







JAVA
JAVA
简历:技术(10W)+ 项目(20W)+ 算法(30W) + 业务(50~100W) + 行业视野(上不封顶)
①JavaSE
JAVA背景知识
JDK安装和配置
程序的运行机制
- Java语言是编译型和解释型的结合
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存失败,源站可能有防盗a下来img-E8Ie02)(C:\Ue10V-526\011027\AppData\Roaming\Typora\typora-user-images\image-2021480310176152570.pg69)(C:\Users\UC241027\AppData\Roaming\Typora\typora-user-images\image-20210310171652570.png)]](https://img-blog.csdnimg.cn/20210312003618779.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L2xpdV90b19saXU=,size_16,color_FFFFFF,t_70)
- JVM(Java Virtual Machine):它定义了指令集、寄存器集、结构栈、垃圾收集堆、内存区域,负责java字节码解释运行,边解释边运行,一次编译随处运行。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-tPyAuFO8-1615480452506)(C:\Users\UC241027\AppData\Roaming\Typora\typora-user-images\image-20210310171254229.png)]](https://img-blog.csdnimg.cn/20210312003646844.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L2xpdV90b19saXU=,size_16,color_FFFFFF,t_70)
-
JRE(Java Runtime Environment):Java虚拟机、库函数、运行Java应用程序必须的文件。
-
JDK(Java Development Kit):包含JRE,以及增加编译器和调试器等用于程序开发的文件。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-KvO4YieD-1615480452508)(C:\Users\UC241027\AppData\Roaming\Typora\typora-user-images\image-20210310171344212.png)]](https://img-blog.csdnimg.cn/20210312003719808.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L2xpdV90b19saXU=,size_16,color_FFFFFF,t_70)
Java安装与配置
-
环境变量Path配置
JAVA_HOME : JAVA安装的目录
Path:%JAVA_HOME%\bin
第一个Java程序
-
Java编译的时候,出现unmappable character for encoding GBK
解决方法:
1、由于系统默认编码不是utf8,所以要将编译改写为javac -encoding UTF-8 XXX.java就可以正常输出
2、将XXX.java文件另存为–>选择编码ANSI保存
变量、数据类型、运算符
标识符
- ASCⅡ字符集:12^8 = 256
- Unicode国际字符集:2^16 = 65536
变量
-
变量本质是可操作的存储空间,空间位置是确定的,值不确定;变量名访问“对应的存储空间”,操作这个“存储空间”存储的值
-
局部变量、成员变量(也称实例变量)和静态变量
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-pL6TpdQv-1615480452511)(C:\Users\UC241027\AppData\Roaming\Typora\typora-user-images\image-20210310211250387.png)]](https://img-blog.csdnimg.cn/20210312003747473.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L2xpdV90b19saXU=,size_16,color_FFFFFF,t_70)
数据类型
- boolean类型是4个字节,数组中是1个字节(在内存中占1个字节或4个字节)
- 数字格式化输出

System.out.format("%.3f %.3f\n",r,volume);
System.out.printf("%.3f %.3f\n",r,volume);
运算符
-
整数运算:
两数有一个为long,则结果为long。
没有long时,结果为int。即使操作数全为short、byte,结果也是int。
-
浮点运算:
有一个为long,结果为long。
两个为float,结果才为float。
-
取模运算:
一般使用整数,结果是”余数“,”余数“符号和左边相同。
-
自增、自减
a++ //先赋值,再自增
++a //先自增,再赋值
-
关系运算符
>、>=、<、<= 仅针对数值类型(byte/short/int/long,float/double 以及char–>0~65535)
-
逻辑运算符
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-oCtv8dkQ-1615480452512)(C:\Users\UC241027\AppData\Roaming\Typora\typora-user-images\image-20210310230353130.png)]](https://img-blog.csdnimg.cn/20210312003807375.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L2xpdV90b19saXU=,size_16,color_FFFFFF,t_70)
-
位运算符
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-3Mb1d0ax-1615480452516)(C:\Users\UC241027\AppData\Roaming\Typora\typora-user-images\image-20210310231511440.png)]](https://img-blog.csdnimg.cn/20210312003820665.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L2xpdV90b19saXU=,size_16,color_FFFFFF,t_70)
-
数据类型的转换
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Tc6yegud-1615480452517)(C:\Users\UC241027\AppData\Roaming\Typora\typora-user-images\image-20210311133606475.png)]](https://img-blog.csdnimg.cn/20210312003836127.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L2xpdV90b19saXU=,size_16,color_FFFFFF,t_70)
整型常量是int类型,但是可以自动转为:byte、short、char。只要不超过对应类型的范围。
控制语句
-
控制语句分为:顺序、选择、循环;
-
任何软件和程序,本质上都是有"变量、选择语句、循环语句"组成。
switch语句
- switch语句中case标签在JDK1.5之前必须是整数(long类型除外)或枚举,不能字符串,但在JDK1.7之后允许使用字符串
Scanner类 键盘输入
-
java中Scanner类nextInt之后用nextLine无法读取输入
问题出现原因:
这是因为在调用nextLine()函数前调用了Scanner的另一个函数nextInt()(或是nextDouble())。出现这种情况的原因是两个函数的处理机制不同,nextInt()函数在缓冲区中遇到“空格”、“回车符”等空白字符时会将空白字符前的数据读取走,但空白字符不会被处理掉,而nextLine()函数是在缓冲区中读取一行数据,这行数据以“回车符”为结束标志,nextLine()会把包括回车符在内的数据提走。所以nextInt()后的nextLine()函数并非读取不到数据,因为nextInt()将“回车符”留在了缓冲区,nextLine()读取时遇到的第一个字符便是“回车符”,所以直接结束了。
解决方法:
在要使用nextLine()前先调用一次nextLine(),这样留在缓冲区的“回车符”就会被处理掉,这时第二个nextLine()函数可以正常读取到数据。
方法
方法重载(overload):实际是完全不同的方法,只是名称相同而已,释义:定义多个方法名相同,但参数不同的方法。
- 构成方法重载的条件:
- 不同的含义:形参类型、形参个数、形参顺序不同
- 只有返回值不同不构成方法的重载(如:int a(String str){}与void a(String str){}不构成方法重载)
- 只有形参的名称不同,不构成方法的重载
- 方法重写的三个要点:

面向对象编程
- 属性用于定义该类或该类对象包含的数据或者说静态特征。成员变量可以对其初始化,如果不对其初始化,Java使用默认的值对其初始化。
- 成员变量的默认值

- 构造器4个要点

- JAVA虚拟机内存模型概念

- 容易造成内存泄漏的操作
①. 创建大量无用对象
②.静态集合类的使用
③.各种连接对象(IO流对象、数据库连接对象、网络连接对象)未关闭
④.监听器的使用
- 对象的声明周期
- 创建对象四步
①.分配对象空间,并将对象成员变量初始化为0或空
②.执行属性值得显式初始化
③.执行构造方法
④.返回对象的地址给相关的变量 - 使用
通过变量引用操作对象 - 回收
对象咩有被变量使用,则被认为是”垃圾“,会被垃圾回收器回收
this、static关键字
this关键字
-
创建一个对象分为四步:

** this的本质是“创建好的对象地址”,在构造方法调用前,对象已经创建。因此,在构造方法中使用this表示"当前对象"。 -
this最常的用法

static关键字

继承
继承的实现
- 继承要点:

instanceof 运算符
instanceof是二元运算符,左边是对象,右边是类;当对象是右边类或子类所创建对象时,返回true;反之为false。
public class Person{
String name;
int age;
public static void main(String[] args){
Student s = new Student(“AAA”,66);
System.out.println(s instanceof Person);
System.out.println(s instanceof Student);
}
}
class Student extends Person{
}
方法的重写 override
子类通过重写父类的方法,可以用自身的行为替换父类的行为;方法的重写是实现多态的必要条件。
- 方法重写需要符合三个要点:

final关键字
属性和方法前加final,是不可扩展(继承)和更改的,方法不可重写,但可重载。
- final关键字的作用:

继承和组合
组合不同于继承,更加灵活。
组合的核心是将父类对象作为子类的属性,然后,子类通过调用这个属性来获取父类的属性和方法。
- 组合:吸收或并购
public class Animal{
public static void main(String[] args){
Taidi t = new Taidi();
t.dog.shout();
}
}
class Dog{
public void shout(){
System.out.println("wangwang....");
}
}
//组合
class Taidi {
Dog dog = new Dog(); //Taidi包含(吸收)了Dog,所以具备了Dog的属性和方法
}
总结: 继承除了代码复用、也能方便我们对事务建模。”is a“ 关系建议使用继承,”has a“ 关系建议使用组合。(如:Student is a Person逻辑就没问题,但Student has a Person就有问题了;笔记本和芯片的关系属于包含,则可以使用”has a“)
super关键字
- super 可以看做是直接父类对象的引用。通过super来访问被子类覆盖的方法或属性。
- 使用super调用普通方法,语句没有位置限制,可以在子类中随便调用。
- 若构造方法的第一行代码没有显式的调用super()或者this();那么java默认都会调用super(),含义是调用父类的无参数构造方法。super()可省略。
继承树追溯

封装(encapsulation)
- 封装的具体的优点

- 封装的实现—使用访问控制符
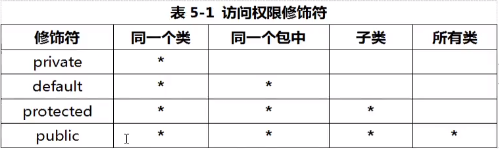
- protected需要注意的两个细节

- protected需要注意的两个细节
多态
多态指的是同一个方法调用,由于对象不同可能会有不同的行为。
- 多态的要点

- 多态的必要三个条件
- 继承
- 重写
- 父类引用指向子类对象
- 类型的强制转化,分编译和运行,编译看左边,编译之后是什么类型就执行什么样的方法;运行看右边。
抽象方法和抽象类
abstract修饰的方法,没有方法体,只有声明。定义的是一种"规范",就是告诉子类必须要给抽象方法提供具体的实现。
- 抽象类的使用要点:

