引言
- Fpgrowth算法又叫fp tree,通俗来讲是计算特征之间关联程度的,Fp树是其核心
- FP树(Frequent Pattern Tree)是一种用于高效挖掘频繁项集的数据结构。它通过将事务数据集转换为一棵树形结构来实现,其中每个节点表示一个项,每个路径表示一个事务。
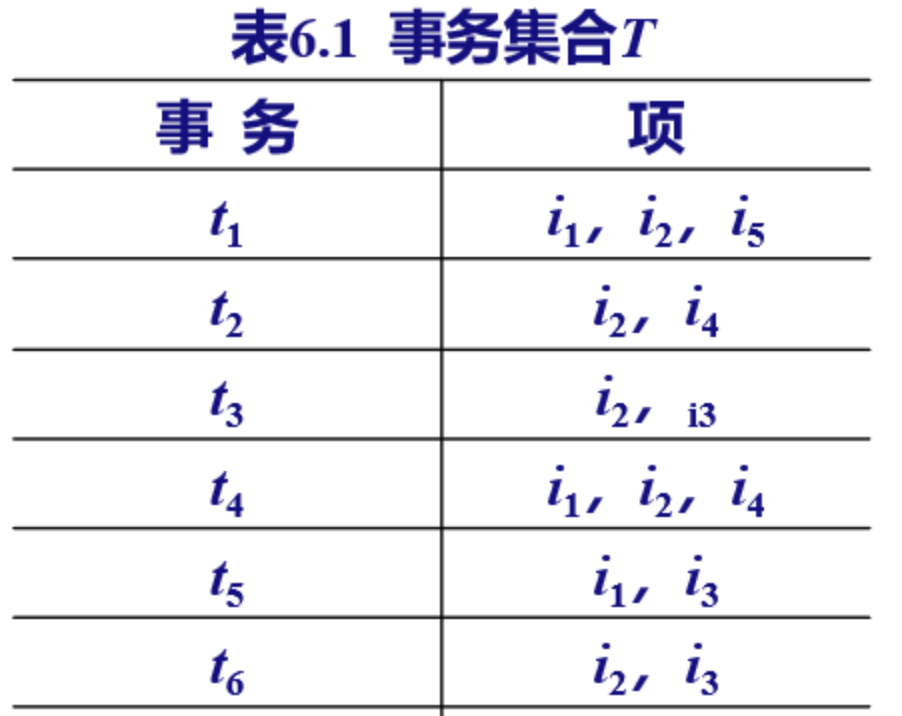
- 如下图,事物就是列,项就是行数据,更通俗的理解就是事物大概对应的就是序号,编号,项就是序号对应的每行数据(如果感觉抽象可以往下看详解时候的例子)
算法详解
基本步骤:
- 1 扫描一次事物集,找出频繁1项集,并按频度降序排列得到列表L。
- 2 基于L,再扫描一次事务集,对每个原事务进行处理:删去不在L中的项,并按照L中的顺序排列,得到修改后的事务集T’。
- 3 构造FP树
- 4 在FP树上递归地找出所有频繁项集
- 注1:左边就是数据,其中a b c d都是表示特征,项就是这些特征的组合; 然后需要找出频繁 1 项集,啥意思呢,通俗解释就是,比如下图中{A:8}集合离只有一个键值对就是 1 项集,几个键值对就是几项集,这个 1 项集其实就是特征在事物中总共出现的次数
- 注2: 得到每个特征的出现次数进行降序排列,并根据支持度(就是特征出现次数/总特证数)筛选不符合支持度的特征得到项头表,也就是 L(可以看到O,I 不满足所以不在 L 中)
- 注3: 根据 L 得到修改后的事物集T‘,其实就是去掉了项特征不在 L 表中的特征
建立 FP Tree
- 此处是理解的一个难点之一,看下图
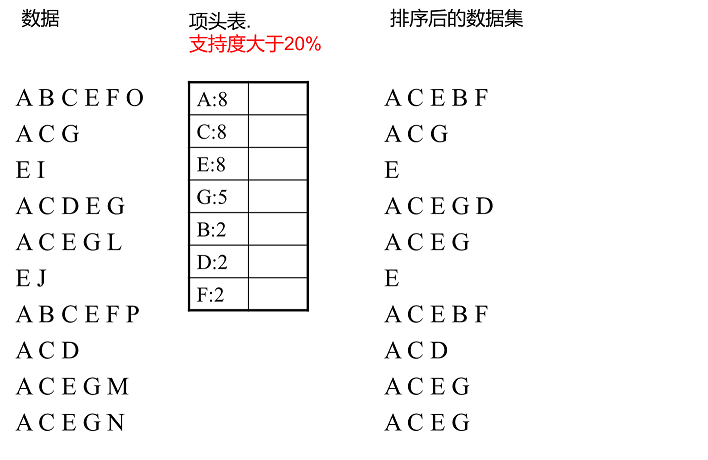
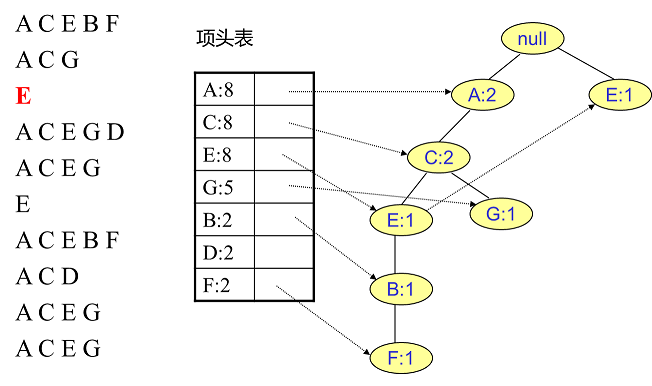
- 首先我们根据 T’还有项头表来建立节点,可以理解成画树的分叉,比如第一条数据 ACEBF(因为 ACEBF 目前都只出现了一次,所以第一条分叉只有一条,此为根节点):
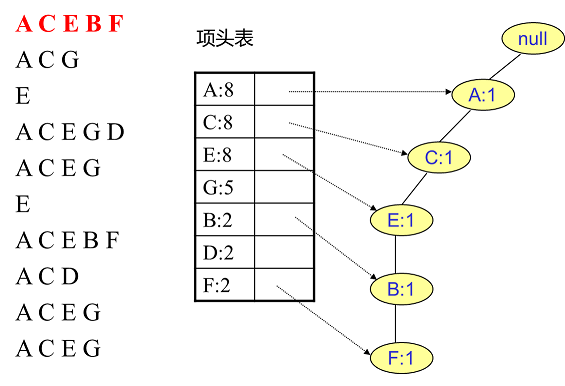
- 然后插入第二条数据 ACG,因为第一条数据中已经有AC项了,所以第一条分支上的 AC都+1,而 G 是没有的,所以建立一个新节点
