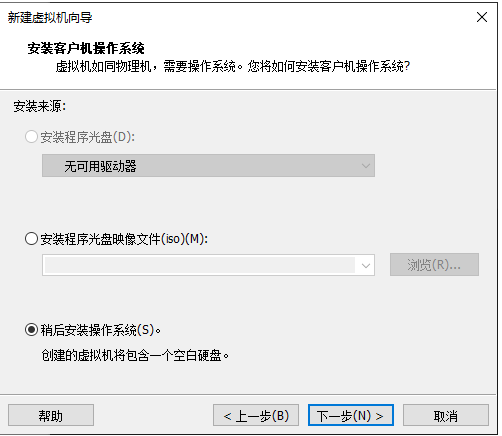
3.稍后安装操作系统
4.选择Linux 版本为Centos6 64位
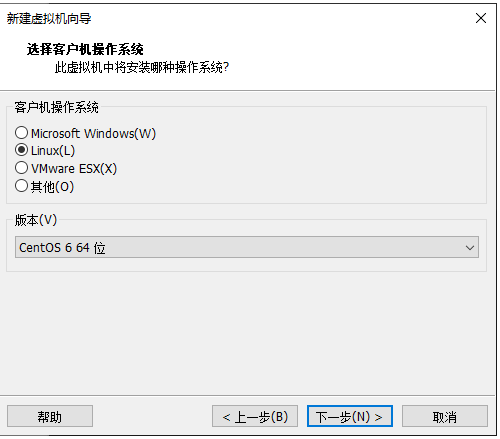
5.虚拟机命名为Hadoop001
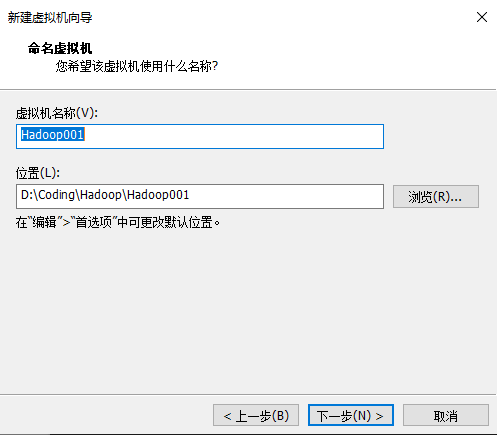
6.处理机配置,这里配置最好对应下图:
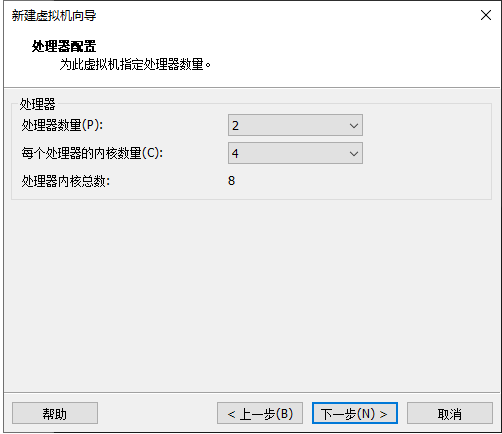
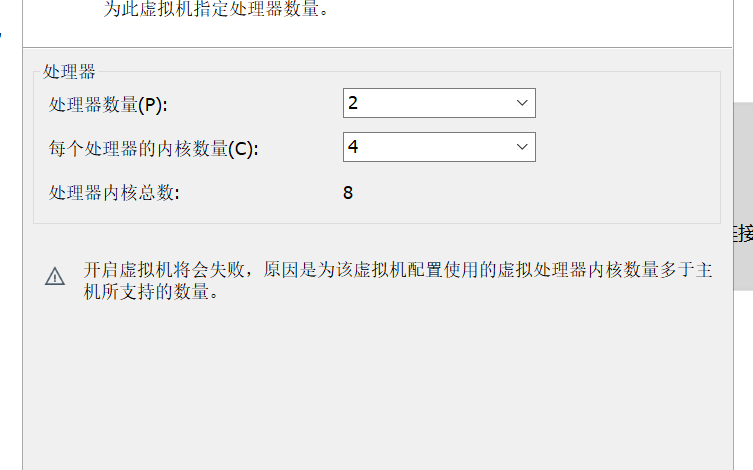
注意: 如果电脑配置不足,虚拟机会自动提示,这里根据自己电脑配置调整即可
7.网络类型选择NAT
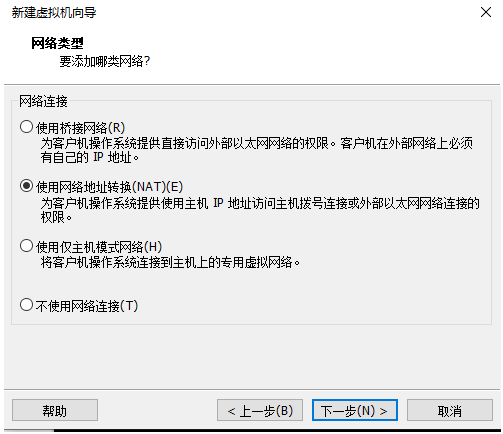
8.I/O控制器类型选择LSI Logic
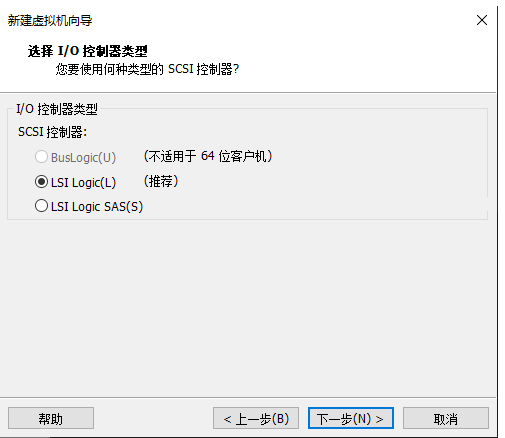
9.磁盘类型选择SCSI
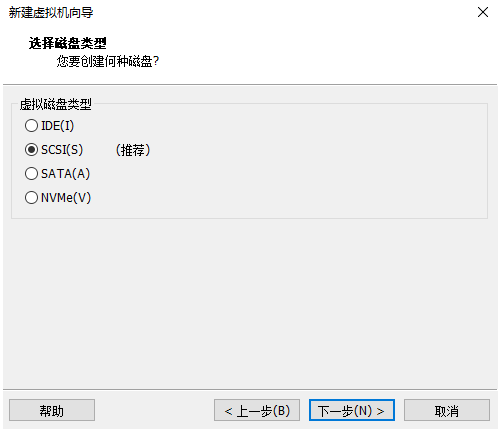
10.创建新虚拟磁盘
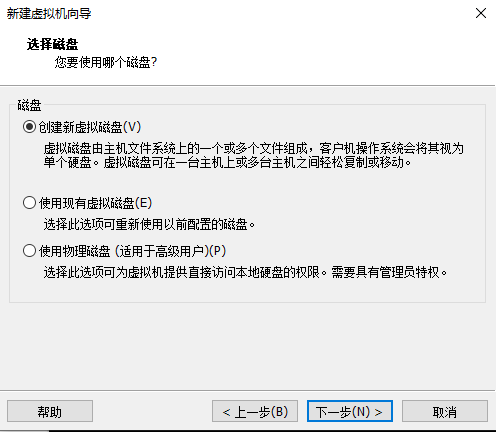
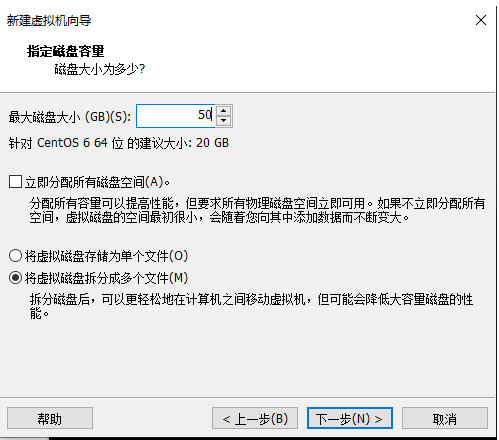
11.磁盘大小分配50G,将虚拟磁盘拆分成多个文件
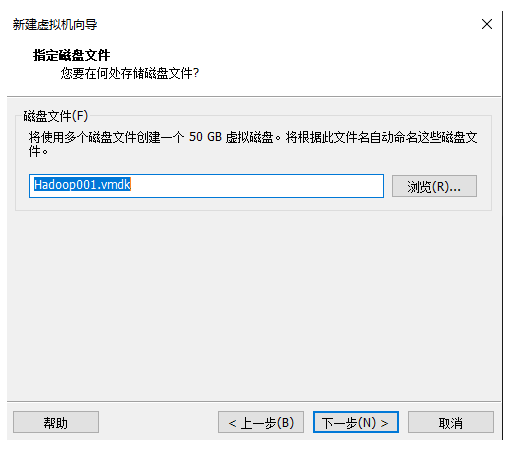
12.指定磁盘文件
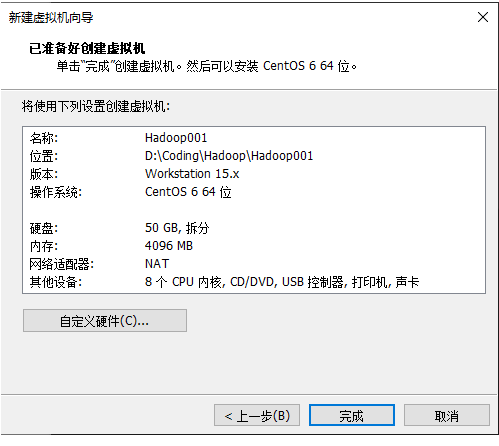
13.创建完成
14.在虚拟机配置中选择下载好的镜像文件

