








一、HDFS的工作机制
很多不是真正理解hadoop技术体系的人,经常会觉得HDFS可用于网盘类应用。但实际并非如此。要想将技术准确用在恰当的地方,必须对技术有深刻的理解。
1.1 概述
- HDFS集群分为两大角色: NameNode、DataNode
- NameNode负责管理整个文件系统的元数据
- DataNode负责管理用户的文件数据块
- 文件会按照固定的大小(blocksize)切成若干块后分布式存储在若干台DataNode上。
- 每一个文件块可以有多个副本,并存放在不同的DataNode上。
- DataNode会定期向NameNode汇报自身所保存的文件block信息,而NameNode则会负责保存文件的副本数量。
- HDFS的内部工作机制对客户端保持透明,客户端请求访问HDFS都是通过NameNode申请来进行。
二、HDFS写数据流程
2.1 概述
客户端要向HDFS写数据,首先要跟NameNode通信以确认可以写文件并获得接收文件block的DataNode,然后,客户端按顺序将文件逐个以block传递给相应DataNode,并由接收到block的DataNode负责向其他DataNode复制block的副本。
2.2 详细步骤图
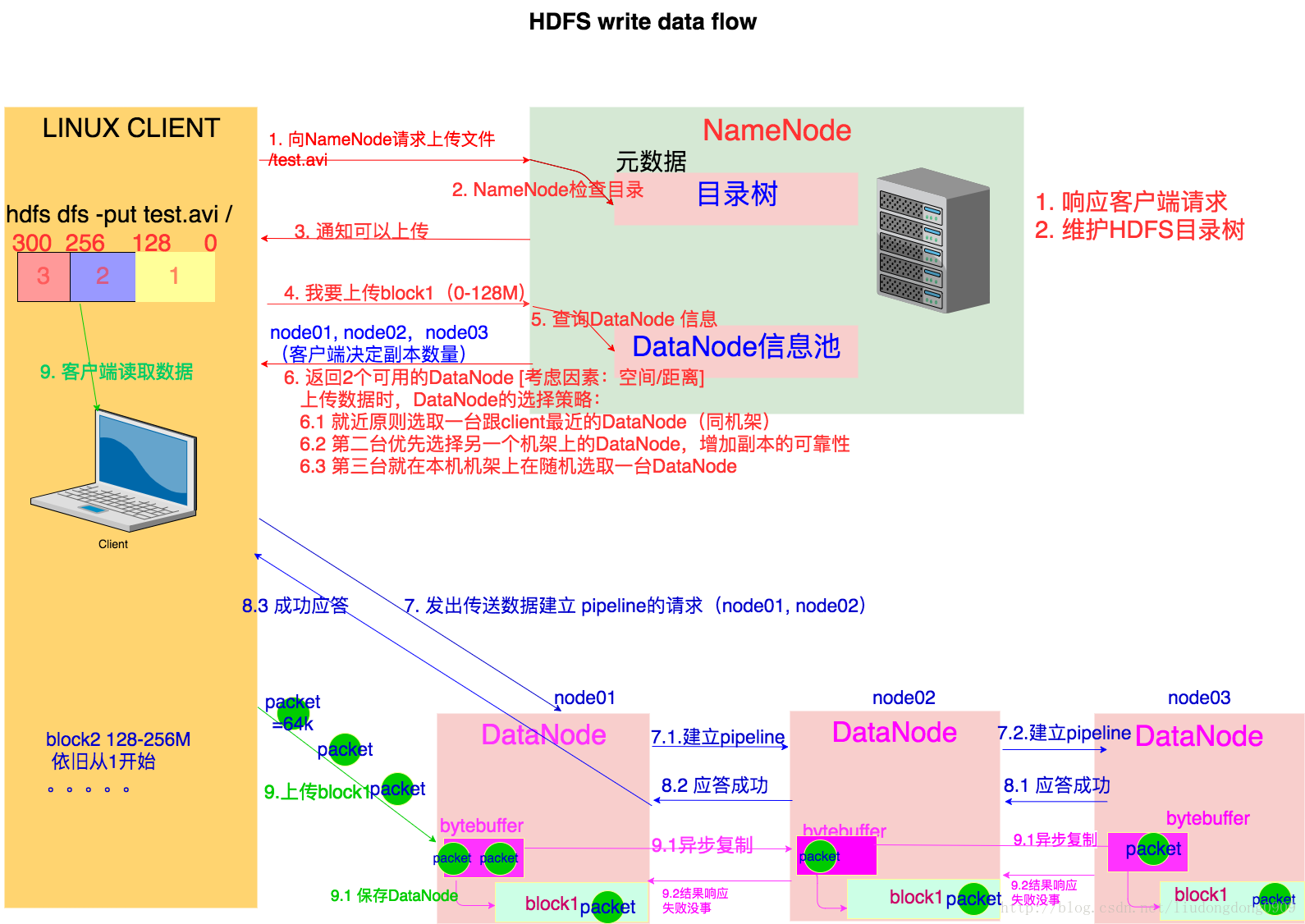
2.3 详细步骤解析
- 与NameNode通信请求上传文件,NameNode检查目标文件是否存在,父目录是否存在
- NameNode返回是否可以上传
- client请求第一个block该传输到那些DataNode服务器上
- NameNode返回3个DataNode服务器 node01、node02、node03