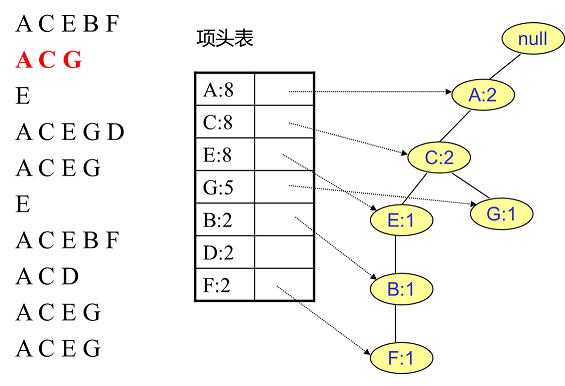
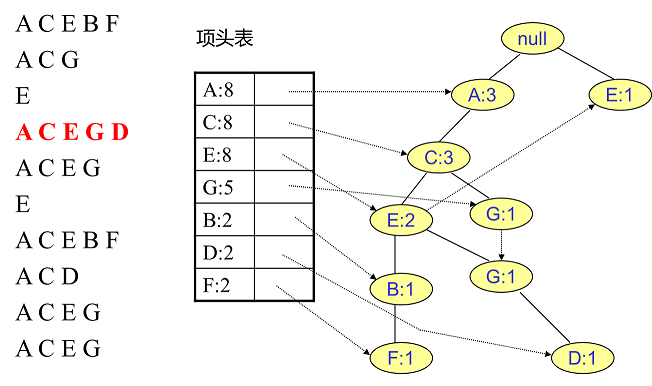
- 同理插入剩余数据(此处详细每条数据插入后的图片可以点击参考资料 1)
…
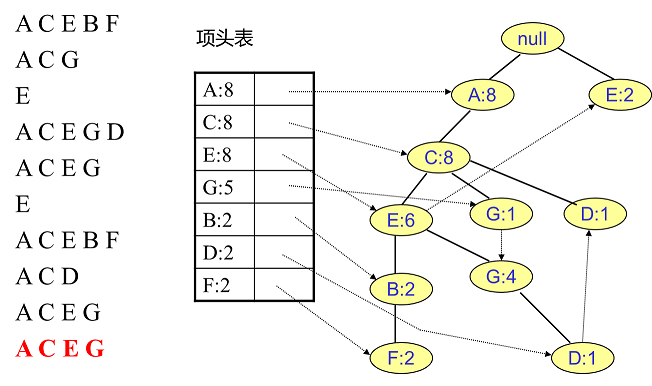
- 最终建立的 Fp 树如下图
FP tree 的挖掘
- 建立好 fp tree 后就该挖掘频繁项集了,此处也是一个难点,或者说是比较容易一头雾水的地方
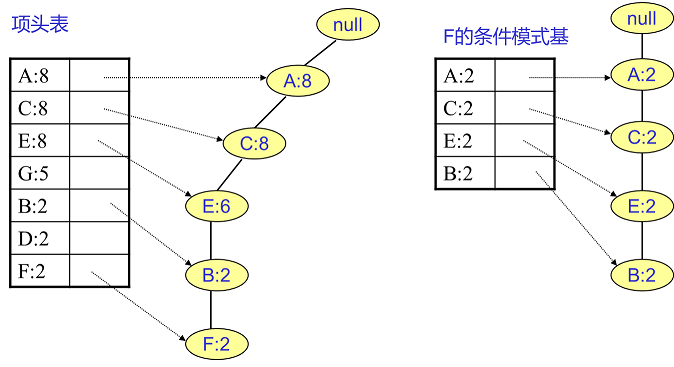
- 例如我们先找特征 F 相关的节点,如下图所示,左边就是所有 F 相关的分叉和节点了,中间这个 F 的条件模式基听起来过于拗口难以理解,可以这么来理解
- 首先左侧的分叉只有一条,那就是 ACEGBF,那么在上面的 T‘事物集数据中,以ACEGBF这样的顺序的数据只有: 第一条ACEBF,倒数第四条ACEBF,那么就得到了下图中 F 的条件模式基表格对应的特征与数字,
- 得到频繁 2 项集有(这里其实就是排列组合):{ A:2,F:2},{ C:2,F:2},{ E:2,F:2},{ B:2,F:2}
- 同样方法,频繁3 项集{A:2,C:2,F:2}{A:2,E:2,F:2}{A:2,B:2,F:2}{C:2,E:2,F:2}{C:2,B:2,F:2}{E:2,B:2,F:2}
- 同样的组合方式得到其他频繁项集,最高到频繁 5 项集
- 假如分叉有两条呢?比如 D 节点两个分叉,一个是 ACD 分叉,一个是 ACEGD分叉,同理,ACD 分叉的有倒数第三条数据 ACD,ACEGD分叉只有第四条数据 ACEGD,那么两个分叉汇总后得到{A:2, C:2,E:1 G:1,D:1, D:1},此处还要筛选一下,因为 D 节点相关分叉上 E,G节点支持度小于 20%(类似上面删除特征O,I 一样,根据支持度筛选),所以得到了下图中的 D 的条件模式基,同样的方式求得 D 的所有频繁项集
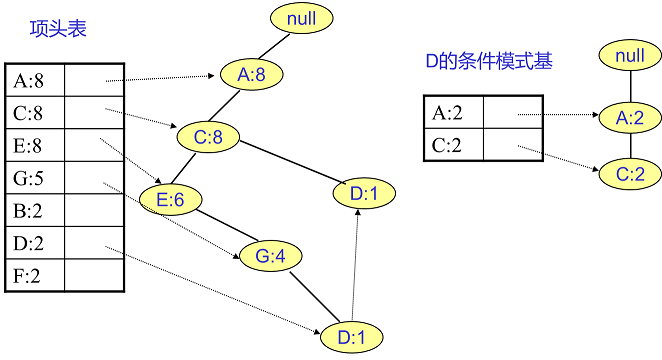
- 其他的节点与上面两种情况同理,加入有三个分叉,多个分叉的都是同理可得到各个节点的频繁项集
