







在这一节我们主要是对支持向量机进行系统的回顾,以及通过Python来实现。由于内容很多,所以这里分成三篇博文。第一篇讲SVM初级,第二篇讲进阶,主要是把SVM整条知识链理直,第三篇介绍Python的实现。SVM有很多介绍的非常好的博文,具体可以参考本文列出的参考文献和推荐阅读资料。在本文中,定位在于把集大成于一身的SVM的整体知识链理直,所以不会涉及细节的推导。网上的解说的很好的推导和书籍很多,大家可以进一步参考。
目录
一、引入
二、线性可分SVM与硬间隔最大化
三、Dual优化问题
3.1、对偶问题
3.2、SVM优化的对偶问题
四、松弛向量与软间隔最大化
五、核函数
六、多类分类之SVM
6.1、“一对多”的方法
6.2、“一对一”的方法
七、KKT条件分析
八、SVM的实现之SMO算法
8.1、坐标下降算法
8.2、SMO算法原理
8.3、SMO算法的Python实现
九、参考文献与推荐阅读
一、引入
支持向量机(SupportVector Machines),这个名字可是响当当的,在机器学习或者模式识别领域可是无人不知,无人不晓啊。八九十年代的时候,和神经网络一决雌雄,独领风骚,并吸引了大批为之狂热和追随的粉丝。虽然几十年过去了,但风采不减当年,在模式识别领域依然占据着大遍江山。王位稳固了几十年。当然了,它也繁衍了很多子子孙孙,出现了很多基因改良的版本,也发展了不少裙带关系。但其中的睿智依然被世人称道,并将千秋万代!
好了,买了那么久广告,不知道是不是高估了。我们还是脚踏实地,来看看传说的SVM是个什么东西吧。我们知道,分类的目的是学会一个分类函数或分类模型(或者叫做分类器),该模型能把数据库中的数据项映射到给定类别中的某一个,从而可以用于预测未知类别。对于用于分类的支持向量机,它是个二分类的分类模型。也就是说,给定一个包含正例和反例(正样本点和负样本点)的样本集合,支持向量机的目的是寻找一个超平面来对样本进行分割,把样本中的正例和反例用超平面分开,但是不是简单地分看,其原则是使正例和反例之间的间隔最大。学习的目标是在特征空间中找到一个分类超平面wx+b=0,分类面由法向量w和截距b决定。分类超平面将特征空间划分两部分,一部分是正类,一部分是负类。法向量指向的一侧是正类,另一侧为负类。
用一个二维空间里仅有两类样本的分类问题来举个小例子。假设我们给定了下图左图所示的两类点Class1和Class2(也就是正样本集和负样本集)。我们的任务是要找到一个线,把他们划分开。你会告诉我,那简单,挥笔一画,洋洋洒洒五颜六色的线就出来了,然后很得意的和我说,看看吧,下面右图,都是你要的答案,如果你还想要,我还可以给你画出无数条。对,没错,的确可以画出无数条。那哪条最好呢?你会问我,怎么样衡量“好”?假设Class1和Class2分别是两条村子的人,他们因为两条村子之间的地盘分割的事闹僵了,叫你去说个理,到底怎么划分才是最公平的。这里的“好”,可以理解为对Class1和Class2都是公平的。