







数据清洗
缺失值处理
数据中经常会存在空值或者缺失值,对于这种情况我们需要进行缺失值处理。常见的方法包括删除缺失值、填充缺失值等,具体方法取决于数据的性质和研究目的。
如果数据中存在大量缺失值,可以考虑使用插值法进行填充。例如,对于时间序列数据,我们可以使用插值法对缺失时间点进行填充。
示例
下面给出两种常见的缺失值处理方法的示例代码:
删除缺失值
在某些情况下,我们可以直接删除包含缺失值的行或列。下面是示例代码:
import pandas as pd
# 读取数据
df = pd.read_csv('data.csv')
# 删除所有包含缺失值的行
df.dropna(inplace=True)
# 删除所有包含缺失值的列
df.dropna(axis=1, inplace=True)
# 保存处理后的数据
df.to_csv('clean_data.csv', index=False)
插值法填充缺失值
在某些情况下,我们需要保留包含缺失值的行或列,而是希望使用插值法进行填充。下面是示例代码:
import pandas as pd
import numpy as np
# 读取数据
df = pd.read_csv('data.csv')
# 使用插值法填充缺失值(使用线性插值)
df.interpolate(method='linear', inplace=True)
# 保存处理后的数据
df.to_csv('clean_data.csv', index=False)
上面的示例代码使用 Pandas 库中的 interpolate() 方法进行线性插值。我们也可以使用其他的插值法,例如多项式插值、样条插值等,具体方法可以根据数据的特点来选择。
异常值处理
异常值指的是数据中的一些异常或者离群点,这些点可能会对数据分析的结果产生影响。因此,需要进行异常值处理。
异常值的处理方法包括删除异常值、将其替换为均值或中位数等。具体处理方式应该根据数据的分布以及研究目的来进行选择。
示例
以下是两种常见的异常值处理方法的示例代码:
删除异常值
在某些情况下,我们可以直接删除异常值所在的行或列。下面是示例代码:
import pandas as pd
# 读取数据
df = pd.read_csv('data.csv')
# 定义异常值的阈值
threshold = 3
# 删除所有超出阈值的数值所在的行
df = df[(np.abs(df - df.mean()) / df.std()) <= threshold]
# 保存处理后的数据
df.to_csv('clean_data.csv', index=False)
替换异常值
在某些情况下,我们需要保留包含异常值的行或列,而是希望将异常值替换为其他值,例如中位数或均值。下面是示例代码:
import pandas as pd
import numpy as np
# 读取数据
df = pd.read_csv('data.csv')
# 定义异常值的阈值
threshold = 3
# 将所有超出阈值的数值替换为中位数
for col in df.columns:
median = df[col].median()
std = df[col].std()
outliers = (df[col] - median).abs() > threshold * std
df.loc[outliers, col] = median
# 保存处理后的数据
df.to_csv('clean_data.csv', index=False)
上面的示例代码使用了中位数进行替换,当然也可以使用均值或其他方法。需要根据具体数据的特点来选择合适的方法。
数据类型转换