- 注意,A 节点的条件模式基为空,所以不需要再求了(上述节点依然不包含全部过程,详细过程见上面参考资料 1)
代码部分:
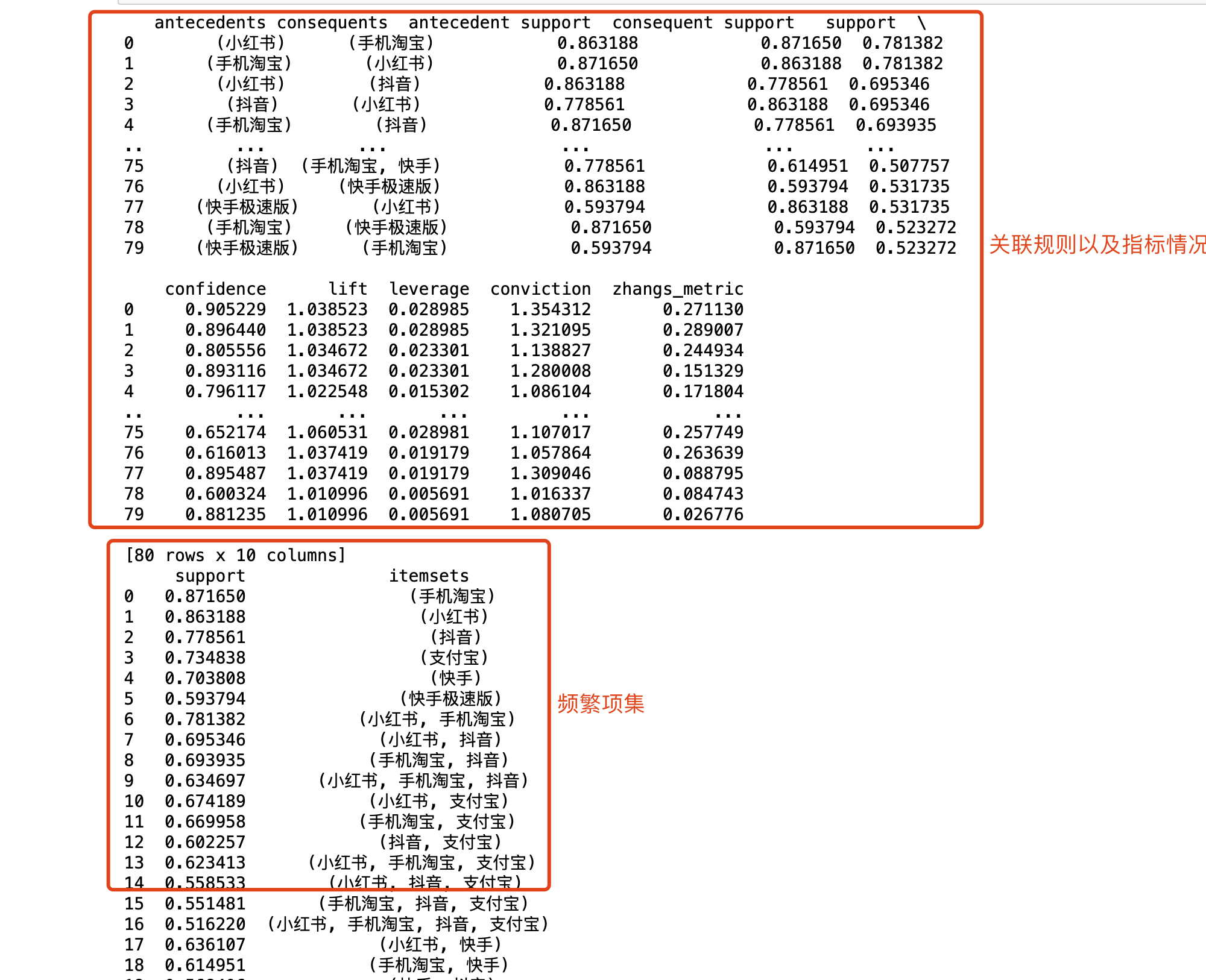
- 代码部分除了得到频繁项集与上面介绍一致外,还包含了关联规则,通俗理解就是频繁项集只是得到了不同的特征组合,但是这个特征组合关联性强弱,需要生成关联规则以及指标来确定,从而拿到符合要求的特征组合
- association_rules函数生成规则,具体用法下一篇文章介绍
- mlxtend 中fpgrowth 的函数参数介绍链接点击
- 简单理解参数min_support其实就是上面那个支持度,use_colnames是因为 df 处理的时候用序号表示的列名,该参数还原还原的列名,具体可看上面官网例子
- 测试数据此处放部分,足以生成结果
"京东,小红书,快手,快手极速版,手机淘宝,抖音,抖音极速版,抖音火山版,支付宝,美团,饿了么"
"七猫免费小说,京东,今日头条,今日头条极速版,唯品会,墨迹天气,小红书,快手,快手极速版,手机淘宝,抖音,抖音极速版,支付宝,爱奇艺,番茄免费小说,美团,饿了么"
"UC浏览器,七猫免费小说,京东,今日头条,今日头条极速版,墨迹天气,小红书,快手,快手极速版,手机天猫,手机淘宝,抖音,抖音火山版,搜狐视频,支付宝,番茄免费小说,美团,西瓜视频,饿了么"
"京东,墨迹天气,小红书,快手,手机淘宝,抖音,支付宝,爱奇艺,美团"
"MOMO陌陌,QQ阅读,京东,京东金融,优酷视频,小红书,快手极速版,懂车帝,手机淘宝,抖音,抖音极速版,抖音火山版,探探,支付宝,番茄免费小说,番茄畅听,美团,菜鸟裹裹,西瓜视频,饿了么"
"小红书,快手极速版,手机淘宝,抖音,支付宝,番茄免费小说,番茄畅听,西瓜视频"
"优酷视频,小红书,快手,快手极速版,抖音极速版,支付宝,番茄免费小说,西瓜视频"
"UC浏览器,七猫免费小说,今日头条,今日头条极速版,优酷视频,小红书,快手,快手极速版,手机淘宝,抖音,抖音极速版,抖音火山版,搜狐视频,支付宝,洋葱学园,爱奇艺,番茄免费小说,美团,西瓜视频"
"MOMO陌陌,Soul,UC浏览器,京东,今日头条,今日头条极速版,优酷视频,小红书,快手,快手极速版,手机淘宝,抖音极速版,抖音火山版,搜狐视频,洋葱学园,番茄免费小说,西瓜视频,饿了么"
