










python运行简单的 MapReduce之 word count
- 这里python运行就直接在虚机上编写脚本运行测试
- 准备一份文档 word.txt 任意内容
a b c d e
ab ab ab abb ac kk kk
123
22332
434
3433
123
1
1
1
1
- 准备执行脚本(类似于 java中的main方法,执行入口)
## hadoop 安装目录
HADOOP_CMD="/usr/local/src/hadoop/hadoop-2.10.0/bin/hadoop"
## 找到hadoop-streaming 的jar包. hadoop支持多语言就是因为有hadoop-streaming. hadoop 1.x 和 hadoop2.x的hadoop-streaming地址不同,可自行百度
STREAM_JAR_PATH="/usr/local/src/hadoop/hadoop-2.10.0/share/hadoop/tools/lib/hadoop-streaming-2.10.0.jar"
## 上传本地文件时 输入本地文件
INPUT_FILE_PATH="/word.txt"
## 输出的haoop 目录
OUTPUT_PATH="/output"
$HADOOP_CMD jar $STREAM_JAR_PATH \
-input $INPUT_FILE_PATH \
-output $OUTPUT_PATH \
-mapper "python map.py" \ ## 指定map阶段使用 map.py的脚本
-reducer "python red.py" \
-file ./map.py \ ## 这里file的意思是将本地的 map.py脚本上传到hadoop,让执行任务的datanode节点可以获取map执行脚本
-file ./red.py
- 编写mapper map.py
#!/usr/local/bin/python
import sys
# 从标准读入 即 行读,这里对word.txt 标准读入,循环第一次即读入 a b c d e
for line in sys.stdin:
ss = line.strip().split(' ')
for s in ss:
if s.strip() != "":
print "%s\t%s" % (s, 1)
执行完成后会生成 <k,v>格式的数据,由于输出时加了 \t 制表符 ,格式例如
a 1
b 1
c 1
d 1
e 1
- 编写reducer red.py
import sys
cur_word = None
sum = 0
# 同样行读入map输出的数据,制表符切割,得到 k,v 。 计数后返回则为word count结果
for line in sys.stdin:
ss = line.strip().split('\t')
if len(ss) != 2:
continue
word, count = ss
if cur_word == None:
cur_word = word
if cur_word != word:
print "%s\t%s" % (cur_word, sum)
sum = 0
cur_word = word
sum += int(count)
# print的数据会写入指定的 output 目录生成结果
print "%s\t%s" % (cur_word, sum)
- 运行,执行run.sh
先放开脚本权限
chmod +x run.sh
./run.sh
会有日志显示运行进度,完成后查看结果
hadoop fs -ls /output
可以得到两个文件,分别是
_SUCCESS # 结果状态
part-r-00000 # 输出结果
查看结果
hadoop fs -text /output/part-r-00000 得到如下结果
a 1
ab 3
b 1
c 1
····
- python 本地运行在实际中不太方便,很多时候项目很大,因此这种方式可以用于开发时抽离业务,自己mock数据,只测试一下map reduce的逻辑正确性。并且程序也可以通过linux的cat sort 等命令结合 自己编写脚本直接验证逻辑,可以在运行mapReduce之前运行一下以下命令测试数据结果
上述脚本中逻辑简要流程如下 准备文档 ——》 执行map,从文档中标准读入,处理 -》 执行reduce,获取map处理后的数据 -》 输出到 hdfs 指定目录
因此可以简化为
cat word.txt | python map.py | sort -k1rn | python red.py -> result.txt
因为map执行后,hadoop会默认排序一次,所以这里使用sort 命令模拟 hadoop Shuffle阶段的排序
使用这种方式可以快速检测自己编写的mapreduce的一些逻辑性问题,可以极大避免在执行hadoop job后因为一些基本问题而造成的资源浪费,节约时间
- 上述方式即简单的在虚机内使用python方式运行map reduce。举一反三,map 和 reduce 可以根据自己业务需求自定义编写,其中run.sh 的配置可以看参数配置部分内容
参数配置
- 设置map和reduce个数
//控制reduce个数
-jobconf mapred.reduce.tasks=2
//map个数由文件决定,输入压缩文件数量即map个数
- 输出压缩
// 是否打开压缩开关
-jobconf "mapred.compress.map.output=true" \
// 指定压缩算法
-jobconf "mapred.map.output.compression.codec=org.apache.hadoop.io.compress.GzipCodec" \
// 输出为压缩
-jobconf "mapred.output.compress=true" \
// 指定输出的压缩格式
-jobconf "mapred.output.compression.codec=org.apache.hadoop.io.compress.GzipCodec" \
- 全局排序
-jobconf stream.num.map.output.key.fields=2 \
-jobconf num.key.fields.for.partition=1 \
-partitioner org.apache.hadoop.mapred.lib.KeyFieldBasedPartitioner
java运行之idea远程提交任务到hadoop集群
- 上面说了在虚机内直接写脚本方式,大部分同学使用java开发。Java开发后有两种方式运行项目
