







1. Java中,常用的容器都有哪些,列举几个?
Java中常用的容器有:
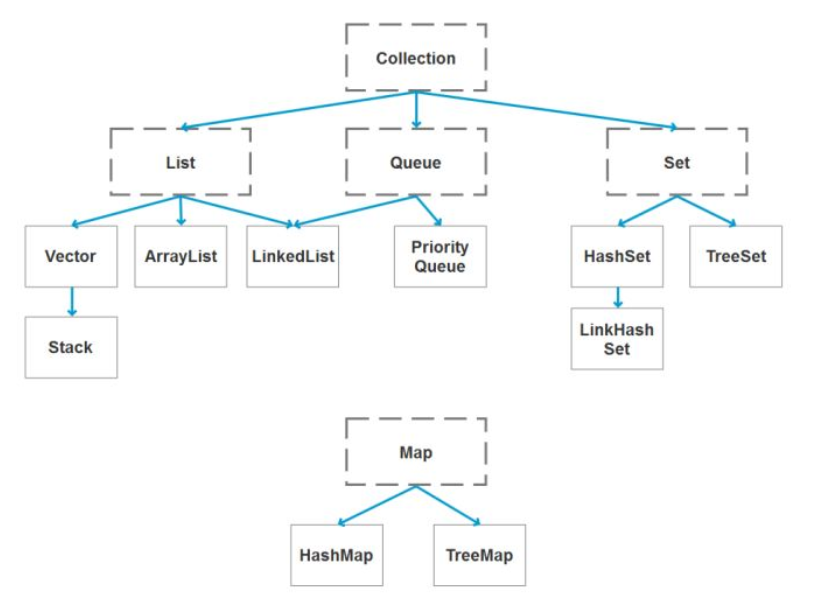
1)Collection 接口
Collection是Java集合框架的根接口,它定义了集合的基本操作,如添加、删除、遍历等。Collection接口有两个主要的子接口:List和Set。
2)List 接口
List是一个有序的集合,允许元素重复,并且提供了按照下标访问元素的操作。List接口的实现类主要有:
- ArrayList:基于动态数组实现的List,支持随机访问,但插入和删除操作可能需要移动元素,因此效率较低。
- LinkedList:基于链表实现的List,插入和删除操作效率高,但不支持随机访问。
- Vector:与ArrayList类似,但它是同步的,适用于多线程环境。不过,由于同步开销,Vector的性能通常低于ArrayList。
- Stack:继承自Vector,实现了一个后进先出(LIFO)的栈结构。
3)Set 接口
Set是一个不允许有重复元素的集合,其元素是无序的。Set接口的实现类主要有:
- HashSet:基于哈希表实现的Set,不保证元素的迭代顺序,允许使用null元素。
- LinkedHashSet:继承自HashSet,通过链表维护元素的插入顺序,因此可以保证元素的迭代顺序与插入顺序一致。
- TreeSet:基于红黑树实现的Set,可以保证元素的自然排序或根据构造时提供的Comparator进行排序。
4)Map 接口
Map是一个将键映射到值的对象,一个键最多只能映射到一个值。Map接口的实现类主要有:
- HashMap:基于哈希表实现的Map,允许使用null键和null值。
- Hashtable:与HashMap类似,但它是同步的,适用于多线程环境。不过,由于同步开销,Hashtable的性能通常低于HashMap。另外,Hashtable不允许使用null键和null值。
