






目录
一、Docker 网络实现原理
Docker使用Linux桥接,在宿主机虚拟一个Docker容器网桥(docker0),Docker启动一个容器时会根据Docker网桥的网段分配给容器一个IP地址,称为Container-IP,同时Docker网桥是每个容器的默认网关。因为在同一宿主机内的容器都接入同一个网桥,这样容器之间就能够通过容器的 Container-IP 直接通信。
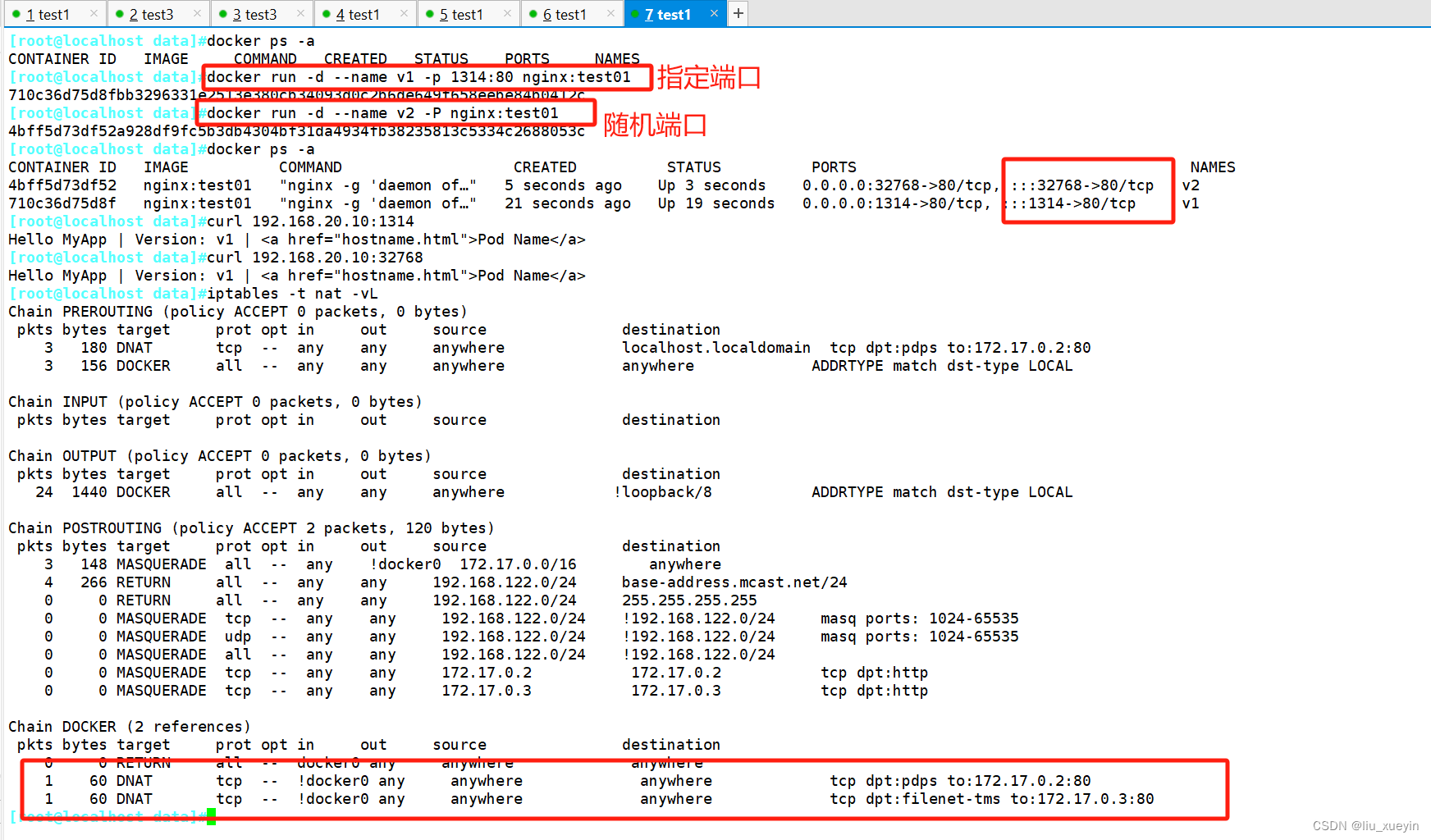
Docker网桥是宿主机虚拟出来的,并不是真实存在的网络设备,外部网络是无法寻址到的,这也意味着外部网络无法直接通过 Container-IP 访问到容器。如果容器希望外部访问能够访问到,可以通过映射容器端口到宿主主机(端口映射),即 docker run 创建容器时候通过 -p 或 -P 参数来启用,访问容器的时候就通过[宿主机IP]:[容器端口]访问容器。
#查看容器的输出和日志信息
docker logs 容器的ID/名称
查看的是容器中pid=1的主进程的日志


二、Docker 的网络模式
有四种基础网络模式+自定义网络
- Host:容器将不会虚拟出自己的网卡,配置自己的IP等,而是使用宿主机的IP和端口。
- Container:创建的容器不会创建自己的网卡,配置自己的IP,而是和一个指定的容器共享IP、端口范围。
- None:该模式关闭了容器的网络功能。
- Bridge:默认为该模式,此模式会为每一个容器分配、设置IP等,并将容器连接到一个docker0虚拟网桥,通过docker0网桥以及iptables nat 表配置与宿主机通信。
- 自定义网络
#使用docker run创建Docker容器时,可以用 --net 或 --network 选项指定容器的网络模式
●host模式:使用 --net=host 指定。
●none模式:使用 --net=none 指定。
●container模式:使用 --net=container:NAME_or_ID 指定。
●bridge模式:使用 --net=bridge 指定,默认设置,可省略。
安装Docker时,它会自动创建三个网络,
bridge(创建容器默认连接到此网络)、 none 、host
