







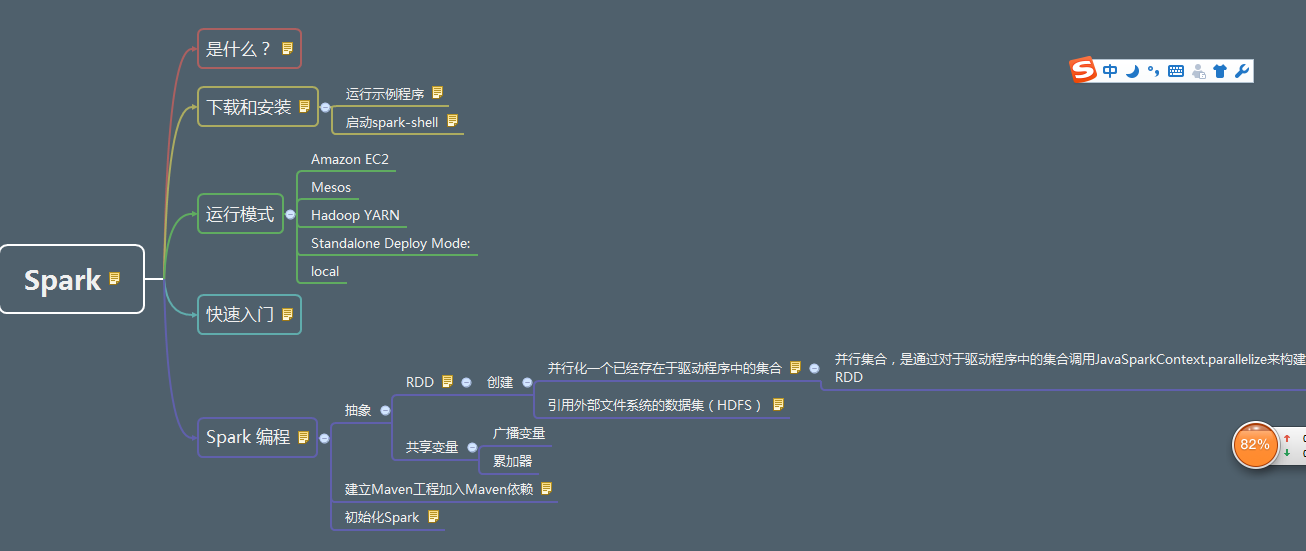
首先看看思维导图,我的spark是1.6.1版本,jdk是1.7版本
spark是什么?
Spark是基于内存计算的大数据并行计算框架。Spark基于内存计算,提高了在大数据环境下数据处理的实时性,同时保证了高容错性和高可伸缩性,允许用户将Spark 部署在大量廉价硬件之上,形成集群。
下载和安装
可以看我之前发表的博客
Spark安装
安装成功后运行示例程序
在spark安装目录下examples/src/main目录中。 运行的一个Java或Scala示例程序,使用bin/run-example <class> [params]
./bin/run-example SparkPi 10启动spark-shell时的参数
./bin/spark-shell –master local[2]
参数master 表名主机master在分布式集群中的URL
local【2】 表示在本地通过开启2个线程运行
运行模式
四种:
1.Mesos
2.Hadoop YARN
3.spark
4.local
一般我们用的是local和spark模式
首先建立maven工程加入整个项目所用到的包的maven依赖
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>sparkday01</groupId>
<artifactId>sparkday01</artifactId>
<version>0.0.1-SNAPSHOT</version>
<packaging>jar</packaging>
<name>sparkday01</name>
<url>http://maven.apache.org</url>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
</properties>
<dependencies>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.10</artifactId>
<version>1.6.1</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.6.4</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.10</artifactId>
<version>1.6.1</version>
</dependency>
</dependencies>
</project>
下面开始初始化spark
spark程序需要做的第一件事情,就是创建一个SparkContext对象,它将告诉spark如何访问一个集群,而要创建一个SparkContext对象,你首先要创建一个SparkConf对象,该对象访问了你的应用程序的信息
比如下面的代码是运行在spark模式下
public class sparkTestCon {
public static void main(String[] args) {
SparkConf conf=new SparkConf();
conf.set("spark.testing.memory", "2147480000"); //因为jvm无法获得足够的资源
JavaSparkContext sc = new JavaSparkContext("spark://192.168.52.140:7077", "First Spark App",conf);
System.out.println(sc);
}
}
下面是运行在本机,把上面的第6行代码改为如下
JavaSparkContext sc = new JavaSparkContext("local", "First Spark App",conf);
快速入门
可以参看我的博客,转载的一篇文章
Spark快速入门
Spark编程
每一个spark应用程序都包含一个驱动程序(driver program ),他会运行用户的main函数,并在集群上执行各种并行操作(parallel operations)
spark提供的最主要的抽象概念有两种:
弹性分布式数据集(resilient distributed dataset)简称RDD ,他是一个元素集合,被分区地分布到集群的不同节点上,可以被并行操作,RDDS可以从hdfs(或者任意其他的支持Hadoop的文件系统)上的一个文件开始创建,或者通过转换驱动程序中已经存在的Scala集合得到,用户也可以让spark将一个RDD持久化到内存中,使其能再并行操作中被有效地重复使用,最后RDD能自动从节点故障中恢复
spark的第二个抽象概念是共享变量(shared variables),它可以在并行操作中使用,在默认情况下,当spark将一个函数以任务集的形式在不同的节点上并行运行时,会将该函数所使用的每个变量拷贝传递给每一个任务中,有时候,一个变量需要在任务之间,或者驱动程序之间进行共享,spark支持两种共享变量:
广播变量(broadcast variables),它可以在所有节点的内存中缓存一个值。
累加器(accumulators):只能用于做加法的变量,例如计算器或求和器
RDD的创建有两种方式
1.引用外部文件系统的数据集(HDFS)