接口 interface
- 面向对象的精髓,是对对象的抽象,最能体现这一点的就是接口。
- 接口就是比"抽象类"还"抽象"的"抽象类"。(abstract)
- 接口就是定标准的,就是要让别人实现的。(public)
- 接口声明方法的时候可以不写public和abstract,默认是有的。
- 接口定义的是不变的,如变量只能定义为常量。可以不写public abtract final来修饰变量,默认是有的。
定义接口的详细说明:

区别:
- 普通类:具体实现
- 抽象类:具体实现,规范(抽象方法)
- 接口:JDK1.8之前只有规范,但JDK1.8之后新增了静态方法和默认方法
- 默认方法:
默认方法和抽象方法的区别是抽象方法必须要被实现,因为默认方法有方法体,所以不需要实现,在接口中default必须要写,通过实现类的对象调用。 - 静态方法:
可以在接口中直接定义静态方法的实现。这个静态方法直接从属于接口(接口也是类,一种特殊的类),可以通过接口名调用。
- 默认方法:
接口的多继承
接口完全支持多继承,和类的继承类似,子接口扩展某个父接口,将会获得父接口中所定义的一切。
字符串String 类详解
字符串String是在方法区的字符串常量池(String Pool)中存储
String 类和常量池
-
常量池分三种:

-
String基础

内部类
- 内部类:
- 定义在一个类的内部的类,目的是方便使用外部类的相关属性和方法;
- 内部类只是一个编译时概念,一旦编译成功,就会成为完全不同的两个类。

- 内部类作用

- 内部类的分类

- 非静态内部类

//外部类
public class Outer {
private int age = 10;
private void show(){
System.out.println("good!!!");
}
//非静态内部类
public class Inner{
private String name = "tom";
private int age = 20;
public void showInner(){
System.out.println("Inner.showInner");
System.out.println(age);
System.out.println(Outer.this.age);
show();
}
}
public static void main(String[] args) {
Outer.Inner inner = new Outer().new Inner(); //通过 new 外部类名().内部类名() 来创建内部类对象
inner.showInner();
}
}
- 静态内部类

//外部类
public class Outer {
private int a = 10;
private static int b = 20;
//静态内部类
static class Inner{
public void test(){
System.out.println(b);
}
}
public static void main(String[] args) {
Outer.Inner inner = new Outer.Inner(); //通过 new 外部类名.内部类名() 来创建内部类对象
inner.test();
}
}
- 匿名内部类
适合那种只需要使用一次的类。
public class AnonymousInnerClass {
public void test(A a){
a.run();
}
public static void main(String[] args) {
AnonymousInnerClass anonymousInnerClass = new AnonymousInnerClass();
//匿名内部类
anonymousInnerClass.test(new A() {
@Override
public void run() {
System.out.println("匿名内部类是没有名字的类,只需使用一次;如果重新调用一次,就会定义新的匿名内部类!");
}
});
}
}
interface A{
void run();
}
- 局部内部类
定义在方法内部的,作用域只限于本方法。

public class LocalInnerClass{
public void show(){
//作用域仅限于该方法
class Inner{
public void fun(){
System.out.println("局部内部类的实现!");
}
}
new Inner().fun();
}
public static void main(String[] args){
new LocalInnerClass().show();
}
}
数组
数组:相同类型数据的有序集合,数组也是对象。
- 数组的四个基本特点

数组初始化
- 1、数组静态初始化
例如:
int[] a = {1,2,3}; //静态初始化基本类型数组
Man[] mans = {new Man(1,1),new Man(2,2)}; //静态初始化引用类型数组
- 2、数组动态初始化
例如:
int[] a = new int[2]; //动态初始化数组,先分配空间
a[0] = 1; //给数组元素赋值
a[1] = 2; //给数组元素赋值
- 3、数组的默认初始化

例如:
int[] a = new int[2]; //默认值:0,0
boolean[] b = new boolean[2]; //默认值:false,false
String[] s = new String[2]; //默认值:null,null
总结:默认初始化---->数组元素相当于对象的属性,遵守对象属性默认初始化的规则。
异常机制
当程序出现错误,程序安全的、继续执行的机制。
JAVA常用类
Wrapper包装类
包装类:可以把基本类型、包装类对象、字符串三者进行互相转化
-
自动装箱和拆箱