然后你二话不说,指着黑色那条线,说“就它了!正常人都知道!在两条村子最中间画条线很明显对他们就是公平的,谁也别想多,谁也没拿少”。这个例子可能不太恰当,但道理还是一样的。对于分类来说,我们需要确定一个分类的线,如果新的一个样本到来,如果落在线的左边,那么这个样本就归为class1类,如果落在线的右边,就归为class2这一类。那哪条线才是最好的呢?我们仍然认为是中间的那条,因为这样,对新的样本的划分结果我们才认为最可信,那这里的“好”就是可信了。另外,在二维空间,分类的就是线,如果是三维的,分类的就是面了,更高维,也有个霸气的名字叫超平面。因为它霸气,所以一般将任何维的分类边界都统称为超平面。
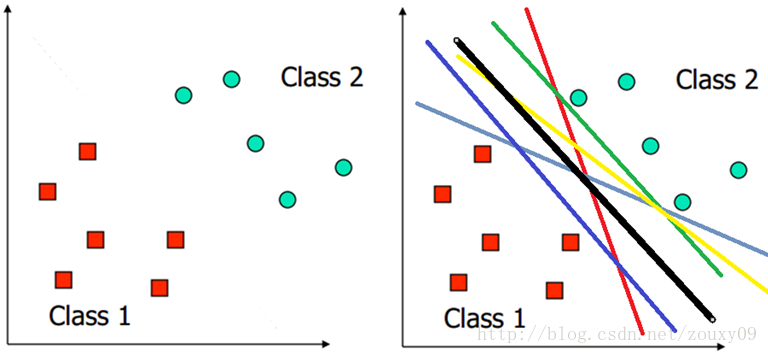
好了。对于人来说,我们可以轻易的找到这条线或者超平面(当然了,那是因为你可以看到样本具体的分布是怎样的,如果样本的维度大于三维的话,我们就没办法把这些样本像上面的图一样画出来了,这时候就看不到了,这时候靠人的双眼也无能为力了。“如果我能看得见,生命也许完全不同,可能我想要的,我喜欢的我爱的,都不一样……”),但计算机怎么知道怎么找到这条线呢?我们怎么把我们的找这条线的方法告诉他,让他按照我们的方法来找到这条线呢?呃,我们要建模!!!把我们的意识“强加”给计算机的某个数学模型,让他去求解这个模型,得到某个解,这个解就是我们的这条线,那这样目的就达到了。那下面就得开始建模之旅了。
二、线性可分SVM与硬间隔最大化
其实上面这种分类思想就是SVM的思想。可以表达为:SVM试图寻找一个超平面来对样本进行分割,把样本中的正例和反例用超平面分开,但是不是很敷衍地简单的分开,而是尽最大的努力使正例和反例之间的间隔margin最大。这样它的分类结果才更加可信,而且对于未知的新样本才有很好的分类预测能力(机器学习美其名曰泛化能力)。
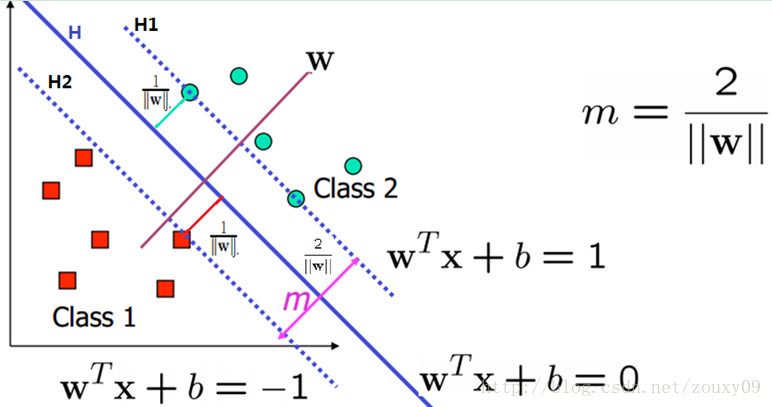
我们的目标是寻找一个超平面,使得离超平面比较近的点能有更大的间距。也就是我们不考虑所有的点都必须远离超平面,我们关心求得的超平面能够让所有点中离它最近的点具有最大间距。
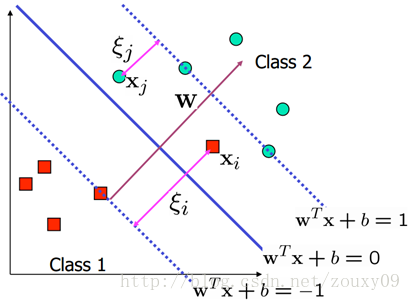
我们先用数学公式来描述下。假设我们有N个训练样本{(x1, y1),(x2, y2), …, (xN, yN)},x是d维向量,而yi∊{+1, -1}是样本的标签,分别代表两个不同的类。这里我们需要用这些样本去训练学习一个线性分类器(超平面):f(x)=sgn(wTx + b),也就是wTx + b大于0的时候,输出+1,小于0的时候,输出-1。sgn()表示取符号。而g(x) =wTx + b=0就是我们要寻找的分类超平面,如上图所示。刚才说我们要怎么做了?我们需要这个超平面最大的分隔这两类。也就是这个分类面到这两个类的最近的那个样本的距离相同,而且最大。为了更好的说明,我们在上图中找到两个和这个超平面平行和距离相等的超平面:H1: y = wTx + b=+1 和 H2: y = wTx + b=-1。
