






【小白从小学Python、C、Java】
【Python全国计算机等级考试】
【Python数据分析考试必会题】
● 标题与摘要
Python的数据分析中
交叉验证
● 选择题
以下说法错误的是:
A 交叉验证可以更好地评估模型的泛化能力
B 10折交叉验证将进行10次训练与测试
C K折交叉验证只进行一次训练与测试
D 交叉验证结果取平均值,减少结果片面的问题
● 问题解析
1.在评估模型结果时,容易因为数据集划分不合理而影响评分结果,从而导致单次评分结果可信度不高。所以需要使用不同的划分多评估几次,然后计算所有评分的平均值,这是比较有效的方法,称作交叉验证。
交叉验证(Cross Validation)会反复对数据集进行划分,并使用不同的划分对模型进行评分,减少单独测试结果过于片面以及训练数据不足的问题,可以更好地评估模型的泛化能力。
2.K折交叉验证过程:
(1)将已知类别的样本随机地划分为大小大致相等的k个子集S1,…,Sk,并进行k次训练与测试。第i次子集Si作为测试数据集,其余子集的并集作为训练数据集。进行k次训练得到k个分类模型,当利用分类模型对测试样本或者新样本进行分类时,综合考虑k个分类模型的分类结果。
(2)举例10折交叉验证:
将已知类别的样本随机地划分为大小大致相等的10个子集,并进行10次训练与测试。分别取1至10为测试集,其余子集的并集作为训练数据集。之后将测试结果取平均值,详见图1。
3.交叉验证语法:
sklearn.model_selection.cross_val_score(estimator,X,y=None,*,groups=None,scoring=None,cv=None,n_jobs=None,verbose=0,fit_params=None,pre_dispatch='2*n_jobs',error_score=nan)
参数解释:
(1)estimator用来指定要评估的模型。
(2)X和y分别用来指定数据集及其对应的标签。
(3)groups默认为None,将数据集拆分为训练集、测试集时使用的样本的分组标签。
(4)scoring默认为None。
(5)cv用来指定划分策略,常设置为整数,表示把数据集拆分成几个部分对模型进行训练和评分。cv=None时,使用默认的5折交叉验证。
(6)n_jobs默认None,并行运行的作业数。
(7)verbose默认为0。
(8)fit_params默认None,传递给估计器的fit方法的参数。
(9)pre_dispatch默认='2*n_jobs',控制在并行执行期间分派的作业数。
(10)error_score默认=np.nan,如果在估计器拟合中发生错误,则分配给分数的值。
4.使用Python自带的糖尿病数据集进行简单的3折交叉验证,分别输出三次模型结果,如图2所示。
● 附图
图1 10折交叉验证

图2 糖尿病数据集进行3折交叉验证
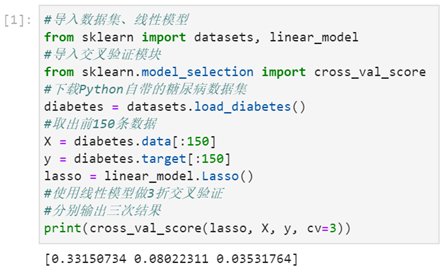
● 附图代码
#导入数据集、线性模型
from sklearn import datasets, linear_model
#导入交叉验证模块
from sklearn.model_selection import cross_val_score
#下载Python自带的糖尿病数据集
diabetes = datasets.load_diabetes()
#取出前150条数据
X = diabetes.data[:150]
y = diabetes.target[:150]
lasso = linear_model.Lasso()
#使用线性模型做3折交叉验证
#分别输出三次结果
print(cross_val_score(lasso, X, y, cv=3))
● 正确答案
C
欢迎大家转发,一起传播知识和正能量,帮助到更多人。期待大家提出宝贵改进建议,互相交流,收获更大。辛苦大家转发时注明出处(也是咱们公益编程交流群的入口网址),刘经纬老师共享知识相关文件下载地址为:http://liujingwei.cn

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











