






公司的新项目,用的人人开源,吐槽一下(这个框架对于二次开发一点都不友好)。
客户要求用户可以针对每个页面的表格中的列做自定义显示、显示顺序、查询时默认排序,并且保存成方案。
系统使用SpringBoot加mybatis-puls,看得出来,人人开源想对mybatis-puls做一个二次封装,但是这个二次封装好像不管是对于二次开发还是使用效率都不友好。
废话说完了,开始上逻辑:
第一做表设计,逻辑不是特别复杂,两到三个表就可以实现,我怕后期甲方会出什么幺蛾子,所以整了三张表
直接上截图感觉更好理解一些,这是用户跟方案关系表
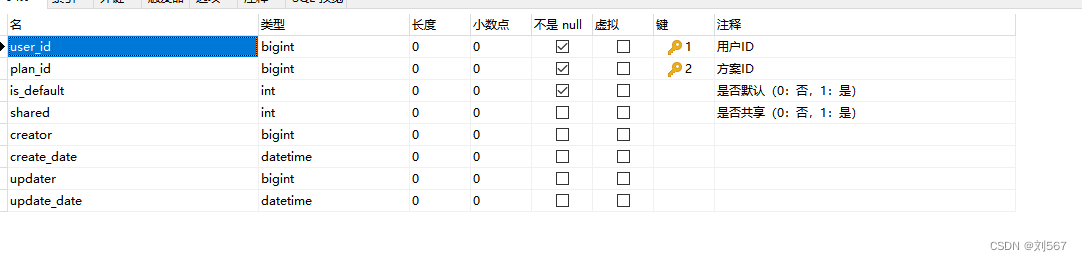
这是方案与table的关系表
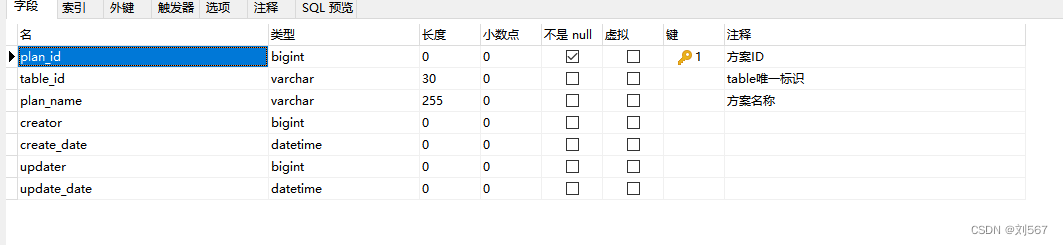
这是方案与其中的列关系表
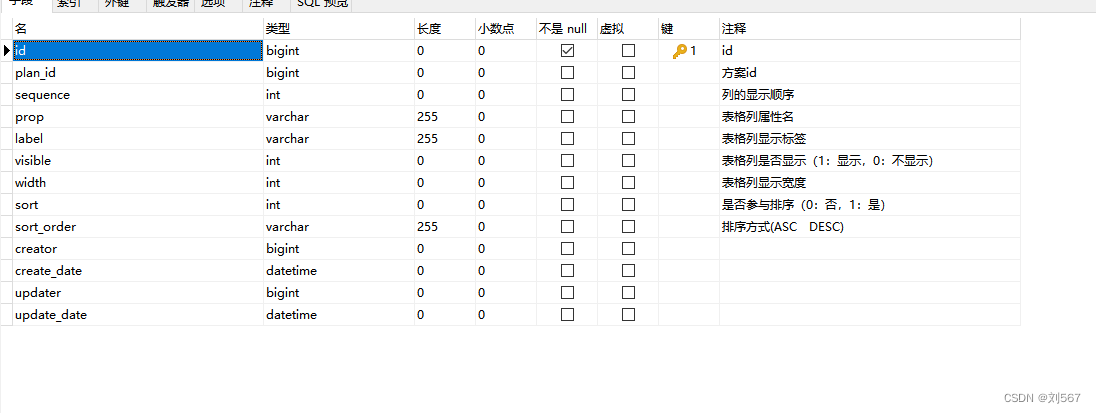
前端设置好了,我负责给他保存就好了,然后因为这个系统用户比较少也就百十号人,每个人的默认方案会放在redis里面存着。
分页跟排序用的是mybatis-plus自带的
首先创建一个公共的DTO父类
@Data
public abstract class BaseDTO implements Serializable {
@ApiModelProperty(value = "当前页码")
private Integer page;
@ApiModelProperty(value = "每页显示记录数")
private Integer limit;
@ApiModelProperty(value = "排序")
private List<OrderItem> orderItems;
}OrderItem用的MP的排序类

然后确保每个接口的接收参数都继承BaseDTO
创建排序的注解
/**
* 自定义排序使用,如果类上面没有注解,那么表示这个DTO是单表查询
*/
@Target({ElementType.FIELD, ElementType.TYPE})
@Retention(RetentionPolicy.RUNTIME)
@Documented
public @interface SortOfQuery {
/**
* 字段在SQL里对应的表的名称或者别名,有别名必须写别名
* 如果在类上表示该SQL的主表的名称或者别名
*/
String name();
/**
* 数据库字段值
* 如果数据库字段跟DTO的对应属性不是下划线转大小写的格式,则需要标记出该属性对应的数据库字段
*/
String value() default "";
}DTO上面用加上注解:
@EqualsAndHashCode(callSuper = true)
@Data
@SortOfQuery(name = "fl")
public class FileListDTO extends BaseDTO {
@SortOfQuery(name = "zas")
private String auditNo;
@SortOfQuery(name = "an")
private Integer documentsType;
private String formType;
}对应的SQL示例:
SELECT
fl.form_type AS formType,
an.documents_type AS documentsType,
zas.audit_no AS auditNo
FROM file_list fl
LEFT JOIN notice an ON fl.number = an.audit_notice_no
LEFT JOIN audit_start zas ON an.audit_start_no = zas.audit_start_no在 CrudServiceImpl公共的实现类里处理公共的逻辑
public abstract class CrudServiceImpl<M extends BaseMapper<T>, T, D> extends BaseServiceImpl<M, T> implements CrudService<T, D> {
protected Class<D> currentDtoClass() {
return (Class<D>) ReflectionKit.getSuperClassGenericType(getClass(), CrudServiceImpl.class, 2);
}
protected Class<T> currentEntityClass() {
return (Class<T>) ReflectionKit.getSuperClassGenericType(getClass(), CrudServiceImpl.class, 2);
}
@Override
public PageData<D> page(Map<String, Object> params) {
IPage<T> page = baseDao.selectPage(
getPage(params, null, false),
getWrapper(params)
);
return getPageData(page, currentDtoClass());