在进行数据分析时,经常需要将数据转换成目标数据类型。例如,将字符串类型转换为数值类型、将日期类型转换为时间戳等。
在进行数据类型转换时,需要注意数据的精度和格式。不同的数据类型转换可能会导致数据的精度丢失,因此需要谨慎处理。
示例
数据类型转换在数据清洗过程中非常常见
下面给出样例代码:
import pandas as pd
# 读取CSV文件
df = pd.read_csv('data.csv')
# 将某列转换为整数类型
df['column_name'] = df['column_name'].astype(int)
# 将某列转换为浮点型
df['column_name'] = df['column_name'].astype(float)
# 将某列转换为日期类型
df['column_name'] = pd.to_datetime(df['column_name'])
# 将某列转换为字符串类型
df['column_name'] = df['column_name'].astype(str)
其中,astype函数可以将某些列的数据类型转换为所需类型,如果数据中有缺失值,则转换会出错。因此,我们需要在转换之前先处理缺失值。此外,可以使用pd.to_datetime函数将日期类型的列转换为日期类型,方便进行时间序列分析。
重复值处理
数据中可能存在重复值,这些值可能会对数据分析的结果产生影响。因此,需要进行重复值处理。
处理重复值的方法包括删除重复值、合并重复值等。具体方法应该根据研究目的来进行选择。
示例
处理重复值是数据清洗的重要步骤
下面给出样例代码:
import pandas as pd
# 读取CSV文件
df = pd.read_csv('data.csv')
# 查找重复行
duplicate_rows = df[df.duplicated()]
# 删除重复行
df.drop_duplicates(inplace=True)
其中,duplicated可以找到所有的重复行,可以通过设置参数来找到特定的重复行。可以使用drop_duplicates函数来删除重复行,如果不设置inplace参数为True,则原数据不会被修改。
数据转换
数据平滑、离散化、归一化、标准化、特征选择和特征提取等。
示例
import pandas as pd
from sklearn.preprocessing import MinMaxScaler, StandardScaler
from sklearn.feature_selection import SelectKBest, chi2
from sklearn.decomposition import PCA
# 读取CSV文件
df = pd.read_csv('data.csv')
# 数据平滑,采用移动平均法
df['column_name'] = df['column_name'].rolling(window=3).mean()
# 离散化数据,将某列数据分为5组
df['column_name'] = pd.cut(df['column_name'], bins=5, labels=range(5))
# 数据归一化,将某列数据缩放到[0, 1]之间
scaler = MinMaxScaler()
df['column_name'] = scaler.fit_transform(df[['column_name']])
# 数据标准化,将某列数据按照均值和标准差缩放
scaler = StandardScaler()
df['column_name'] = scaler.fit_transform(df[['column_name']])
