






简介
字词向量表示本质上就是将一个个离散单词通过一定手段映射到向量中,从而使每个单词都有自己的表征向量。这样最直观的好处就是可以计算空间相似度来表征词语间的相似度,另一个好处就是词语有了向量表征后,我们就可以像训练图片或者语音那样来训练文本内容。
下面介绍如何用OC实现字词向量模型,主要实现了四种模型:基于Hierarchical Softmax的连续词袋模型(CBOW)及Skip-Gram模型,和基于Negative Sampling的连续词袋模型(CBOW)及Skip-Gram模型。

数据预处理
首先我们需要一个处理好的输入数据源,最好是每个词语之间是空格分开。英文文章用简单的脚本语言就可以实现过滤做成输入源,中文就比较困难一点,可以借助一些分词工具实现,也可以网上下载专门的训练数据。
接下来就是将词读入数据,并统计每个词语出现的频率,建立好对应关系,这块比较简单,直接看代码:
- (void)readWordFromFile
{
FILE *file = fopen([_filePath UTF8String], "rb");
char word[MAX_WORDLENGTH];
_dicSize = 0;
_totalWords = 0;
if (file == NULL) {
NSLog(@"File Error");
return;
}
while (1) {
[self readWord:word File:file];
if (feof(file)) {
break;
}
if (strlen(word) == 0) {
continue;
}
int i = [self findWordInDict:word];
if (i == -1) { // not found
[self addWordToDict:word];
}
else
{
_dictionary[i].frequency++;
}
_totalWords++;
}
[self sortDict];
[self buildHuffmanTree];
_fileSize = ftell(file);
fclose(file);
}
- (void)readWord:(char *)word File:(FILE *)file
{
int letter;
int len = 0;
while (!feof(file)) {
letter = fgetc(file);
if (letter == 13) { // New Page
continue;
}
if (len == 0 && letter == '\n') { // ignore Return
word[len] = 0;
return;
}
if (letter == ' ' || letter == '\n' || letter == '\t') { // ignore Return + Space + EOL
break;
}
if (len >= MAX_WORDLENGTH - 1) {
break;
}
word[len] = letter;
len++;
}
word[len] = 0;
}
- (int)findWordInDict:(char *)word
{
id index = [_indexDict objectForKey:[[NSString stringWithCString:word encoding:NSUTF8StringEncoding] lowercaseString]];
if (index == NULL) {
return -1;
}
return [index intValue];
}
- (void)addWordToDict:(char *)word
{
long len = strlen(word) + 1;
_dictionary[_dicSize].word = calloc(len, (sizeof(char)));
strcpy(_dictionary[_dicSize].word, word);
_dictionary[_dicSize].frequency = 1;
_dicSize++;
if (_dicSize + 2 > max_dicSize) {
max_dicSize += 1000;
_dictionary = realloc(_dictionary, sizeof(struct dic_word) * max_dicSize);
}
[_indexDict setValue:[NSNumber numberWithInt:_dicSize-1] forKey:[[NSString stringWithCString:word encoding:NSUTF8StringEncoding] lowercaseString]];
}
其中,_dictionary是一个自定义struct的数组,定义是
struct dic_word {
int *code; // Huffman Code
int codeLength;
int *position; // path of the HuffmanCode
char *word;
long long frequency;
};
最后就是根据词语的频率数组生成一棵Huffman树,目的是给每个词语生成一个可训练的唯一编码与路径。
Huffman树构造过程:
- 根据给定的n个权值{w1,w2,...wn}构成n棵二叉树的森林F={T1,T2,...,Tn},其中每棵二叉树Ti中只有一个带权为wi的根结点,且其左右子树为空。
