







人脸识别经典算法
Suncicie
2017.12.10
特征脸(Eigenface)
获取M张人脸的图像集合,每张图片转换成一个N维度向量,组成集合
$S$计算平均图像
- 计算每张图像和平均图像的差值Φ ,就是用S集合里的每个元素减去步骤二中的平均值。
找到M个正交的单位向量un,这些单位向量其实是用来描述Φ (步骤三中的差值)分布的。un里面的第k(k=1,2,3…M)个向量uk 是通过下式计算的,
识别人脸,先计算出要判别的人脸的特征脸
计算与对比脸的欧式距离
- 特点,简单易理解,作为不是专门研究人脸识别的论文,这个人脸识别方案经常被用,易收到光照遮挡物等影响


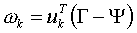
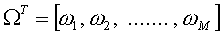
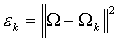
FishFace(LDA)
LDA
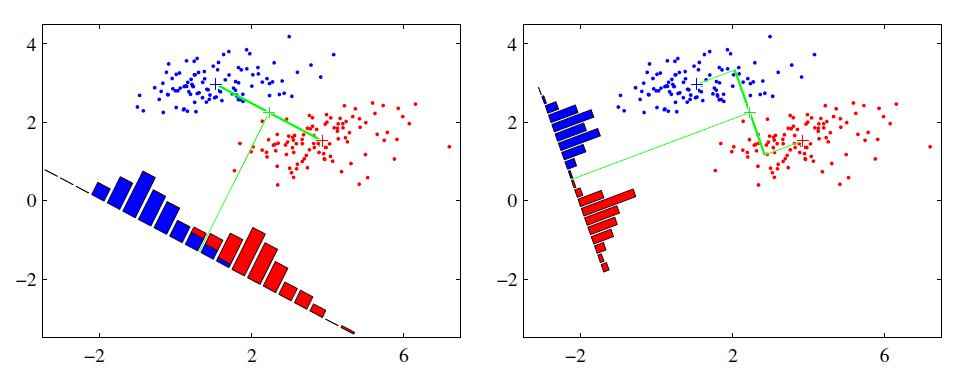
- 投影后类内方差最小,类间方差最
计算过程
计算每类数据的均值
- 数据投影到w向量后,每类的中心点
不同的类要尽量分开即
同类要尽量聚拢,聚合度计算如下,即到中心点的距离累积越小越好
目标函数(分子小分母大,目标函数越大)
- 化简求值
- FaceFisher
- FaceFisher人脸识别识别不同的人脸是多分类问题 假设有C个人的人脸图像,每个人可以有多张图像,所以按人来分,可以将图像分为C类
- 如同Eigenface将每张图像按照逐行逐列的形式获取像素组成一个向量,比如100x100的图像得到的向量为10000维,将向量投影到一个向量空间
$W=(w_1,w_2,...w_n)$ - 问题转化为找到一个
$W$使得类别之间距离大,同类距离小 - 判别图片
- 将新图片映射到
$W$空间,根据欧式距离算与个类别的距离来进行识别
- 将新图片映射到
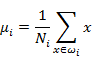
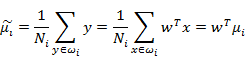
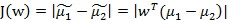
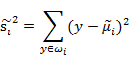
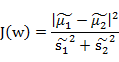

3. 特点,与特征脸类似简单易理解,易收到光照遮挡物等影响,都是==通过降维然后计算相似度的原理==
LBP方法(Local Binary Patterns,局部二值模式)
LBP特征提取
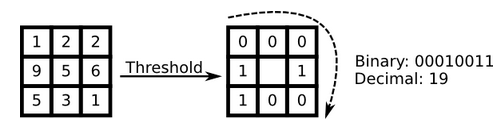
最初的LBP是定义在像素3x3邻域内的,以邻域中心像素为阈值,将相邻的8个像素的灰度值与其进行比较,若周围像素值大于中心像素值,则该像素点的位置被标记为1,否则为0
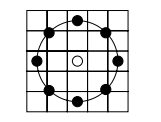
改进版LBP算子将3×3邻域扩展到任意邻域,并用圆形邻域代替了正方形邻域,改进后的 LBP 算子允许在半径为 R的圆形邻域内有任意多个像素点。从而得到了诸如半径为R的圆形区域内含有P个采样点的LBP算子
计算采样点的位置R是采样半径,p是第p个采样点,P是采样数目
双线性差值变成整数
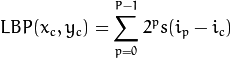