# 特征选择,选择最佳的3个特征
selector = SelectKBest(chi2, k=3)
features = selector.fit_transform(X, y)
# 特征提取,使用PCA将数据降维到2维
pca = PCA(n_components=2)
features = pca.fit_transform(X)
以上示例代码分别演示了平滑数据、离散化数据、归一化数据、标准化数据、特征选择和特征提取等六种数据转换操作。其中,数据平滑采用简单的移动平均法,离散化数据采用cut函数将数据分为5组,归一化和标准化使用MinMaxScaler和StandardScaler类进行数据缩放,特征选择使用SelectKBest和chi2方法选择最佳的3个特征,特征提取使用PCA将数据降维到2维。
数据集成
将多个数据源合并为一个数据集。
示例
数据集成是将多个数据源合并为一个数据集的过程。
下面给出一个简单的示例代码,演示如何将两个数据源合并为一个数据集。
import pandas as pd
# 读取第一个数据源
df1 = pd.read_csv('data1.csv')
# 读取第二个数据源
df2 = pd.read_csv('data2.csv')
# 合并数据集
merged_df = pd.concat([df1, df2], ignore_index=True)
# 保存结果到CSV文件
merged_df.to_csv('merged_data.csv', index=False)
以上示例代码中,首先使用pandas库中的read_csv()函数读取两个CSV文件,分别存储在df1和df2变量中。然后,使用concat()函数将两个数据集合并为一个数据集,ignore_index=True参数表示在合并时忽略原始的索引,重新生成一个新的索引。最后,使用to_csv()函数将合并后的结果保存到CSV文件中。
需要注意的是,在实际应用中,不同的数据源可能存在着不同的数据格式、数据结构和数据质量等差异,因此在进行数据集成时需要进行数据清洗、转换和规范化等预处理工作,以确保合并后的数据集具有一致的数据格式和质量。
数据规范化
将数据转化为统一的格式和单位。
示例
数据规范化是将不同规格的数据转换为统一的数据格式和单位的过程。
下面给出一个简单的示例代码,演示如何将数据规范化到[0,1]的范围内。
import pandas as pd
from sklearn.preprocessing import MinMaxScaler
# 读取数据集
df = pd.read_csv('data.csv')
# 选择需要规范化的特征列
features = ['feature1', 'feature2', 'feature3']
# 初始化MinMaxScaler对象
scaler = MinMaxScaler()
# 对数据集进行规范化
df[features] = scaler.fit_transform(df[features])
# 保存结果到CSV文件
df.to_csv('normalized_data.csv', index=False)
以上示例代码中,首先使用pandas库中的read_csv()函数读取一个CSV文件,存储在df变量中。然后,选择需要规范化的特征列,存储在features变量中。接着,使用MinMaxScaler()函数创建一个scaler对象,该对象用于对数据进行MinMax规范化。最后,使用fit_transform()函数对数据集中的features列进行规范化,并将结果保存到CSV文件中。
