









学习Selenium+Python,最终的目的是为了实现自动化测试的操作。
前面几篇文章,详细介绍了搭建环境、如何准确定位测试对象以及几个常用web 控件的脚本使用,基本可以实现关于网站的登录、注册等自动化操作。
今天开始学习自动化测试模型的介绍,包括模块化,数据驱动以及数据驱动参数化。自动化测试模型是自动化测试架构的基础。
1.模块化与类库
我们 测试过程中,即使自动化测试,写的脚本,很多内容是重复性的;于是我们就可以考虑将其重复的部分,写成一个公共的模块,需要的时候进行调用,这样就大大提高了我们编写脚本的效率。
下面以百度云网站的登录,退出为例。
分析:
百度云网站的登录,那么需要登录部分的脚本,用于自动输入用户名,密码以及点击登录按钮。将此脚本命名为Login.py 退出该网页,只需要简单的quit()函数即可实现,将此脚本命名为Quit_OS.py
首先,写login.py的内容如下:
from selenium import webdriver
from selenium.webdirver.common.action_chains import ActionChains
import time
def login():
browser=webdriver.Chrome()
browser.find_element_by_name("userName").clear()
browser.find_element_by_name("userName").send_keys("alu***")
browser.find_element_by_name("userName").send_keys(Keys.TAB)
browser.find_element_by_name("password").send_keys("*****")
browser.find_element_by_css_selector("input[value='登录']").click()
其次,写Quit_OS.py 脚本
from selenium import webdriver
from selenium.webdirver.common.action_chains import ActionChains
import time
def quit_OS():
browser=webdriver.Chrome()
browser.quit()
然后,整合Login.py与Quit_OS.py 集成一个完整的,可重复性使用的。
#coding=utf-8
from selenium import webdriver
from selenium.webdirver.common.action_chains import ActionChains
import time
import Login,Quit_OS #调用Login,Quit_OS模块
browser=webdriver.Chrome()
url="http://yun.baidu.com/"
browser.get(url)
# 调用登录模块
Login.login() #注意大小写,调用模块名字与函数名字的书写
time.sleep(10)
# 调用退出模块
Quit_OS.quit_OS()
这样做的优点是提高了开发效率,不用重复的编写相同的脚本;假如,我已经写好一个登录模块,我后续需要做的就是在需要的地方调用,不同重复写脚本。同时,方便了代码的维护,假如登录模块发生了变化,我只用修改 login.py 文件中登录模块的代码即可,那么所有调用登录模块的脚本不用做任何修改。
2.数据驱动
这点与QTP中的DataTable的功能类似。可以理解成参数化,输入数据的不同从而引起输出结果的变化。
测试案例:以搜狗搜索为例,自动搜索5次不同的关键字。
测试脚本:
from selenium import webdriver
from selenium.webdriver.common.action_chains import ActionChains
import time
values=['Selenium','QTP','Loadrunner','Python','Ruby']
for key in values:
browser=webdriver.Chrome()
url="https://www.sogou.com/"
browser.get(url)
browser.find_element_by_name("query").clear()
browser.find_element_by_name("query").send_keys(key)
browser.find_element_by_css_selector("input[value='搜狗搜索']").click()
time.sleep(4)
browser.quit()
这样可以做到,不管我们读取的是数组,还是字典、函数,又或者是 csv、txt 文件。实现了数据与脚本的分离,实现了参数化。传100个数据,通过脚本的执行,可以返回100个结果出来。
3.数据驱动(**.txt)参数化
在上一段的数据驱动中介绍了如何通过 python 定的数组对sogou输入数据进行参数化设置,将其它循环的读取 vlalues 数组中每一个数据。这里我们将通过读取 txt 文件中的数据来实现参数化。
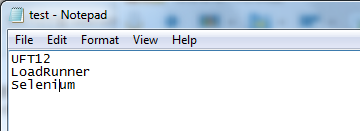
在C:\Python3.4目录下,创建一个test.txt,在里面输入:
测试案例:应用搜狗搜索,即通过读取tes.txt的数据,得到相应的搜索网页结果。
搜狗输入编辑框的定位:
测试脚本:

source=open("test.txt","r")
keys=source.readlines()
source.close()
for key in keys:
browser=webdriver.Chrome()
url="https://www.sogou.com/"
browser.get(url)
browser.find_element_by_name("query").clear()
browser.find_element_by_name("query").send_keys(key)
browser.find_element_by_css_selector("input[value='搜狗搜索']").click()
time.sleep(4)
browser.quit()
4.数据驱动(**.csv)参数化
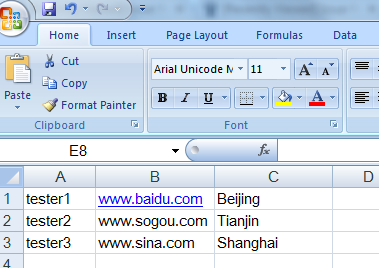
如果我有自动化脚本中要参数化一张表单,表单需要填写用户名、网址,城市等信息,使用上面的方法就很难来解决这个问题,那么,可以通过读取 .csv 文件的方法来解决这个问题。
**.csv文件是通过Excel或者WPS来创建,创建后,另存为CSV类型。
测试脚本:
#coding=utf-8
import csv #加载csv模块
with open('test.csv') as f:
data = csv.reader(f)
for user in data:
print (user[0])
print (user[1])
print (user[2])
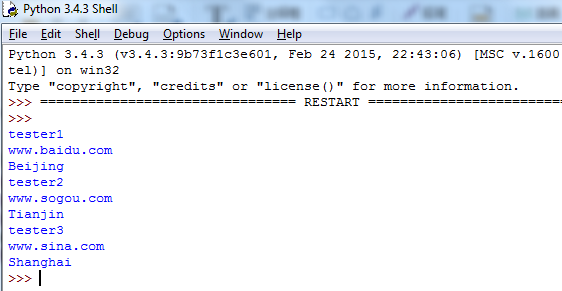
F5,运行得到:
更多关于软件测试,可以加好友交流
















 1011
1011

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