}
@Override
public PageData<D> getListByMoreTable(D params) {
IPage<T> page1 = getPage(params);
IPage<D> listOrder = getListOrderByMoreTable(params, page1);
return getPageData(listOrder, currentDtoClass());
}
public IPage<D> getListOrderByMoreTable(D params, IPage<T> page) {
return null;
}
@Override
public PageData<D> getList(D params) {
IPage<T> page1 = getPage(params);
IPage<D> listOrder = getListOrder(params, page1);
return getPageData(listOrder, currentDtoClass());
}
public IPage<D> getListOrder(D params, IPage<T> page) {
return null;
}
protected IPage<T> getPage(D params) {
BaseDTO baseDTO = (BaseDTO) params;
//分页参数
long curPage = 1;
long limit = 10;
if (baseDTO.getPage() != null) {
curPage = baseDTO.getPage();
}
if (baseDTO.getLimit() != null) {
limit = baseDTO.getLimit();
}
//分页对象
Page<T> page = new Page<>(curPage, limit);
List<OrderItem> orderList = baseDTO.getOrderItems();
if (orderList == null || orderList.size() == 0) {
return page;
}
page.addOrder(getOrderItems(orderList, currentEntityClass(), currentDtoClass()));
return page;
}
private List<OrderItem> getOrderItems(List<OrderItem> orderItems, Class<T> currentEntityClass, Class<D> dtoClass) {
List<Field> allFields = new ArrayList<>();
Map<String, Boolean> map = new HashMap<>();
allFields.addAll(Arrays.asList(currentEntityClass.getDeclaredFields()));
allFields.addAll(Arrays.asList(currentEntityClass.getSuperclass().getDeclaredFields()));
for (OrderItem orderItem : orderItems) {
map.put(orderItem.getColumn(), orderItem.isAsc());
}
//获取类上面的注解
SortOfQuery annotation = dtoClass.getAnnotation(SortOfQuery.class);
if (annotation != null) {
List<Field> dtoFields = new ArrayList<>(Arrays.asList(dtoClass.getDeclaredFields()));
return getTableFieldByMoreTable(map, dtoFields, annotation, dtoClass);
}
return getTableField(map, allFields);
}
/**
* 多表联查排序使用
*/
private List<OrderItem> getTableFieldByMoreTable(Map<String, Boolean> map, List<Field> allFields, SortOfQuery classAnnotation, Class<D> dtoClass) {
String name2 = classAnnotation.name();//获取主表的别名
ArrayList<OrderItem> orderItems1 = new ArrayList<>();//需要返回的
for (Field allField : allFields) {//遍历所有的列
String name1 = allField.getName();//获取属性名称
Boolean asc = map.get(name1);
OrderItem orderItem = new OrderItem();
