







-
Hive的架构和工作原理简介
Hive 是基于Hadoop之上的数仓,便于用户可以基于SQL(Hive QL)进行数据分析,其架构图如下:
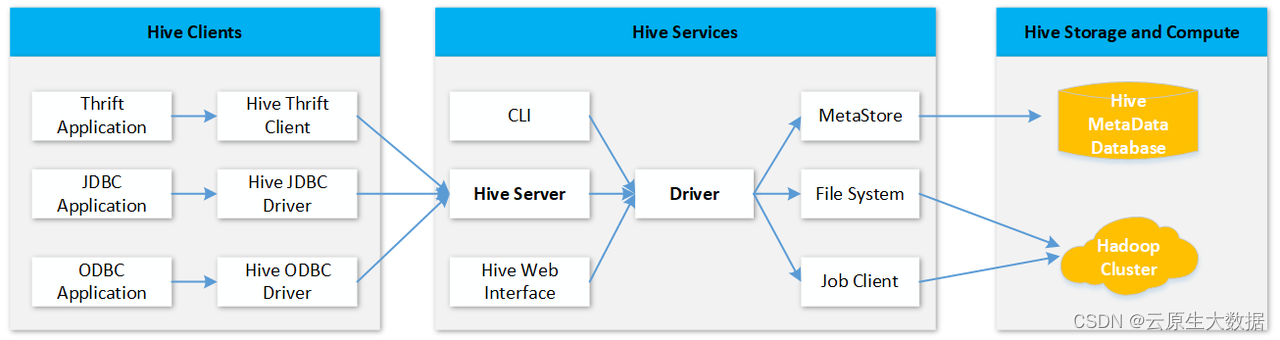
从上图可知,Hive主要用来将建立结构化数据库和后端分布式结构化文件的映射,以及把SQL语句转换为MapReduce(tez或spark)任务,以便进行分布式查询分析。
具体分布式文件的存储、分布式计算的执行等均由后端的Hadoop来承接,如下图所示:
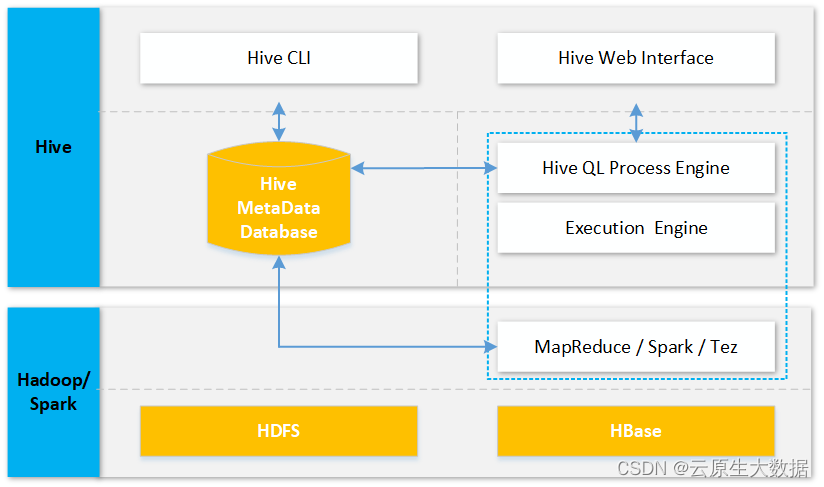
基于上图架构,Hive迁移主要包含两部分:Hive 元数据以及存储在HDFS/HBase上的文件数据,同时由于新Hive版本升级还需调整元数据以适应新版本。
方案一:Upgrade SQL方式
Hive元数据迁移方案
HIve元数据用来存储hive 关系型数据库和HDFS的映射关系,生产HIve元数据一般选择存储在MySQL中,元数据迁移即迁移存储在MySql中的hivemetastore库,操作步骤如下:
Dump 源 Hive 元数据库
# dumpmysql 库
mysqldump -hX.X.X.X -uroot -pXXXX --single-transaction --set-gtid-purged=OFF hivemetastore > hivemetastore-src.sql
# 如果 mysql 数据没有开启 GTID,请删除命令行中的 --set-gtid-purged=OFF
# X.X.X.X为数据库服务器地址
# XXXX为数据库密码
# 如果数据库用户不是 root,请用正确的用户名
# hivemetastore 是 Hive 元数据库名 -
确认目标 Hive 表数据在 HDFS 中的路径
Hive 表数据在 HDFS 中的缺省路径由 hive-site.xml 中的 hive.metastore.warehouse.dir 指定。如果 Hive 表在 HDFS 的存储位置依然保持与源 Hive 一致,那么需要修改目标Hive配置项 hive.metastore.warehouse.dir与源 Hive 数据库中的值一致。例如,源 hive-site.xml 中 hive.metastore.warehouse.dir 为下面的值:
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/apps/hive/warehouse</value>
</property>目标 hive-site.xml与源hive-site.xml保持一致。
确认目标 Hive 元数据 SDS.LOCATION 和 DBS.DB_LOCATION_URI 字段
查询获取当前元数据库中 SDS.LOCATION 和 DBS.DB_LOCATION_URI 字段:
SELECT DB_LOCATION_URI from DBS;
SELECT LOCATION from SDS;
# 结果如下
mysql> SELECT LOCATION from SDS;
+--------------------------------------------------+
| LOCATION |
+--------------------------------------------------+
| hdfs://hdfs-ha/usr/hive/warehouse/hitest.db/t1 |
| hdfs://hdfs-ha/usr/hive/warehouse/test2 |
+--------------------------------------------------+
mysql> SELECT DB_LOCATION_URI from DBS;
+-----------------------------------------------+
| DB_LOCATION_URI |
+-----------------------------------------------+
| hdfs://hdfs-ha/usr/hive/warehouse |
| hdfs://hdfs-ha/usr/hive/warehouse/hitest.db |
+-----------------------------------------------+
其中 hdfs://hdfs-ha 是 HDFS 默认文件系统名,由 core-site.xml 中的 fs.defaultFS 指定,
<property>
<name>fs.defaultFS</name>
<value>hdfs://hdfs-ha</value>