docker network ls
docker network list
##查看docker网络列表
#网络模式详解:
第一种:host模式
相当于Vmware中的桥接模式,与宿主机在同一个网络中,但没有独立IP地址。
Docker使用了Linux的Namespaces技术来进行资源隔离,如PID Namespace隔离进程,Mount Namespace隔离文件系统,Network Namespace隔离网络等。
一个Network Namespace提供了一份独立的网络环境,包括网卡、路由、iptable规则等都与其他的Network Namespace隔离。 一个Docker容器一般会分配一个独立的Network Namespace。 但如果启动容器的时候使用host模式,那么这个容器将不会获得一个独立的Network Namespace, 而是和宿主机共用一个Network Namespace。容器将不会虚拟出自己的网卡、配置自己的IP等,而是使用宿主机的IP和端口。
总结:容器与宿主机共享网络命名空间,即容器和宿主机使用同一个IP、端口范围(容器与宿主机或其它使用host模式的容器不能用同一个端口)、路由、iptables规则等网络资源。


[root@localhost data]#docker inspect b1 |grep host
"NetworkMode": "host",
[root@localhost data]#docker inspect b1 |grep -i network
"NetworkMode": "host",
[root@localhost data]#docker exec -it b1 sh
/ # ifconfig
/ # ping 192.168.20.6 
第二种:bridge模式
bridge模式是docker的默认网络模式,不用--net参数,就是bridge模式。
相当于Vmware中的 nat 模式,容器使用独立network Namespace,并连接到docker0虚拟网卡。通过docker0网桥以及iptables nat表配置与宿主机通信,此模式会为每一个容器分配Network Namespace、设置IP等,并将一个主机上的 Docker 容器连接到一个虚拟网桥上。