好了,这时候我们就需要两个条件:(1)没有任何样本在这两个平面之间;(2)这两个平面的距离需要最大。(对任何的H1和H2,我们都可以归一化系数向量w,这样就可以得到H1和H2表达式的右边分别是+1和-1了)。先来看条件(2)。我们需要最大化这个距离,所以就存在一些样本处于这两条线上,他们叫支持向量(后面会说到他们的重要性)。那么它的距离是什么呢?我们初中就学过,两条平行线的距离的求法,例如ax+by=c1和ax+by=c2,那他们的距离是|c2-c1|/sqrt(x2+y2)(sqrt()表示开根号)。注意的是,这里的x和y都表示二维坐标。而用w来表示就是H1:w1x1+w2x2=+1和H2:w1x1+w2x2=-1,那H1和H2的距离就是|1+1|/ sqrt(w12+w12)=2/||w||。也就是w的模的倒数的两倍。也就是说,我们需要最大化margin=2/||w||,为了最大化这个距离,我们应该最小化||w||,看起来好简单哦。同时我们还需要满足条件(2),也就是同时要满足没有数据点分布在H1和H2之间:
也就是,对于任何一个正样本yi=+1,它都要处于H1的右边,也就是要保证:y= wTx + b>=+1。对于任何一个负样本yi=-1,它都要处于H2的左边,也就是要保证:y = wTx + b<=-1。这两个约束,其实可以合并成同一个式子:yi (wTxi + b)>=1。
所以我们的问题就变成:
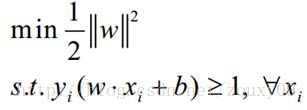
这是个凸二次规划问题。什么叫凸?凸集是指有这么一个点的集合,其中任取两个点连一条直线,这条线上的点仍然在这个集合内部,因此说“凸”是很形象的。例如下图,对于凸函数(在数学表示上,满足约束条件是仿射函数,也就是线性的Ax+b的形式)来说,局部最优就是全局最优,但对非凸函数来说就不是了。二次表示目标函数是自变量的二次函数。

好了,既然是凸二次规划问题,就可以通过一些现成的 QP (Quadratic Programming) 的优化工具来得到最优解。所以,我们的问题到此为止就算全部解决了。虽然这个问题确实是一个标准的 QP 问题,但是它也有它的特殊结构,通过 Lagrange Duality 变换到对偶变量 (dual variable) 的优化问题之后,可以找到一种更加有效的方法来进行求解,而且通常情况下这种方法比直接使用通用的 QP 优化包进行优化要高效得多。也就说,除了用解决QP问题的常规方法之外,还可以应用拉格朗日对偶性,通过求解对偶问题得到最优解,这就是线性可分条件下支持向量机的对偶算法,这样做的优点在于:一是对偶问题往往更容易求解;二者可以自然的引入核函数,进而推广到非线性分类问题。那什么是对偶问题?