- 在森林F中选取两棵根结点的权值最小的树作为左右子树构造一棵新的二叉树,且置新的二叉树的根结点的权值为其左,右子树上根结点的权值之和。
- 在F中删除作为新二叉树左,右子树的两棵二叉树,同时将新得到的二叉树加入森林F中。
- 重复(2)和(3),直到F中只含有一棵树为止。这棵树便是Huffman树。
Huffman编码就是从树的根结点开始,走到我们查询的叶子节点的路径,如果是左边就是0,右边就是1。
用数组实现的代码如下:
int cmp(const void *a, const void *b)
{
return (int)(((struct dic_word *)b)->frequency - ((struct dic_word *)a)->frequency);
}
- (void)sortDict
{
qsort(&_dictionary[0], _dicSize, sizeof(struct dic_word), cmp);
[_indexDict removeAllObjects];
for (int i = 0; i < _dicSize; i++) {
[_indexDict setValue:[NSNumber numberWithInt:i] forKey:[[NSString stringWithCString:_dictionary[i].word encoding:NSUTF8StringEncoding] lowercaseString]];
_dictionary[i].code = calloc(MAX_CODELENGTH, sizeof(int));
_dictionary[i].position = calloc(MAX_CODELENGTH, sizeof(int));
}
}
- (void)buildHuffmanTree
{
int size = _dicSize * 2;
long long code[MAX_CODELENGTH], position[MAX_CODELENGTH];
long long *freq = calloc(size + 1, sizeof(long long));
long long *parent = calloc(size + 1, sizeof(long long));
long long *weight = calloc(size + 1, sizeof(long long));
for (int i = 0; i < _dicSize; i++) {
freq[i] = _dictionary[i].frequency;
}
for (int i = _dicSize; i < size; i++) {
freq[i] = 1e15;
}
long long pos1 = _dicSize - 1;
long long pos2 = _dicSize;
long long min1, min2;
for (int i = 0; i < _dicSize - 1; i++) {
if (pos1 >= 0) { // find left node
if (freq[pos1] < freq[pos2]) {
min1 = pos1;
pos1--;
}
else
{
min1 = pos2;
pos2++;
}
}
else
{
min1 = pos2;
pos2++;
}
if (pos1 >= 0) { // find right node
if (freq[pos1] < freq[pos2]) {
min2 = pos1;
pos1--;
}
else
{
min2 = pos2;
pos2++;
}
}
else
{
min2 = pos2;
pos2++;
}
// combine tree
freq[_dicSize + i] = freq[min1] + freq[min2];
parent[min1] = parent[min2] = _dicSize + i;
weight[min1] = 0;
weight[min2] = 1;
}
// assign dictionary code
for (int i = 0; i < _dicSize; i++) {
long long back = i;
int pos = 0;
while (back != size - 2) {
code[pos] = weight[back];
position[pos] = back;
back = parent[back];
pos++;
}
_dictionary[i].codeLength = pos;
_dictionary[i].position[0] = _dicSize - 2; // position[0] -> the root
// loop: code[0] <-> position[1] ----> code[n] <-> position[n+1]
for (int j = 0; j < pos; j++) {
_dictionary[i].code[pos-1-j] = (int)code[j];
_dictionary[i].position[pos-j] = (int)position[j] - _dicSize;
}
}
free(freq);
free(parent);
free(weight);
}
模型实现
CBOW及Skip-Gram模型,从算法角度看非常相似,其区别为CBOW根据源词上下文词汇('the cat sits on the')来预测目标词汇(例如,‘mat’),而Skip-Gram模型做法相反,它通过目标词汇('mat')来预测源词汇('the cat sits on')。两种方法各有优缺点,CBOW在小型数据集下表现较好而Skip-Gram更适合大型数据集。