15.选择第一个
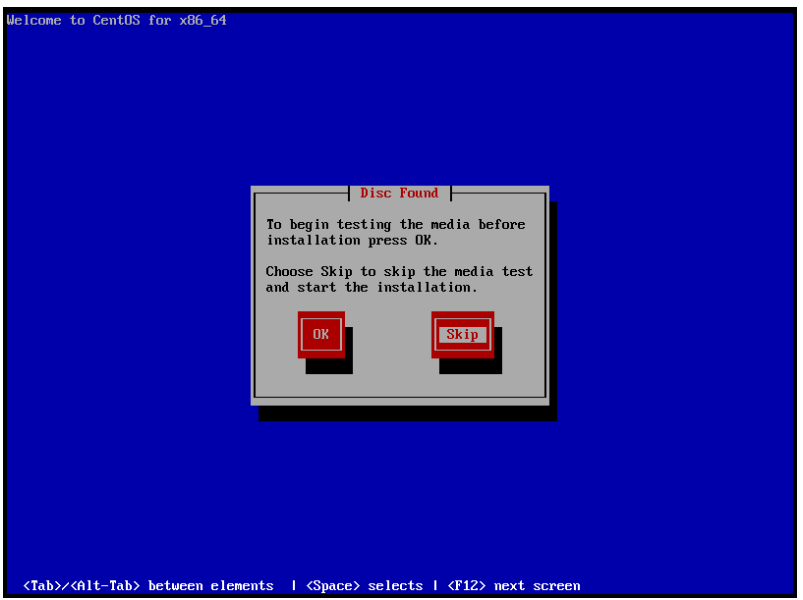
16.选择skip
17.选择next

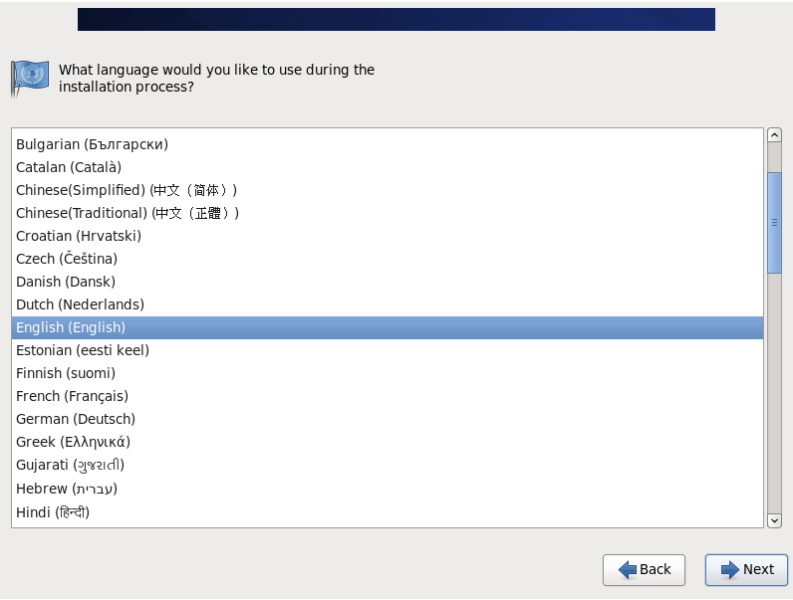
18.语言环境选择英文
19.选择输入法

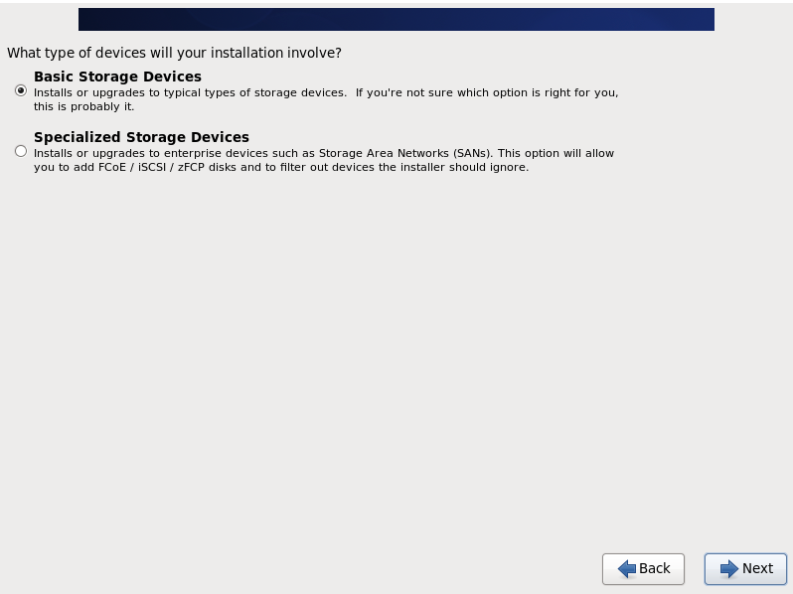
20.选择Basic Storage Devices
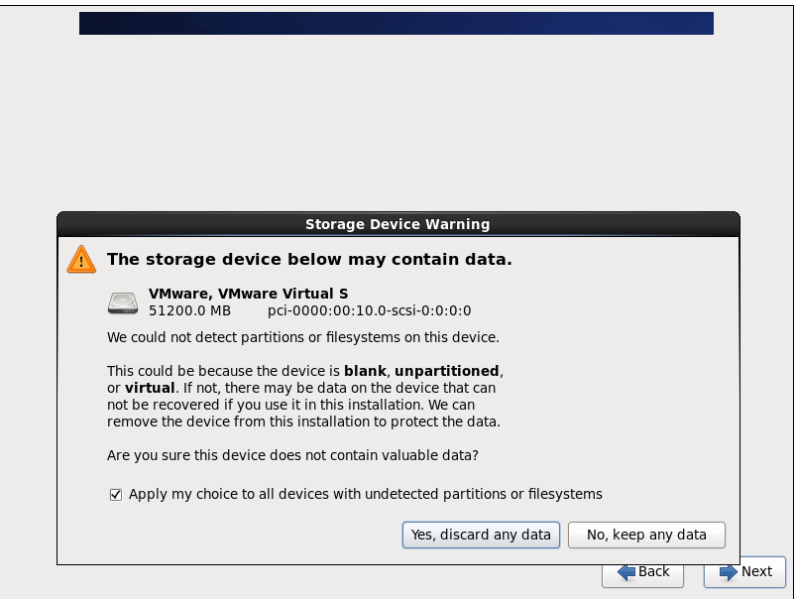
21.同意即可
22.主机命名
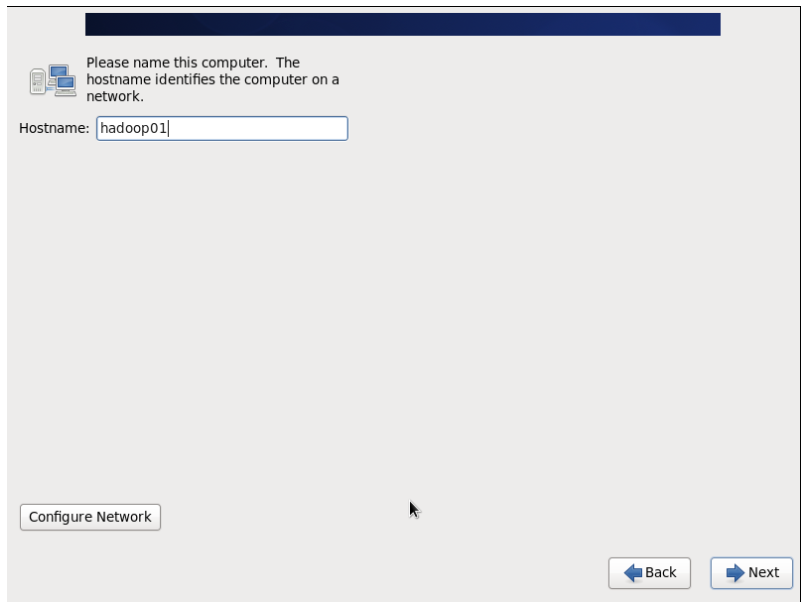
23.配置Configure Network
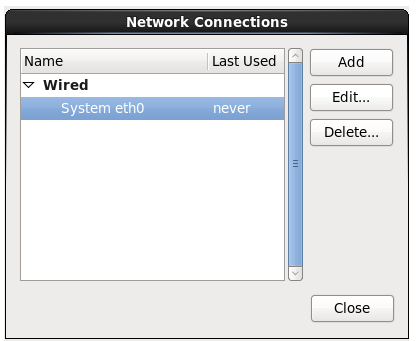