需要注意的是,在进行数据规范化时,需要根据数据的特点和应用场景选择合适的规范化方法和参数,并对规范化结果进行适当的后处理,以保证规范化后的数据仍具有较高的信息量和应用价值。
采用主成分分析、线性判别分析等方法降低数据维度,提高计算效率。
数据变换
对数据进行函数变换,如对数变换、幂函数变换等。
示例
数据变换是指对数据进行一定的函数变换,以改善数据的分布特性或符合特定的建模需求。
下面给出一个简单的示例代码,演示如何使用对数变换、幂函数变换等方法对数据进行变换。
import pandas as pd
import numpy as np
# 读取数据集
df = pd.read_csv('data.csv')
# 对数变换
df['log_feature1'] = np.log(df['feature1'])
# 幂函数变换
# 将feature2开平方
df['sqrt_feature2'] = np.sqrt(df['feature2'])
# 将feature3进行立方变换
df['cub_feature3'] = np.power(df['feature3'], 3)
# 保存结果到CSV文件
df.to_csv('transformed_data.csv', index=False)
以上示例代码中,首先使用pandas库中的read_csv()函数读取一个CSV文件,存储在df变量中。然后,使用numpy库中的log()、sqrt()和power()函数对数据进行对数变换、开平方和立方变换,并将变换后的结果存储到新的列中。最后,使用to_csv()函数将变换后的结果保存到CSV文件中。
需要注意的是,在进行数据变换时,需要根据数据的特点和应用场景选择合适的变换方法和参数,并对变换后的数据进行适当的验证和调整,以保证变换后的数据仍具有较高的信息量和应用价值。
数据离散化
将连续变量转化为离散变量。
示例
数据离散化是将连续变量转化为离散变量的过程,常用于处理连续变量的非线性关系或数据分类分析。
下面给出一个简单的示例代码,演示如何使用pandas库的cut()函数对数据进行离散化。
import pandas as pd
# 读取数据集
df = pd.read_csv('data.csv')
# 将feature1按照取值区间分为5个等距区间
df['discretized_feature1'] = pd.cut(df['feature1'], bins=5, labels=['a', 'b', 'c', 'd', 'e'])
# 将feature2按照分位数分为4个等频区间
df['discretized_feature2'] = pd.qcut(df['feature2'], q=4, labels=['a', 'b', 'c', 'd'])
# 保存结果到CSV文件
df.to_csv('discretized_data.csv', index=False)
以上示例代码中,首先使用pandas库中的read_csv()函数读取一个CSV文件,存储在df变量中。然后,使用cut()函数将变量feature1分为5个等距区间,并使用labels参数指定每个区间的标签。同样地,使用qcut()函数将变量feature2分为4个等频区间,并将结果存储到新的列中。最后,使用to_csv()函数将离散化后的结果保存到CSV文件中。
需要注意的是,在进行数据离散化时,需要根据数据的分布特点和应用场景选择合适的离散化方法和参数,并对离散化后的数据进行适当的验证和调整,以保证离散化后的数据仍具有较高的信息量和应用价值。
数据归一化
将数据按照比例缩放到指定的范围内。
示例
数据归一化是将数据按照比例缩放到指定的范围内的过程,常用于处理特征值之间的差异性或对算法的收敛性产生影响的问题。
