







系统总体架构
整个集群NAS主要由集群文件系统、高可用NAS集群、LVS负载集群三个逻辑部分组成,如图1所示。集群文件系统使用glusterfs,它具有全局统一命名空间、高性能、高可用、高扩展等特点,它最大特点是采用无元数据服务设计。集群NAS系统基于标准的NFS/CIFS/HTTP/FTP等协议来提供数据访问服务,这里采用NFS/Samba/Httpd/vsftpd开源软件来,多个物理节点通过CTDB构建成高可用NAS集群。集群负载均衡使用国人主导开创的LVS系统来实现,对外使用单一IP提供服务。综合采用Glusterfs, NFS, Samba, CTDB, LVS这些开源软件系统,我们可以构建出于毫不逊色于商业系统的集群NAS系统。图1所示的系统总体架构,逻辑上由三个独立物理集群构成,实际构建部署中这三个集群位于同一个物理集群上,以上这些开源部署在所有节点上。如此,即可有效提高每个节点的利用效率,更为重要的是能够大大节约成本。本文余下部分将详细解说如何基于开源软件构建一个具有三个节点的集群NAS系统。
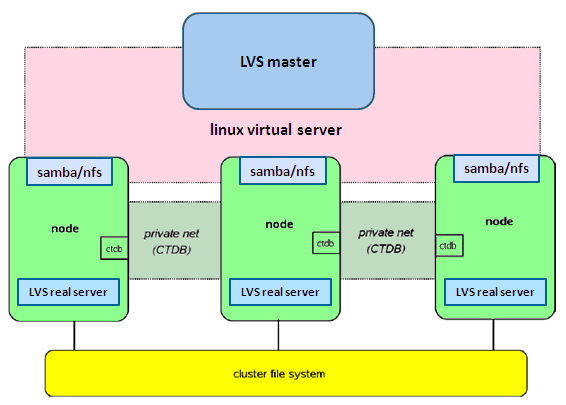
图1 集群NAS系统总体架构
“集群”主要分为高性能集群HPC(High Performance Cluster)、高可用集群HAC(High Availablity Cluster)和负载均衡集群LBC(Load Balancing Cluster)。集群文件系统是指协同多个节点提供高性能、高可用或负载均衡的文件系统,它是分布式文件系统的一个子集,消除了单点故障和性能瓶问题。对于客户端来说集群是透明的,它看到是一个单一的全局命名空间,用户文件访问请求被分散到所有集群上进行处理。此外,可扩展性(包括Scale-Up和Scale-Out)、可靠性、易管理等也是集群文件系统追求的目标。在元数据管理方面,可以采用专用的服务器,也可以采用服务器集群,或者采用完全对等分布的无专用元数据服务器架构。目前典型的集群文件系统有SONAS, ISILON, IBRIX, NetAPP-GX, Lustre, PVFS2, GlusterFS, Google File System, LoongStore, CZSS等。集群文件系统是构建集群NAS的底层核心部分,在开源集群文件系统方面,Lustre, Glusterfs, Ceph, MooseFS等是主流,我们这里选择glusterfs进行构建集群NAS。
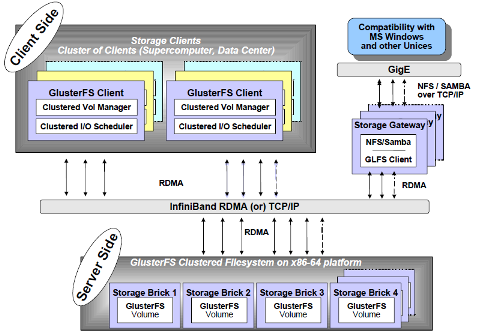
图2 glusterfs系统架构
GlusterFS是Scale-Out存储解决方案Gluster的核心,它是一个开源的分布式文件系统,具有强大的横向扩展能力,通过扩展能够支持数PB存储容量和处理数千客户端。GlusterFS借助TCP/IP或InfiniBand RDMA网络将物理分布的存储资源聚集在一起,使用单一全局命名空间来管理数据。GlusterFS基于可堆叠的用户空间设计,可为各种不同的数据负载提供优异的性能。Glusterfs的主要特征包括:高扩展性和高性能、高可用性、全局统一命名空间、弹性哈希算法、弹性卷管理、基于标准协议,技术实现特点包括:完全软件实现、完整的存储操作系统栈、用户空间实现、模块化堆栈式架构、原始数据格式存储、无元数据服务设计。关于glusterfs更多信息请参考"Glusterfs集群文件系统研究"一文。
Glusterfs集群文件安装配置详细过程如下:
(1) 安装软件
从http://download.gluster.com/pub/gluster/glusterfs/LATEST/下载glusterfs软件,源码及安装包均可。下面以glusterfs-3.2.5.tar.gz源码进行安装,在所有brick server操作均相同。
cd /opt/
yum install flex bison
wget http://download.gluster.com/pub/gluster/glusterfs/LATEST/glusterfs-3.2.5.tar.gz
tar xvzf glusterfs-3.2.5.tar.gz
cd glusterfs-3.2.5
./configure
make & make install
service glusterd start
chkconfig glusterd on(2) 系统配置
在其中一个节点进行,假设为192.168.1.54,其他两个节点为192.168.1.55和192.168.1.56
gluster volume info (测试glusterd服务是否运行正常)
