






版权声明:开源精神,欢迎转载
这一段时间对数据库优化方面的认识深有体会,就以MySQL为例测试一下分区表的性能
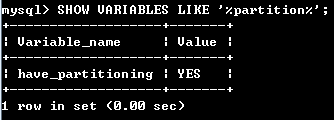
MySQL5.0好像不支持分区,我用的5.5版本,测试是否支持可通过以下方法:
SHOW VARIABLES LIKE '%partition%';
- 1

- 1
如果结果为yes则说明支持,如下图:
创建表
不分区的表:
CREATE TABLE no_part_tab
(id INT DEFAULT NULL,
remark VARCHAR(50) DEFAULT NULL,
d_date DATE DEFAULT NULL
)ENGINE=MYISAM
- 1
- 2
- 3
- 4
- 5

- 1
- 2
- 3
- 4
- 5
分区表:
CREATE TABLE part_tab
(id INT DEFAULT NULL,
remark VARCHAR(50) DEFAULT NULL,
d_date DATE DEFAULT NULL
)ENGINE=MYISAM
PARTITION BY RANGE(YEAR(d_date))(
PARTITION p0 VALUES LESS THAN(1995),
PARTITION p1 VALUES LESS THAN(1996),
PARTITION p2 VALUES LESS THAN(1997),
PARTITION p3 VALUES LESS THAN(1998),
PARTITION p4 VALUES LESS THAN(1999),
PARTITION p5 VALUES LESS THAN(2000),
PARTITION p6 VALUES LESS THAN(2001),
PARTITION p7 VALUES LESS THAN(2002),
PARTITION p8 VALUES LESS THAN(2003),
PARTITION p9 VALUES LESS THAN(2004),
PARTITION p10 VALUES LESS THAN maxvalue);
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
插入数据
MySQL没有像Oracle那样的序列,所以要用循环插入,每张表插入800w数据做测试
插入未分区表:
DROP PROCEDURE IF EXISTS no_load_part;
DELIMITER//
CREATE PROCEDURE no_load_part()
BEGIN
DECLARE i INT;
SET i =1;
WHILE i<8000001
DO
INSERT INTO no_part_tab VALUES(i,'no',ADDDATE('1995-01-01',(RAND(i)*36520) MOD 3652));
SET i=i+1;
END WHILE;
END//
DELIMITER ;
CALL no_load_part;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
插入分区表:
DROP PROCEDURE IF EXISTS load_part;