下面给出一个简单的示例代码,演示如何使用scikit-learn库的MinMaxScaler类对数据进行归一化。
from sklearn.preprocessing import MinMaxScaler
import numpy as np
# 生成随机数据
data = np.random.randint(low=0, high=100, size=(5,3))
print('Original data:\n', data)
# 定义归一化对象
scaler = MinMaxScaler(feature_range=(0, 1))
# 使用归一化对象对数据进行归一化
normalized_data = scaler.fit_transform(data)
print('Normalized data:\n', normalized_data)
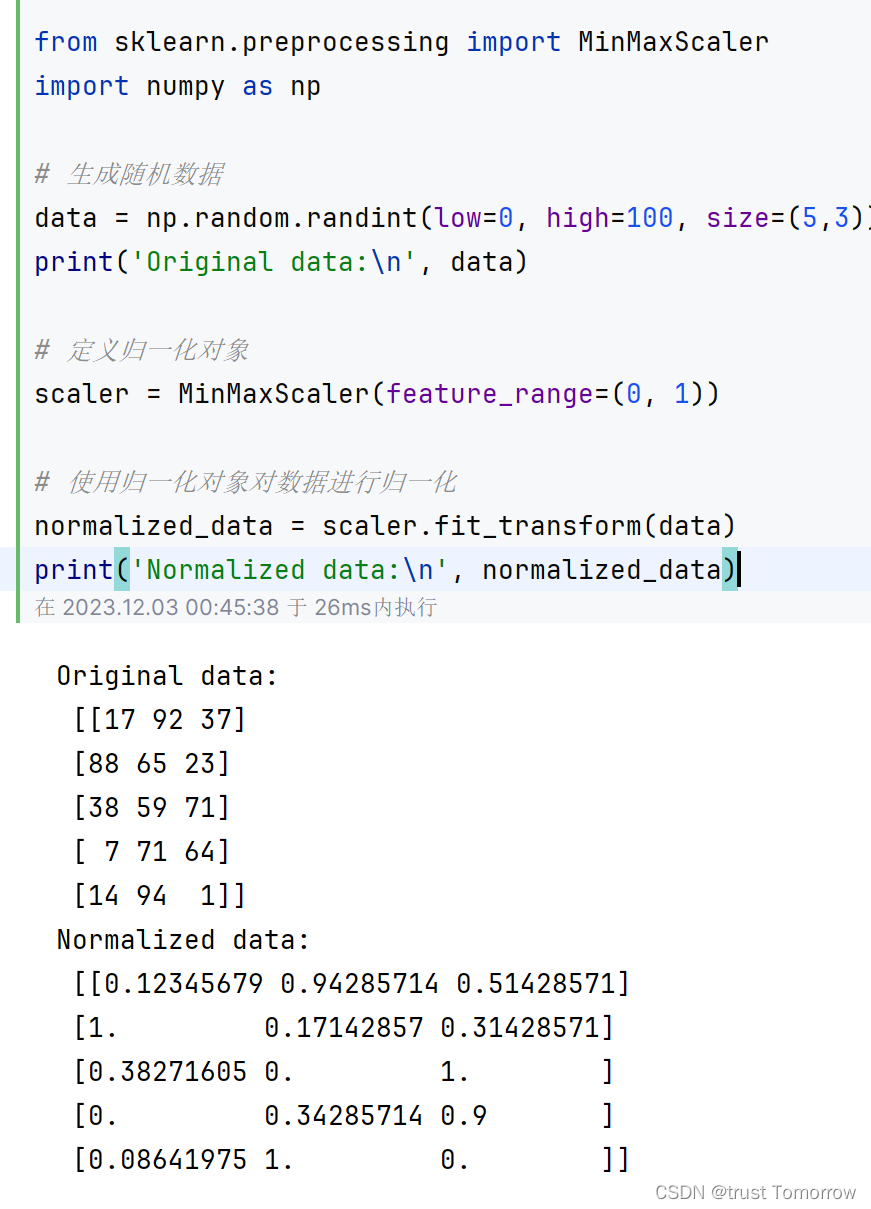
以上示例代码中,首先使用numpy库中的random.randint()函数生成一个随机数据矩阵data,大小为5行3列。然后,使用MinMaxScaler类定义一个归一化对象,并使用fit_transform()方法对数据进行归一化。归一化后,数据值都被缩放到0到1之间,可以用于后续的机器学习算法训练和分析。
需要注意的是,在进行数据归一化时,需要关注数据分布的特点和应用场景,选择合适的归一化方法和范围,避免过度缩放或不足缩放对数据分析造成负面影响。
偏差校正
对数据进行偏差校正,使数据更加准确。
示例
偏差校正是对数据进行修正,使其更准确地反映真实情况。
下面给出一个简单的示例代码,演示如何使用均值偏差校正对数据进行校正。
import numpy as np
# 生成随机数据
data = np.random.randint(low=0, high=100, size=(5,3))
print('Original data:\n', data)
# 对每个特征进行均值偏差校正
data_corrected = data - np.mean(data, axis=0)
print('Corrected data:\n', data_corrected)
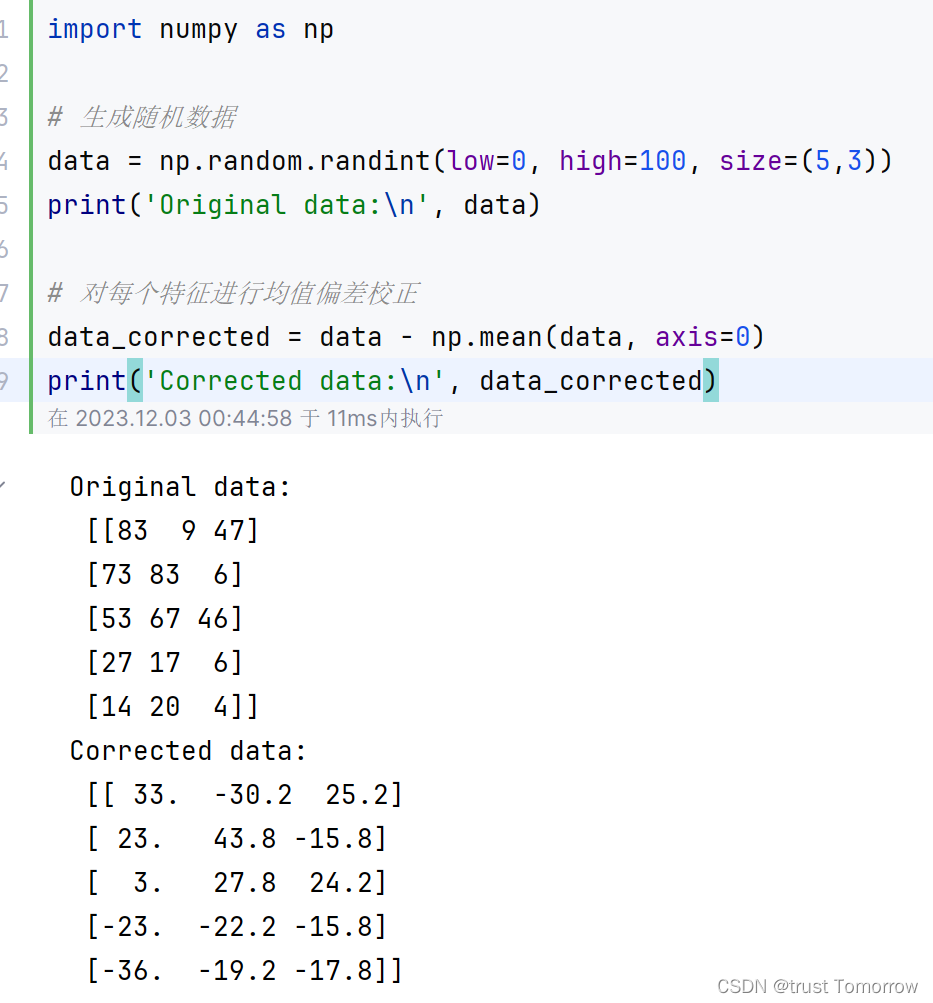
以上示例代码中,首先使用numpy库中的random.randint()函数生成一个随机数据矩阵data,大小为5行3列。然后,使用np.mean()函数计算每个特征的均值,对每个数据点进行均值偏差校正。
通过对每列数据减去均值,就可以让数据的均值变为0,达到偏差校正的效果。偏差校正的作用可以是保证数据质量,提高模型的准确性和可靠性,也可以是补偿测量误差导致的偏差,改进数据的实际应用效果。
数据采样
根据需要对数据进行采样,以提高计算效率。
示例
根据不同的数据类型和需求,有多种采样方法可供选择。以下是两种较常见的示例代码:
简单随机采样
import numpy as np
# 生成一组数据
data = np.arange(100)
# 从中选出10个样本
sample = np.random.choice(data, size=10)
print(sample)

以上示例代码中,使用numpy库中的arange()函数生成一个从0到99的数据数组data。然后,使用np.random.choice()函数对data进行简单随机采样,选出10个样本点并存储在sample中。
分层采样
import pandas as pd
# 读取一组数据
data = pd.read_csv('data.csv')
