







举例:K-SVD最大的不同在字典更新这一步,K-SVD每次更新一个原子(即字典的一列)和其对应的稀疏系数,直到所有的原子更新完毕,重复迭代几次即可得到优化的字典和稀疏系数。如下。



如上图(左上),现在我们要更新第k个原子,即d_k..那我们需要知道在上一步迭代之后哪些信号使用了该原子,即稀疏系数不为0的部分是哪些?从左上图中很容易看出,x'的第k列T(x_k),也就是x的第k行中不为0的那部分所对应的T(y_k)即是我们要找的信号,结果见左下图蓝色部分。我们用d_k和稀疏系数x(k)'来重构这部分使用了d(k)的信号,它和T(y_k)的差值即E,右上图中绿色部分,接下来我们要使用最后这个图这个约束来更新x_k和d_k这两个值…如此反复,直到过完备字典D的所有原子更新完毕为止…求解这个x_k和d_k,直接对E进行SVD分解即可。
这里是我个人查资料后补充:
SVD decomposes  into
into 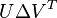 . The solution for
. The solution for  is the first column of U, the coefficient vector
is the first column of U, the coefficient vector 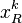 as the first column of
as the first column of  . After updated the whole dictionary, the process then turns to iteratively solve X, then iteratively solve D.
. After updated the whole dictionary, the process then turns to iteratively solve X, then iteratively solve D.
matlab代码
function [A,x]= KSVD(y,codebook_size,errGoal)%==============================
%input parameter
% y - input signal
% codebook_size - count of atoms
%output parameter
% A - dictionary
% x - coefficent
%==============================
if(size(y,2)<codebook_size)
disp('codebook_size is too large or training samples is too small');
return;
end
% initialization
[rows,cols]=size(y);
r=randperm(cols);
A=y(:,r(1:codebook_size));
A=A./repmat(sqrt(sum(A.^2,1)),rows,1);
ksvd_iter=10;
for k=1:ksvd_iter
% sparse coding
x=OMP(A,y,5.0/6*rows);
% update dictionary
for m=1:codebook_size
mindex=find(x(m,:));
if ~isempty(mindex)
mx=x(:,mindex); mx(m,:)=0; my=A*mx; resy=y(:,mindex);
mE=resy-my; [u,s,v]=svds(mE,1); A(:,m)=u; x(m,mindex)=s*v';
end
end
end















 206
206

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