SortOfQuery sortOfQuery = allField.getAnnotation(SortOfQuery.class);//获取属性上面的排序注解
if (asc != null) {
if (sortOfQuery == null) {
//如果属性上没有注解,那么就用类上的注解
String s = humpToUnderline(name1);//获取到属性名字大写转下划线之后的名字
orderItem.setColumn(name2 + "." + s);
orderItem.setAsc(asc);
orderItems1.add(orderItem);
} else {
//如果属性上有排序注解,那么优先用属性上的
String value = sortOfQuery.value();//获取属性对应数据库里的列名
String name = sortOfQuery.name();//获取该属性对应SQL里的表别名
if ("".equals(value)) {
//这个字段是按照下划线转大小写的方式转换
String s = humpToUnderline(name1);//获取到属性名字大写转下划线之后的名字
orderItem.setColumn(name + "." + s);
orderItem.setAsc(asc);
orderItems1.add(orderItem);
} else {
orderItem.setColumn(name + "." + value);
orderItem.setAsc(asc);
orderItems1.add(orderItem);
}
}
}
}
return orderItems1;
}
/**
* 单表查询排序使用
*/
private ArrayList<OrderItem> getTableField(Map<String, Boolean> map, List<Field> allFields) {
ArrayList<OrderItem> orderItems1 = new ArrayList<>();
for (Field allField : allFields) {
if (allField.isAnnotationPresent(TableField.class)) {
TableField annotation = allField.getAnnotation(TableField.class);
//如果注解value属性是空的,则走大写转下划线
String value = annotation.value();
Boolean aBoolean;
String s;
if (StringUtils.isAllEmpty(value)) {
s = humpToUnderline(value);
aBoolean = map.get(value);
} else {
s = value;
aBoolean = map.get(value);
}
if (aBoolean != null) {
OrderItem orderItem = new OrderItem();
orderItem.setColumn(value);
orderItem.setAsc(aBoolean);
orderItems1.add(orderItem);
}
} else {
String name = allField.getName();
String s = humpToUnderline(name);
Boolean aBoolean = map.get(name);
if (aBoolean != null) {
OrderItem orderItem = new OrderItem();
orderItem.setColumn(s);
orderItem.setAsc(aBoolean);
orderItems1.add(orderItem);
}
}
}
return orderItems1;
}
/**
* 驼峰转下划线
*
* @param str 目标字符串
* @return: java.lang.String
*/
public static String humpToUnderline(String str) {
String regex = "([A-Z])";
Matcher matcher = Pattern.compile(regex).matcher(str);
while (matcher.find()) {
String target = matcher.group();
str = str.replaceAll(target, "_" + target.toLowerCase());
}
return str;
}
}无关紧要的代码都删掉了
主要逻辑就是通过反射获取DTO,获取类上面的自定义注解,然后把DTO的属性跟前端传过来的需要排序的字段对比,在DTO里面的就大写转下划线,前面拼上从注解获取的表别名,就OK了,可能描述的不好,大家有问题可以直接讨论哈















 238
238











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