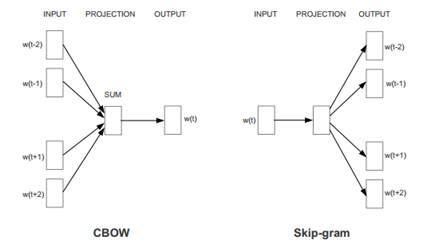
训练方式也分为两种,一种是Hierarchical Softmax,这种方式要用到前面数据预处理的Huffman编码与路径,开销较大。
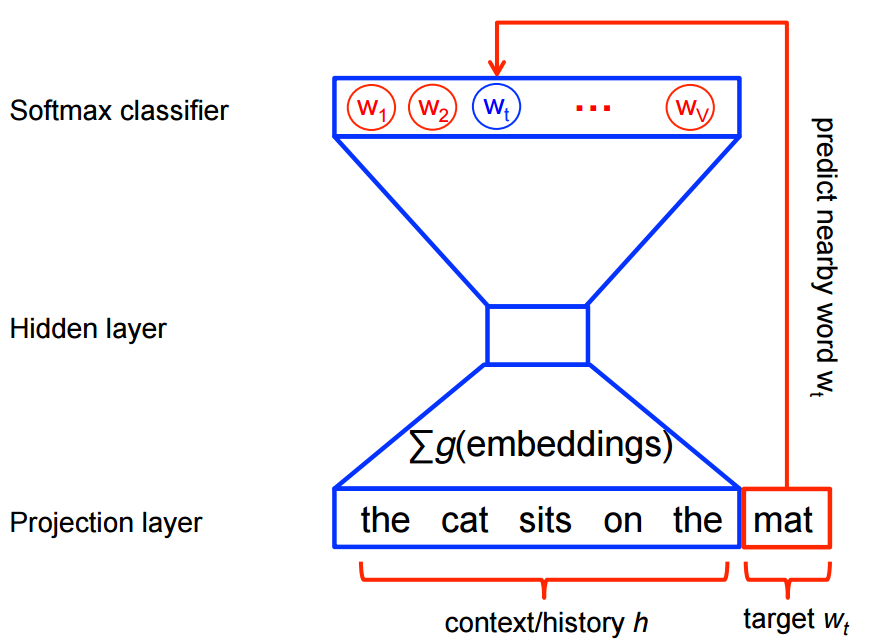
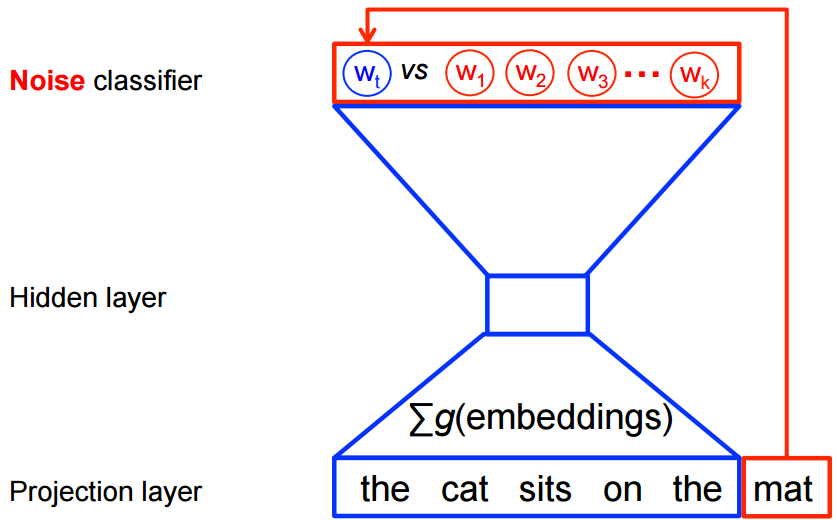
另一种则是Negative Sampling,这种方式就避免了对所有特征的学习。它的原理是用一个二分类器(逻辑回归)在同一个上下文环境里从 k 虚构的 (噪声) 单词W*区分出真正的目标单词Wt。使用这种方式需要对每个单词初始化一个与它频率相关的随机选中概率。
CBOW实现代码:
// Hierarchical Softmax
- (void)HSCbow:(int)threadId file:(const char *)filePath
{
FILE *file = fopen(filePath, "rb");
if (file == NULL) {
NSLog(@"File Error");
return;
}
fseek(file, _loader.fileSize / _threadNum * threadId, SEEK_SET);
int sentence[MAX_SENTENCE];
int senPos = 0;
int iter = _iterNum;
while (iter) {
while (1) {
int index = [_loader readWordIndex:file];
if (feof(file)) {
break;
}
if (index == -1) {
continue;
}
sentence[senPos] = index;
senPos++;
_trainedNum++;
if (senPos >= _loader.totalWords / _threadNum) {
break;
}
}
if (_trainedNum > _descentGap) {
_descentRate *= 1 - _trainedNum / (double)(_iterNum * _loader.totalWords + 1);
if (_descentRate < _startDescentRate / 1e4) {
_descentRate = _startDescentRate / 1e4;
}
_descentGap += 1e4;
}
for (int i = 0; i < senPos; i++) {
int word = sentence[i];
int start = rand() % _windowSize;
double *layer = calloc(_layerSize, sizeof(double));
double *layerLoss = calloc(_layerSize, sizeof(double));
// sum the surrounding words
for (int j = start; j < 2 * _windowSize + 1 - start; j ++) if(j != _windowSize){
int cindex = i - _windowSize + j;
if (cindex < 0 || cindex >= senPos) {
continue;
}
int cword = sentence[cindex];
vDSP_vaddD(layer, 1, (_neur1 + _layerSize * cword), 1, layer, 1, _layerSize);
}
// update neur2
for (int l = 0; l < _loader.dictionary[word].codeLength; l++) {
int dw = _loader.dictionary[word].code[l];
int codeP = _loader.dictionary[word].position[l];
double multX = 0;
for (int p = 0; p < _layerSize; p++) {
multX += layer[p] * _neur2[codeP*_layerSize + p];
}
double q = [self sigmoid:multX];
double g = _descentRate * (1 - dw - q);
for (int p = 0; p < _layerSize; p++) {
layerLoss[p] += g * _neur2[codeP*_layerSize + p];
}
for (int p = 0; p < _layerSize; p++) {
_neur2[codeP*_layerSize + p] += g * layer[p];
}
}
// update neur1
for (int j = start; j < 2 * _windowSize + 1 - start; j ++) if(j != _windowSize){
int cindex = i - _windowSize + j;
if (cindex < 0 || cindex >= senPos) {
continue;
}
int cword = sentence[cindex];