"七猫免费小说,京东,优酷视频,小红书,平安口袋银行,手机淘宝,抖音,抖音极速版,支付宝,爱奇艺,番茄免费小说,芒果TV,饿了么"
"优酷视频,小红书,快手,手机淘宝,抖音,支付宝,美团"
"YY,京东,唯品会,小红书,快手,快手极速版,懂车帝,手机淘宝,抖音,支付宝,爱奇艺,番茄免费小说,美团,饿了么"
"京东,京东金融,小红书,快手,手机淘宝,抖音,探探,支付宝,美团,菜鸟裹裹,起点读书"
"京东,今日头条,小红书,快手,手机淘宝,抖音,支付宝,美团"
"UC浏览器,京东,今日头条,墨迹天气,小红书,手机淘宝,抖音,支付宝,番茄免费小说,美团,芒果TV"
"小红书,快手,快手极速版,手机淘宝,抖音,抖音极速版,支付宝,番茄畅听,饿了么"
"得间免费小说,快手极速版,手机淘宝,支付宝,番茄免费小说"
"LOFTER,Soul,京东,今日头条,优酷视频,唯品会,小红书,快手,快手极速版,手机淘宝,抖音,抖音极速版,番茄免费小说,饿了么"
"Soul,七猫免费小说,今日头条,今日头条极速版,优酷视频,小红书,快手,快手极速版,手机淘宝,抖音,搜狐视频,支付宝,番茄畅听,西瓜视频"
"京东,小红书,手机淘宝,抖音,支付宝"
"Soul,UC浏览器,七猫免费小说,京东,今日头条,今日头条极速版,优酷视频,小红书,快手,快手极速版,手机淘宝,抖音,抖音极速版,搜狐视频,爱奇艺,番茄畅听,西瓜视频,飞猪"
"小红书,快手极速版,手机淘宝,抖音,支付宝,番茄免费小说,美团,芒果TV,西瓜视频,饿了么"
"MOMO陌陌,京东,今日头条,唯品会,小红书,快手,手机淘宝,抖音,支付宝,番茄免费小说"
"YY,小红书,快手,快手极速版,手机淘宝,抖音,支付宝,西瓜视频"
"UC浏览器,京东,今日头条极速版,优酷视频,哔哩哔哩漫画,唯品会,小红书,快手,快手极速版,手机淘宝,抖音,抖音极速版,抖音火山版,搜狐视频,支付宝,番茄畅听,腾讯动漫,西瓜视频,饿了么"
"UC浏览器,京东,今日头条,今日头条极速版,小红书,快手,快手极速版,手机淘宝,抖音,抖音极速版,抖音火山版,支付宝,西瓜视频"
"小红书,抖音,支付宝"
