







背景:
频繁项集挖掘算法用于挖掘经常一起出现的item集合(称为频繁项集),通过挖掘出这些频繁项集,当在一个事务中出现频繁项集的其中一个item,则可以把该频繁项集的其他item作为
推荐。比如经典的购物篮分析中啤酒、尿布故事,啤酒和尿布经常在用户的购物篮中一起出现,通过挖掘出啤酒、尿布这个啤酒项集,则当一个用户买了啤酒的时候可以为他推荐尿布,这样用户购买的可能性会比较大,从而达到组合营销的目的。
常见的频繁项集挖掘算法有两类,一类是Apriori算法,另一类是FPGrowth。Apriori通过不断的构造候选集、筛选候选集挖掘出频繁项集,需要多次扫描原始数据,当原始数据较大时,磁盘I/O次数太多,效率比较低下。FPGrowth算法则只需扫描原始数据两遍,通过FP-tree数据结构对原始数据进行压缩,效率较高。
FPGrowth算法主要分为两个步骤:FP-tree构建、递归挖掘FP-tree。FP-tree构建通过两次数据扫描,将原始数据中的事务压缩到一个FP-tree树,该FP-tree类似于前缀树,相同前缀的路径可以共用,从而达到压缩数据的目的。接着通过FP-tree找出每个item的条件模式基、条件FP-tree,递归的挖掘条件FP-tree得到所有的频繁项集。算法的主要计算瓶颈在FP-tree的递归挖掘上,下面详细介绍FPGrowth算法的主要步骤。
FPGrowth的算法步骤:
- FP-tree构建

-
- 第一遍扫描数据,找出频繁1项集L,按降序排序
- 第二遍扫描数据:
- 对每个transaction,过滤不频繁集合,剩下的频繁项集按L顺序排序
- 把每个transaction的频繁1项集插入到FP-tree中,相同前缀的路径可以共用
- 同时增加一个header table,把FP-tree中相同item连接起来,也是降序排序
==>
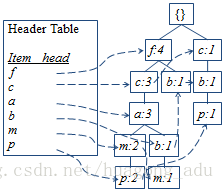
- 频繁项挖掘
-
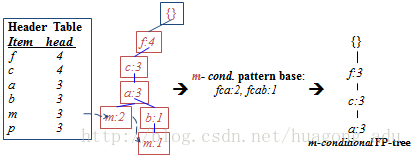
- 从header table的最下面的item开始,构造每个item的条件模式基(conditional pattern base)
- 顺着header table中item的链表,找出所有包含该item的前缀路径,这些前缀路径就是该item的条件模式基(CPB)
- 所有这些CPB的频繁度(计数)为该路径上item的频繁度(计数)
- 如包含p的其中一条路径是fcamp,该路径中p的频繁度为2,则该CPB fcam的频繁度为2
- 构造条件FP-tree(conditional FP-tree)
- FP-Growh:递归的挖掘每个条件FP-tree,累加后缀频繁项集,直到找到FP-tree为空或者FP-tree只有一条路径(只有一条路径情况下,所有路径上item的组合都是频繁项集)
- 从header table的最下面的item开始,构造每个item的条件模式基(conditional pattern base)


注意点:
- FP-Tree中header table按item降序排序原因
-
- 共用前缀:不排序会造成不能共用前缀
- 更多的共用前缀:频繁的item会在树的上层,可以被更多的共享;升序排序会造成那些频繁出现的item出现在树的分支中,不能更多的共用前缀
- 共用前缀:不排序会造成不能共用前缀


参考文献:
-
顶

















 8181
8181

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