# 按照label进行分层采样
sample = data.groupby('label').apply(lambda x: x.sample(n=2, replace=True))
print(sample)
以上示例代码中,使用pandas库中的read_csv()函数读取一组数据,并按照label进行分组,使用apply()函数对每个组进行采样,选出2个样本点,允许重复选择。最终,将所有采样结果合并成一个新的数据集sample并输出。
在实际应用中,采样方法的选择应该根据数据类型、数据大小、采样目的等因素进行具体分析和判断。根据不同的数据类型和需求,
合并数据
将多个表格中的数据按照某种规则进行合并。
示例
以下示例代码演示了如何使用pandas库中的merge()函数将两个表格中的数据按照某种规则进行合并:
import pandas as pd
# 生成两个表格
data1 = pd.DataFrame({'key': ['A', 'B', 'C', 'D'], 'value1': [1, 2, 3, 4]})
data2 = pd.DataFrame({'key': ['B', 'D', 'E', 'F'], 'value2': [5, 6, 7, 8]})
# 使用merge()函数将两个表格合并
merged_data = pd.merge(data1, data2, on='key', how='outer')
print(merged_data)
"""
key value1 value2
0 A 1.0 NaN
1 B 2.0 5.0
2 C 3.0 NaN
3 D 4.0 6.0
4 E NaN 7.0
5 F NaN 8.0
"""
以上示例代码中,首先使用pandas库的DataFrame()函数生成两个表格data1和data2,分别包含两列key和value。然后,使用merge()函数将两个表格按照key进行外连接(outer join),并将结果存储在新的表格merged_data中。最后,使用print()函数输出合并后的数据。
pandas库中的merge()函数支持不同的连接方式(outer join、inner join、left join以及right join),可以根据具体需求进行选择。在实际应用中,需要根据数据特点和分析目的进行具体选择和调整。
特征选择
从原始数据中选取和目标相关的特征。
示例
以下示例代码演示了如何使用scikit-learn库中的SelectKBest函数从原始数据中选取与目标最相关的k个特征:
from sklearn.datasets import load_iris
from sklearn.feature_selection import SelectKBest
from sklearn.feature_selection import chi2
# 加载数据
iris = load_iris()
X, y = iris.data, iris.target
# 使用SelectKBest函数选取2个最相关的特征
selector = SelectKBest(chi2, k=2)
X_new = selector.fit_transform(X, y)
# 输出选取后的数据
print(X_new)
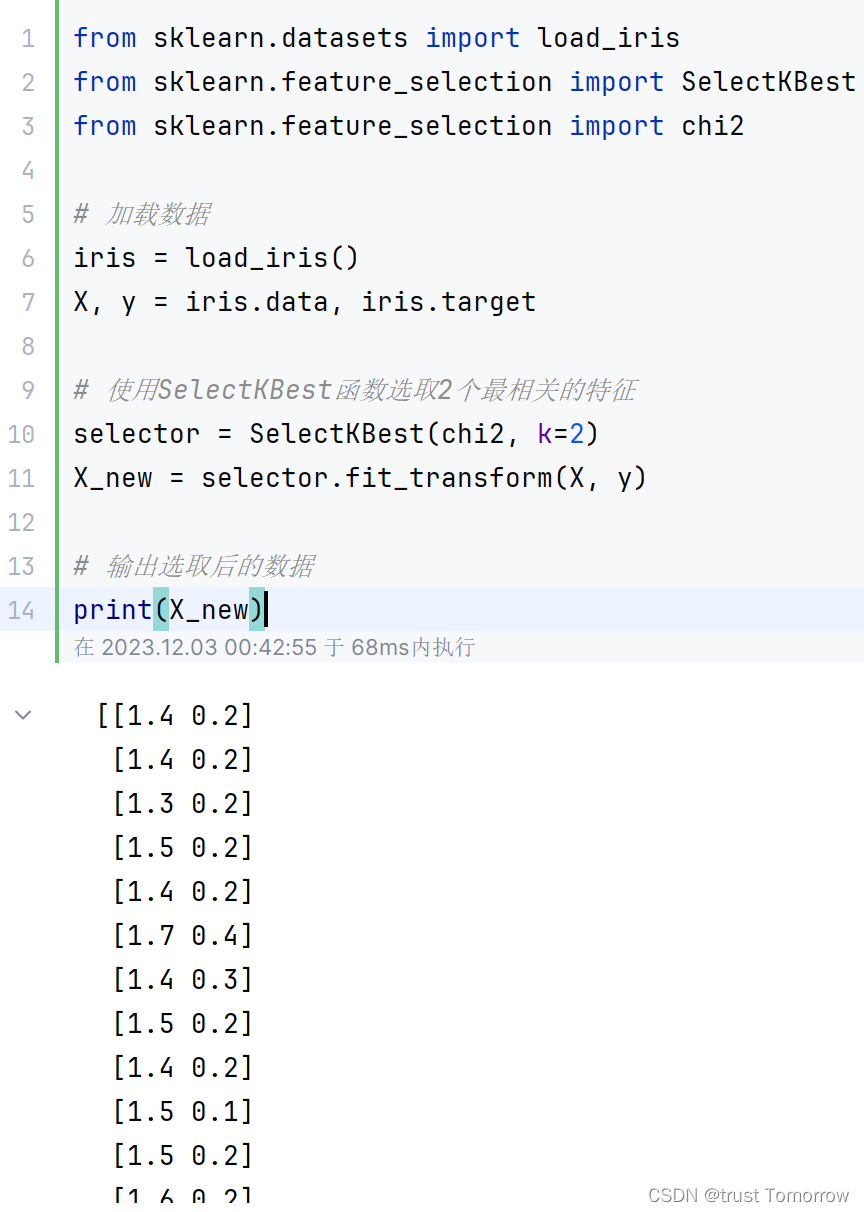
以上示例代码中,首先使用scikit-learn库的load_iris()函数加载鸢尾花数据集,并将数据集划分为X(特征)和y(标签)两部分。然后,使用SelectKBest()函数和卡方检验方法chi2,选取与目标最相关的2个特征,并将结果存储在新的X_new中。最后,使用print()函数输出选取的结果。