gluster peer probe 192.168.1.55 (将192.168.1.55加入集群)
gluster peer probe 192.168.1.56 (将192.168.1.56加入集群)
gluster peer status(3) 系统测试
创建一个卷并进行mount测试,假设在192.168.1.54上进行
gluster volume create testvol 192.168.1.54:/gluster/testvol 192.168.1.55:/gluster/testvol 192.168.1.56:/gluster/testvol
glsuter volume start testvol
mount -t glusterfs 192.168.1.54:/testvol /mnt/
mount (查看所的挂载的文件系统)
df -h (查看挂载文件系统的容量信息)高可用集群NAS
诸如Glusterfs、Lustre、Ceph等集群文件系统,提供了统一命名空间、高性能、高可用、高扩展的非结构化数据解决方案。出于性能方面考虑,集群文件系统都设计了私有协议的客户端,通常是基于VFS或FUSE接口实现的与POSIX标准兼容的接口,但往往仅提供Linux/Unix系统客户端软件。对于Linux/Unix系统来说,只需要安装集群文件系统客户端内核模块或软件即可;而对于Windows/Mac等系统而言,因为没有客户端软件可用,就没法访问集群文件系统了。另外,一些特殊场合下,用户不希望在Linux/Unix/Windows/Mac系统上安装客户端软件,而是希望通过标准协议访问集群文件系统。因此,我们需要以集群文件系统为底层基础核心,构建使用标准协议访问的存储服务,目前主要就是使用NFS/CIFS标准协议的NAS。传统NAS系统具有单点性能瓶颈、扩展性差、应用规模和高负载支持有限等不足,无法满足大数据应用需求。集群NAS是一种横向扩展(Scale-out)存储架构,它协同多个节点(即通常所称的NAS机头)提供高性能、高可用或高负载均衡的NAS(NFS/CIFS)服务,具有容量和性能线性扩展的优势。

图3 CTDB基本架构
这里我们基于CTDB实现高可用集群NAS。CTDB是一种轻量级的集群数据库实现,基于它可以实现很多应用集群,目前CTDB支持Samba, NFS, HTTPD, VSFTPD, ISCSI, WINBIND应用,集群共享数据存储支持GPFS,GFS(2),Glusterfs, Luster, OCFS(2)。CTDB本身不是HA解决方案,但与集群文件系统相结合,它可以提供一种简便高效的HA集群解决方案。集群配置两组IP,Private IP用于heartbeat和集群内部通信,Public IP用于提供外部服务访问。Public IP动态在所有集群节点上分配,当有节点发生故障,CTDB将调度其他可用节点接管其原先分配的Public IP,故障节点恢复后,漂移的Public IP会重新被接管。这个过程对客户端是透明的,保证应用不会中断,也就是我们这里所说的高可用HA。
高可用集群NAS的安装配置详细过程如下:
(1) IP配置
Single IP: 192.168.1.50 (后面由LVS使用,对外提供单一IP访问)
Public IP: 192.168.1.51, 192.168.1.52, 192.168.1.53 (用于外部访问,或提供给LVS进行负载均衡)
Private IP: 192.168.1.54, 192.168.1.55, 192.168.1.56 (用于内部访问,heartbeat及集群内部通信)
(2) 挂载集群文件系统
这里使用Glusterfs集群文件系统为所有节点提供共享存储空间,并为CTDB提供lock和status等共享存储空间。CTDB卷建议采用gluster replica volume,NAS卷可以根据实际需求选择distribute, stripe, replica及复合卷。如下创建两个卷,在IP: 192.168.1.54上进行:
gluster volume create nas replica 2 192.168.1.54:/gluster/nas 192.168.1.55:/gluster/nas (replica卷)
gluster volume create ctdb 192.168.1.54:/gluster/ctdb 192.168.1.55:/gluster/ctdb 192.168.1.56:/gluster/ctdb (distribute卷)
gluster volume start nas