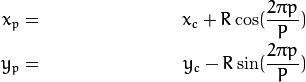

旋转不变LBP算子
- 将图像旋转一周,始终取得到最小的LBP值
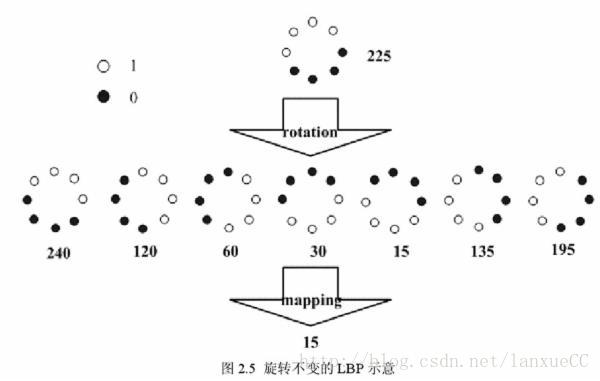
3. LBP等价模式
- LBP表达的是局部信息的纹理,如果直接用这个来分类,计算量很多,5×5邻域内20个采样点,有2的20次方=1,048,576种二进制模式。如此多的二值模式无论对于纹理的提取还是对于纹理的识别、分类及信息的存取都是不利的。
- 当某个LBP所对应的循环二进制数从0到1或从1到0最多有两次跳变时,该LBP所对应的二进制就称为一个等价模式类。如00000000(0次跳变),00000111(只含一次从0到1的跳变),10001111(先由1跳到0,再由0跳到1,共两次跳变)都是等价模式类。除等价模式类以外的模式都归为另一类,称为混合模式类
- 等价模式代表了图像的边缘、斑点、角点等关键模式,等价模式占了总模式中的绝大多数,所以极大的降低了特征维度。利用这些等价模式和混合模式类直方图,能够更好地提取图像的本质特征
可以看出LBP在不同光照下影响小

LBP特征匹配
- 将一副人脸图像分为7x7的子区域(如下图),并在子区域内根据LBP值统计其直方图,以直方图作为其判别特征。这样做的好处是在一定范围内避免图像没完全对准的情况,同时也对LBP特征做了降维处理
直方图交叉核方法
- 图像的直方图

- 直方图均衡化
- 图片偏亮或者偏暗直接调整直方图可以是图片细节清晰
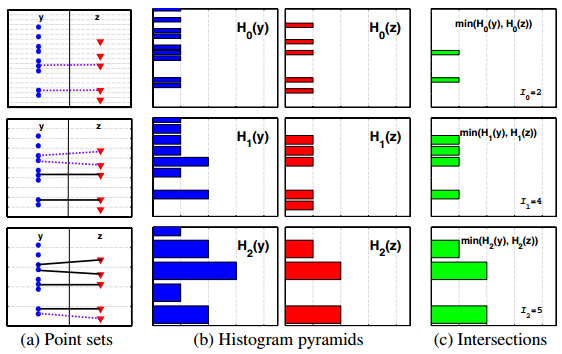
直方图交叉核(计算两张图直方图的差距)
根据直方图的间距得到多种类型的直方图
- 直方图间距:如像素230-255的像素统计出的直方图间距为15
不同的间距不同的直方图之间的交叉,通过交叉的堆叠来衡量相似度实现匹配
- y,z代表两个数据集,b中左右表示两个数据分布的直方图,c代表b中左右两幅图的交叉,根据交叉来计算相似度
- 图像的直方图
卡方统计方法

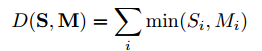
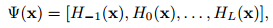
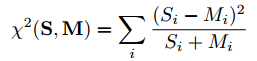
1. $S_i$待检测图像,$M_i$已知图像,上公式为卡方检验公式
HOG特征
HOG方向梯度直方图(Histogram of Oriented Gradient, HOG)特征是图像识别中最常用的特征之一了,它利用了梯度的统计信息,而梯度主要存在于边缘的地方,就类似于LBP编码的统计信息,大家都是用直方图来表示一般结合其他分类方法来做
1. gamma校正
2. 图像转灰度
3. 计算图像的梯度(SOBEL算子)
- 水平梯度算子:$(-1,0,1)$,垂直梯度算子:$(-1,0,1)^T$
- $G_x(x,y)=I(x+1,y)-I(x-1,y) $
- $G_y(x,y)=I(x,y+1)-I(x,y-1) $
- $G(x,y)=\sqrt {G_x^2(x,y)+G_y^2(x,y)}$ #计算梯度
- $\theta (x,y)=arctan(\frac {G_y(x,y)}{G_x(x,y)})$#计算梯度方向
4. 梯度信息统计
- 与LBP类似,划分为cell 来获取局部特征,可以矩形划分圆形划分