- TreeMap:基于红黑树实现的Map,可以保证键的自然排序或根据构造时提供的Comparator进行排序。
- LinkedHashMap:继承自HashMap,通过链表维护元素的插入顺序或访问顺序。
2. Collection 和 Collections 有什么区别?
1)定义与用途
Collection是Java集合框架中的根接口,它表示一组对象的集合。它定义了集合的基本操作和行为,如添加、删除、遍历等。Collection是一个抽象的概念,不能直接实例化。它主要用于定义集合操作的标准方法,这些方法被其所有子接口(如List、Set)和实现类(如ArrayList、HashSet)所继承和实现。
Collections是Java集合框架中的一个工具类,提供了一系列静态方法,用于对集合进行操作。Collections类的方法主要用于对集合进行一些通用操作,如排序、查找、替换等。这些方法都是静态的,可以直接通过类名调用,无需创建Collections类的实例。
2)实现方式
Collection:作为一个接口,Collection需要通过其实现类(如ArrayList、HashSet等)进行实例化,才能使用其定义的方法。
Collections:作为一个工具类,Collections不需要实例化。它提供的所有方法都是静态的,可以直接通过类名调用。
3)提供的方法
Collection:定义了一系列集合操作的标准方法,如
add(E e)、remove(Object o)、contains(Object o)、size()、isEmpty()、iterator()等。这些方法被其所有子接口和实现类所继承和实现。Collections:提供了一系列静态方法,用于对集合进行操作。这些方法包括
sort(List<T> list)、max(Collection<? extends T> coll)、min(Collection<? extends T> coll)、shuffle(List<?> list)、reverse(List<?> list)等。这些方法通常用于对集合进行排序、查找最大值、最小值、混排、反转等操作。
4)示例对比
使用Collection接口
List<Integer> list = new ArrayList<>(); list.add(3); list.add(1); list.add(2); // 遍历集合并打印元素 for (Integer num : list) { System.out.println(num); }使用Collections类:
List<Integer> list = new ArrayList<>(); list.add(3); list.add(1); list.add(2); // 使用Collections类的sort方法对集合进行排序 Collections.sort(list); // 遍历集合并打印排序后的元素 for (Integer num : list) { System.out.println(num); } // 使用Collections类的max方法获取集合中的最大值 Integer max = Collections.max(list); System.out.println("Max value: " + max);
3. List、Set、Map 之间的区别是什么?
1)存储方式和元素重复性
List:List是一个有序的集合,可以包含重复的元素。它允许通过索引来访问元素,这意味着List中的每个元素都有一个唯一的整数索引,从0开始。List接口的实现类主要有ArrayList、LinkedList等。
Set:Set是一个无序且不包含重复元素的集合。Set接口的实现类主要有HashSet、TreeSet等。需要注意的是,虽然Set是无序的,但TreeSet是一个例外,它能够对元素进行排序。
Map:Map是一种将键(Key)映射到值(Value)的对象,一个键可以映射到最多一个值。Map接口的实现类主要有HashMap、TreeMap等。Map中的键不能重复,但值可以重复。
2)有序性
List:List是有序的,元素的存储顺序与插入顺序一致。
Set:Set通常是无序的,元素的存储顺序不保证与插入顺序一致。但是,TreeSet是一个例外,它会对元素进行排序。
Map:Map中的元素是按照键的自然顺序或创建Map时提供的Comparator进行排序的(在TreeMap中),而在HashMap中则不保证顺序。LinkedHashMap保持了元素的插入顺序。
3)重复元素
List:允许包含重复的元素。
Set:不允许包含重复的元素。
Map:键(Key)不能重复,但值(Value)可以重复。
4)主要实现类及其特点
List:
- ArrayList:基于动态数组实现,支持快速随机访问,但插入和删除操作可能需要移动大量元素,效率较低。
- LinkedList:基于链表实现,支持高效的插入和删除操作,但不支持快速随机访问。
Set:
- HashSet:基于哈希表实现,提供快速的插入、删除和查找操作,但不保证元素的迭代顺序。
- TreeSet:基于红黑树实现,能够对元素进行排序,但插入、删除和查找操作的时间复杂度为O(log n)。
Map:
- HashMap:基于哈希表实现,提供快速的插入、删除和查找操作,但不保证映射的顺序。
- TreeMap:基于红黑树实现,能够对键进行排序,提供有序的映射视图。
- LinkedHashMap:保持了元素的插入顺序,或者最近最少使用(LRU)顺序,如果构造时指定了accessOrder为true。
5) 应用场景
List:适用于需要保持元素插入顺序的场景,或者需要频繁访问列表中间元素的场景。
Set:适用于不需要保持元素插入顺序,且不允许重复元素的场景。当需要快速查找、插入和删除元素时,HashSet是一个很好的选择。如果需要元素有序,则可以使用TreeSet。
Map:适用于需要存储键值对数据的场景。HashMap适用于大多数需要快速访问的场景,而TreeMap适用于需要按键排序的场景。LinkedHashMap则适用于需要保持插入顺序或访问顺序的场景。