"京东,今日头条,今日头条极速版,优酷视频,小红书,快手,快手极速版,抖音,支付宝,爱奇艺,美团,芒果TV,花小猪打车,西瓜视频,饿了么"
"京东,今日头条,小红书,快手,手机淘宝,抖音,支付宝,番茄畅听"
"Soul,京东,京东金融,今日头条,分期乐,快手,手机淘宝,抖音,搜狐视频,支付宝,爱奇艺,番茄畅听,美团,西瓜视频,饿了么"
"MOMO陌陌,Soul,七猫免费小说,京东,今日头条,今日头条极速版,优酷视频,唯品会,小红书,快手,快手极速版,手机淘宝,抖音,抖音极速版,支付宝,番茄免费小说,番茄畅听,西瓜视频,起点读书"
"小红书,快手,手机淘宝,抖音,支付宝,滴滴车主,美团"
"优酷视频,墨迹天气,小红书,快手,手机淘宝,抖音,支付宝"
"小红书,快手,抖音,抖音火山版"
"UC浏览器,小红书,快手,快手极速版,手机淘宝,抖音,抖音极速版,支付宝"
"京东,今日头条,优酷视频,小红书,快手,快手极速版,手机淘宝,抖音,抖音极速版,抖音火山版,搜狐视频,支付宝,洋葱学园,番茄免费小说,西瓜视频"
"KEEP,小红书,手机淘宝,抖音,支付宝,爱奇艺,美团,菜鸟裹裹"
"UC浏览器,七猫免费小说,中华万年历,京东,今日头条,今日头条极速版,优酷视频,小红书,快手,快手极速版,手机天猫,手机淘宝,抖音,抖音火山版,搜狐视频,爱奇艺,番茄免费小说,番茄畅听,西瓜视频"
"KEEP,京东,今日头条,优酷视频,小红书,快手,快手极速版,手机淘宝,抖音,抖音极速版,支付宝,爱奇艺,美团,芒果TV,西瓜视频,饿了么"
"京东,优酷视频,小红书,手机淘宝,抖音,抖音极速版,支付宝,爱奇艺"
"京东,小红书,手机淘宝,抖音,抖音极速版,支付宝"
"京东,优酷视频,快手极速版,手机淘宝,抖音极速版,抖音火山版,支付宝,西瓜视频,饿了么"
"优酷视频,小红书,快手,快手极速版,手机淘宝,抖音,抖音极速版,支付宝,滴滴车主,美团"
"小红书,手机淘宝,抖音,支付宝"
"MOMO陌陌,Soul,京东,小红书,快手,手机淘宝,抖音,探探,支付宝,芒果TV"
"京东金融,今日头条极速版,小红书,快手,快手极速版,抖音,抖音极速版,支付宝"
"UC浏览器,七猫免费小说,京东,今日头条,优酷视频,唯品会,小红书,懂车帝,手机淘宝,抖音,抖音极速版,搜狐视频,番茄免费小说,番茄畅听,西瓜视频"