vDSP_vaddD(layerLoss, 1, (_neur1 + _layerSize * cword), 1, (_neur1 + _layerSize * cword), 1, _layerSize);
}
free(layer);
free(layerLoss);
}
senPos = 0;
fseek(file, _loader.fileSize / _threadNum * threadId, SEEK_SET);
iter--;
}
}
// Negative Sampling
- (void)NSCbow:(int)threadId file:(const char *)filePath
{
FILE *file = fopen(filePath, "rb");
if (file == NULL) {
NSLog(@"File Error");
return;
}
fseek(file, _loader.fileSize / _threadNum * threadId, SEEK_SET);
int sentence[MAX_SENTENCE];
int senPos = 0;
int iter = _iterNum;
while (iter) {
while (1) {
int index = [_loader readWordIndex:file];
if (feof(file)) {
break;
}
if (index == -1) {
continue;
}
sentence[senPos] = index;
senPos++;
_trainedNum++;
if (senPos >= _loader.totalWords / _threadNum) {
break;
}
}
if (_trainedNum > _descentGap) {
_descentRate *= 1 - _trainedNum / (double)(_iterNum * _loader.totalWords + 1);
if (_descentRate < _startDescentRate / 1e4) {
_descentRate = _startDescentRate / 1e4;
}
_descentGap += 1e4;
}
for (int i = 0; i < senPos; i++) {
int word = sentence[i];
int start = rand() % _windowSize;
double *layer = calloc(_layerSize, sizeof(double));
double *layerLoss = calloc(_layerSize, sizeof(double));
// sum the surrounding words
for (int j = start; j < 2 * _windowSize + 1 - start; j ++) if(j != _windowSize){
int cindex = i - _windowSize + j;
if (cindex < 0 || cindex >= senPos) {
continue;
}
int cword = sentence[cindex];
vDSP_vaddD(layer, 1, (_neur1 + _layerSize * cword), 1, layer, 1, _layerSize);
}
// update neur2
int label, seed;
for (int l = 0; l <= _negativeSeed; l++) {
if (l == 0) {
label = 1;
seed = word;
}
else
{
seed = _nsTable[rand() % _loader.totalWords];
if (seed == word) {
continue;
}
label = 0;
}
double multX = 0;
for (int p = 0; p < _layerSize; p++) {
multX += layer[p] * _neur2[seed*_layerSize + p];
}
double q = [self sigmoid:multX];
double g = _descentRate * (label - q);
for (int p = 0; p < _layerSize; p++) {
layerLoss[p] += g * _neur2[seed*_layerSize + p];
}
for (int p = 0; p < _layerSize; p++) {
_neur2[seed*_layerSize + p] += g * layer[p];
}
}
// update neur1
for (int j = start; j < 2 * _windowSize + 1 - start; j ++) if(j != _windowSize){
int cindex = i - _windowSize + j;
if (cindex < 0 || cindex >= senPos) {
continue;
}
int cword = sentence[cindex];
vDSP_vaddD(layerLoss, 1, (_neur1 + _layerSize * cword), 1, (_neur1 + _layerSize * cword), 1, _layerSize);
}
free(layer);
free(layerLoss);
}
senPos = 0;