4. HashMap 和 Hashtable 有什么区别?
1) 线程安全性
HashMap:不是线程安全的。如果在多线程环境下同时访问和修改HashMap,可能会导致数据不一致或丢失。因此,在多线程环境中使用HashMap时,需要外部同步。
Hashtable:是线程安全的。Hashtable的每个方法都是通过
synchronized关键字实现的同步,这意味着多个线程可以同时访问Hashtable而不会出现数据竞争问题。然而,线程安全也带来了性能开销。
2)对null的支持
HashMap:允许键(Key)和值(Value)为null,但需要注意的是,由于HashMap的键是唯一的,如果存储了多个null键,那么只有一个null键会被保留,其他的null键会被覆盖。
Hashtable:不允许键(Key)或值(Value)为null。如果尝试存储null键或值,将会引发
NullPointerException异常。
3)实现和继承关系
HashMap:继承自
AbstractMap类,实现了Map接口。Hashtable:继承自
Dictionary类,实现了Map接口。不过,Dictionary类是一个较旧的接口,现在较少使用。
4) 提供的接口
HashMap:提供了较为基本的接口,如
put、get、containsKey、containsValue等。Hashtable:除了
HashMap提供的接口外,还提供了elements()和contains()两个方法。其中,elements()方法用于返回此Hashtable中的值的枚举,而contains()方法用于判断该Hashtable是否包含传入的value,其作用与containsValue()一致。但需要注意的是,随着Java版本的更新,推荐使用Iterator或Spliterator等更现代的迭代方式。
5)初始容量和扩容机制
HashMap和Hashtable在初始容量和扩容机制上有所不同,但具体细节可能因Java版本而异。一般来说,它们都会根据元素的增加动态扩容,但扩容的触发条件和扩容的具体实现可能有所不同。
6)性能
HashMap:通常比Hashtable具有更高的性能,因为它不是线程安全的,不需要进行同步操作。然而,在多线程环境下,HashMap的性能可能会受到影响。
Hashtable:由于线程安全性的开销,Hashtable的性能通常低于HashMap。但在单线程环境下,这种差异可能并不明显。
7) 应用场景
HashMap:适用于大多数单线程环境下的键值对存储需求。当需要快速查找和插入元素时,HashMap是一个很好的选择。
Hashtable:适用于多线程环境下的键值对存储需求,尤其是当线程安全是首要考虑因素时。然而,随着Java并发包(java.util.concurrent)的引入,
ConcurrentHashMap等并发集合提供了更好的性能和线程安全性,因此在许多情况下可能更推荐使用它们。
5. 如何决定使用 HashMap 还是 TreeMap?
在选择使用 HashMap 还是 TreeMap 时,需要考虑访问数据的速度和数据的顺序性。
1)访问速度:HashMap 的访问速度比 TreeMap 更快,因为 HashMap 内部使用哈希表,能够快速定位到元素;而 TreeMap 则是基于红黑树实现的,需要进行树的查找操作,效率较低。
2)数据顺序性:如果需要按照键的顺序来访问映射表中的元素,则应该使用 TreeMap;因为 TreeMap 会自动按照键值进行排序,因此在需要有序访问数据的场合,比如需要将元素遍历输出或排序,或者需要查找最小值和最大值等操作,使用 TreeMap 会更加合适。而如果不需要有序访问数据,则应该使用 HashMap。
3) 是否需要键值对的顺序保持一致:HashMap 和 TreeMap 的元素遍历顺序可能不同,因此,如果需要遍历顺序一致,则应该使用 LinkedHashMap,它是 HashMap 的子类,但它会保持元素插入顺序或者访问顺序不变。如果需要排序,可以使用 TreeMap。
















 1352
1352

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