三、Dual优化问题
3.1、对偶问题
在约束最优化问题中,常常利用拉格朗日对偶性将原始问题转换为对偶问题,通过求解对偶问题而得到原始问题的解。至于这其中的原理和推导参考文献[3]讲得非常好。大家可以参考下。这里只将对偶问题是怎么操作的。假设我们的优化问题是:
min f(x)
s.t. hi(x) = 0, i=1, 2, …,n
这是个带等式约束的优化问题。我们引入拉格朗日乘子,得到拉格朗日函数为:
L(x, α)=f(x)+α1h1(x)+ α2h2(x)+…+αnhn(x)
然后我们将拉格朗日函数对x求极值,也就是对x求导,导数为0,就可以得到α关于x的函数,然后再代入拉格朗日函数就变成:
max W(α) = L(x(α), α)
这时候,带等式约束的优化问题就变成只有一个变量α(多个约束条件就是向量)的优化问题,这时候的求解就很简单了。同样是求导另其等于0,解出α即可。需要注意的是,我们把原始的问题叫做primal problem,转换后的形式叫做dual problem。需要注意的是,原始问题是最小化,转化为对偶问题后就变成了求最大值了。对于不等式约束,其实是同样的操作。简单地来说,通过给每一个约束条件加上一个 Lagrange multiplier(拉格朗日乘子),我们可以将约束条件融和到目标函数里去,这样求解优化问题就会更加容易。(这里其实涉及到很多蛮有趣的东西的,大家可以参考更多的博文)
3.2、SVM优化的对偶问题
对于SVM,前面提到,其primal problem是以下形式:
同样的方法引入拉格朗日乘子,我们就可以得到以下拉格朗日函数:
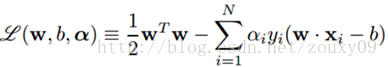
然后对L(w, b, α)分别求w和b的极值。也就是L(w, b,α)对w和b的梯度为0:∂L/∂w=0和∂L/∂b=0,还需要满足α>=0。求解这里导数为0的式子可以得到:
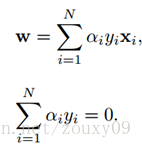
然后再代入拉格朗日函数后,就变成:
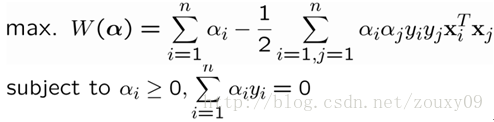
这个就是dual problem(如果我们知道α,我们就知道了w。反过来,如果我们知道w,也可以知道α)。这时候我们就变成了求对α的极大,即是关于对偶变量α的优化问题(没有了变量w,b,只有α)。当求解得到最优的α*后,就可以同样代入到上面的公式,导出w*和b*了,最终得出分离超平面和分类决策函数。也就是训练好了SVM。那来一个新的样本x后,就可以这样分类了:
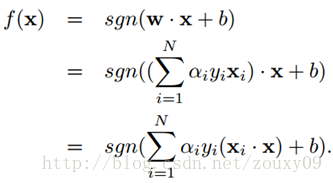
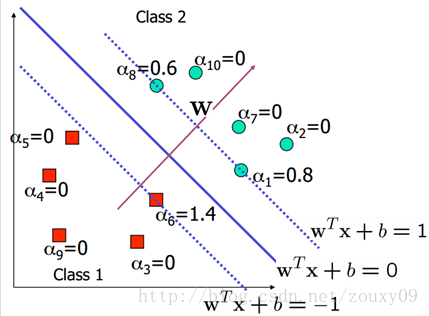
在这里,其实很多的αi都是0,也就是说w只是一些少量样本的线性加权值。这种“稀疏”的表示实际上看成是KNN的数据压缩的版本。也就是说,以后新来的要分类的样本首先根据w和b做一次线性运算,然后看求的结果是大于0还是小于0来判断正例还是负例。现在有了αi,我们不需要求出w,只需将新来的样本和训练数据中的所有样本做内积和即可。那有人会说,与前面所有的样本都做运算是不是太耗时了?其实不然,我们从KKT条件中得到,只有支持向量的αi不为0,其他情况αi都是0。因此,我们只需求新来的样本和支持向量的内积,然后运算即可。这种写法为下面要提到的核函数(kernel)做了很好的铺垫。如下图所示:
四、松弛向量与软间隔最大化
我们之前讨论的情况都是建立在样本的分布比较优雅和线性可分的假设上,在这种情况下可以找到近乎完美的超平面对两类样本进行分离。但如果遇到下面这两种情况呢?左图,负类的一个样本点A不太合群,跑到正类这边了,这时候如果按上面的确定分类面的方法,那么就会得到左图中红色这条分类边界,嗯,看起来不太爽,好像全世界都在将就A一样。还有就是遇到右图的这种情况。正类的一个点和负类的一个点都跑到了别人家门口,这时候就找不到一条直线来将他们分开了,那这时候怎么办呢?我们真的要对这些零丁的不太听话的离群点屈服和将就吗?就因为他们的不完美改变我们原来完美的分界面会不会得不偿失呢?但又不得不考虑他们,那怎样才能折中呢?