fseek(file, _loader.fileSize / _threadNum * threadId, SEEK_SET);
iter--;
}
}
- (double)sigmoid:(double)x
{
if (x > 20) {
return 1;
}
if (x < -20) {
return 0;
}
return exp(x) / (1 + exp(x));
}
- (void)createNSTable
{
_nsTable = calloc(_loader.totalWords, sizeof(int));
int seg = 0;
for (int i = 0; i < _loader.dicSize; i++) {
for (int j = 0; j < _loader.dictionary[i].frequency; j++) {
_nsTable[seg] = i;
// printf("%d ",_nsTable[seg]);
seg++;
}
}
}
Skip-Gram实现代码:
// Hierarchical Softmax
- (void)HSSkipGram:(int)threadId file:(const char *)filePath
{
FILE *file = fopen(filePath, "rb");
if (file == NULL) {
NSLog(@"File Error");
return;
}
fseek(file, _loader.fileSize / _threadNum * threadId, SEEK_SET);
int sentence[MAX_SENTENCE];
int senPos = 0;
int iter = _iterNum;
while (iter) {
while (1) {
int index = [_loader readWordIndex:file];
if (feof(file)) {
break;
}
if (index == -1) {
continue;
}
sentence[senPos] = index;
senPos++;
_trainedNum++;
if (senPos >= _loader.totalWords / _threadNum) {
break;
}
}
if (_trainedNum > _descentGap) {
_descentRate *= 1 - _trainedNum / (double)(_iterNum * _loader.totalWords + 1);
if (_descentRate < _startDescentRate / 1e4) {
_descentRate = _startDescentRate / 1e4;
}
_descentGap += 1e4;
}
for (int i = 0; i < senPos; i++) {
int word = sentence[i];
int start = rand() % _windowSize;
for (int j = start; j < 2 * _windowSize + 1 - start; j ++) if(j != _windowSize){
double *layerLoss = calloc(_layerSize, sizeof(double));
int cindex = i - _windowSize + j;
if (cindex < 0 || cindex >= senPos) {
continue;
}
int cword = sentence[cindex];
// update neur2
for (int l = 0; l < _loader.dictionary[word].codeLength; l++) {
int dw = _loader.dictionary[word].code[l];
int codeP = _loader.dictionary[word].position[l];
double multX = 0;
for (int p = 0; p < _layerSize; p++) {
multX += _neur1[cword*_layerSize + p] * _neur2[codeP*_layerSize + p];
}
double q = [self sigmoid:multX];
double g = _descentRate * (1 - dw - q);
for (int p = 0; p < _layerSize; p++) {
layerLoss[p] += g * _neur2[codeP*_layerSize + p];
}
for (int p = 0; p < _layerSize; p++) {
_neur2[codeP*_layerSize + p] += g * _neur1[cword*_layerSize + p];
}
}
// update neur1
vDSP_vaddD(layerLoss, 1, (_neur1 + _layerSize * cword), 1, (_neur1 + _layerSize * cword), 1, _layerSize);
free(layerLoss);
}
}
senPos = 0;
fseek(file, _loader.fileSize / _threadNum * threadId, SEEK_SET);
iter--;
}
}
// Negative Sampling
- (void)NSSkipGram:(int)threadId file:(const char *)filePath