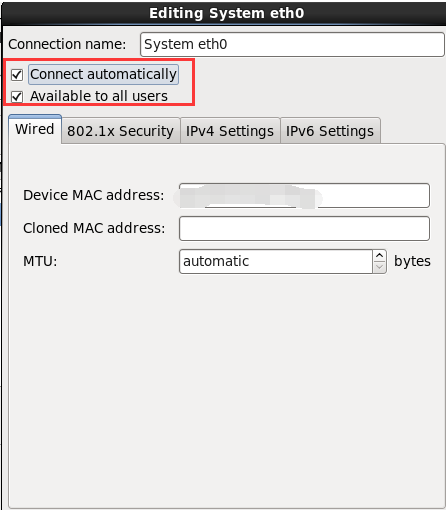
24.勾选即可
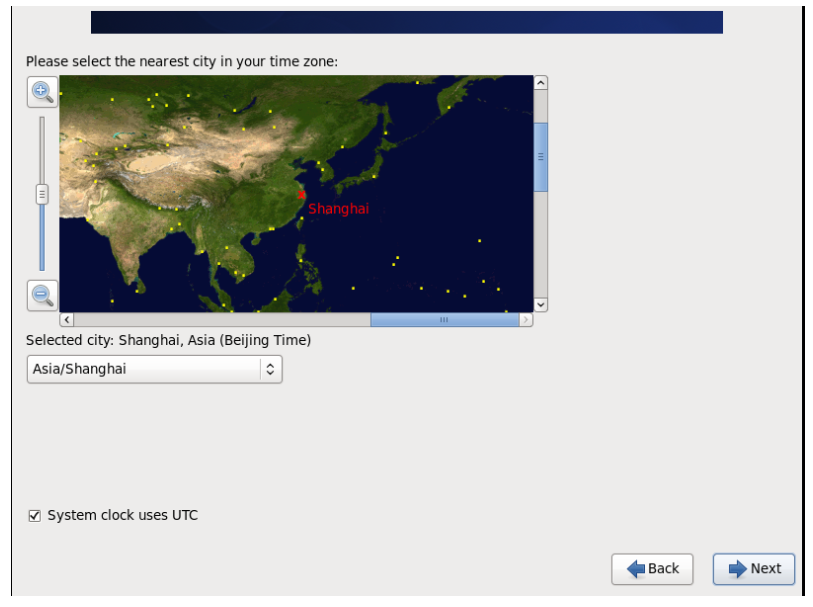
25.选择相应的时区
26.密码设个123456就行了
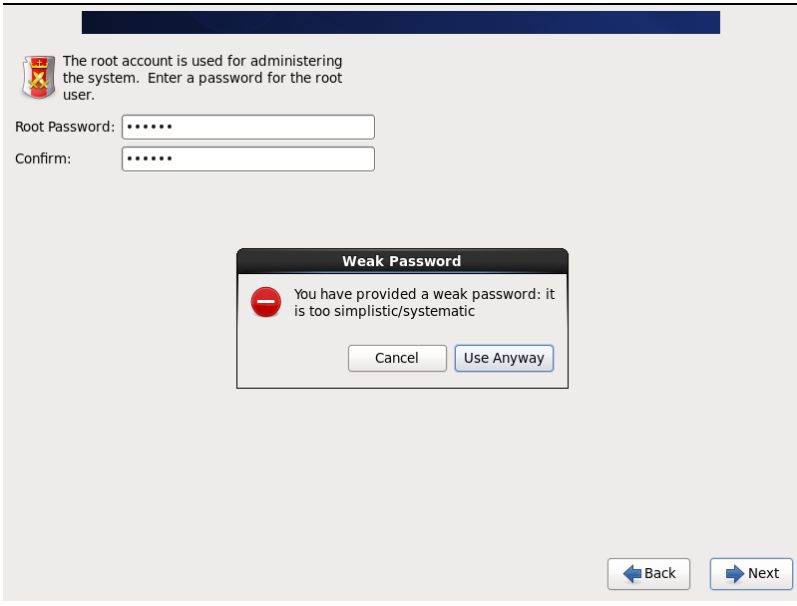
27.选择Use All Space
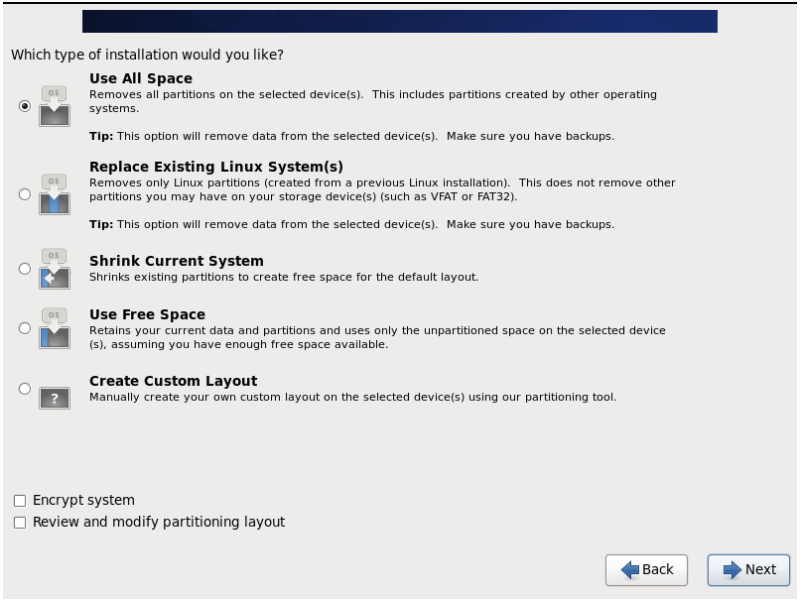
28.write changes to disk
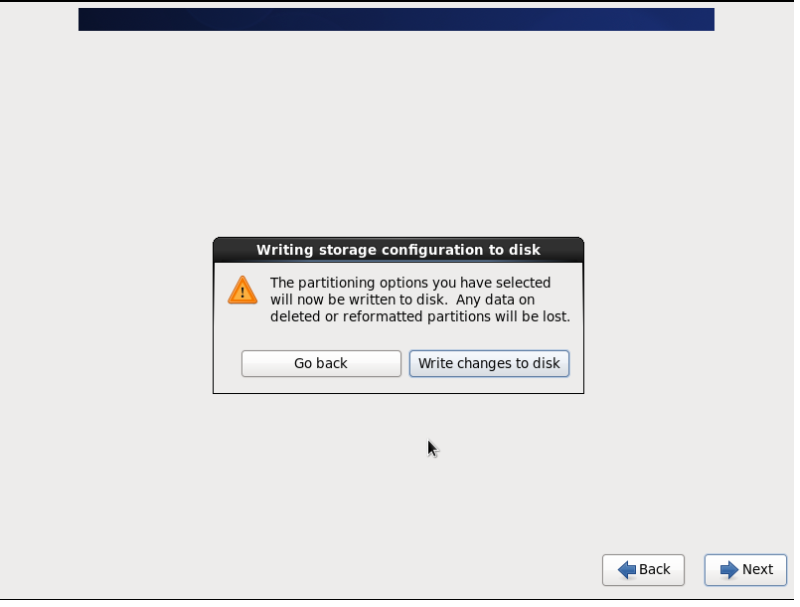
29.选择Basic
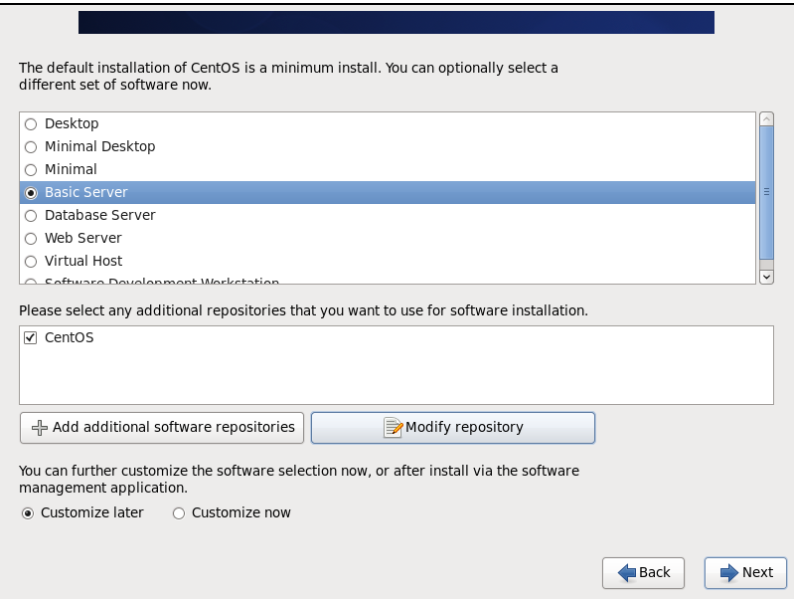
30.系统开始初始化