-
包装类的缓存问题
当数字在[-128,127]之间的时候,返回缓存数组中的某个元素。
public class Test{
public static void main(String[] args){
//当数字在[-128,127]之间的时候,返回的是缓存数组中的某个元素
Integer i1 = 123; //自动装箱;编译器:Integer i1 = Integer.valueOf(123);
Integer i2 = 123; //自动装箱;编译器:Integer i1 = Integer.valueOf(123);
System.out.println(i1 == i2); // true;是因为123都是从缓存中取的同一个元素
System.out.println(i1.equals(i2)); // true
}
}
/**
* 自定义包装类
*/
public class MyInteger {
private int value;
private static MyInteger[] cache;
public static final int LOW = -128;
public static final int HIGH = 127;
static{
cache = new MyInteger[(HIGH - LOW) + 1];
int j = LOW;
//[-128,127]
for(int i = 0;i < cache.length;i++){
cache[i] = MyInteger.valueOf(j++);
}
}
public static MyInteger valueOf(int i){
if(i >= LOW && i<= HIGH){
return cache[i - LOW];
}
return new MyInteger(i);
}
private MyInteger(int value){
this.value = value;
}
public static void main(String[] args) {
MyInteger m = MyInteger.valueOf(300);
}
}
字符串相关类
String类:不可变字符序列,会产生新对象的。
StringBuilder类:可变字符序列;效率高,但是线程不安全;添加字符序列,返回自身对象。
StringBuffer类:可变字符序列;效率低,但是线程安全;添加字符序列,返回自身对象。
- String 类
public class Test{
public static void main(String[] args){
//编译器做了优化,在编译的时候,右边是字符串常量,不是变量,所以直接将字符串做了拼接
String str1 = "hello" + " java"; //相当于 str1 = "hello java";
String str2 = "hello java";
System.out.println(str1 == str2); //true
String str3 = "hello";
String str4 = " java";
//编译的时候不知道变量中存储的是什么,所以没办法在编辑的时候做优化
String str5 = str3 + str4;
System.out.println(str2 == str5); //false
}
}
- 效率测试
public class Test {
public static void main(String[] args) {
String str = "";
long num1 = Runtime.getRuntime().freeMemory();
long time1 = System.currentTimeMillis();
for(int i = 0;i < 5000;i++){
str += i;
}
long num2 = Runtime.getRuntime().freeMemory();
long time2 = System.currentTimeMillis();
System.out.println("String占用内存:" + (num1 - num2));
System.out.println("String占用时间:" + (time2 - time1));
System.out.println("===================================");
StringBuilder sb = new StringBuilder("");
long num3 = Runtime.getRuntime().freeMemory();
long time3 = System.currentTimeMillis();
for(int i = 0;i < 5000;i++){
sb.append(i);
}
long num4 = Runtime.getRuntime().freeMemory();
long time4 = System.currentTimeMillis();
System.out.println("StringBuilder占用内存:" + (num3 - num4));
System.out.println("StringBuilder占用时间:" + (time4 - time3));
System.out.println("===================================");
StringBuffer sb2 = new StringBuffer("");
long num5 = Runtime.getRuntime().freeMemory();
long time5 = System.currentTimeMillis();
for(int i = 0;i < 5000;i++){
sb2.append(i);
}
long num6 = Runtime.getRuntime().freeMemory();
long time6 = System.currentTimeMillis();
System.out.println("StringBuffer占用内存;" + (num5 - num6));
System.out.println("StringBuffer占用时间:" + (time6 - time5));
}
}
效率测试结果如下:

File类
java.io.File类:代表文件和目录。
枚举
枚举类型隐形地继承自java.lang.Enum。枚举实质上还是类,而每个被枚举的成员实质就是一个枚举类型的实例。他们默认都是public static final修饰的。可以直接通过枚举类型名使用。
enum 枚举名 {
枚举体(常量列表)
}
- 特别注意:

集合(容器)
泛型
泛型简介
泛型是将类型基于一个占位符形式来定义,在泛型中,不可以使用基本类型,只能用对象类型来定义泛型。

- 泛型的好处:

总结一下:

- 类型擦除
编译时采用泛型写的类型参数,编译器会在编译时去掉。

泛型的使用
- 定义泛型

- 泛型类
泛型类是把泛型定义在类上。 - 泛型接口
泛型接口和泛型类的声明方式一致。泛型接口的具体类型需要在实现类中进行声明。 - 泛型方法
泛型方法是指将方法的参数类型定义成泛型,以便在调用时接受不同类型的参数。类型参数可以有多个,用逗号隔开,如:<K,V>。类型参数一般放到返回值前面。- 非静态方法

- 静态方法
静态方法无法访问类上定义的泛型;如果静态方法操作的引用数据类型不确定的时候,必须要将泛型定义在方法上。

- 非静态方法
- 泛型方法与可变参数
在泛型方法中,泛型也可以定义可变参数类型。

- 通配符和上下限定
- 无界通配符


- 通配符的上限限定
上限限定表示通配符的类型是T类以及T类的子类或者T接口以及T接口的子接口。

- 通配符的下限限定
下限限定表示通配符的类型是T类以及T类的父类或者T接口以及T接口的父接口。该方法不适用泛型类。

- 无界通配符
- 泛型总结

容器
数组也是一种容器,可以放置对象或基本类型数据
- 数组的优势:是一种简单的线性序列,可以快速地访问数组元素,效率高。仅从效率和类型检查的角度讲,数组是最好的。
- 数组的劣势:不灵活。容量需要事先定义好,不能随着需求的辩护而扩容。

总之,容器的底层都是基于数组来完成的。容器中数据都是存储在内存的。
List
List:有序(元素存入集合的顺序和取出的顺序一致)、可重复
- ArrayList是List接口的实现类。是List存储特征的具体实现。
- ArrayList底层是用数组实现的存储。特点:查询效率高、增删效率低、线程不安全。
- ArrayList:延迟扩容,如要扩容以1.5倍扩容。
Vector
Vector:底层使用数组实现的。线程安全,效率低。Vector的使用与ArrayList是相同的。初始容量是10,如要扩容以2倍扩容。
Stack
Stack:栈容器,是Vector的一个子类,它实现了一个标准的后进先出(LIFO:Last In First Out)的栈。
- 栈的操作

