







XINCHECK SDK是一个提供了文本查重引擎和文本查重算法的java包,使用它可以快速开发涉及文本查重相关的功能。比如标书查重、论文查重、文档查重、作业查重之类的。
也有基于这个sdk开发的桌面端软件,我这边也进行了试用。可以看这个链接XINCheck桌面端使用介绍
好了废话不多说,下面简单介绍一下SDK的使用方式
一、引入查重SDK
通过maven将本SDK 0.5.0版本引入到项目中
XINCHECK SDK需要使用1.8.0_151及以上版本的JDK,如JDK低于此版本,需要修改JDK加密策略文件或升级JDK。
SDK存放在私有maven仓库中,需要先在<repositories>中添加以下仓库
<repository>
<id>XINCHECK</id>
<name>XINCHECK Public Repository</name>
<url>https://maven.xincheck.com/repository/maven-releases/</url>
</repository>
然后在<dependencies>中添加依赖
<dependency>
<groupId>com.xincheck</groupId>
<artifactId>duplicate-check</artifactId>
<version>0.5.10</version>
</dependency>
除maven外同样支持Gradle、lvy等,修改对应引入语法即可。
二、授权SDK
非商业用户可以申请免费的许可证,需要先调用下面的方法获取并打印服务器或PC机的机器指纹
System.out.println(CheckManager.INSTANCE.getMachineCode());
访问获取免费版授权页面获取授权许可证
然后再拿获取到的免费授权对SDK进行授权
CheckManager.INSTANCE.setRegCode("授权许可证");
三、使用简易启动器开始查重
SDK内置了简易启动器EasyStarter,一行代码即可完成SDK调用。参数介绍如下
参数1:待查文件所在的文件夹路径(如果待查文件只有一个,可以传文件路径);
参数2:比对库文件所在的文件夹路径(如果比对库中只有一个文件,可以传文件路径);
参数3:保存查重报告的文件夹路径。如果不需要导出查重报告可以传空字符串;
参数4:白名单文本。对于标书查重等场景,有一些文本是允许重复的,这些文本可以通过该参数传入。该参数可选,如不需要可以不传或传null。
List<Reporter> reporters = EasyStarter.check(new File("参数1"), new File("参数2"), "参数3", "参数4");
横向查重应用场景下参数1和参数2可以相同,相同的文件会自动跳过比对,不会出现重复率100%的问题。除示例方法外,该方法还有多个重载,具体可以自行了解,如需详细了解。
完整示例代码可参见GitHub链接中的EasyStart部分。
四、查重结果
查重完毕后可以保存如下样式的html查重报告,部分样式可以通过接口自定义:


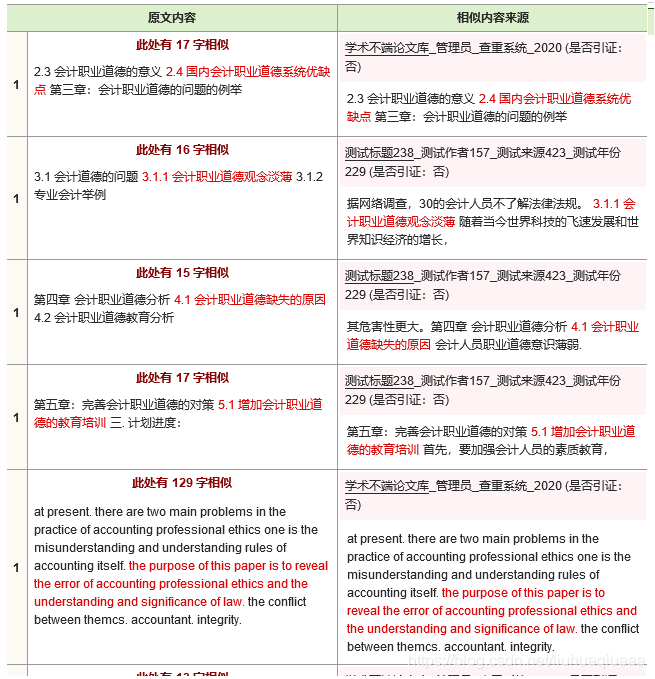
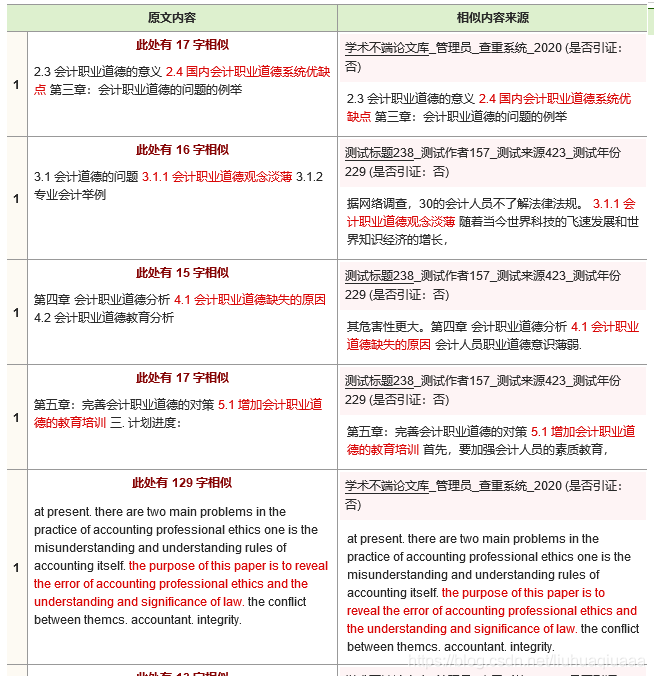
五、详细开发文档
EasyStarter只适用于逻辑简单、数据量少、无异步执行需求的应用场景,其中大量参数使用了默认值。实际项目开发过程中,对于复杂的应用场景,可以查阅完整的开发者接入文档,使用原生方式进行调用:开发者接入文档
五、付费?
XINCheck有付费版本可以购买,具体价格参加它的网站上的报价表。不过个人使用的话其实使用免费版就足够了,虽然免费版只支持8000字以下下的文本查重,但是超过8000字的可以拆分成多个文件进行查重也是一样的。报价表链接。

















 838
838

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