{
FILE *file = fopen(filePath, "rb");
if (file == NULL) {
NSLog(@"File Error");
return;
}
fseek(file, _loader.fileSize / _threadNum * threadId, SEEK_SET);
int sentence[MAX_SENTENCE];
int senPos = 0;
int iter = _iterNum;
while (iter) {
while (1) {
int index = [_loader readWordIndex:file];
if (feof(file)) {
break;
}
if (index == -1) {
continue;
}
sentence[senPos] = index;
senPos++;
_trainedNum++;
if (senPos >= _loader.totalWords / _threadNum) {
break;
}
}
if (_trainedNum > _descentGap) {
_descentRate *= 1 - _trainedNum / (double)(_iterNum * _loader.totalWords + 1);
if (_descentRate < _startDescentRate / 1e4) {
_descentRate = _startDescentRate / 1e4;
}
_descentGap += 1e4;
}
for (int i = 0; i < senPos; i++) {
int word = sentence[i];
int start = rand() % _windowSize;
for (int j = start; j < 2 * _windowSize + 1 - start; j ++) if(j != _windowSize){
double *layerLoss = calloc(_layerSize, sizeof(double));
int cindex = i - _windowSize + j;
if (cindex < 0 || cindex >= senPos) {
continue;
}
int cword = sentence[cindex];
// update neur2
int label,seed;
for (int l = 0; l <= _negativeSeed; l++) {
if (l == 0) {
label = 1;
seed = word;
}
else
{
seed = _nsTable[rand() % _loader.totalWords];
if (seed == word) {
continue;
}
label = 0;
}
double multX = 0;
for (int p = 0; p < _layerSize; p++) {
multX += _neur1[cword*_layerSize + p] * _neur2[seed*_layerSize + p];
}
double q = [self sigmoid:multX];
double g = _descentRate * (label - q);
for (int p = 0; p < _layerSize; p++) {
layerLoss[p] += g * _neur2[seed*_layerSize + p];
}
for (int p = 0; p < _layerSize; p++) {
_neur2[seed*_layerSize + p] += g * _neur1[cword*_layerSize + p];
}
}
// update neur1
vDSP_vaddD(layerLoss, 1, (_neur1 + _layerSize * cword), 1, (_neur1 + _layerSize * cword), 1, _layerSize);
free(layerLoss);
}
}
senPos = 0;
fseek(file, _loader.fileSize / _threadNum * threadId, SEEK_SET);
iter--;
}
}
- (double)sigmoid:(double)x
{
if (x > 20) {
return 1;
}
if (x < -20) {
return 0;
}
return exp(x) / (1 + exp(x));
}
- (void)createNSTable
{
_nsTable = calloc(_loader.totalWords, sizeof(int));
int seg = 0;
for (int i = 0; i < _loader.dicSize; i++) {
for (int j = 0; j < _loader.dictionary[i].frequency; j++) {
_nsTable[seg] = i;
seg++;
}
}
}
训练结果
我这里用NSCBow训练了一下《北京折叠》英文版里面的词语,然后输出了几个单词与之Cosine Distance相近的词语。
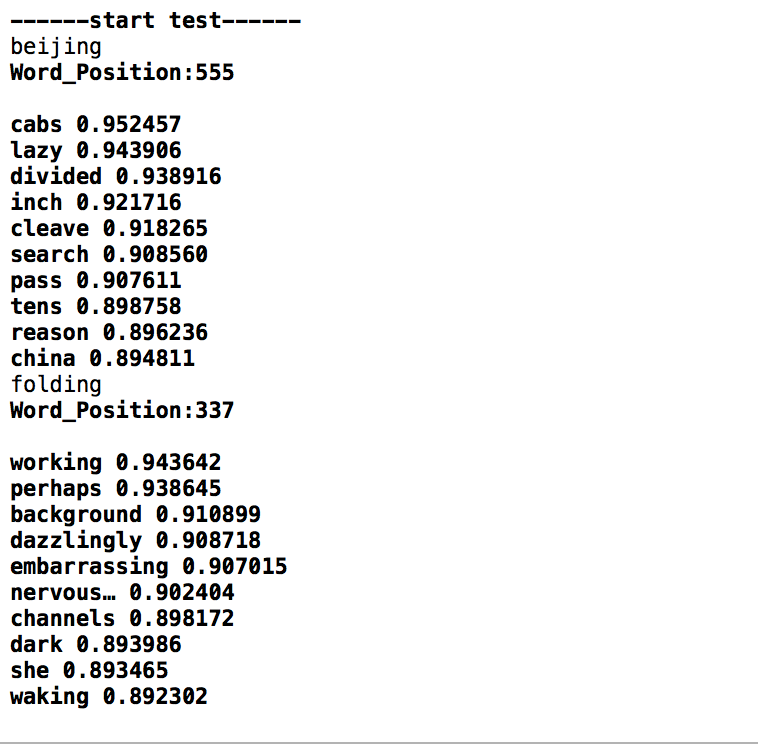
有兴趣的朋友可以看这里的完整代码Orz😊。














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