</property> /usr/hive/warehouse为 Hive 表在 HDFS 中的默认存储路径,也是 hive-site.xml 中 hive.metastore.warehouse.dir 指定的值。所以我们需要修改源 hive 元数据 sql 文件中的 SDS.LOCATION 和 DBS.DB_LOCATION_URI 两个字段。确保被导入的 Hive 元数据库中的这两个字段使用的是正确的路径。可使用如下 sed 命令批量修改 sql 文件。
# 替换defaultFS:
sed -i 's/old-defaultFS/new-defaultFS/g' hivemetastore-src.sql
# 替换ip,一般用不到,除非有关联的外部表 :
sed -i 's/oldcluster-ip:4007/newcluster-ip:4007/g' hivemetastore-src.sql-
停止目标 Hive 服务 MetaStore、HiveServer2、WebHcataLog
在目标集群管理平台,停止hive组件所有服务。
-
备份目标 Hive 元数据库
# 备份目标hive元数据库
mysqldump -hX.X.X.X -uroot -pXXXX --single-transaction --set-gtid-purged=OFF hivemetastore > hivemetastore-target.sql
# 如果 mysql 数据没有开启 GTID,请删除命令行中的 --set-gtid-purged=OFF
# X.X.X.X为数据库服务器地址
# XXXX为数据库密码
# 如果数据库用户不是 root,请用正确的用户名
# hivemetastor 是 Hive 元数据库名-
Drop/Create 目标 Hive 元数据
mysql> drop database hivemetastore;
mysql> create database hivemetastore; -
导入源 Hive 元数据库到目标数据库
mysql -hX.X.X.X -uroot -pXXXX hivemetastore < hivemetastore-src.sql
# X.X.X.X为数据库服务器地址
# XXXX为数据库密码
# 如果数据库用户不是 root,请用正确的用户名
# hivemetastor 是 hive 元数据库名至此Hive元数据迁移已完成,如果源Hive和目标Hive版本可直接启动目标 Hive 服务 MetaStore、HiveServer2。
如果源Hive和目标Hive版本不一致还需要使用以下Hive元数据升级方案,升级Hive元数据以兼容新版本Hive。
-
Hive元数据升级方案
分别在源集群和目标集群查询 Hive 版本,确定两端版本号:
hive --service version
Hive官方提供metastore升级,官方升级脚本和升级规则如下:
[root@hadoop]# pwd
/data/hive/1/hive-3.1.0/scripts/metastore/upgrade
[root@hadoop upgrade]# cat mysql/upgrade.order.mysql
0.5.0-to-0.6.0
0.6.0-to-0.7.0
0.7.0-to-0.8.0
0.8.0-to-0.9.0
0.9.0-to-0.10.0
0.10.0-to-0.11.0
0.11.0-to-0.12.0
0.12.0-to-0.13.0
0.13.0-to-0.14.0
0.14.0-to-1.1.0
1.1.0-to-1.2.0
1.2.0-to-2.0.0
2.0.0-to-2.1.0
2.1.0-to-2.2.0
2.2.0-to-2.3.0
2.3.0-to-3.0.0
3.0.0-to-3.1.0
升级脚本存放位置:/data/hive/1/hive-3.1.0/scripts/metastore/upgrade/mysql/
hive 不支持跨版本升级,例如 hive 从1.1.0 升级到 3.1.0需要依次执行:
upgrade-1.1.0-to-1.2.0.mysql.sql ->
upgrade-1.2.0-to-2.0.0.mysql.sql ->
upgrade-2.0.0-to-2.1.0.mysql.sql ->
upgrade-2.1.0-to-2.2.0.mysql.sql ->
upgrade-2.2.0-to-2.3.0.mysql.sql ->
upgrade-2.3.0-to-3.0.0.mysql.sql ->
upgrade-3.0.0-to-3.1.0.mysql.sql升级脚本主要操作为建表、加字段、改内容。如果表或字段已经存在,则升级过程中字段已存在的异常可以忽略。
升级命令如下:
mysql> source /data/hive/1/hive-3.1.0/scripts/metastore/upgrade/mysql/upgrade-1.1.0-to-1.2.0.mysql.sql;
