









 本文探讨了Java中处理Unicode汉字的方法,包括如何声明和使用常用汉字(位于BMP平面,2字节表示)以及生僻汉字(超出BMP平面,需特殊转换)。通过实例代码展示了`Character.toChars()`方法在处理多字节汉字时的作用,并解释了Unicode平面的概念。
本文探讨了Java中处理Unicode汉字的方法,包括如何声明和使用常用汉字(位于BMP平面,2字节表示)以及生僻汉字(超出BMP平面,需特殊转换)。通过实例代码展示了`Character.toChars()`方法在处理多字节汉字时的作用,并解释了Unicode平面的概念。
前文介绍了Unicode基本知识,没看过的去看一下,传送门:字符集与编码系列:Unicode字符集_liudun_cool的博客-CSDN博客
常用汉字在Java中的用法
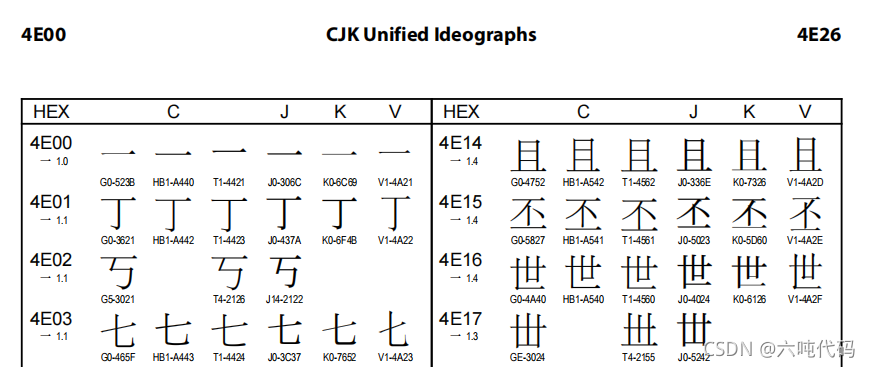
对于一些常用汉字,一般都在Unicode的BMP平面,也就是2个字节足够表示。比如,我打开一个Unicode CJK码表,可以看到第一个汉字就是编码为4E00的 ‘一’,第二个是编码为4E01的 ‘丁’。下图中的CJKV的含义:
C = 中国(大陆、香港、台湾)
J = 日本
K = 韩国
V = 越南
先来试一试Java中char类型和Unicode的关系吧。写几行Java代码:
//根据字符在码表中的编号,声明一个字符变量
// '\u'是Unicode字符固定前缀,4E01是这个字符在Unicode码表中的十六进制编号
char ch = '\u4E01';//4E01是十六进制,对应的十进制值=19969
System.out.println("Unicode中编码'4E01'代表的字符是:"+ch);
System.out.println("19969在Unicode中代表汉字:"+(char)19969);控制台输出:
Unicode中编码'4E01'代表的字符是:丁
19969在Unicode中代表汉字:丁
生僻汉字在Java中的用法
此处我所谓的生僻字,是指不在BMP平面的汉字。为了演示生僻字,我打开了Unicode平面2的码表,随便选一个字。
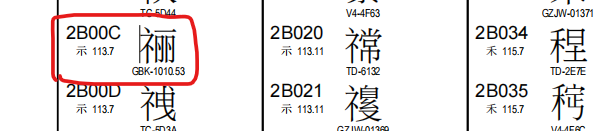
这个字的编码2B00C中的2就是平面编号。看这个十六进制编码就知道,2个字节无法表示,这种字符在Java中怎么声明呢?写一段Java代码:
//char ch = '\u2B00C';这样会直接编译错误
//BMP平面之外的汉字,超出2个字节,要用如下方式声明一个char类型变量
//方式1:
char[] ch3 = Character.toChars(0x2B00C);
//方式2:
char[] ch4 = {'\uD86C','\uDC0C'};
System.out.print(ch3);
System.out.print(ch4);控制台输出:
𫀌𫀌
可以看到,这种BMP平面之外的生僻汉字,超出了2个字节,无法靠普通的 '字' 方式直接声明char类型变量,需要Character包装类的toChars()内部做特殊转换 。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