(1)当Docker进程启动时,会在主机上创建一个名为docker0的虚拟网桥,此主机上启动的Docker容器会连接到这个虚拟网桥上。虚拟网桥的工作方式和物理交换机类似,这样主机上的所有容器就通过交换机连在了一个二层网络中。
(2)从docker0子网中分配一个IP给容器使用,并设置docker0的IP地址为容器的默认网关。在主机上创建一对虚拟网卡veth pair设备。 veth设备总是成对出现的,它们组成了一个数据的通道,数据从一个设备进入,就会从另一个设备出来。因此,veth设备常用来连接两个网络设备。
(3)Docker将 veth pair 设备的一端放在新创建的容器中,并命名为 eth0(容器的网卡),另一端放在主机中, 以 veth* 这样类似的名字命名, 并将这个网络设备加入到 docker0 网桥中。可以通过 brctl show 命令查看。
(4)使用 docker run -p 时,docker实际是在iptables做了DNAT规则,实现端口转发功能。可以使用iptables -t nat -vnL 查看。

[root@localhost data]#docker run -d --name d2 -p 3344:80 --net=bridge nginx:test01
#--name 选项可以给容器创建一个自定义名称
[root@localhost data]#docker inspect d2|grep -i network
[root@localhost data]#docker inspect d2|grep -i ipaddress

[root@localhost data]#ifconfig docker
docker0: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 172.17.0.1 netmask 255.255.0.0 broadcast 172.17.255.255
inet6 fe80::42:55ff:fe03:9d7a prefixlen 64 scopeid 0x20<link>
ether 02:42:55:03:9d:7a txqueuelen 0 (Ethernet)