mysql> source /data/hive/1/hive-3.1.0/scripts/metastore/upgrade/mysql/upgrade-1.2.0-to-2.0.0.mysql.sql;启动目标 Hive 服务 MetaStore、HiveServer2。
最后可通过 Hive sql 查询进行验证。
-
语法兼容性
版本升级可能会遇到保留字和function兼容性问题问题,下面总结升级过程中可能遇到的一些语法兼容性问题:
-
Hive新增保留字问题
Hive随着版本变迁,保留字越来越多。 保留字的详细情况可以参考:Hive各个版本的保留字链接:
https://cwiki.apache.org/confluence/display/Hive/LanguageManual+DDL#LanguageManualDDL-Keywords,Non-reservedKeywordsandReservedKeywords
新版本Hive会预留更多保留字,如果SQL用到产生语法问题,在hive 2.1.0 和之前版本可以通过参数设置set hive.support.sql11.reserved.keywords=false来取消保留字校验, 达到不需要修改SQL,又能保证线上SQL稳定运行的兼容效果。
当SQL中含有跨版本之间(hive 2.1.0 -> hive 3.1.0)的新增的关键字时候,只能修改SQL进行兼容了,需要将与关键字冲突的属性名用反引号包围。 新版本增加的关键字有:OFFSET、SUBQUERY、REWRITE、PRIMARY、FOREIGN、KEY、 REFERENCES、CONSTRAINT等。
-
Function兼容性
Hive函数手册链接:
https://cwiki.apache.org/confluence/display/Hive/LanguageManual+UDF#LanguageManualUDF-DateFunctions
和Hive 1.1.0相关变动的函数有5处,用到以下function的HSQL需要注意(某些是hive1.1.0新添加的,可忽略):
-
T greatest(T v1, T v2, ...) - 在hive2.0.0修复了返回NULL的bug
-
T least(T v1, T v2, ...) - 在hive2.0.0修复了返回NULL的bug
-
string add_months(string start_date, int num_months, output_date_format) - 从hive1.1.0开始参数规则有所变化
-
string last_day(string date) - 从hive1.1.0开始使用
-
string initcap(string A) - 从hive1.1.0开始使用
方案二:New Create Table方式
通过脚本获得所有的建表语句,然后直接在高版本的hive中执行相应的建表语句,然后数据导入之后, 使用 msck repair table 修复分区信息。
注意:但是如果批量修复元数据,有可能分区太多导致OOM,可以设置下批次,比如:set hive.msck.repair.batch.size=5000;
源Hive集群获取table的脚本样例如下:
#!/bin/bash
#查询获得所有databases
databases=`hive -S -e "show databases;"`
echo $databases
array=(${databases// / })
#循环传入database
for database in ${array[@]}
do
#获取该库下所有tables
tablenames=`hive -S -e "use $database; show tables;"`
table_array=(${tablenames// / })
#删除该库历史建表语句
rm -rf ${database}.txt
#循环传入table
for tablename in ${table_array[@]}
do
create_table=`hive -S -e "use $database; show create table $tablename;"`";"
echo -e $create_table >> ${database}.txt
echo -e '\n' >> ${database}.txt
done
done然后在目标Hive集群执行${database}.txt所在库的建表语句。
最后修复分区信息
msck repair table 















 1140
1140











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