"京东,小红书,快手,手机淘宝,抖音,番茄畅听,西瓜视频"
"Soul,京东,小红书,快手,快手极速版,手机淘宝,抖音,抖音极速版,抖音火山版,支付宝,美团,西瓜视频"
"京东,今日头条,小红书,快手,快手极速版,手机淘宝,抖音,抖音极速版,支付宝,番茄免费小说,西瓜视频"
import pandas as pd
from mlxtend.preprocessing import TransactionEncoder
from mlxtend.frequent_patterns import fpgrowth, association_rules
with open('./test2.csv', 'r') as f:
dataset = [line.strip().split(',') for line in f]
te = TransactionEncoder()
te_ary = te.fit(dataset).transform(dataset)
df = pd.DataFrame(te_ary, columns=te.columns_)
frequent_itemsets = fpgrowth(df, min_support=0.5, use_colnames=True)
rules = association_rules(frequent_itemsets, metric="confidence", min_threshold=0.5)
print(rules)
print(frequent_itemsets)
frequent_itemsets.to_csv('frequent_itemsets2.csv', index=False)
rules.to_csv('rules2.csv', index=False)
结尾
- 关于该算法的一些个人理解可能存在错误,仅供参考,本文更像是对参考资料的个人理解来加深记忆,可以优先看参考资料某些不懂的地方本文可能有所帮助。
























 1087
1087











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