RX packets 248 bytes 21320 (20.8 KiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 340 bytes 25341 (24.7 KiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
[root@localhost data]#iptables -t nat -vnL

[root@localhost data]#docker exec -it d1 sh
/ # ifconfig
/ # ping 172.17.0.3

总结:该模式是默认的docker网络模式,每个容器拥有自己独立的网络命名空间。意味着每一个容器有自己独立的ip和端口范围以及路由器和iptables规则;
容器连接到docker0的虚拟网桥,通过docker0网桥以及iptables nat表配置(端口映射)与宿主机之间进行通信。
同时容器之间也可以通信
第三种:container模式
这个模式指定新创建的容器和已经存在的一个容器共享一个Network Namespace,而不是和宿主机共享。 新创建的容器不会创建自己的网卡,配置自己的IP,而是和一个指定的容器共享IP、端口范围等。同样,两个容器除了网络方面,其他的如文件系统、进程列表等还是隔离的。两个容器的进程可以通过lo网卡设备通信。
[root@localhost data]#docker run -id --name test1 --net=container:d2 centos:7 /bin/bash
[root@localhost data]#docker ps -a
[root@localhost data]#docker run -id --name test2 --net=container:d2 nginx:test01
新创建的容器和已经存在的一个容器共享一个Network Namespace
验证:
实际上这6个文件也对应了6大命名空间
[root@localhost data]#docker inspect -f {{.State.Pid}} test1
#查看容器进程号
[root@localhost data]#ll /proc/17491/ns/
#查看容器的进程、网络、文件系统等命名空间编号
第四种:none模式
