







 本文详细介绍了从支持向量机(SVM)到双线性支持向量机(Bilinear SVM)再到支持矩阵机(SMM)的发展过程。涵盖SVM的基本原理、核技巧的应用、SMO算法简介以及Bilinear SVM和SMM如何更好地处理矩阵结构数据。
本文详细介绍了从支持向量机(SVM)到双线性支持向量机(Bilinear SVM)再到支持矩阵机(SMM)的发展过程。涵盖SVM的基本原理、核技巧的应用、SMO算法简介以及Bilinear SVM和SMM如何更好地处理矩阵结构数据。
本文讲述从SVM(支持向量机)到 Bilinear SVM(双线性支持向量机),最后到SMM(Support Matrix Machines , 支持矩阵机)的发展历程。
参考文献为:
- 《统计学习方法》 李航
- NIPS2009 文章 ”Bilinear classifiers for visual recognition”
- ICML2015文章 ”Support Matrix Machines”
SVM
支持向量机是一个二分类的算法,它的实现机理主要是间隔最大化,根据训练数据是否线性可分性分为三类:当训练数据线性可分时,运用硬间隔最大化(hard margin maximization)学习一个线性可分支持向量机;当训练数据近似线性可分时,运用软间隔最大化(soft margin maximization)学习一个线性支持向量机;当训练数据线性不可分时运用核技巧(kernel trick)和软间隔最大化学习一个非线性支持向量机.
- 几个重要的基本术语:分离超平面、分类决策函数、函数间隔、几何间隔、支持向量
以下面这一个图说明这几个概念。
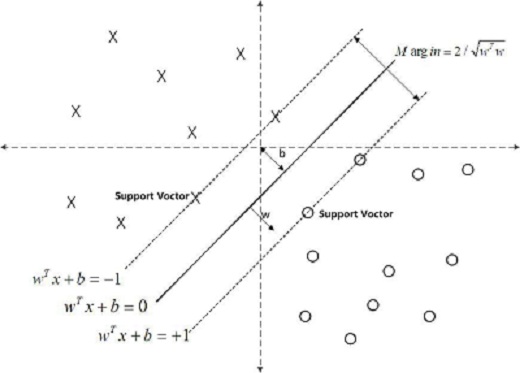
假设给定一个特征空间的上训练数据集:
T=(x1,y1),(x2,y2),...,(xn,yn)
,
xi
为实例,
yi
为对应的类标,取值为
1
代表分类正确,
分离超平面:将特征空间划分为正负两类的超平面,法向量指向的一侧为正类,另一侧为负类。对应图中的实线
wTx+b=0
, 其中
w
为法向量,
分类决策函数:即 f(x)=sign(wTx+b)
函数间隔:对于每一个样本点,函数间隔为 yi(wTxi+b) , 其中 |wTxi+b| 能相对的表示点 xi 距离超平面的远近,而 wTxi+b 的符号与类标 yi 是否一致则表示是否分类正确。我们把所有点中函数间隔最小的定义为整个数据集对于超平面的函数间隔。
几何间隔:对于每一个样本点,几何间隔为
yi||w||(wTxi+b)
。对于函数间隔,只要成比例的改变
w
和
支持向量:距离分类超平面最近的实例。对于正样本,支持向量在 wTx+b=+1 上,对于负样本,支持向量在 wTx+b=−1 上。
- 硬间隔最大化
开篇提过,SVM实现的机理是间隔最大化(具体指几何间隔最大化),因此有以下目标函数(其中 θ 表示几何间隔):
将几何间隔 θ 换成函数间隔 γ ,得到下式:
将最大化问题等价转化为最小化问题,同时由于 γ 的改变对目标函数的优化没有影响,所以令 γ =1,于是得到线性可分支持向量机学习的最优化问题形式:
我们将上面的最优化问题称为原始问题,通过对其构建拉格朗日函数并求解,可以得到它的对偶形式 :
具体过程再此不再叙述,想了解的话可以阅读李航的统计学习方法。
- 软间隔最大化
当训训练数据近似线性可分时,我们对每个样本点引进一个松弛变量 ξi≥0 , 于是最优化问题就从硬间隔最大化过渡为:
它的对偶形式是:
还可以从Hinge Loss Function(合页损失函数)的角度推倒出线性支持向量机的目标函数:
其中 [z]+ 为 hing loss function , 表示小于 0 的部分取
- 核技巧
通俗的讲,核技巧的主要思想是将一个低维的线性不可分的样本点投影到高维,使其变得线性可分,即用维数升高为代价换取线性可分性。听上去还是有点玄乎,再通俗点就是从不同的视角看这些样本点,即所谓横看成岭侧成峰。下面是一个很好的例子:
![]](https://img-blog.csdn.net/20160323180737376)
假设图中直线是我们要分类的样本点,红色ab段是正类,两边的蓝色段是负类。显然用线性方法(即直线)是无法进行分类的,我们可以用图中的抛物线将正负类分开。
设抛物线的方程是 g(x)=c0x2+c1x+c2 , 显然这是一个二维非线性的。
我们令 [a1,a2,a3]=[c0,c1,c2] , [y1,y2,y3]=[x2,x,1] ,
那么有 g(x)=c0x2+c1x+c2=[c0,c1,c2]⋅[x2,x,1]T=[a1,a2,a3]⋅[y1,y2,y3]T=a1y1+a2y2+a3y3 ,
式子 a1y1+a2y2+a3y3 是三维线性的。
这个简单例子验证了将一个低维的线性不可分的样本点投影到高维,使其变得线性可分的思想。
在上面例子中我们把
g(x)
中的
x2
项看成
x1x2
,定义
[x1,x2]
构成的二维空间为
X
,而
满足一定条件的函数才能作为核函数(条件在此不作讨论),常用的核函数有
多项式核函数 : K(x,z)=(x⋅z+1)p , 对应的分类决策函为: f(x)=sign(∑i=1Nsaiyi(xi⋅x+1)p+b)
高斯核函数 : K(x,z)=exp(−||x−z||22σ2) , 对应的分类决策函数为: f(x)=sign(∑i=1Nsaiyiexp(−||x−z||22σ2)+b)
从上面可以看出,对于非线性支持向量机,只需要把线性支持向量机对偶形式中的內积换成核函数即可。
- SMO
上面提到的三种支持向量机形式上都是凸二次规划问题,具有全局最优解,且有许多算法可以求解。但是当样本容量很大时求解非常低效,所以提出了快速实现算法,SMO(序列最小最优化)是其中广泛使用的一种。具体内容以后有时间再补充上。
Blinear SVM
双线性支持向量机的提出是基于实际分类问题中,我们要处理的数据(比如图像)是以矩阵的形式存在、存放的,矩阵内部具有结构性,即行与行,列与列之间是相互关联的。而SVM在处理时,把代表单个实例的矩阵按行或列首尾相接拉成一个长向量的形式进行处理,这就在一定程度上损坏了矩阵的结构性。基于此种考虑提出了双线性SVM。
以软间隔最大化得到的线性支持向量机为例,它的优化函数为:
由于
tr(WTW)=vec(WT)Tvec(WT)=wTw
,
tr(WTXi)=vec(WT)Tvec(XTi)=wTxi
, 其中
W
为回归矩阵,
为了获取矩阵的结构信息,一种做法是在
W
矩阵上加低秩(low-rank)约束。具体加低秩的办法又有许多,我们在此讲开题中NIPS2009中用到的方法 :
令
SMM
在开题提到的 ICML2015的这篇文章中,作者提出了一种叫支持矩阵机的全新分类方法。其出发点和双线性SVM相同,都是为了最大程度上利用矩阵的固有结构信息,从而提高分类精度。具体的思路也是利用
W
矩阵的低秩性。作者抛弃了将
可以将这个目标函数看成 : F范数+核范数+Hing Loss Function
后续会补充上SMO算法具体过程以及相关的代码实现。不足之处欢迎批评指正。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