gluster volume start ctdb在三个节点上同时mount以上创建的nas和ctdb卷:
mkdir /gluster/data
mkdir /gluster/lock
mount -t glusterfs 192.168.1.54:/ctdb /gluster/lock (CTDB使用)
mount -t glusterfs 192.168.1.54:/nas /gluster/data (集群NAS使用)(2) 安装软件
yum install samba (安装samba服务以及工具包)
yum install nfs-utils (安装nfs工具包,服务已集成于内核中)
yum install ctdb (安装CTDB软件包)(3) 配置Samba
smb.conf文件默认位于/etc/samba/smb.conf,我们把smb.conf放在CTDB lock卷上,并为所有节点建立符号链接至/etc/samba/smb.conf。
ln -s /glsuter/lock/smb.conf /etc/samba/smb.conf
smb.conf配置内容如下:
[global]
workgroup = MYGROUP
server string = Samba Server Version %v
log file = /var/log/samba/log.%m
clustering = yes
idmap backend = tdb2
private dir = /gluster/lock
fileid:mapping = fsid
use mmap = no
nt acl support = yes
ea support = yes
security = user
passdb backend = tdbsam
[public]
comment = CTDB NAS
path = /gluster/data
public = yes
writable = yes (4) 配置NFS
同样将/etc/sysconfig/nfs和/etc/export存放在CTDB lock卷上,并为所有节点建立符号链接。
ln -s /gluster/lock/nfs /etc/sysconfig/nfs
ln -s /gluster/lock/export /etc/export
nfs配置内容如下:
CTDB_MANAGES_NFS=yes
NFS_TICKLE_SHARED_DIRECTORY=/gluster/lock/nfs-tickles
STATD_PORT=595
STATD_OUTGOING_PORT=596
MOUNTD_PORT=597
RQUOTAD_PORT=598
LOCKD_UDPPORT=599
LOCKD_TCPPORT=599
STATD_SHARED_DIRECTORY=/gluster/lock/nfs-state
NFS_HOSTNAME="ctdb"
STATD_HOSTNAME="$NFS_HOSTNAME -P "$STATD_SHARED_DIRECTORY/$PUBLIC_IP" -H /etc/ctdb/statd-callout -p 97"
RPCNFSDARGS="-N 4"export配置内容如下:
/gluster/data *(rw,fsid=1235)(5) 配置CTDB
同样将/etc/sysconfig/ctdb, /etc/ctdb/public_addresses, /etc/ctdb/nodes存放于CTDB lock卷上,并为所有节点建立符号链接。
ln -s /gluster/lock/ctdb /etc/sysconfig/ctdb
ln -s /gluster/lock/public_addresses /etc/ctdb/public_addresses
ln -s /glsuter/lock/nodes /etc/ctdb/nodes
ctdb配置内容如下:
CTDB_RECOVERY_LOCK=/gluster/lock/lockfile
CTDB_PUBLIC_INTERFACE=eth0
CTDB_PUBLIC_ADDRESSES=/etc/ctdb/public_addresses
#CTDB_LVS_PUBLIC_IP=192.168.1.50 (这里启用LVS single IP不成功,后面单独配置LVS进行负载均衡)
CTDB_MANAGES_SAMBA=yes
CTDB_MANAGES_WINBIND=yes
CTDB_MANAGES_NFS=yes
CTDB_NODES=/etc/ctdb/nodes
CTDB_DEBUGLEVEL=ERRpublic_addresses配置内容如下:
192.168.1.51/24 eth0
192.168.1.52/24 eth0
192.168.1.53/24 eth0nodes配置内容如下:
192.168.1.54
192.168.1.55
192.168.1.56(6) 启动服务并查看状态
chkconfig ctdb on
chkconfig smb off (CTDB自动管理smb服务)
chkconfig nfs off (CTDB自动管理nfs服务)
/etc/init.d/ctdb start
ctdb status
ctdb ip
ctdb ping -n all(7) 访问测试
Windows CIFS访问:
\\192.168.1.51\public
\\192.168.1.52\public
\\192.168.1.53\public
Linux NFS/CIFS访问:
mount -t nfs 192.168.1.51:/gluster/data /mnt/
mount -t nfs 192.168.1.52:/gluster/data /mnt/
mount -t nfs 192.168.1.53:/gluster/data /mnt/
mount -t cifs //192.168.1.51/public /mnt -o username=xxx (xxx为使用smbpasswd创建的用户)
mount -t cifs //192.168.1.52/public /mnt -o username=xxx
mount -t cifs //192.168.1.51/public /mnt -o username=xxx自动负载均衡集群NAS
上面我们已经成功构建了高可用集群NAS,所有NAS机头均可对外提供NAS服务,并且相互之间具备高可用的特性。如果按照上面的配置实施,则用户可以用通过192.168.1.51, 192.168.1.52, 192.168.153三个IP使用NFS/CIFS来访问集群NAS,访问时需要指定IP。显而易见,这个高可用集群NAS不具备自动负载均衡(load balance)的功能,很容易导致集群NAS机头负载不均衡的情况发生,这对大规模高并发访问或数据密集型应用是非常不利的。
负载均衡最为常用的一种方法是RR-DNS,它为同一个主机名配置多个IP地址,在应答DNS查询时根据Round Robin算法返回不同的IP地址,客户端使用返回的IP连接主机,从而实现负载均衡的目的。RR-DNS负载均衡方法的优点是简单、灵活、方便、成本低,客户端和服务端都不要作修改(除配置DNS信息之外),而且集群节点可以跨WAN。RR-DNS的问题是无法感知集群节点负载状态并进行调度,对故障节点也会进行调度,可能造成额外的网络负载,不够均衡,容错反应时间长。另外一种最为常用的负载均衡技术是 LVS(Linux Virtual Server),它由章文嵩博士开创的开源项目,广泛被业界推崇和使用。LVS是一种高效的Layer-4交换机,提供Linux平台下的集群负载平衡功能,它为物理集群构建一个高扩展和高可用的虚拟服务器,以单一IP代表整个集群对外提供服务。相对于RR-DNS,LVS可以有效弥补其不足之外,配置稍显复杂。LVS主要有三种工作模式,即 VS-NAT, VS-TUN, VS-DR。VS-NAT模式,集群中的物理服务器可以使用任何支持TCP/IP操作系统,物理服务器可以分配Internet的保留私有地址,只有负载均衡器需要一个合法的IP地址。缺点是扩展性有限,当服务器节点数据增长到20个以上时,负载均衡器将成为整个系统的瓶颈,因为所有的请求包和应答包都需要经过负载均衡器再生;VS-TUN模式,负载均衡器只负责将请求包分发给物理服务器,而物理服务器将应答包直接发给用户。所以负载均衡器能处理很巨大的请求量,负载均衡器不再是系统的瓶颈。 这种方式的不足是,需要所有的服务器支持"IP Tunneling"协议;VS-DR模式,和VS-TUN相同,负载均衡器也只是分发请求,应答包通过单独的路由方法返回给客户端。与VS-TUN相比,VS-DR这种实现方式不需要隧道结构,因此可以使用大多数操作系统做为物理服务器。它的不足是,要求负载均衡器的网卡必须与集群物理网卡在一个物理段上。
图4 LVS DR工作模式系统架构
这里采用LVS DR工作模式构建自动负载均衡集群NAS,安装配置详细过程如下:
(1) 安装软件
modprobe -l|grep ipvs (验证系统是否支持LVS/IPVS)
yum install ipvsadm(2) 配置LVS master
编写shell脚本lvsmaster.sh,并在master节点上运行,其配置内容如下:
#!/bin/sh
VIP=192.168.1.50
RIP1=192.168.1.51
RIP2=192.168.1.52
RIP3=192.168.1.53
PORT=0
. /etc/rc.d/init.d/functions
case "$1" in
start)
echo "start LVS of DirectorServer"
#Set the Virtual IP Address
/sbin/ifconfig eth0:1 $VIP broadcast $VIP netmask 255.255.255.255 up
/sbin/route add -host $VIP dev eth0:1
#Clear IPVS Table
/sbin/ipvsadm -C
#Set Lvs
/sbin/ipvsadm -A -t $VIP:$PORT -s rr -p 60
/sbin/ipvsadm -a -t $VIP:$PORT -r $RIP1:$PORT -g
/sbin/ipvsadm -a -t $VIP:$PORT -r $RIP2:$PORT -g
/sbin/ipvsadm -a -t $VIP:$PORT -r $RIP3:$PORT -g
#Run Lvs
/sbin/ipvsadm
;;
stop)
echo "close LVS Directorserver"
/sbin/ipvsadm -C
/sbin/ifconfig eth0:1 down
;;
*)
echo "Usage: $0 {start|stop}"
exit 1
esac(3) 配置LVS realserver
编写shell脚本lvsrealserver.sh,并在所有集群节点上运行,这里master节点同时也是real server节点。其配置内容如下:
#!/bin/bash
VIP=192.168.1.50
BROADCAST=192.168.1.255 #vip's broadcast
. /etc/rc.d/init.d/functions
case "$1" in
start)
echo "reparing for Real Server"
echo "1" >/proc/sys/net/ipv4/conf/lo/arp_ignore
echo "2" >/proc/sys/net/ipv4/conf/lo/arp_announce
echo "1" >/proc/sys/net/ipv4/conf/all/arp_ignore
echo "2" >/proc/sys/net/ipv4/conf/all/arp_announce
ifconfig lo:0 $VIP netmask 255.255.255.255 broadcast $BROADCAST up
/sbin/route add -host $VIP dev lo:0
;;
stop)
ifconfig lo:0 down
echo "0" >/proc/sys/net/ipv4/conf/lo/arp_ignore
echo "0" >/proc/sys/net/ipv4/conf/lo/arp_announce
echo "0" >/proc/sys/net/ipv4/conf/all/arp_ignore
echo "0" >/proc/sys/net/ipv4/conf/all/arp_announce
;;
*)
echo "Usage: lvs {start|stop}"
exit 1
esac(4) 系统测试
ipvsadm -Ln
\\192.168.1.50\public (Windows平台CIFS访问)
mount -t nfs 192.168.1.53:/gluster/data /mnt/ (Linux平台NFS访问)
mount -t cifs //192.168.1.51/public /mnt -o username=xxx (Linux平台CIFS访问)以上构建的LVS具有单点故障问题,如果需要构建高可用LVS,请参考以下URL进行配置:
(1) piranha方案, http://www.linuxvirtualserver.org/docs/ha/piranha.html
(2) ldirectord方案, http://www.linuxvirtualserver.org/docs/ha/heartbeat_ldirectord.html















 70
70

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