31.可见系统已经安装成功,reboot重启即可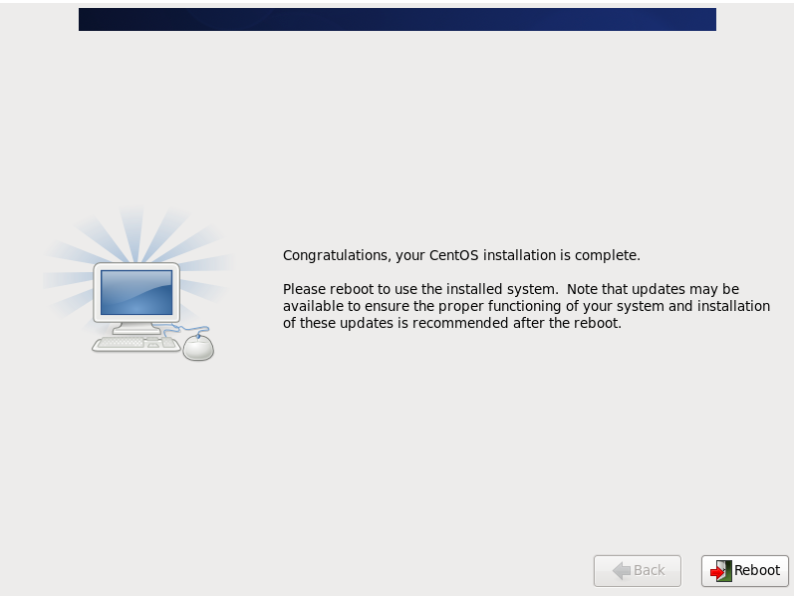
32.进入系统界面
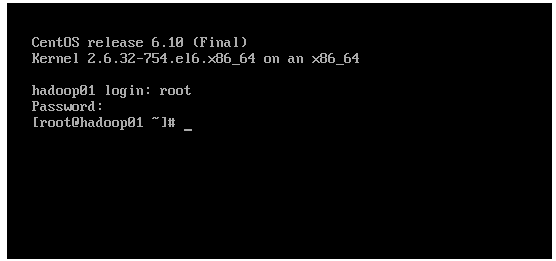
因为hadoop实验需要3个服务器,另外两个可以使用克隆安装
33.选择下一步
34.下一步
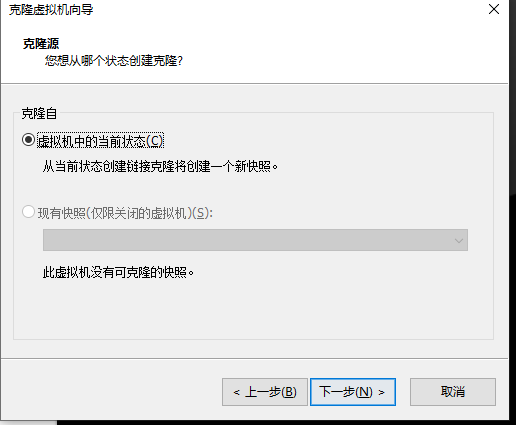
35.克隆类型选择链接克隆,尽量节省磁盘空间
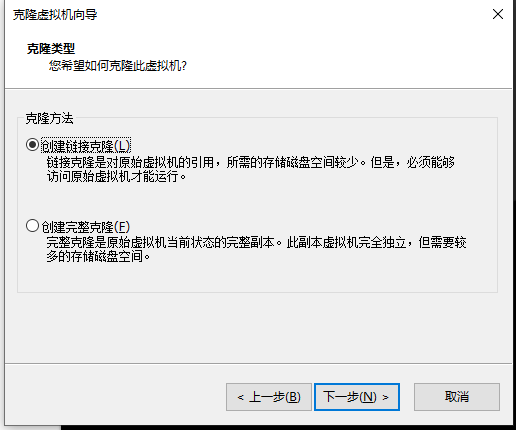
36.命名
37.可以看到安装完成之后的情形
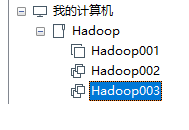
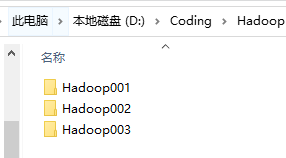
网络配置
1.配置网卡