//栈容器使用案例
public class StackTest {
public static void main(String[] args) {
StackTest st = new StackTest();
st.symmetry();
}
//匹配符号的对称性
public void symmetry(){
String str = "...{.....[....(....)....]....}..(....)..[...]...";
//实例化Stack
Stack<String> stack = new Stack<>();
//假设修正法
boolean flag = true; //假设是匹配的
//拆分字符串获取字符
for(int i = 0;i < str.length();i++){
char c = str.charAt(i);
if(c == '{'){
stack.push("}");
}
if(c == '['){
stack.push("]");
}
if(c == '('){
stack.push(")");
}
//判断符号是否匹配
if(c == '}'||c == ']'||c == ')'){
if(stack.empty()){
flag = false;
break;
}
String x = stack.pop();
if(x.charAt(0) != c){
flag = false;
break;
}
}
}
if(!stack.empty()){
flag = false;
}
System.out.println(flag);
}
}
LinkedList
- 底层用双向链表实现的存储。特点:查询效率低,增删效率高,线程不安全。
- 实现了List接口,所以LinkedList是具备List的存储特征的(有序,元素有重复)
Set
Set特点:无序,不可重复。无序指Set中的元素没有索引,只能遍历查找;不可重复指不允许加入重复的元素。
HashSet
- HashSet:是一个没有重复元素的集合,不保证元素的顺序,线程不安全。允许有null元素;采用哈希算法实现,底层是用HashMap实现的,HashMap底层使用的是数组与链表实现元素的存储。查询效率和增删效率比较高。Hash算法也称之为散列算法。
无序:
不重复:


TreeSet

- 通过元素自身实现比较规则

- 通过比较器指定比较规则

Map
Map接口定义了双例集合的存储特征,它不是Collection接口的子接口。双例集合的存储特征是以key与value结构为单位进行存储的。
- Map与Collection的区别

HashMap

- HashMap的底层源码


TreeMap

Iterator 迭代器

- Iterator对象的工作原理

Collections工具类

数据结构
数据结构是以某种特定的布局方式存储数据(存储结构上差异)的容器。

- 数据结构逻辑分类
- 线性结构:元素存在一对一的相互关系
线性表、栈、队列、串(一堆数组)等 - 树形结构:元素存在一对多的相互关系
二叉树、红黑树、B树、哈夫曼树等 - 图形结构:元素存在多对多的相互关系
有向图、无向图、简单图等
线性结构
栈结构
栈是一种只能从一端存取数据且遵循"后进先出(LIFO)"原则的线性存储结构
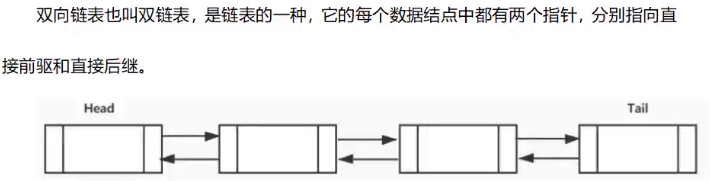
链表结构
链表结构是由许多节点构成的,每个节点都包含两部分:

- 链表分类
单向链表
双向链表
双向循环链表 - 链表的特点

- 链表的优缺点

单向链表结构

双向链表结构
树形结构

- 节点
使用树结构存储的每一个数据元素都被称为“结点”。 - 节点的度
某个结点所拥有的子树的个数 - 树的深度
树中节点的做大层次数 - 叶子结点
度为0的结点,也叫终端结点。 - 分支结点
度不为0的结点,也叫非终端结点或内部结点。 - 孩子
也可称之为子树或者子结点,表示当前节点下层的直接结点。 - 双亲
也可称之为父结点,表示当前结点的直接上层结点。 - 根节点
没有双亲结点的结点。在一个树形结构中只有一个根节点。 - 祖先
从当前结点上层的所有结点。 - 子孙
当前结点下层的所有结点。 - 兄弟
同一双亲的孩子。
二叉树

满二叉树


完全二叉树


二叉树遍历






正则表达式
Java中正则表达式为String类型,被验证的内容同样为String类型。通过String类中的matches方法实现内容的匹配校验。如:”被验证内容“.matches(“正则表达式”)

在定义限定内容规则是,如果没有指定长度限定,那么默认长度为1。
内容限定
- 单个字符限定
[a]:表示当前内容必须是字母a - 范围字符限定
[a-z0-9]:表示内容可以是a-z之间的任意字母或者0-9之间的任意数字,不分先后 - 取反限定
[^abc]:表示内容不能是a或b或c。
长度限定

长度限定符号

预定义字符
在正则表达式中可以通过一些预定义字符来表示内容限定。目的是为了简化内容限定的定义

组合定义
通过多个内容限定与长度限定来组合定义
常见的正则表达式
| :或者 ,如:a|b (a或b)
\\.:任意字符 ,如:-|\\. (-或任意一个字符)

IO流
- 数据源:提供数据的原始媒介。常见的数据源有:数据库、文件、其他程序、内存、网络连接、IO设备。

- 流:抽象、动态的概念,是一连串连续动态的数据集合。
输入流:数据流从数据源到程序(InputStream、Reader结尾的流)
输出流:数据流从程序到目的地(OutputStream、Writer结尾的流)