使用none模式,Docker容器拥有自己的Network Namespace,但是,并不为Docker容器进行任何网络配置。 也就是说,这个Docker容器没有网卡、IP、路由等信息。这种网络模式下容器只有lo回环网络,没有其他网卡。这种类型的网络没有办法联网,封闭的网络能很好的保证容器的安全性。
[root@localhost data]#docker run -d --name c2 --net=none nginx:test01
[root@localhost data]#docker exec -it c2 sh
/ # ifconfig 
第五种:自定义网络
#直接使用bridge模式,是无法支持指定IP运行docker的,例如执行以下命令就会报错
[root@localhost data]#docker run -itd --name a1 --network bridge --ip 172.17.0.10 centos:7 /bin/bash
//创建自定义网络
#可以先自定义网络,再使用指定IP运行docker
docker network create --subnet=172.18.0.0/16 --opt "com.docker.network.bridge.name"="docker1" mynetwork
----------------------------------------------------------------------------------------------------------
#docker1 为执行 ifconfig -a 命令时,显示的网卡名,如果不使用 --opt 参数指定此名称,那你在使用 ifconfig -a 命令查看网络信息时,看到的是类似 br-110eb56a0b22 这样的名字,这显然不怎么好记。
#mynetwork 为执行 docker network list 命令时,显示的bridge网络模式名称。
----------------------------------------------------------------------------------------------------------