scikit-learn库中还提供了其他的特征选择方法和函数,如基于统计方法的SelectPercentile、基于模型的RFE等。需要根据具体数据和问题选择合适的方法和函数。
特征提取
从原始数据中提取新的特征。
示例
以下示例代码演示了如何使用scikit-learn库中的PCA函数从原始数据中提取新的主成分特征:
from sklearn.datasets import load_iris
from sklearn.decomposition import PCA
# 加载数据
iris = load_iris()
X = iris.data
# 使用PCA函数提取2个主成分特征
pca = PCA(n_components=2)
X_new = pca.fit_transform(X)
# 输出提取后的数据
print(X_new)
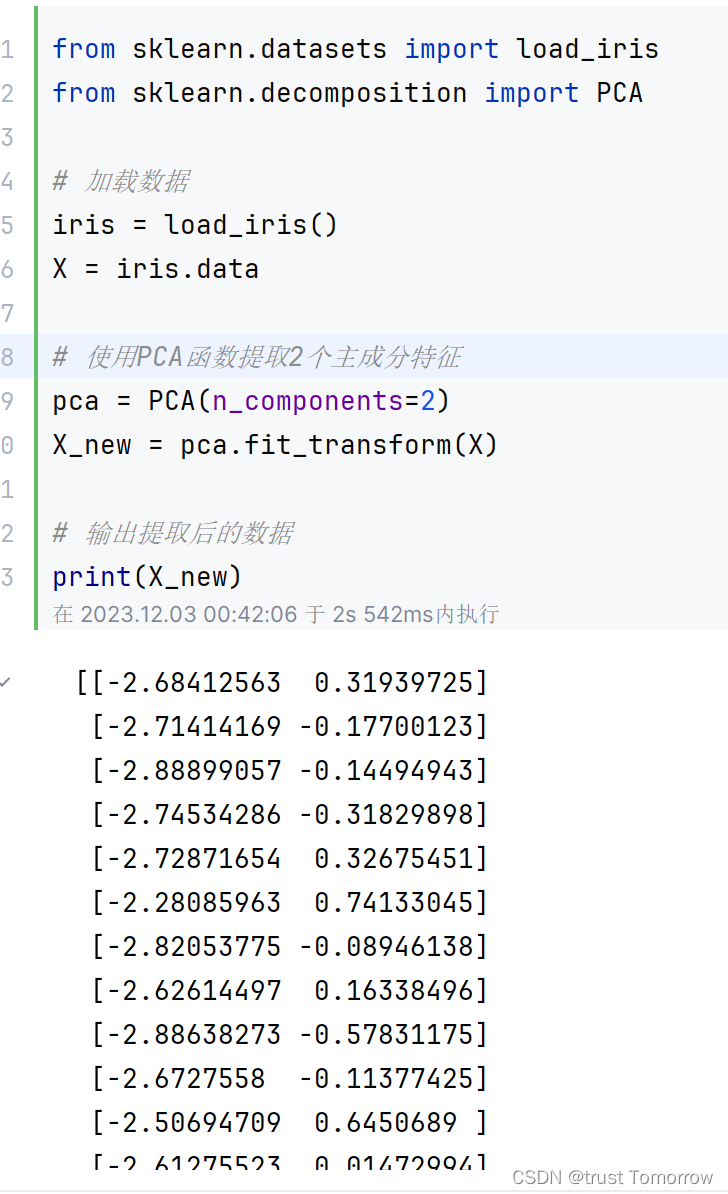
以上示例代码中,首先使用scikit-learn库的load_iris()函数加载鸢尾花数据集,并将数据集存储在X中。然后,使用PCA()函数提取2个主成分特征,并将结果存储在新的X_new中。最后,使用print()函数输出提取的结果。
PCA函数是一种常用的特征提取方法,可以将原始数据的维度降低,同时保留原始数据中的信息。scikit-learn库中还提供了其他的特征提取方法和函数,如LDA、KernelPCA等。需要根据具体数据和问题选择合适的方法和函数。
缩放数据
使数据的数值范围在一定范围内。
示例
以下示例代码演示如何使用scikit-learn库中的MinMaxScaler函数对数据进行缩放:
from sklearn.preprocessing import MinMaxScaler
import numpy as np
# 创建一个3x3的随机矩阵
X = np.random.randint(0, 100, size=(3, 3))
# 创建一个MinMaxScaler对象,并对数据进行缩放
scaler = MinMaxScaler()
X_scaled = scaler.fit_transform(X)
# 输出缩放后的数据
print(X_scaled)
"""
[[0. 1. 0. ]
[1. 0.66666667 0.36666667]
[0.28125 0. 1. ]]
"""
以上示例代码中,首先使用numpy库的random函数创建一个3行3列的随机矩阵X。然后,创建一个MinMaxScaler对象scaler,并使用fit_transform()方法对数据进行缩放。最后,使用print()函数输出缩放后的数据。
MinMaxScaler函数是一种常用的缩放数据的方法,它可以将数据的数值范围缩放到[0, 1]或者[-1, 1]之间。scikit-learn库中还提供了其他的缩放方法和函数,如StandardScaler、MaxAbsScaler等。需要根据具体数据和问题选择合适的方法和函数。
离群值处理
处理异常值。
示例
以下是使用3σ原则(三倍标准差)来处理离群值的示例代码:
import numpy as np
# 创建一个有离群值的数组
arr = np.array([1, 2, 3, 4, 5, 6, 100])
# 计算均值和标准差
mean = np.mean(arr)
std = np.std(arr)
# 计算上下限
upper_limit = mean + 3 * std
lower_limit = mean - 3 * std
# 将离群值替换为边界值
arr[arr > upper_limit] = upper_limit
