









一 错误描述
1 负责的BI中的数据数据可视化项目一直运行的比较稳定,突然早上用户反馈,报表查询非常慢,非常卡,而且有些网页直接打不开(单体应用,没有降级和熔断)。
2 没一会CPU就报警了,CPU使用率非常高,居高不下。
3 查看日志,后端一直报错:数据库某个用户的账号连接超多。
4 DBA联系反应我们的应用占用了太多连接,IDLE连接数太多,导致该账号的其他应用无法使用数据库了,且DBA调高了连接限制后,没一会,连接又被我们的应用占满。
5 无奈一时半会想不出原因,就重启了服务,没想到一会就又报警了,又是重启,之后才稳定了
6 当天的复盘:只能整理出表面原因:有个部门的同事一个账号配置了多个报表,而且将这些报表配置为每一秒刷新一次,将这些报表的定时刷新关闭以后,情况才有所好转。
7 按照理解,项目使用了Druid连接池,最大连接数设置的是10个,即使没有足够的连接,也不应该超过10个,更不会有IDLE的连接。

二 综合分析:
1 公司采用了开源的Davinci 作为BI工具,该开源项目采用数据源分离技术进行数据库连接管理(其实就是会为每个数据源构造一个Druidi连接池,单独控制每个数据源的连接信息,并将该连接池,保存于一个全局map中【类似于Spring对于Bean的管理】)在每次页面报表进行查询显示的时候,会获取map中的连接池,然后获取连接进行查询,每个报表一个线程进行查询。



public DruidDataSource getDataSource(JdbcSourceInfo jdbcSourceInfo) throws SourceException {
/*
省略业务代码
属性获取
*/
String key = getDataSourceKey(jdbcSourceInfo);
DruidDataSource druidDataSource = dataSourceMap.get(key);
if (druidDataSource != null && !druidDataSource.isClosed()) {
return druidDataSource;
}
Lock lock = getDataSourceLock(key);
/********加锁***************/
try {
if (!lock.tryLock(30L, TimeUnit.SECONDS)) {
druidDataSource = dataSourceMap.get(key);
/******************双重校验******************/
if (druidDataSource != null && !druidDataSource.isClosed()) {
return druidDataSource;
}
throw new SourceException("Unable to get datasource for jdbcUrl: " + jdbcUrl);
}
} catch (InterruptedException e) {
throw new SourceException("Unable to get datasource for jdbcUrl: " + jdbcUrl);
}
druidDataSource = dataSourceMap.get(key);
/******************双重校验******************/
if (druidDataSource != null && !druidDataSource.isClosed()) {
lock.unlock();
return druidDataSource;
}
druidDataSource = new DruidDataSource();
try {
if (StringUtils.isEmpty(dbVersion) ||
!ext || JDBC_DATASOURCE_DEFAULT_VERSION.equals(dbVersion)) {
String className = SourceUtils.getDriverClassName(jdbcUrl, null);
try {
Class.forName(className);
} catch (ClassNotFoundException e) {
throw new SourceException("Unable to get driver instance for jdbcUrl: " + jdbcUrl);
}
druidDataSource.setDriverClassName(className);
} else {
druidDataSource.setDriverClassName(CustomDataSourceUtils.getInstance(jdbcUrl, dbVersion).getDriver());
String path = System.getenv("DAVINCI3_HOME") + File.separator + String.format(Consts.PATH_EXT_FORMATTER, jdbcSourceInfo.getDatabase(), dbVersion);
druidDataSource.setDriverClassLoader(ExtendedJdbcClassLoader.getExtJdbcClassLoader(path));
}
/************省略业务属性的set代码************/
druidDataSource.setRemoveAbandonedTimeout(3600 + 5 * 60);
druidDataSource.setLogAbandoned(true);
druidDataSource.setConnectProperties(properties);
try {
druidDataSource.setFilters(filters);
druidDataSource.init();
log.info("init datasource success ,sourceKey:{}", key);
} catch (Exception e) {
log.error("Exception during pool initialization", e);
throw new SourceException(e.getMessage());
}
dataSourceMap.put(key, druidDataSource);
} finally {
lock.unlock();
}
return druidDataSource;
}
直接查看代码,经过分析,虽然是多线程的,但是看的时候也只能看到设计的还是比较精妙,且每次使用多线程都会严谨的双重校验,理论上是不会出现问题的。
2 想到虽然连接池可以控制每个池中连接数,会不会连接池本身没有控制住,这样的话,多个连接池,也是会导致连接数超级多的。又想起了Druid具有自带的监控页面,于是百度了一下如何访问,通过查看Druid监控页面,证实了自己的想法。

3 继续分析代码,发现创建连接池的地方和释放连接池的地方貌似没有问题,每次都有锁,且新建成功的理论上都会被释放成功,不应该出现多个连接池的情况。
4 仔细看代码,很多抛出异常的地方其实没做任何处理,那会不会是Druid连接池没有创建成功的,会自己后台重试或者没有释放呢?druid的连接池的监控页面又是怎么查询出来的呢?于是又开始查阅Druid的代码。
这一块的页面寻找是百度到的。因为没有开发过类似的功能,所以不太懂,前后端一个包里,Druid的设计原理,懂得麻烦给讲一下。 
既然涉及前后端交互,我的认知肯定是Ajax请求url,就必然有controller,没想到Druid用的更底层,用的是Servlet,至于为什么这么低层,懂得大神,可以在评论里讲一下。