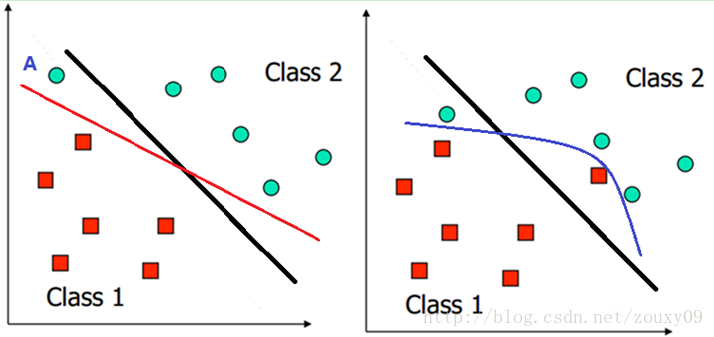
对于上面说的这种偏离正常位置很远的数据点,我们称之为 outlier,它有可能是采集训练样本的时候的噪声,也有可能是某个标数据的大叔打瞌睡标错了,把正样本标成负样本了。那一般来说,如果我们直接忽略它,原来的分隔超平面还是挺好的,但是由于这个 outlier 的出现,导致分隔超平面不得不被挤歪了,同时 margin 也相应变小了。当然,更严重的情况是,如果出现右图的这种outlier,我们将无法构造出能将数据线性分开的超平面来。
为了处理这种情况,我们允许数据点在一定程度上偏离超平面。也就是允许一些点跑到H1和H2之间,也就是他们到分类面的间隔会小于1。如下图:
具体来说,原来的约束条件就变为:
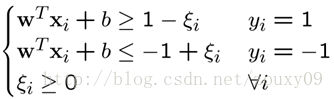
这时候,我们在目标函数里面增加一个惩罚项,新的模型就变成(也称软间隔):
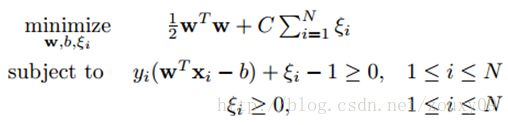
引入非负参数ξi后(称为松弛变量),就允许某些样本点的函数间隔小于1,即在最大间隔区间里面,或者函数间隔是负数,即样本点在对方的区域中。而放松限制条件后,我们需要重新调整目标函数,以对离群点进行处罚,目标函数后面加上的第二项就表示离群点越多,目标函数值越大,而我们要求的是尽可能小的目标函数值。这里的C是离群点的权重,C越大表明离群点对目标函数影响越大,也就是越不希望看到离群点。这时候,间隔也会很小。我们看到,目标函数控制了离群点的数目和程度,使大部分样本点仍然遵守限制条件。
这时候,经过同样的推导过程,我们的对偶优化问题变成:
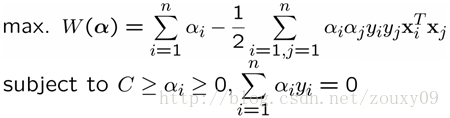
此时,我们发现没有了参数ξi,与之前模型唯一不同在于αi又多了αi<=C的限制条件。需要提醒的是,b的求值公式也发生了改变,改变结果在SMO算法里面介绍。















 1929
1929

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