- 根据Dalal等人的实验,在行人目标检测中,在无符号方向角度范围并将其平均分成9份(bins)(180度分为9个bin,每个范围20度,如0-20度是一份,20-40度是一份)能取得最好的效果,当bin的数目继续增大效果改变不明显,故一般在人体目标检测中使用bin数目为9范围0~180度的度量方式,然后==各个角度做统计==
- 归一化,不同的局部,会因光照而前景背景变化梯度变化巨大,而且block需要连接,需要进行归一化,然后把cells进行合并
- L1,L2归一化
- 加快直方统计图速率(三线性插值)
- 最终HOG特征

- HOG主要用在object detection 领域,特别是行人检测,智能交通系统,当然也有文章提到把,对噪声遮挡很敏感,计算很慢
HOG用在手势识别,人脸识别等方面
shif特征
深度学习的人脸的识别方法
- 很多方法的精度达到0.99+ ,甚至比人工识别的精度更高
mtcnn
face++(0.9950)
- 用到了传统的10层CNN网络
- 影响神经网络识别准确性的因素是数据集,下图显示大的数据集对精度的提升有明显的作用,数据的分布同样对模型效果影响
- 文章从网络上收集数据,在LFW数据集上准确率达到99.5%,但是在真实系统中,准确率只有60%,主要是同一个人不同年纪的差别导致,或者不同形态姿态导致(多分类了还需要L2???)
- 文中提到的改进方向是从数据收集角度,比如从人物的视频中获取每一帧不同的人脸图像等
DeepFace(0.9735)
常规人脸识别流程是:==人脸检测-对齐-表达-分类==
- 设计了一个很好的DNN架构和大数据集
- 利用3D建模来进行人脸对齐
人脸对齐:根据输入的人脸图像,自动定位出面部关键特征点,如眼睛、鼻尖、嘴角点、眉毛以及人脸各部件轮廓点等
红框是人脸检测,白点是人脸对齐

人脸对齐:
1. 通过6个特征点检测人脸;
2. 剪切;
3. 建立Delaunay triangulation(特征的三角区域);
4. 参考标准3d模型,将3d模型比对到图片上;
5. 进行仿射变形,最终生成正面图像。
深度神经网络:
1. 对齐后的图像进行输入
2. C1-M2-C3卷积池化卷积层
2. L4,L5, L6全连接层
FR+FCN(0.9645 )
- 自然条件下,因为角度,光线,occlusions(咬合/张口闭口),低分辨率等原因,使人脸图像在个体之间有很大的差异,影响到人脸识别的广泛应用。本文提出了一种新的深度学习模型,可以学习人脸图像看不见的一面。==作者开发了一种从个体照片中自动选择/合成canonical-view(标准正面图像)的方法==;
- 训练了一个深度深度学习网络来重建人脸(收集一个人的很多张人脸,根据不同侧影角度来重建人脸,识别时根据所拍摄的照片重建出正面人脸来进行识别)
- 效果图
DeepID(0.9745 )
1.(VGG net 和GoogleLeNet)两种深度神经网络的ensemble
FaceNet(0.9963)
- FaceNet,可以直接将人脸图像映射到欧几里得空间,空间的距离代表了人脸图像的相似性。只要该映射空间生成,人脸识别,验证和聚类等任务就可以轻松完成
- FaceNet的核心是百万级的训练数据以及 triplet loss
总结
- 人脸识别效果好的而且顶尖的技术几乎都用到了深度学习,需要庞大的,良好的数据集,计算复杂,速度慢,对硬件有一定的要求(需要GPU,内存大,SSD快等)
- 对于SGX中图像隐私保护来说,如果研究重点不是放在图像识别精度的话,没必要采用复杂的人脸识别方案,其次由于SGX的硬件设计,每个安全的enlave只有90M,而且不同的enlave之间需要验证等复杂的交互才能通信,所以并不适合采用复杂的人脸识别方案。
- Eigenface作为一种挺经典的人脸识别方案,在很多论文中被用做人脸识别的代表方案,在OpenCV中有C++开源代码,在SGX中重构相对比较方便,推荐此方案














 2266
2266











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