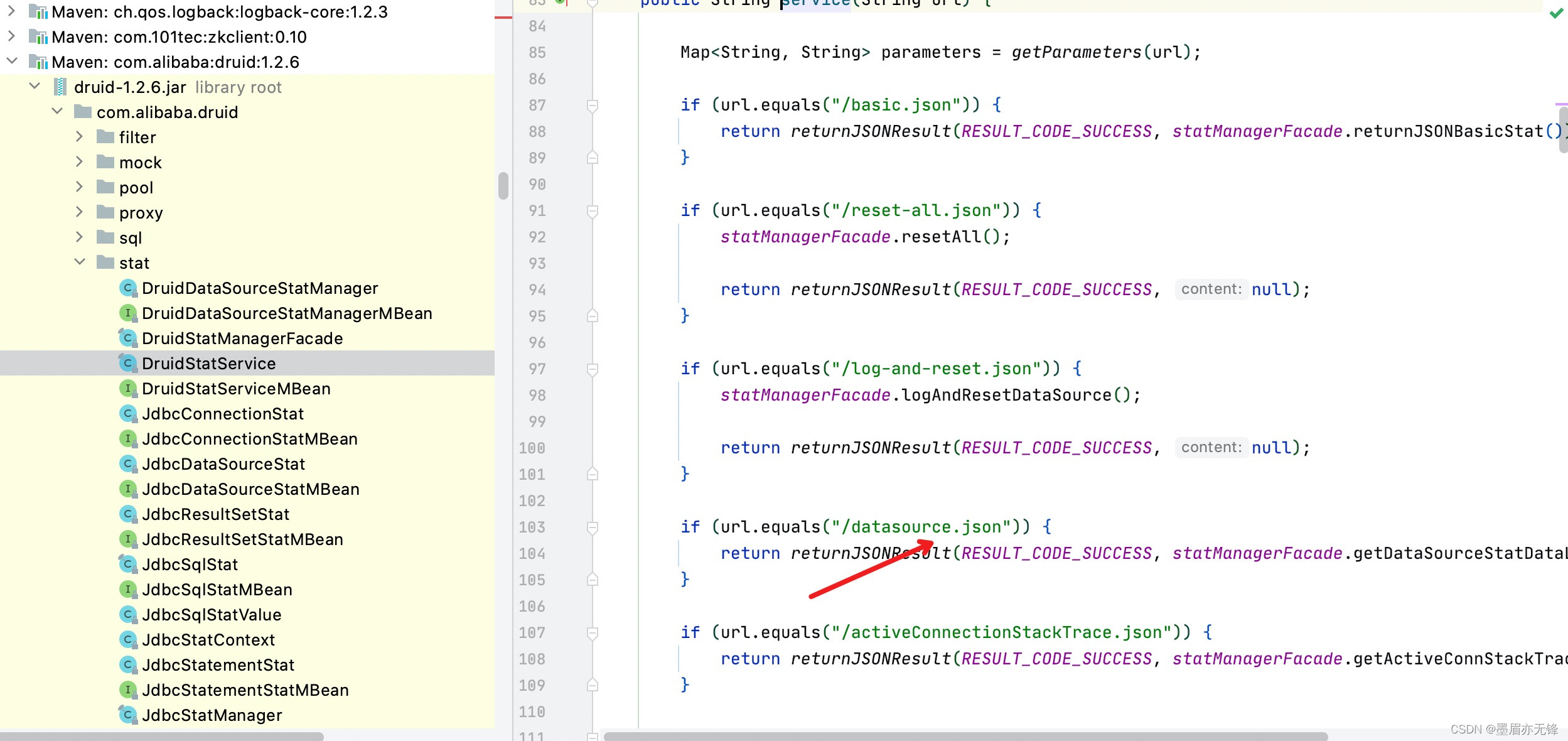

到此找到了监控页面查询的地方,那就继续寻找Druid的合适在这个Manager中注册的。
终于在初始化的代码中找到了,这个方法。

到此终于找到了原因,可能大家已经被绕晕,我刚开始也是非常晕的,后来才梳理明白,
在获取链接的地方,大家可以看到有个三次重试,获取不到就返回,然后没有连接没有获取到,就会释放连接池,然后重建连接池,获取链接。问题就出在这里。
因为刚开始数据库连接被其他的应用完全占用,我们的Davinci获取不到连接,就会报错,druid在后台还会继续尝试,多余的线程会排队等待连接,超时的时候获取不到,就会拿到null ,就会触发重建数据池。
重建数据池后,在初始化的时候会失败,但是registerMbean会执行,又因为代码中初始化失败手,仅是抛出异常,却没有进行关闭,

导致监控页面可以查到,而且这些初始化的池应该后台还会重试,导致连接就处于丢失了,并没有纳入我们的map进行管理。又因为最小连接是1 ,所以这个池会一直等着别人连接他,但是又不会连接,就导致泄漏了,这个地方增加一行代码 
就好了。
到此为止,终于解决了这个问题,历经4 -5 天,但至于为什么初始化失败的连接池还是会占用连接,这个一块还待验证,由于没时间继续读Druid的代码,后续会继续跟进,找到原因。也希望有Druid大神,能给出指导。














 789
789











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









