







树形结构
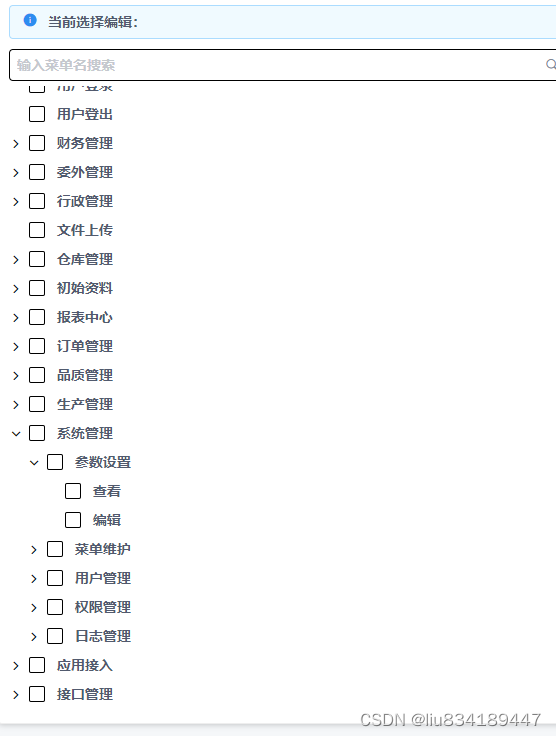
-
数据库表 admin_menu
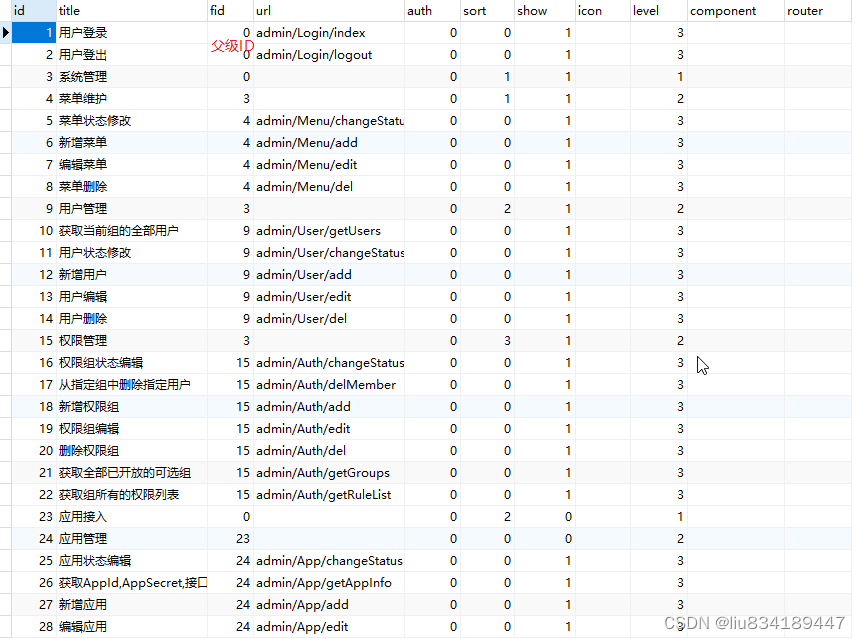
-
dao层sql
@Mapper
@Repository
public interface MenuMapper extends BaseMapper<AdminMenu> {
@Select({"select * from admin_menu where fid=#{fid}"})
List<AdminMenu> findByfid(@Param("fid") int fid);
}
- 创建实体类
package com.example.diandujava.entity.DataBase;
import java.util.List;
/**
* 菜单
*/
public class AdminMenu {
private long id;
private String title;
private long fid;
private String url;
private long auth;
private long sort;
private long show;
private String icon;
private long level;
private String component;
private String router;
//加一个放子级的
private List<AdminMenu> children;
//get set 省略
}
- 定义service层
/**
* 查询所有菜单
* @return 所有菜单
*/
public ReturnMsg findMenus(){
ReturnMsg msg = new ReturnMsg();
try {
List<AdminMenu> menus= getMenusList(0);
msg.setMsg("查询成功");
msg.setData(menus);
msg.setCode(1);
}catch (Exception e) {
msg.setMsg("查询失败");
msg.setCode(0);
}
return msg;
}
/**
* 递归查询菜单
* @param fid 父级ID
* @return
*/
private List<AdminMenu> getMenusList(Integer fid){
//根据传入ID查出
List<AdminMenu> menus = menuMapper.findByfid(fid);
AdminMenu menu1 =new AdminMenu();
for (int i = 0; i < menus.size(); i++) {
menu1.setId(menus.get(i).getId());
Integer id=Integer.parseInt(String.valueOf(menu1.getId()));
List<AdminMenu>dtos=getMenusList(id);
menus.get(i).setChildren(dtos);
}
return menus;
}
- controller层实现
@GetMapping("/index")
public ReturnMsg findmenu(){return menuService.findMenus();}
- postman测试
















 978
978











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