- JAVA中四大IO抽象类
InputStream/OutputStream和Reader/Writer类是所有IO类的抽象父类
InputStream: 字节输入流
OutputStream: 字节输出流
Reader: 读取的字符流抽象类,数据单位为字符
Writer: 输出的字符流抽象类,数据单位为字符
- Java中流的细分
按流的方向分类:
输入流:InputStream、Reader结尾的流
输出流:OutputStream、Writer结尾的流
按处理的数据单元分类:
字节流:以字节为单位获取数据,FileInputStream、FileOutputStream
字符流:以字符为单位获取数据,Reader/Writer结尾的流,如FIleReader、FileWriter
按处理对象不同分类
节点流:直接从数据源或目的地读写数据,如:FileInputStream、FileReader、DataInputStream
处理流:也叫包装流,不直接连接到数据源或目的地,是”处理流的流“。通过对其他流的处理提高程序的性能,如:BufferedInputStream、BufferedReader。

- 通过字节缓冲流提高读写效率

总结:



- File类
File类是Java提供的针对磁盘中的文件或目录转换对象的包装类。一个File对象可以代表一个文件或目录。
文件字节流
通过缓冲区提高读写效率
方式一:

public class FileDemo {
public static void main(String[] args) throws Exception{
try(FileInputStream fis = new FileInputStream("images/s1.jpg");
FileOutputStream fos = new FileOutputStream("images/11.jpg");
){
//创建一个缓冲区
byte[] buff = new byte[1024]; //空间换效率,效率低,但空间节省。
int len = 0;
while((len = fis.read(buff)) != -1){
fos.write(buff,0,len);
}
fos.flush();
}catch (Exception e){
e.printStackTrace();
}
}
}
方式二:

public class FileDemo {
public static void main(String[] args) throws Exception{
try(FileInputStream fis = new FileInputStream("images/s1.jpg");
FileOutputStream fos = new FileOutputStream("images/11.jpg");
){
//创建一个缓冲区
byte[] buff = new byte[fis.available()]; //效率换空间,占内存,但效率快
fis.read(buff);
fos.write(buff);
fos.flush();
}catch (Exception e){
e.printStackTrace();
}
}
}
通过字节缓冲流提高读写效率

public class FileCopyTools {
public static void main(String[] args) {
copyFile("images/s1.jpg","images/11.jpg");
}
/**
* 文件拷贝方法
*/
public static void copyFile(String src,String des){
try(BufferedInputStream bis = new BufferedInputStream(new FileInputStream(src));
BufferedOutputStream bos = new BufferedOutputStream(new FileOutputStream(des));
){
int temp = 0;
while((temp = bis.read()) != -1){
bos.write(temp);
}
bos.flush();
} catch (Exception e){
e.printStackTrace();
}
}
}
文件字符流
- 如果一个一个字符读取,结果是Unicode字符,需将结果强转char才能看懂数据内容。
- 如果是字符输出流,创建了两个字符输出流并同时向同一个文件输出内容,默认是会覆盖。除非加参数true,才能追加。
字符缓冲流
字符输入缓冲流
字符输出缓冲流



转换流
InputStreamReader/OutputStreamWriter用来实现将字节流转化成字符流。

字符输出流
- PrintWriter: 是节点流,可以直接作用于文件的。

字节数组流

字节数组输入流(ByteArrayInputStream)
- ByteArrayInputStream : 则是把内存的"字节数组对象"当做数据源。
- FileInputStream :是把文件当做数据源。
字节数组输出流(ByteArrayOutputStream)
- ByteArrayOutputStream:将流中的数据写入到字节数组中。
public class ByteArrayOutputStreamDemo {
public static void main(String[] args) {
ByteArrayOutputStream bos = null;
StringBuilder sb = new StringBuilder();
try{
bos = new ByteArrayOutputStream();
bos.write('a');
bos.write('b');
bos.write('c');
byte[] arr = bos.toByteArray();
for(int i = 0;i < arr.length;i++){
sb.append((char)arr[i]);
}
System.out.println(sb.toString());
}finally{
try{
if(bos != null){
bos.close();
}
}catch (Exception e){
e.printStackTrace();
}
}
}
}
数据流

- DataInputStream和DataOutputStream提供了可以存取与机器无关的所有Java基础类型数据(如:int、double、String等)。
数据输出流
//数据输出流
public class DataIOStreamDemo {
public static void main(String[] args) {
try(DataOutputStream dos = new DataOutputStream(new BufferedOutputStream(new FileOutputStream("data.txt")));){
dos.writeChar('a');
dos.writeInt(4);
dos.writeDouble(Math.random());
dos.writeUTF("您好");
dos.flush();
}catch (Exception e){
e.printStackTrace();
}
}
}
数据输入流
读取的顺序要与数据输出流写入的顺序一致,否则不能读取数据
//数据输入流
public class DataIOStreamDemo {
public static void main(String[] args) {
try(DataInputStream dis = new DataInputStream(new BufferedInputStream(new FileInputStream("data.txt")));){
//直接读取数据,注意:读取的顺序要与写入的顺序一致,否则不能读取数据
System.out.println("char:" + dis.readChar());
System.out.println("int:" + dis.readInt());
System.out.println("double:" + dis.readDouble());
System.out.println("utf:" + dis.readUTF());
}catch (Exception e){
e.printStackTrace();
}
}
}
对象流
数据流只能实现对基本数据类型和字符串类型的读写,并不能Java对象进行读写操作(字符串除外),而对象流除了能实现对基本数据类型进行读写操作,还能对Java对象进行读写操作。