DELIMITER&&
CREATE PROCEDURE load_part()
BEGIN
DECLARE i INT;
SET i=1;
WHILE i<8000001
DO
INSERT INTO part_tab VALUES(i,'partition',ADDDATE('1995-01-01',(RAND(i)*36520) MOD 3652));
SET i=i+1;
END WHILE;
END&&
DELIMITER ;
CALL load_part;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
说明:首先删除procedure,如果已存在的话,然后开始创建新的,delimiter是指定分隔符,默认的是“;”,这里我们不能用分号,就指定为“//”或者“&&”,创建时定义个int类型i,然后通过do…while循环,等程序执行完毕后把分隔符重新指定为“;”,然后通过call语句写入数据库
测试效率
测试sql:
SELECT COUNT(*) FROM no_part_tab WHERE d_date > DATE '1995-01-01' AND d_date< DATE '1995-12-31';
SELECT COUNT(*) FROM part_tab WHERE d_date > DATE '1995-01-01' AND d_date< DATE '1995-12-31';
- 1
- 2
- 3
- 4
- 1
- 2
- 3
- 4
测试结果:
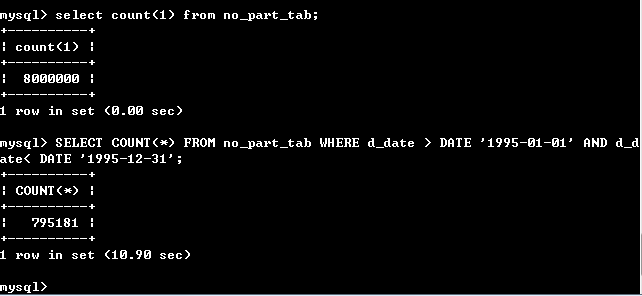
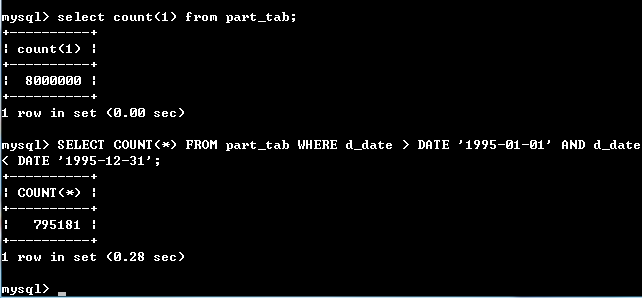
第一次查询的结果对比。不分区是10.90秒,分区是0.28秒,可以看出分区效率提高了约97%,第一次查询速度慢,当多查询几次效率一般会提高,我也试了试,下面是结果:
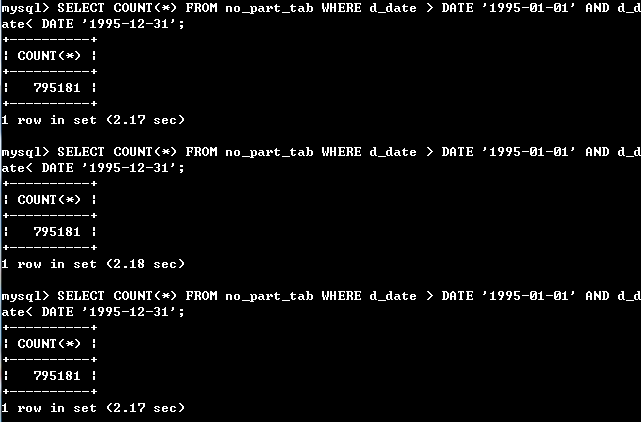
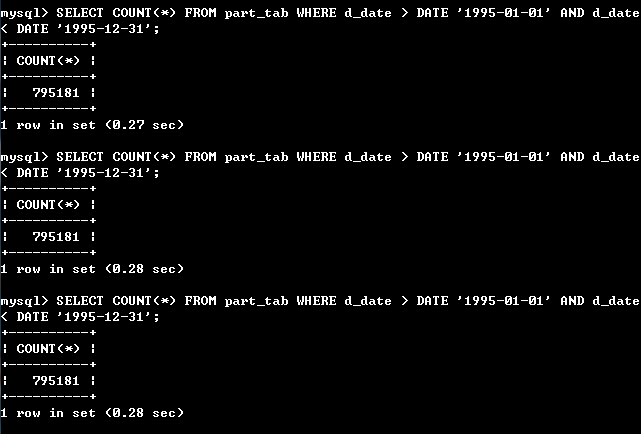
如图可以看出,多查询几次后,不分区的表稳定在2.17秒左右,分区表一直在0.28秒左右,分区的效率依然相比提高约87%,分区效果相当显著
测试数据库相对简单,当数据复杂并且外键多时时,MySQL处理近千万的数据的表时效率是不太好的,这是分区就会显得特别的重要
总结
测试过程中需要了解的注意点:
- 创建表时采用的是myisam类型,除了myisam存储引擎之外还有InnoDB、MEMORY、MERGE等,具体区别我不详述了,我就简单说一下,myisam性能相对来说好点,但不支持事务,另外是二进制,可以windows直接拷贝到linux,InnoDB支持事务等操作,其它存储引擎下的情况我没有测试,有兴趣的可以试试
- MySQL分区方法有多种,除去本次使用的range分区外还有list分区、hash分区、key分区和子分区,另外几种分区方法有兴趣的可以尝试一下

















 1200
1200

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