[root@localhost data]#docker run -itd --name n2 --net=mynetwork --ip 172.18.0.100 nginx:test01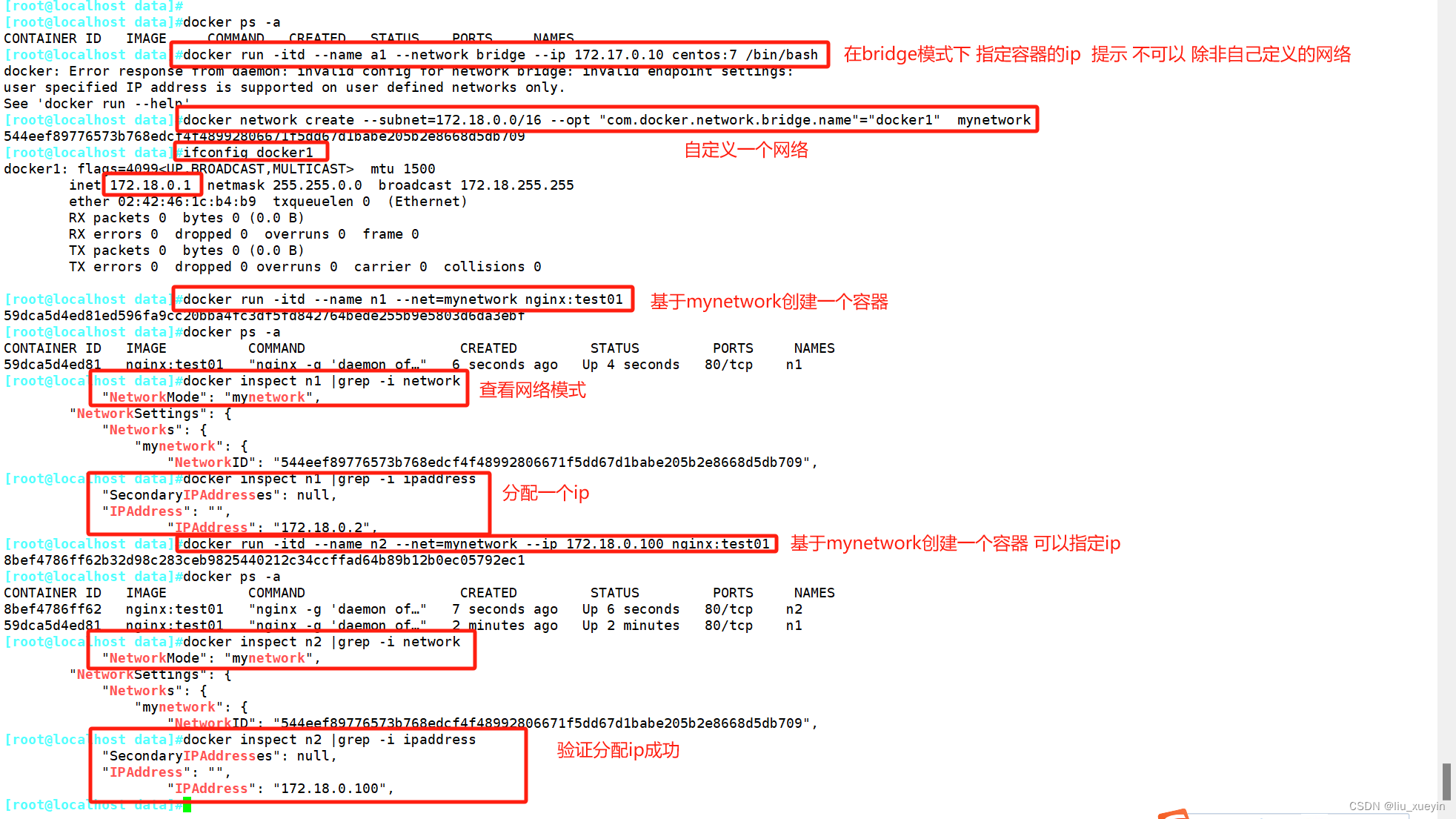
三、Cgroup资源控制
Docker 通过 Cgroup 来控制容器使用的资源配额,包括 CPU、内存、磁盘三大方面, 基本覆盖了常见的资源配额和使用量控制。
Cgroup 是 ControlGroups 的缩写,是 Linux 内核提供的一种可以限制、记录、隔离进程组所使用的物理资源(如 CPU、内存、磁盘 IO 等等) 的机制,被 LXC、docker 等很多项目用于实现进程资源控制。Cgroup 本身是提供将进程进行分组化管理的功能和接口的基础结构,I/O 或内存的分配控制等具体的资源管理是通过该功能来实现的。
第一种:CPU 资源控制
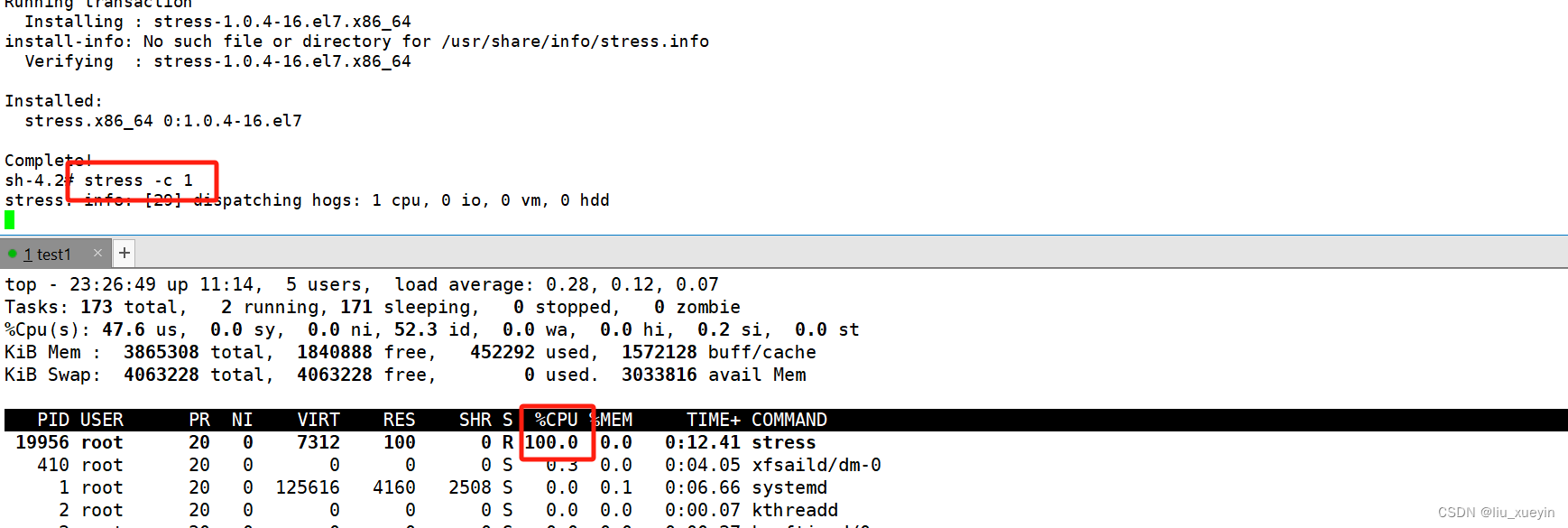
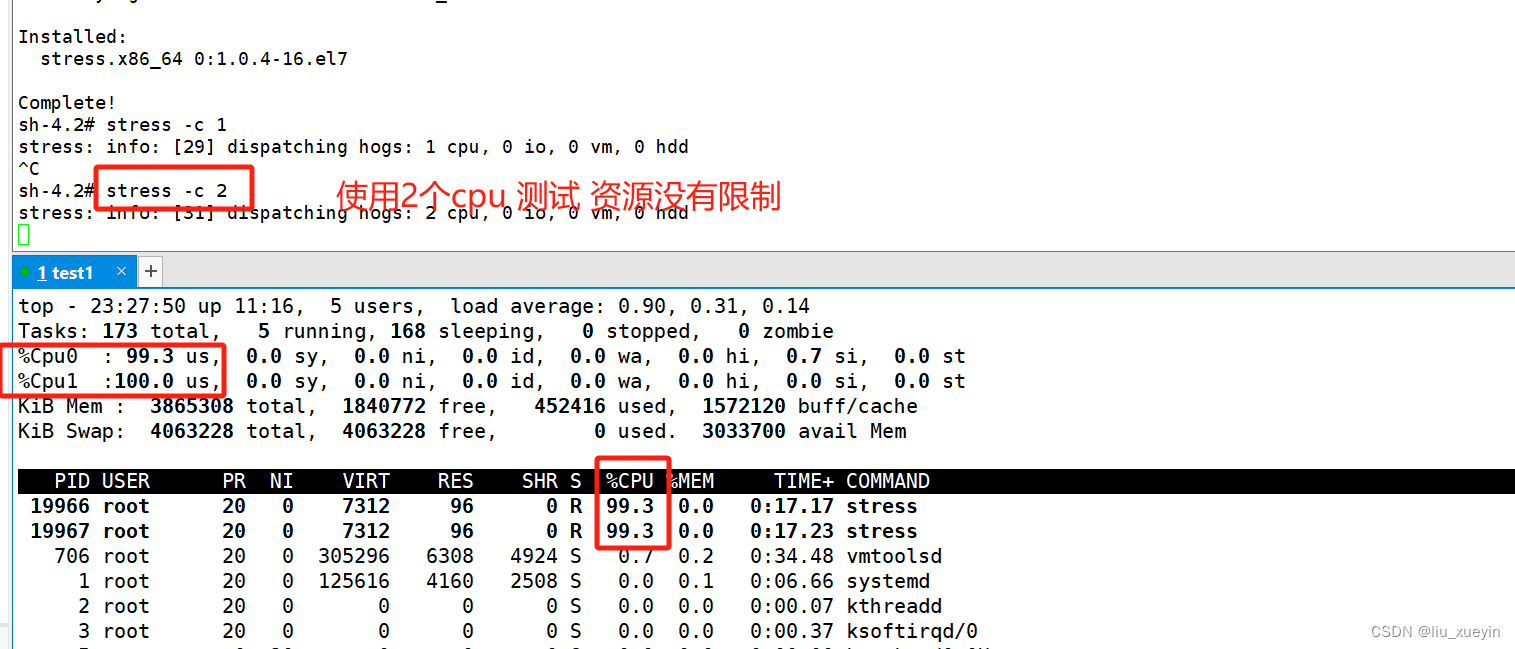
(1)设置CPU使用率上限
Linux通过CFS(Completely Fair Scheduler,完全公平调度器)来调度各个进程对CPU的使用。CFS默认的调度周期是100ms。
我们可以设置每个容器进程的调度周期,以及在这个周期内各个容器最多能使用多少 CPU 时间。
使用 --cpu-period 即可设置调度周期,使用 --cpu-quota 即可设置在每个周期内容器能使用的CPU时间。两者可以配合使用。
CFS 周期的有效范围是 1ms~1s,对应的 --cpu-period 的数值范围是 1000~1000000。
而容器的 CPU 配额必须不小于 1ms,即 --cpu-quota 的值必须 >= 1000。
先下载好压测工具


 做单个容器cpu使用率限制
做单个容器cpu使用率限制

...........................................................后续再补充....................................................
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