- client请求3台中DataNode中的一台node01上传数据(本质上是 RPC调用,建立pipeline),node01收到请求会继续调用node02,然后node02继续调用node03,将整个pipeline建立完成,逐级返回客户端
- client开始往node01上传第一个block(先从磁盘读数据放到一个本地内存缓存),以packet为单位,node01收到一个packet就会传给node02,node02传给node03,node01每传一个packet会放入一个应答队列,等待应答。
- 当一个block传输完成之后,client再次请求NameNode上传第二个block的服务器
三、HDFS读数据流程
2.1 概述
客户端将要读取的文件路径发送个NameNode,NameNode获取文件的元信息(主要是block的存放位置信息)返回给客户端,客户端根据返回的信息找到相应的DataNode,逐个获取文件的block并在客户端本地进行数据追加合并,从而获得整个文件。
2.2 详细步骤图
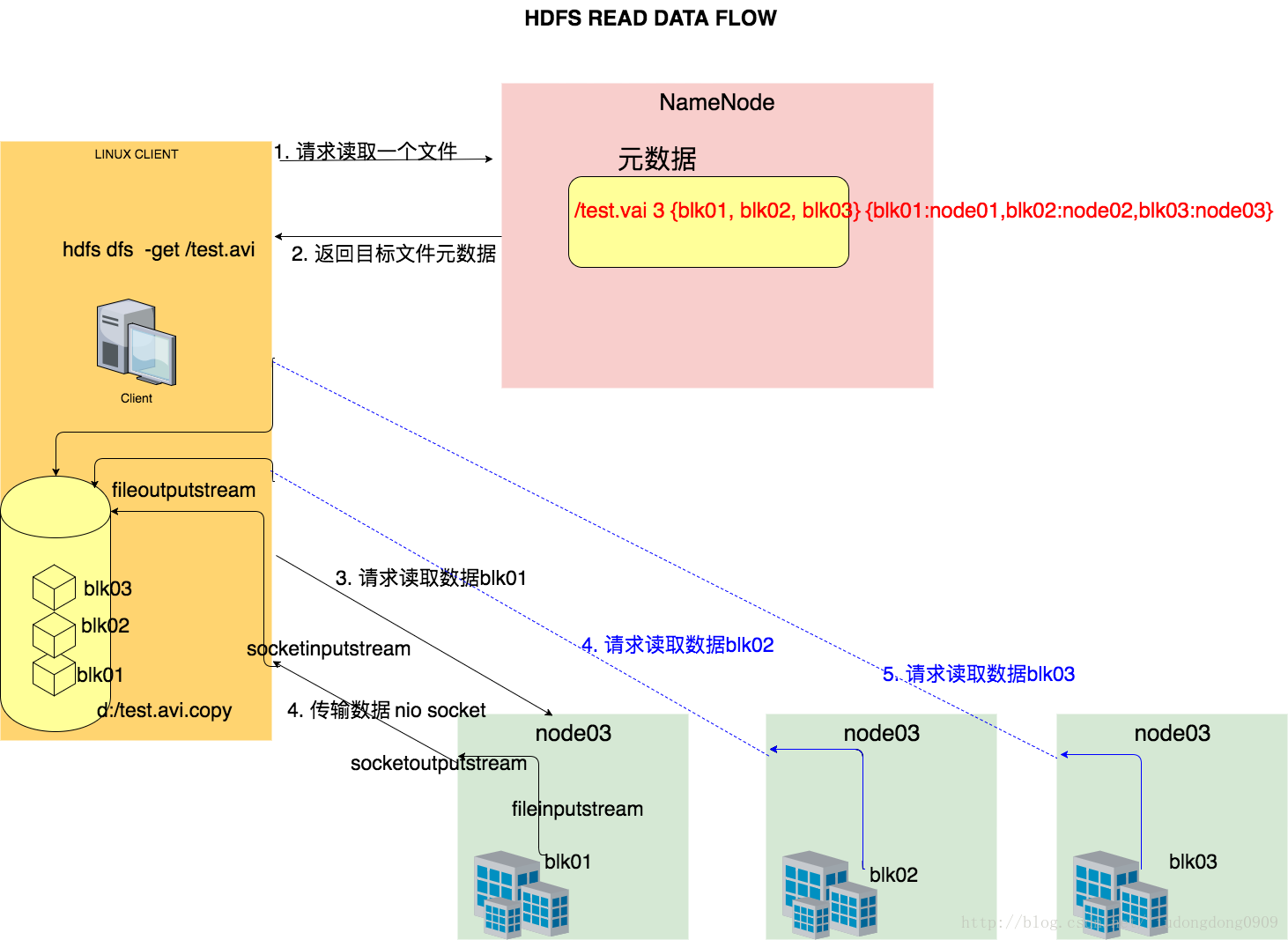
2.3 详细步骤解析
- 与NameNode通信查询元数据,找到文件块坐在的DataNode服务器
- 挑选一台DataNode(就近原则,然后随机)服务器,请求建立socket流
- DataNode开始发送数据(从磁盘里面读取数据放入流,以packet为单位来做校验)
4.客户端以packet为单位接收,先在本地缓存,然后写入目标文件
四、NameNode工作机制
4.1 问题场景
- 集群启动之后,可以查看文件,但是上传文件时报错,打开web页面可以看到NameNode正处于safemode状态,怎么处理?
