







mysql检验分区性能的操作
创建两个结构相同但是一个有分区另外一个没有分区的表

如上图我们给part_tab5创建的分区为1024个,因为mysql中允许最多有1024个分区;之前我测试的是创建8个分区,然后插入500万条数据,然后按照id查询(非索引),part_tab5表的查询速率大约是part_tab6表的查询速率的9倍;注意这里测试的时候不要按照主键查询,因为主键是索引,按照索引查询的时候,即便没有分区,也是非常快的。
现在我很好奇如果我创建了1024个分区,然后插入5000万条数据,带分区的查询速率会比不带分区的快多少呢?
使用存储过程往带有分区的表插入5000万条数据
如下图:

可以使用select命令随时监控插入的条数,如下图:

拷贝一份数据到没有加分区的表中
part_tab6表的结构字段和part_tab5一样,只不过它没有加分区,等到part_tab5表中的5000万条数据插入完成之后,拷贝一份到part_tab6表中,代码如下图:

对比条件查询速率
如果是select 星去查询全部的话,那么有分区的查询的会更慢一些;但是如果是按条件查询的话,比如按照id查询,它的查询时间会更快,如下图:
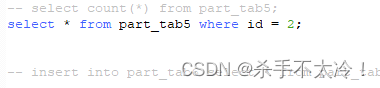
注意这里千万不要对比按照c1字段条件查询的速率,因为c1是索引,内部使用了B+树,它的查询速率是非常快的,你是对比不出来的。而id是一个普通字段,采用了分区和不采用分区对比就非常明显了。
hash分区的时候如果只对其中的某一列进行分区的话,那么其它列速率仍然低
比如我现在有一张表,它的字段有column1,column2,column3,我现在只对column3列进行了hash分区,其它两列没有进行hash分区,那么按条件查询的时候,如果是按照column3条件进行查询,查询速率是比较快的,因为它使用了分区,但是如果按照其它的两列条件查询的话,查询速率是很慢的,因为其它两列没有进行hash分区。
创建太多分区应该也不太好,先创建100个分区。想要用hash分区给多个列分区,格式是不是hash(列名1 + 列名2)?先假设是这样。那么我们创建表的时候就不要有主键了,因为如果有主键的话,我们的hash分区的字段必须是主键包含的字段,也就是主键里面必须有所有hash分区的字段,也就是如果这里的主键不包含列名1和列名2,那么hash(列名1 + 列名2)这样写就是错误的。那如果主键就包含一个字段,而我们想要hash分区的列有好多个,就没办法使用hash分区了。因此我不太确定这样正不正确,先自己测试一下。
后来我又问了大侠,大侠说,没必要每个列名都给他分区,分区一个就行了,比如说我们给时间列名分区,每次查询的时候都可以带上时间,它就会找到对应的区了。但是如果是hash分区这就要求主键必须有时间?这肯定是不合理的。所以我们不能够用hash分区对时间进行分区。要想一下RANGE分区可不可以?
看一下hash分区的时候写hash(列名1, 列名2)的效果,如下图:

最终的效果是,如果hash分区的时候是按照id和c1分区的,那么筛选的时候,只有同时有这两个条件的时候才能找到具体是哪个分区,才能提高效率,如下图:

但是如果where筛选条件不是同时包含c1和id,那么查询效率就很慢了,如下图:

只要筛选条件包含建立分区的所有字段,不管后面还有没有其它的筛选条件,那么分区都有效,如下图:
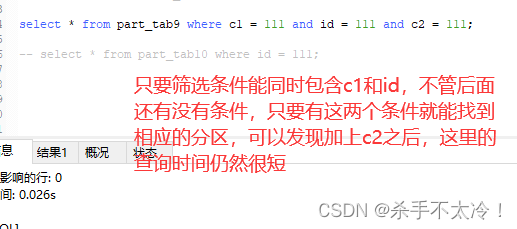
所以这里能不能按照时间进行hash分区,然后每次条件筛选的时候都加上时间范围呢?这个我要建立一张表测试一下,不用建立了不行,因为不可能把时间当做一张表的主键。
后面我又使用RANGE分区的时候,发现分区字段也必须是在主键里面的字段,所以,所有的分区类型都要求如果有主键,那么分区的字段一定是主键里面的某个字段。
因此使用分区的时候,一般会把那个字段加上一个联合主键。如下图:
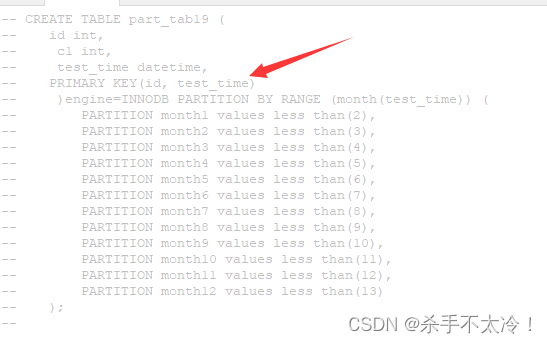
所以现在把id和test_time时间设置成了联合主键,那么用hash分区也是可以的,但是hash分区的时候不允许类型是datetime类型,我们需要把它变成时间戳bigint类型,然后进行hash分区,测试一下使用hash分区(test_time),分成100个区,500w条数据,和使用上面的RANGE分区,分成12个区,500w条数据,看一下后面那个查询效率高?
现在我猜测是使用hash分区分成100个表的查询效率比较高。现在正在使用存储过程生成500w条数据,生成完之后对比一下。
先不管上面的,看下下面的
使用的是RANGE分区,按照日期中的月份分为12个区,日期是1月份的行放到 month1分区(可以理解成一个子表),日期是2月份的行放到month2分区(可以理解成一个子表)。。。日期是12月份的行放到month12分区(可以理解成一个子表)。
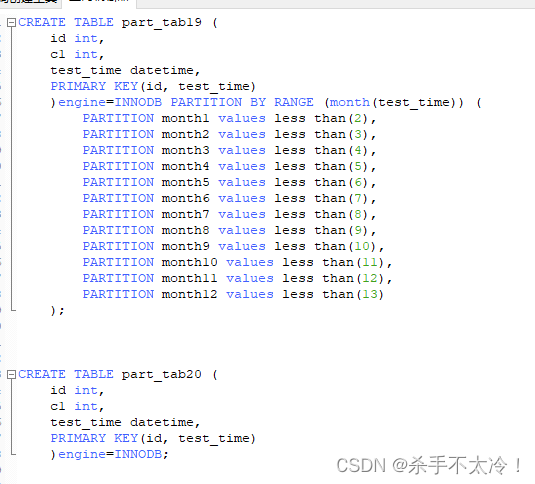
创建分区表part_tab19和未分区表part_tab20
如下图:
代码如下:
CREATE TABLE part_tab19 (
id int,
c1 int,
test_time datetime,
PRIMARY KEY(id, test_time)
)engine=INNODB PARTITION BY RANGE (month(test_time)) (
PARTITION month1 values less than(2),
PARTITION month2 values less than(3),
PARTITION month3 values less than(4),
PARTITION month4 values less than(5),
PARTITION month5 values less than(6),
PARTITION month6 values less than(7),
PARTITION month7 values less than(8),
PARTITION month8 values less than(9),
PARTITION month9 values less than(10),
PARTITION month10 values less than(11),
PARTITION month11 values less than(12),
PARTITION month12 values less than(13)
);
CREATE TABLE part_tab20 (
id int,
c1 int,
test_time datetime,
PRIMARY KEY(id, test_time)
)engine=INNODB;
使用存储过程往分区表里面插入500w条数据
如下图:
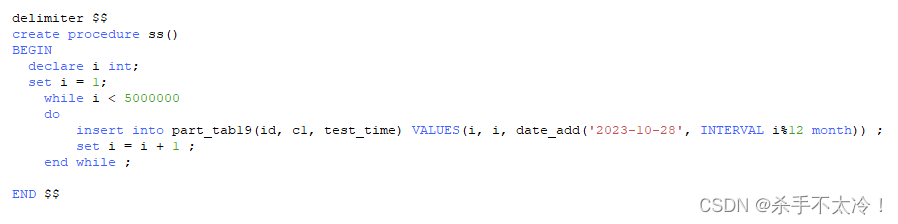
存储过程代码如下:
delimiter $$
create procedure ss()
BEGIN
declare i int;
set i = 1;
while i < 5000000
do
insert into part_tab19(id, c1, test_time) VALUES(i, i, date_add('2023-10-28', INTERVAL i%12 month)) ;
set i = i + 1 ;
end while ;
END $$
把分区表中的数据拷贝到未分区表中
如下图:

代码如下:
insert into part_tab20 select * from part_tab19;
看下分区表part_tab19和未分区表part_tab20里面的数据条数是否一致,如下图:
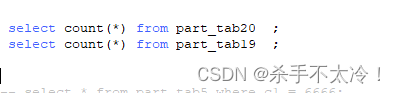
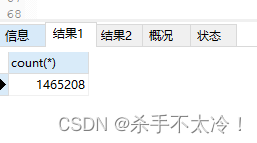
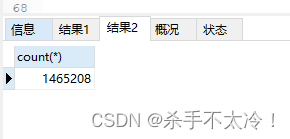
发现现在这俩表的数据是完全一致的,这两个表的字段,数据都是一样的,唯一的区别就是一个表有分区而另外一个表没有分区。
接下来看一下分区是怎么提升查询速率的
首先在未分区的表part_tab20中,我们查询一下c1=162这条数据看看需要多少时间,如下图:

从上图可以发现接近1.3s;
接下来加上时间查询条件,看看需要多久,如下图:

可以发现加上时间范围筛选条件之后没有什么变化,甚至查询时间更长了;为什么呢?因为我们的part_tab20没有按照时间中的月份进行分区;
接下来看一下分区的表part_tab19中,我们查询一下c1=162这条数据(加上时间筛选)的查询时间,如下图:

可以发现只需要0.3秒;
通过分区表的查询时间0.3和未分区表的查询时间1.3对比可得,分区之后速率快了接近4倍;
分区之后表的查询速率为什么会快呢?
比如我们上面的例子,把表分为了12个区,每个月份为一个区,其实也就相当于是按照日期的月份分为了十二张子表,当我们按照月份条件进行查询的时候,不会去查询总表的数据,而是会去查询子表中的数据,因为子表中的数据相对较少,因此查询速率就会提高。

















 105
105











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