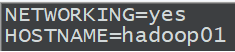
输入上面的命令可以查看hadoop01的网络环境:如下图所示
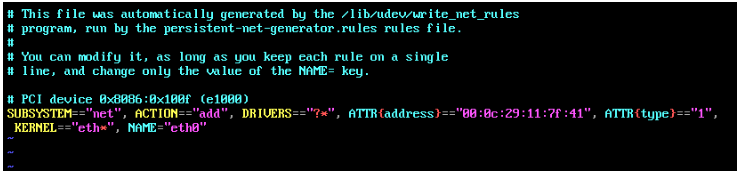
然后开始修改hadoop02,hadoop03的网络配置
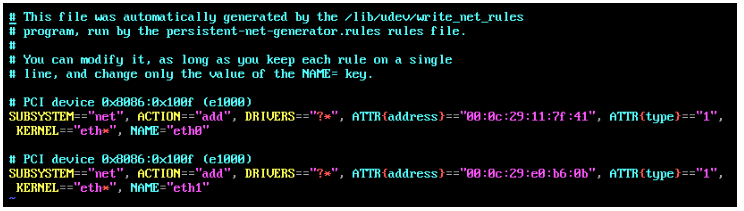
改动如下图所示:
也就是将上面的配置删除,下面的NAME=“eth1” 改成eth0

hadoop03的操作和hadoop02的一样
注意: 这里的MAC地址不能一样,如果一样,就需要自动生成一个
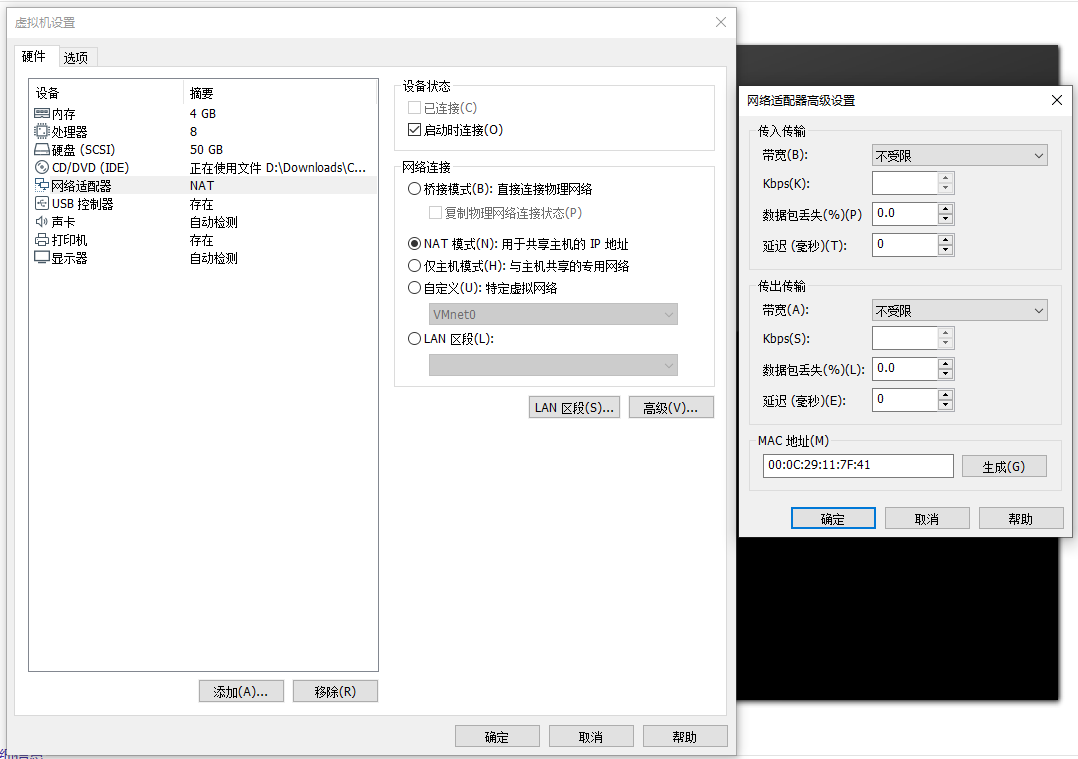
2.配置静态ip
修改hadoop01,02,03的网络配置文件(ifcfg-eth0)

可以查看配置文件的内容如下图所示:
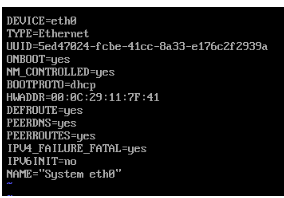
将网络配置改为下面的:
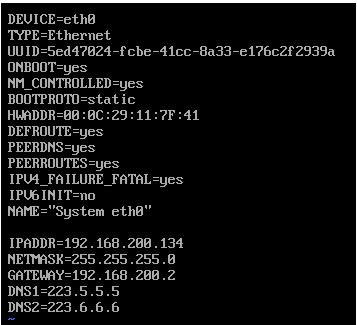
验证网络配置:

这里使用静态IP,ip地址分别是134 135 136
hadoop02和hadoop03的操作和hadoop01的一样,重复即可
3.配置虚拟机网络
首先需要检查是否开启了5个服务
在控制面板的服务里面可以看到是否开启

1.编辑->虚拟网络编辑器
2.配置网络编辑器
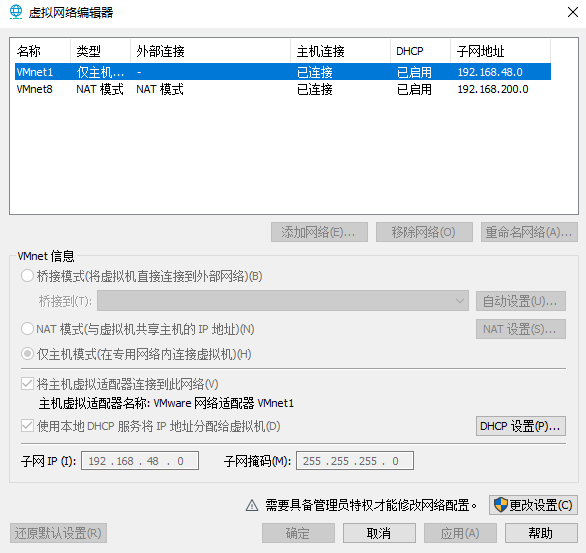
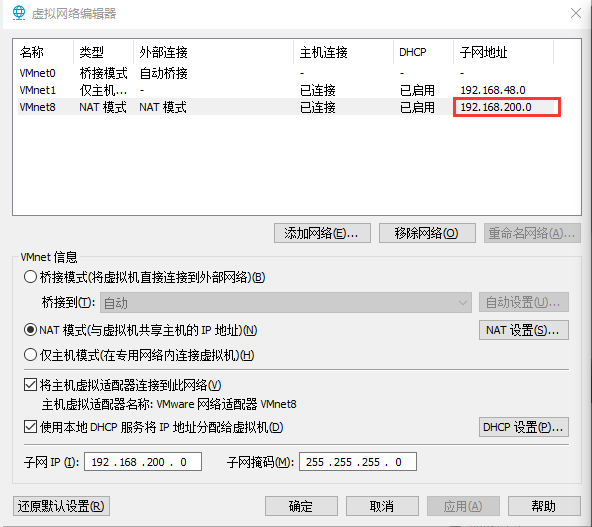
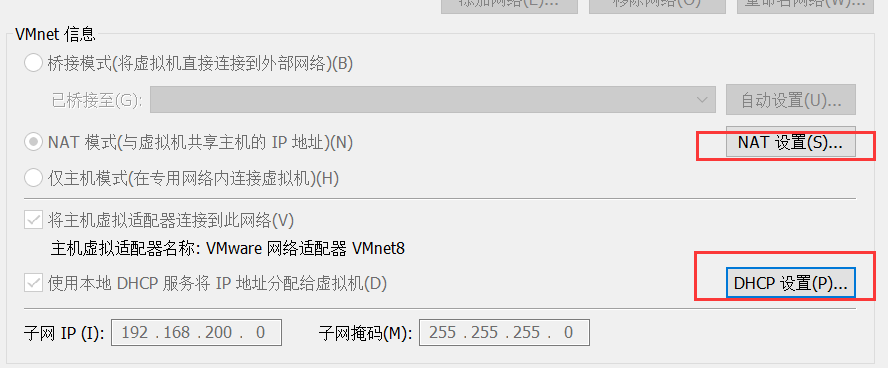
NAT设置如图所示:
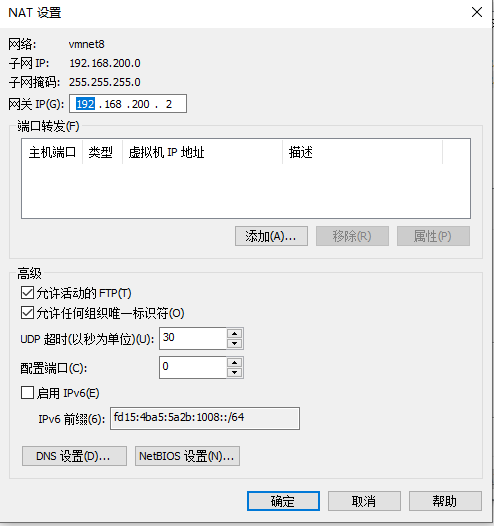
DHCP设置如图所示:
修改VMware network