- NameNode服务器的磁盘故障导致NameNode宕机,如何挽救集群及数据?
- NameNode是否可以有多个? NameNode内存要配置多大?NameNode跟集群数据存储能力有关系吗?
- 文件的blocksize究竟调大好还是调小好?
诸如此类问题的回答,都需要基于对NameNode自身的工作原理的深刻理解。
4.2 NameNode的职责
NameNode主要的两个职责:
1. 负责客户端请求的响应
2. 元数据的管理(查询、修改)
4.3 元数据管理
NameNode对数据的管理采用了三种存储形式:
内存元数据(NameSystem)
磁盘元数据镜像文件
数据操作日志文件(可通过日志运算出元数据)
4.3.1 元数据存储机制
- 内存中有一份完整的元数据(内存 meta data)
- 磁盘有一个“准完整”的元数据镜像(fsimage)文件(在NameNode的工作目录中)
- 用于衔接内存metadata和持久化元数据镜像fsimage之间的操作日子(edits文件)注意:当客户端对hdfs中的文件进行新增或修改操作,操作记录首先被记入edits日志文件中,当客户端操作成功后,相应的元数据会更新到内存metadata中
4.3.2 元数据手动查看
先查看一下 hdpdata中的数据结构:
[hadoop@hadoop01 dfs]$ pwd
/home/hadoop/apps/hdpdata/dfs
[hadoop@hadoop01 dfs]$
[hadoop@hadoop01 dfs]$ tree
.
├── data
│ ├── current
│ │ ├── BP-60221078-172.16.29.161-1514955036901
│ │ │ ├── current
│ │ │ │ ├── dfsUsed
│ │ │ │ ├── finalized
│ │ │ │ │ └── subdir0
│ │ │ │ │ └── subdir0
│ │ │ │ │ ├── blk_1073741832
│ │ │ │ │ ├── blk_1073741832_1008.meta
│ │ │ │ │ ├── blk_1073741833
│ │ │ │ │ ├── blk_1073741833_1009.meta
│ │ │ │ │ ├── blk_1073741843
│ │ │ │ │ ├── blk_1073741843_1019.meta
│ │ │ │ │ ├── blk_1073741850
│ │ │ │ │ ├── blk_1073741850_1026.meta
│ │ │ │ │ ├── blk_1073741851
│ │ │ │ │ ├── blk_1073741851_1027.meta
│ │ │ │ │ ├── blk_1073741853
│ │ │ │ │ ├── blk_1073741853_1029.meta
│ │ │ │ │ ├── blk_1073741864
│ │ │ │ │ ├── blk_1073741864_1040.meta
│ │ │ │ │ ├── blk_1073741865
│ │ │ │ │ ├── blk_1073741865_1041.meta
│ │ │ │ │ ├── blk_1073741867
│ │ │ │ │ ├── blk_1073741867_1043.meta
│ │ │ │ │ ├── blk_1073741868
│ │ │ │ │ └── blk_1073741868_1044.meta
│ │ │ │ ├── rbw
│ │ │ │ └── VERSION
│ │ │ ├── dncp_block_verification.log.curr
│ │ │ ├── dncp_block_verification.log.prev
│ │ │ └── tmp
│ │ └── VERSION
│ └── in_use.lock
├── name
│ ├── current
│ │ ├── edits_0000000000000000001-0000000000000000340
│ │ ├── edits_0000000000000000341-0000000000000000341
│ │ ├── edits_0000000000000000342-0000000000000000343
│ │ ├── edits_0000000000000000344-0000000000000000345
│ │ ├── edits_0000000000000000346-0000000000000000347
│ │ ├── edits_0000000000000000348-0000000000000000349
│ │ ├── edits_0000000000000000350-0000000000000000351
│ │ ├── edits_0000000000000000352-0000000000000000353
│ │ ├── edits_0000000000000000354-0000000000000000355
│ │ ├── edits_0000000000000000356-0000000000000000357
│ │ ├── edits_0000000000000000358-0000000000000000359
│ │ ├── edits_0000000000000000360-0000000000000000361
│ │ ├── edits_0000000000000000362-0000000000000000386
│ │ ├── edits_inprogress_0000000000000000420
│ │ ├── fsimage_0000000000000000417
│ │ ├── fsimage_0000000000000000417.md5
│ │ ├── fsimage_0000000000000000419
│ │ ├── fsimage_0000000000000000419.md5
│ │ ├── seen_txid
│ │ └── VERSION
│ └── in_use 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