2.并行化一个已经存在于驱动程序中的集合(并行集合,是通过对于驱动程序中的集合调用JavaSparkContext.parallelize来构建的RDD)
第一种方式创建
下面通过代码来理解RDD和怎么操作RDD
package com.tg.spark;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.Function;
import org.apache.spark.api.java.function.Function2;
import org.apache.spark.storage.StorageLevel;
/**
* 引用外部文件系统的数据集(HDFS)创建RDD
* 匿名内部类定义函数传给spark
* @author 汤高
*
*/
public class RDDOps {
//完成对所有行的长度求和
public static void main(String[] args) {
SparkConf conf=new SparkConf();
conf.set("spark.testing.memory", "2147480000"); //因为jvm无法获得足够的资源
JavaSparkContext sc = new JavaSparkContext("local", "First Spark App",conf);
System.out.println(sc);
//通过hdfs上的文件定义一个RDD 这个数据暂时还没有加载到内存,也没有在上面执行动作,lines仅仅指向这个文件
JavaRDD<String> lines = sc.textFile("hdfs://master:9000/testFile/README.md");
//定义lineLengths作为Map转换的结果 由于惰性,不会立即计算lineLengths
//第一个参数为传入的内容,第二个参数为函数操作完后返回的结果类型
JavaRDD<Integer> lineLengths = lines.map(new Function<String, Integer>() {
public Integer call(String s) {
System.out.println("每行长度"+s.length());
return s.length(); }
});
//运行reduce 这是一个动作action 这时候,spark才将计算拆分成不同的task,
//并运行在独立的机器上,每台机器运行他自己的map部分和本地的reducation,并返回结果集给去驱动程序
int totalLength = lineLengths.reduce(new Function2<Integer, Integer, Integer>() {
public Integer call(Integer a, Integer b) { return a + b; }
});
System.out.println(totalLength);
//为了以后复用 持久化到内存...
lineLengths.persist(StorageLevel.MEMORY_ONLY());
}
}
如果觉得刚刚那种写法难以理解,可以看看第二种写法
package com.tg.spark;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.Function;
import org.apache.spark.api.java.function.Function2;
import org.apache.spark.storage.StorageLevel;
/**
* 引用外部文件系统的数据集(HDFS)创建RDD
* 外部类定义函数传给spark
* @author 汤高
*
*/
public class RDDOps2 {
// 完成对所有行的长度求和
public static void main(String[] args) {
SparkConf conf = new SparkConf();
conf.set("spark.testing.memory", "2147480000"); // 因为jvm无法获得足够的资源
JavaSparkContext sc = new JavaSparkContext("local", "First Spark App", conf);
System.out.println(sc);
//通过hdfs上的文件定义一个RDD 这个数据暂时还没有加载到内存,也没有在上面执行动作,lines仅仅指向这个文件
JavaRDD<String> lines = sc.textFile("hdfs://master:9000/testFile/README.md");
//定义lineLengths作为Map转换的结果 由于惰性,不会立即计算lineLengths
JavaRDD<Integer> lineLengths = lines.map(new GetLength());
//运行reduce 这是一个动作action 这时候,spark才将计算拆分成不同的task,
//并运行在独立的机器上,每台机器运行他自己的map部分和本地的reducation,并返回结果集给去驱动程序
int totalLength = lineLengths.reduce(new Sum());
System.out.println("总长度"+totalLength);
// 为了以后复用 持久化到内存...