将VMnet8的ipv4修改为下图所示

4.主机名映射配置

5.IP映射配置


6.windows的hosts配置
修改Windows下的hosts文件


**注意:**网络配置完成记得重启网络服务
service network restart或者重启服务器reboot
完成以上步骤,网络配置就算完成
7.测试网络配置
接下来测试网络配置是否完成
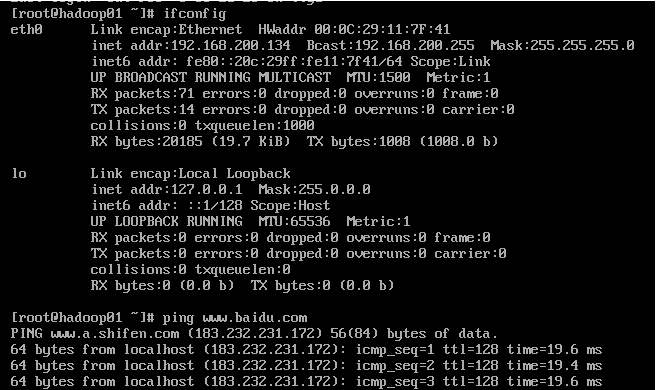
ifcfg-eth0 配置参数说明
1.TYPE:配置文件接口类型。在/etc/sysconfig/network-scripts/目录有多种网络配置文件,有Ethernet 、IPsec等类型,网络接口类型为Ethernet。
2.DEVICE:网络接口名称
3.BOOTPROTO:系统启动地址协议
4.none:不使用启动地址协议
5.bootp:BOOTP协议
6.dhcp:DHCP动态地址协议
7.static:静态地址协议
8.ONBOOT:系统启动时是否激活
yes:系统启动时激活该网络接口
no:系统启动时不激活该网络接口
9.IPADDR:IP地址
10.NETMASK:子网掩码
11.GATEWAY:网关地址
12.BROADCAST:广播地址
13.HWADDR/MACADDR:MAC地址。只需设置其中一个,同时设置时不能相互冲突。
14.PEERDNS:是否指定DNS。如果使用DHCP协议,默认为yes
SSH配置
输入rpm -qa|grep ssh查看ssh是否安装
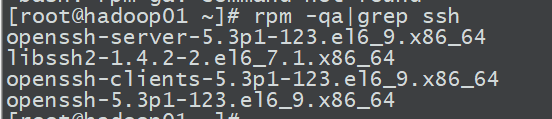
如果没有安装:yum install openssh-server
免密登陆
1.为什么要免密登录
Hadoop节点众多,所以一般在主节点启动从节点,这个时候就需要程序自动在主节点登录
到从节点中,如果不能免密就每次都要输入密码,非常麻烦
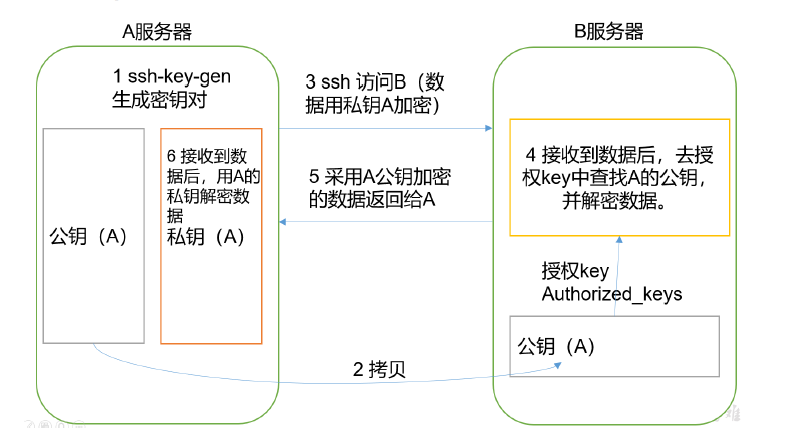
2. 免密SSH登录的原理
需要先在B节点配置A节点的公钥
A节点请求B节点要球登录
B节点使用A节点的公钥,加密一段随机文本
A节点使用私钥解密,并发回给B节点
B节点验证文本是否正确
这里为了更方便的操作,使用secureCRT文件
打开secureCRT文件,new Session创建相应的session连接
1.new Session
2.下一步
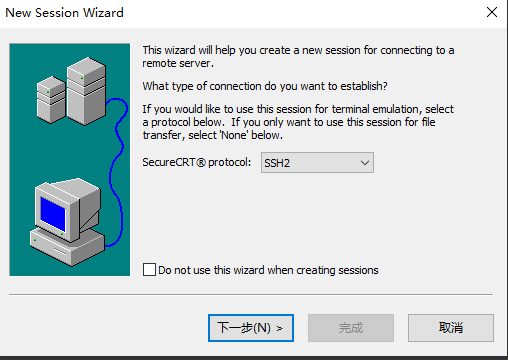
3.填写相应信息
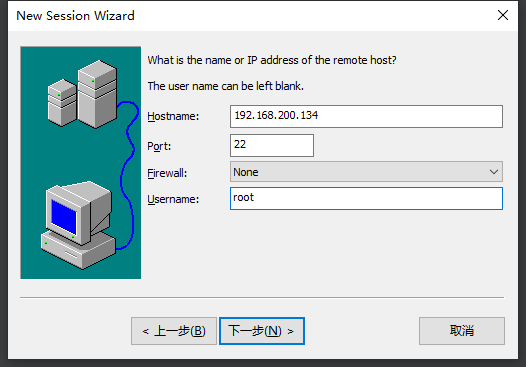
4.SFTP协议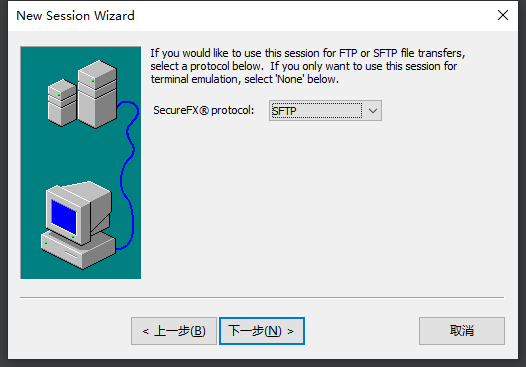
5.命名
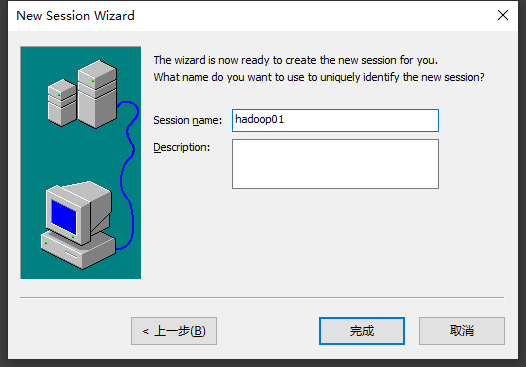
最后效果:
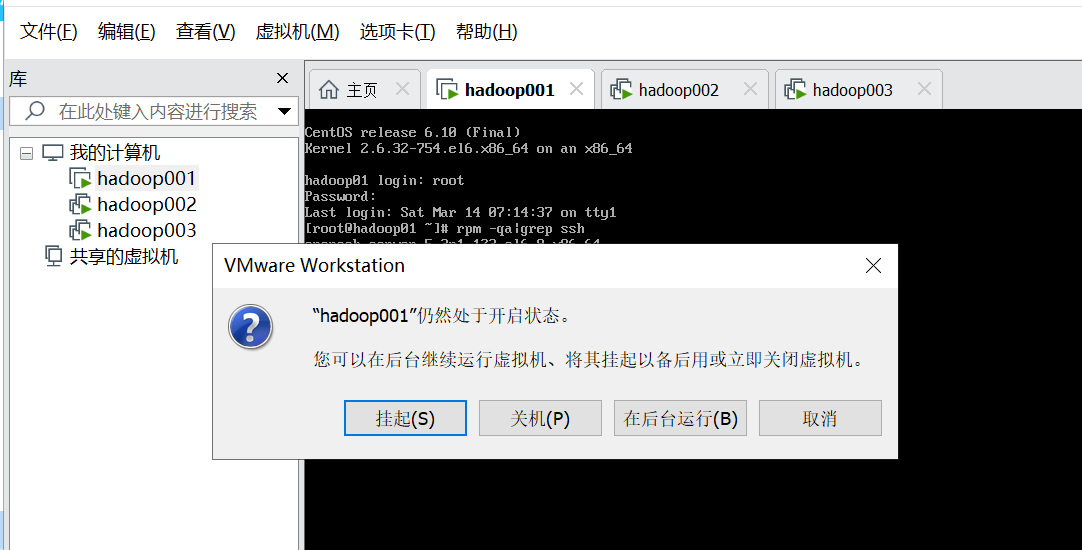
配置完成之后虚拟机就可以后台运行了
这里为了软件的美观,可以进行相应的设置
这里推荐一个配色方案:
SecureCRT优化调整、永久设置、保护眼睛和配色方案
配置免密登录
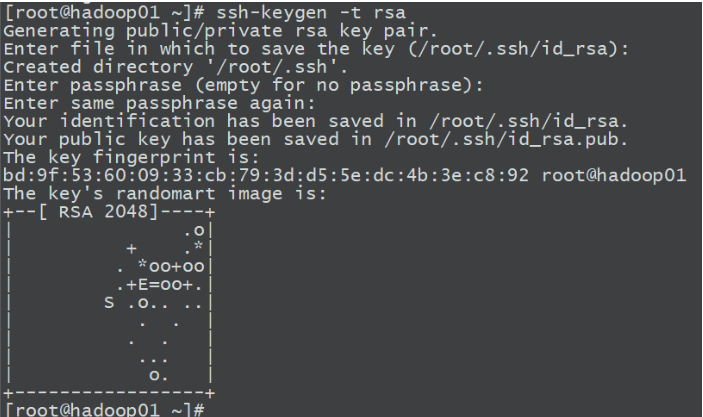
1.在三台机器执行以下命令,生成公钥与私钥
ssh-keygen -t rsa
一直回车就行了
2.复制ssh-copy-id hadoop01
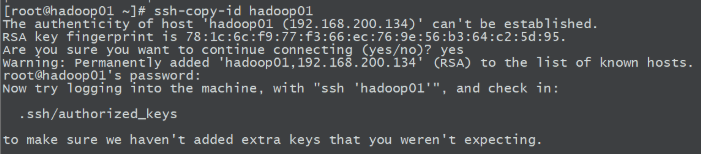
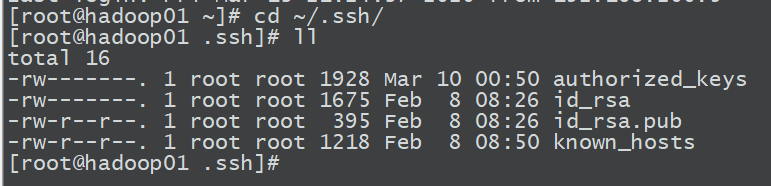