- 对象的序列化和反序列化

序列化
对象的序列化:把java对象转换为字节序列的过程。
- 对象序列化的作用

- 序列化涉及的类和接口

import java.io.BufferedOutputStream;
import java.io.FileOutputStream;
import java.io.ObjectOutputStream;
//对象输出流完成基本数据类型的输出
public class ObjectIOStreamDemo {
public static void main(String[] args) {
try(ObjectOutputStream oos = new ObjectOutputStream(new BufferedOutputStream(new FileOutputStream("data")));){
oos.writeInt(10);
oos.writeDouble(Math.random());
oos.writeChar('a');
oos.writeBoolean(true);
}catch (Exception e){
e.printStackTrace();
}
}
}
- 将对象序列化到文件

反序列化
对象的反序列化:字节序列恢复为Java对象的过程。
随机访问流

- 核心方法

多线程
程序:

进程:

- 进程特点


线程:



- 线程和进程的区别


- 并发

- 方法的执行特点()

- 线程的执行方法的特点

- 主线程

- 主线程的特点
它是产生其他子线程的线程。
它不一定是最后完成执行的线程,子线程可能在它结束之后还在运行。
- 主线程的特点
- 主线程
在主线程中创建并启动的线程,一般称之为子线程。
线程的创建
通过继承Thread类实现多线程

通过实现Runnable接口实现多线程
前两种方式的缺点:1)、没有返回值;2)、不支持泛型;3)、异常必须处理
通过实现Callable接口实现多线程

线程的执行流程

线程的生命周期

- 新生状态

- 就绪状态

- 运行状态

- 阻塞状态

- 死亡状态


线程的使用
终止线程

import java.io.IOException;
public class StopThread implements Runnable{
private boolean flag = true;
@Override
public void run() {
System.out.println(Thread.currentThread().getName() + "线程开始");
int i = 0;
while(flag){
System.out.println(Thread.currentThread().getName() + " " + i++);
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
System.out.println(Thread.currentThread().getName() + "线程结束");
}
//劝自己自杀方式终止线程,线程能正常结束。
public void stop(){
this.flag = false;
}
public static void main(String[] args) throws IOException {
System.out.println("主线程开始");
StopThread st = new StopThread();
Thread t1 = new Thread(st);
//启动线程
t1.start();
System.in.read();
st.stop();
System.out.println("主线程结束");
}
}
- 暂停当前线程执行sleep/yield

- yield 方法的使用

- yield 方法的使用
线程联合

- join方法的使用

class A implements Runnable{
@Override
public void run() {
for (int i = 0; i < 10; i++) {
System.out.println(Thread.currentThread().getName() + " " + i);
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
public class JoinThread {
public static void main(String[] args) throws InterruptedException {
Thread t = new Thread(new A());
//启动A线程
t.start();
//主线程
for (int i = 0; i < 10; i++) {
System.out.println(Thread.currentThread().getName() + " " + i);
//当i=2时,主线程等待A线程结束之后再运行
if(i == 2){
t.join();
}
Thread.sleep(1000);
}
}
}
Thread类常用方法
- 获取当前线程名称


- 判断当前线程是否存活

线程优先级

守护线程


- 守护线程的特点:守护线程会随着用户线程死亡而死亡。
- 守护线程与用户线程的区别

线程同步(就是把并行改成串行)
synchronized可阻止并发更新同一个共享资源,实现了同步,但是synchronized不能用来实现不同线程之间的消息传递(通信)。

实现线程同步

-
synchronized 关键字使用时需要考虑的问题:



线程同步的使用
使用this作为线程对象锁
在不同线程中相同对象中synchronized会互斥。
语法结构:
synchronized(this){
//同步代码
}
或
public synchronized void accessVal(int newVal){
}
使用字符串作为线程对象锁
所有线程在执行synchronized时都会同步。因字符串是不变序列,所以会持有相同锁。
synchronized("字符串"){
//同步代码
}
使用Class作为线程对象锁
在不同线程中,拥有相同Class对象中的synchronized会互斥。
synchronized(XX.class){
//同步代码
}
或
synchronized public static void accessVal(){
//同步代码
}
使用自定义对象作为线程对象锁
在不同线程中,拥有相同自定义对象中的synchronized会互斥。放在线程中形成互斥锁。
synchronized(自定义对象){
//同步代码
}
死锁及解决方案
死锁是因为同一代码块出现嵌套synchronized造成的,解决方法是避免出现嵌套synchronized语句块。


线程并发协作(生产者/消费者模式)

-
角色:
生产者:负责生产数据的模块
消费者:负责处理数据的模块
缓冲区:消费者不能直接使用生产者数据,它们之间有个“缓冲区”。生产者将生产好的数据放入“缓冲区”,消费者从“缓冲区”拿要处理的数据。

缓冲区的好处:

-
wait() 方法:要在synchronized块中调用,该方法执行后,线程会将持有的对象锁释放,并进入阻塞状态,其他需要该对象锁的线程就可以继续运行了。
-
notify() 方法:要在在synchronized块中调用,该方法执行后,会唤醒处于等待状态队列中的一个线程
/**
* 定义馒头类
*/
class ManTou{
private int id;
public ManTou(int id){
this.id = id;
}
public int getId(){
return this.id;
}
}
/**
* 定义缓冲类
*/
class SyncStack{
//定义放馒头的盒子
private ManTou[] mt = new ManTou[10];
//定义盒子的suoyin
private int index;
/**
* 放馒头
*/
public synchronized void push(ManTou manTou){
while(this.index == this.mt.length){
try {
//该方法执行后,线程会将持有的对象锁释放,并进入阻塞状态,其他需要该对象锁的线程就可以继续运行了。
this.wait();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
this.notify(); //该方法执行后,会唤醒处于等待状态队列中的一个线程
this.mt[this.index] = manTou;
this.index++;
}
/**
* 取馒头
*/
public synchronized ManTou pop(){
while(this.index == 0){
try {
//该方法执行后,线程会将持有的对象锁释放,并进入阻塞状态,其他需要该对象锁的线程就可以继续运行了。
this.wait();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
this.notify(); //该方法执行后,会唤醒处于等待状态队列中的一个线程
this.index--;
return this.mt[this.index];
}
}
/**
* 定义生产者线程
*/
class Producer extends Thread{
private SyncStack ss;
public Producer(SyncStack ss){
this.ss = ss;
}
@Override
public void run() {
for (int i = 0; i < 10; i++) {
System.out.println("生产馒头:" + i);
ManTou manTou = new ManTou(i);
this.ss.push(manTou);
}
}
}
/**
* 定义消费者线程
*/
class Customer extends Thread{
private SyncStack ss;
public Customer(SyncStack ss){
this.ss = ss;
}
@Override
public void run() {
for (int i = 0;i < 10;i++) {
ManTou manTou = this.ss.pop();
System.out.println("消费馒头:" + i);
}
}
}
public class ProduceThread {
public static void main(String[] args) {
SyncStack ss = new SyncStack();
new Thread(new Producer(ss)).start();
new Thread(new Customer(ss)).start();
}
}
线程并发协作总结

- 线程通过哪些方法来进行消息传递,总结如下:
下列的方法均是java.lang.Object类的方法,都只能在同步方法或者同步代码块中使用,否则会抛出异常。

网络编程

网络通信协议
OSI七层协议模型:分别是:应用层、表示层、会话层、传输层、网络层、数据链路层、物理层。

TCP/IP协议
应用层、传输层、互联网络层、网络接口层(物理 + 数据链路层)




在www上,每一信息资源都有统一且唯一的地址。URL由四部分组成:协议、存放资源的主机域名、自愿文件和端口号。
Socket

TCP和UDP协议


TCP协议

UDP协议

网络编程中常用类
- InetAddress类:封装计算机的IP地址和域名。没有构造方法,如果要得到对象,只能通过getLocalHost()、getByName()等静态方法创建对象。
- InetSocketAddress类:包含IP和端口信息,常用于Socket通信。此类实现IP套接字地址(IP地址 + 端口号),不依赖任何协议。相比于InetAddress多了端口号。
- URL类:标识了计算机的资源,它是指向互联网“资源”的指针。(IP地址标识了Internet上唯一的计算机)
TCP通信实现
- 请求-响应 模式
Socket类:发送TCP消息
ServerSocket类:创建服务器

- Socket的编程顺序

UDP通信实现

- DatagramPacket:数据容器(封包)的作用
表示数据报包。数据报包用来实现将发送的数据进行封包处理的。 - DatagramSocket:用于发送或接收数据报包

- UDP通信编程基本步骤

XML
- XML和HTML之间的差异
XML主要作用是数据存储和传输
HTML主要作用是用来显示数据

Schema技术
Schema技术替代了DTD
作用:验证是否是“有效”的XML
反射



Lambda表达式
- 可以取代大部分的匿名内部类。
- 尤其在集合的遍历和其他集合操作中,可以极大地优化代码结构。
- JDK8之后利用Lambda新特性,就可以把一个代码块赋给变量。
- Lambda的类型都是一个接口。
- 只有一个接口函数需要被实现的接口类型,叫"函数式接口"。如果增加接口函数,则会导致有多个接口函数需要被实现,就变成了"非函数接口"。假如声明了@FunctionalInterface,这样就不能添加新的接口函数了。
- Lambda表达式只能定义一个抽象方法(接口或函数接口)。被default修饰的方法除外,因为它不是必须要实现的方法。


Lambda表达式语法
- 语法结构


- Lambda表达式的重要特征


Lambda案例

Lambda表达式的使用
有时候不必是使用Lambda的函数体定义实现,可以利用lambda表达式指向一个已经被实现的方法
- 语法
方法归属者::方法名 静态方法的归属者为类名,普通方法归属者为对象
闭包
闭包的本质是代码片断。所以闭包可以理解成一个代码片断的引用。在java中匿名内部类也是闭包的一种实现方式。
在闭包中访问外部的变量时,外部变量必须是final类型,虚拟机会帮我们加上final修饰关键字。














 312
312











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