lineLengths.persist(StorageLevel.MEMORY_ONLY());
}
//定义map函数
//第一个参数为传入的内容,第二个参数为函数操作完后返回的结果类型
static class GetLength implements Function<String, Integer> {
public Integer call(String s) {
return s.length();
}
}
//定义reduce函数
//第一个参数为内容,第三个参数为函数操作完后返回的结果类型
static class Sum implements Function2<Integer, Integer, Integer> {
public Integer call(Integer a, Integer b) {
return a + b;
}
}
}
第二种方式创建RDD
package com.tg.spark;
import java.util.Arrays;
import java.util.List;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.Function;
import org.apache.spark.api.java.function.Function2;
import org.apache.spark.storage.StorageLevel;
import com.tg.spark.RDDOps2.GetLength;
import com.tg.spark.RDDOps2.Sum;
/**
* 并行化一个已经存在于驱动程序中的集合创建RDD
* @author 汤高
*
*/
public class RDDOps3 {
// 完成对所有数求和
public static void main(String[] args) {
SparkConf conf = new SparkConf();
conf.set("spark.testing.memory", "2147480000"); // 因为jvm无法获得足够的资源
JavaSparkContext sc = new JavaSparkContext("local", "First Spark App", conf);
System.out.println(sc);
List<Integer> data = Arrays.asList(1, 2, 3, 4, 5);
//并行集合,是通过对于驱动程序中的集合调用JavaSparkContext.parallelize来构建的RDD
JavaRDD<Integer> distData = sc.parallelize(data);
JavaRDD<Integer> lineLengths = distData.map(new GetLength());
// 运行reduce 这是一个动作action 这时候,spark才将计算拆分成不同的task,
// 并运行在独立的机器上,每台机器运行他自己的map部分和本地的reducation,并返回结果集给去驱动程序
int totalLength = lineLengths.reduce(new Sum());
System.out.println("总和" + totalLength);
// 为了以后复用 持久化到内存...
lineLengths.persist(StorageLevel.MEMORY_ONLY());
}
// 定义map函数
static class GetLength implements Function<Integer, Integer> {
@Override
public Integer call(Integer a) throws Exception {
return a;
}
}
// 定义reduce函数
static class Sum implements Function2<Integer, Integer, Integer> {
public Integer call(Integer a, Integer b) {
return a + b;
}
}
}
注意:上面的写法是基于jdk1.7或者更低版本
基于jdk1.8有更简单的写法
下面是官方文档的说明
所以如果要完成上面第一种创建方式,在jdk1.8中可以简单的这么写
JavaRDD<String> lines = sc.textFile("hdfs://master:9000/testFile/README.md");
JavaRDD<Integer> lineLengths = lines.map(s -> s.length());
int totalLength = lineLengths.reduce((a, b) -> a + b);要完成第二种方式的创建,简单的这么写
List<Integer> data = Arrays.asList(1, 2, 3, 4, 5);
JavaRDD<Integer> distData = sc.parallelize(data);主要不同就是在jdk1.7中我们要自己写一个函数传到map或者reduce方法中,而在jdk1.8中可以直接在map或者reduce方法中写lambda表达式
好了,今天就写到这里,以后的更多内容后面再写
码字不易,转载请指明出处http://blog.csdn.net/tanggao1314/article/details/51570452
参考资料
Spark编程指南

大家好,我是程序哥, 一个来自魔都的程序员,小马哥每个月会付我薪水。公众号推出“面试必备”专栏,跟我一起冲刺职场吧!















 1332
1332











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