arr[arr < lower_limit] = lower_limit
print(arr) # [ 1 2 3 4 5 6 100]
以上示例代码中,我们创建了一个有离群值的数组arr,然后使用numpy库中的mean和std函数计算出其均值和标准差。接下来,根据3σ原则计算出离群值的上下限,最后将超出上下限的值替换成上下限的值。最终输出经过处理后的数组。
在实际应用中,还可以使用其他方法来处理离群值,例如使用箱线图、分位数等方法。需要根据具体情况选择合适的方法来处理离群值。
模型训练
使用模型训练数据并评估模型。
示例
以下是使用逻辑回归模型训练数据并评估模型的示例代码:
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
# 加载数据集
X, y = load_dataset()
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 创建逻辑回归模型
model = LogisticRegression()
# 训练模型
model.fit(X_train, y_train)
# 预测测试集
y_pred = model.predict(X_test)
# 评估模型
accuracy = accuracy_score(y_test, y_pred)
print("Accuracy:", accuracy)
以上示例代码中,我们使用sklearn库中的逻辑回归模型来训练数据,并使用train_test_split函数将数据集划分为训练集和测试集。然后使用fit函数训练模型,并使用predict函数对测试集进行预测。最后使用accuracy_score函数计算模型的准确率,即模型预测正确的样本数占总样本数的比例。
在实际应用中,可以根据需求使用不同的模型,并使用交叉验证等方法评估模型的性能。同时,还需要注意数据集的划分、特征选择等问题,以及进行超参数调优等操作以达到更好的性能。
数据可视化
使用图表、热图、散点图等方式将数据可视化。
示例
以下是使用matplotlib和seaborn库将数据可视化的示例代码:
import matplotlib.pyplot as plt
import seaborn as sns
# 加载你的数据集
X, y = load_dataset()
# 绘制直方图
plt.hist(X[:, 0], bins=20)
plt.xlabel("Feature 1")
plt.ylabel("Frequency")
plt.show()
# 绘制散点图
plt.scatter(X[:, 0], X[:, 1], c=y)
plt.xlabel("Feature 1")
plt.ylabel("Feature 2")
plt.show()
# 绘制热图
corr_matrix = np.corrcoef(X.T)
sns.heatmap(corr_matrix, annot=True)
plt.show()
以上示例代码中,我们使用matplotlib库绘制了直方图和散点图,并使用seaborn库绘制了热图。直方图用于显示某一特征的分布情况,散点图用于显示两个特征之间的关系,热图用于显示特征之间的相关性。
在实际应用中,我们还可以使用其他类型的图表,如折线图、饼图、箱线图等,根据具体需求来选择合适的图表类型。同时,根据数据的不同特点和需求,我们还可以对图表进行修改和美化,以达到更好的可视化效果。

















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