将第一台机器的公钥拷贝到其他机器
scp /root/.ssh/authorized_keys hadoop02:/root/.ssh
scp /root/.ssh/authorized_keys hadoop03:/root/.ssh

如果3台机器可以相互访问,说明配置成功
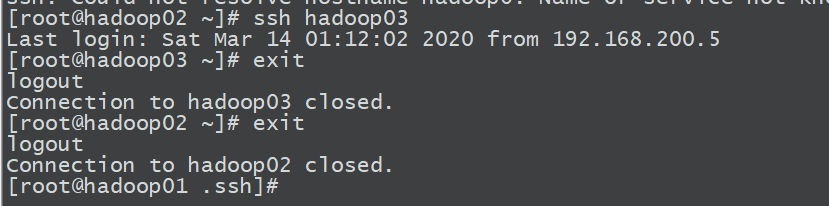
hadoop安装
Hadoop集群部署模式
- 在独立模式下,所有程序都在单个VM上执行,调试Hadoop集群的MapReduce程序也非常方便。一般情况下,该模式常用于学习或开发阶段进行调试程序。
- 在伪分布式模式下,Hadoop程序的守护进程都运行在一台节点上,该模式主要用于调试Hadoop分布式程序的代码,以及程序执行是否正确。伪分布式模式是完全分布式模式的一个特例。
- 在完全分布式模式下,Hadoop的守护进程分别运行在由多个主机措建的集群上,不同节点担任不同的角色,在实际工作应用开发中,通常使用该模式构建企业级Hadoop系统。
从JDK版本7u71以后,JAVA将会在同一时间发布两个版本的JDK,其中:
- 奇数版本为BUG修正并全部通过检验的版本,官方强烈推荐使用这个版本。
- 偶数版本包含了奇数版本所有的内容,以及未被验证的BUG修复,Oracle官方表示:除非你深受BUG困扰,否则不推荐您使用这个版本。
http://hbase.apache.org/book.html#basic.prerequisites
http://hive.apache.org/downloads.html
https://www.oracle.com/technetwork/java/javase/downloads/index.html
根据官网推荐,使用如下软件配置
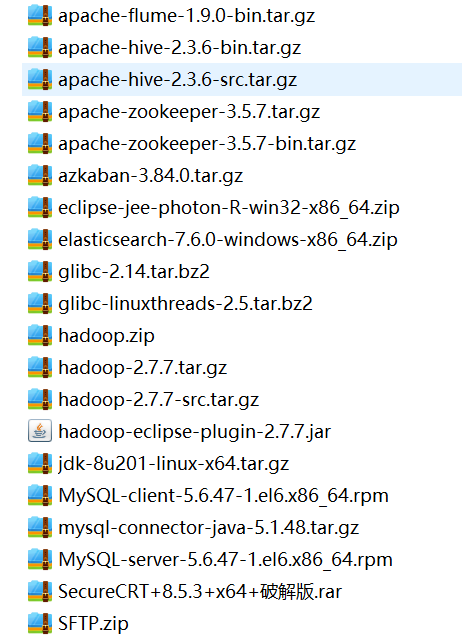
1.上传文件并创建相应文件
1.创建文件:在根目录下创建下图文件

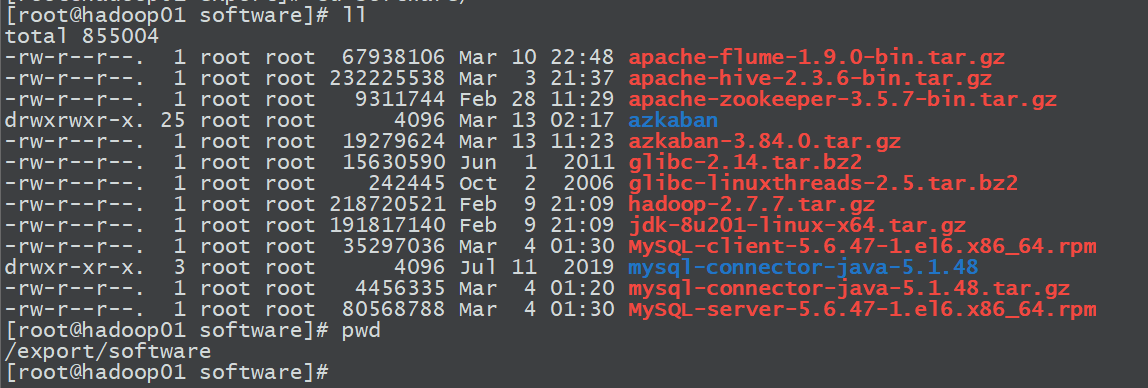
2.通过命令将文件拖进software文件中
安装上传文件命令yum install -y lrzsz
执行命令rz,上传文件
执行命令sz,下载文件
2.安装JDK
解压jdk文件到/export/servers/路径下
tar -zxvf jdk-8u201-linux-x64.tar.gz -C /export/servers/
将jdk文件移动到jdk路径下
mv jdk1.8.0_201 jdk
4.添加环境变量
vim /etc/profile
添加下列代码
export JAVA_HOME=/export/servers/jdk
export PATH=$JAVA_HOME/bin:$PATH
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
添加完成之后记得source /etc/profile使配置生效
测试:
java -version

which java

安装hadoop
1.解压
tar -zxvf hadoop-2.7.7.tar.gz -C /export/servers/
2.编写/etc/profile文件
vim /etc/profile
添加下列命令:

配置完成之后:source /etc/profile

测试:
hadoop version查看是否配置完成
hadoop入门案例:

1.进入hadoop-2.7.7下面
2.创建一个input文件夹
3.将Hadoop的xml配置文件复制到input
xml配置文件是etc/hadoop/*.xml’
4.执行share目录下的MapReduce程序
hadoop jar hadoop-mapreduce-examples-2.7.2.jar grep input output 'dfs[a-z.]+'
5.在hadoop-2.7.7路径下查看输出结果
cat output/*
注意: hadoop jar 是命令,hadoop-mapreduce-examples-2.7.7.jar是自己写的mr代码,input 输入文件夹,output 输出文件夹














 3836
3836











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