- 第一种是编写完成后将项目打成jar包,上传到集群中,使用命令
hadoop jar mydemo.jar hdfs://master:9000/input/word/txt(input文件地址) hdfs://master:9000/out(输出文件地址)
-
第二种是远程提交到hadoop集群上运行,这里主要叙述
1). 第一步,使用开发工具(eclipse或者idea)创建一个maven项目,我还使用了SpringBoot,引入maven依赖<dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-hdfs</artifactId> <version>2.10.0</version> </dependency> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-client</artifactId> <version>2.10.0</version> </dependency> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-mapreduce-client-core</artifactId> <version>2.10.0</version> </dependency> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-common</artifactId> <version>2.10.0</version> </dependency>2). 第二步,编写mapper
package com.hadoop.demo.mapreduce.job.wordcount; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Mapper; import java.io.IOException; public class MyMapper extends Mapper<LongWritable, Text, Text, IntWritable> { @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { String item = value.toString(); String[] items = item.split(" "); if (items.length >= 1) { for (String s : items) { context.write(new Text(s), new IntWritable(1)); } } } }3). 编写reduce
package com.hadoop.demo.mapreduce.job.wordcount; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Reducer; import java.io.IOException; public class MyReducer extends Reducer<Text, IntWritable, Text, IntWritable> { @Override protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException { int sum = 0; for (IntWritable i : values) { sum ++; } context.write(key, new IntWritable(sum)); } }4). 编写启动类
package com.hadoop.demo.mapreduce.job.wordcount; import com.hadoop.demo.mapreduce.job.FileUpload.UploadFile; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import java.io.IOException; import java.util.Properties; public class Main { public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException { Properties properties = System.getProperties(); properties.setProperty("HADOOP_USER_NAME", "root"); Configuration configuration = new Configuration(true); Job job = Job.getInstance(configuration, "word count demo"); // configuration.set("mapreduce.job.jar", "/Users/liujun/Documents/javaPro/mapreduce/out/artifacts/mapreduce_jar/mapreduce.jar"); // 放到nameNode下执行时要把上面一句改成下面这句!!不然找不到target文件夹,会报错。 job.setJarByClass(Main.class); job.setMapperClass(MyMapper.class); job.setReducerClass(MyReducer.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); //job 的相关方法api http://hadoop.apache.org/docs/current/api/org/apache/hadoop/mapreduce/Job.html UploadFile uploadFile = new UploadFile(); String path = uploadFile.upload(); if (path != null) { FileInputFormat.addInputPath(job, new Path(path)); FileOutputFormat.setOutputPath(job, new Path("hdfs://192.168.0.2:9000/mytest/word_count2")); System.exit(job.waitForCompletion(true) ? 0 : 1); } } }5). 将集群上hadoop/etc 目录下的 core-site.xml , mapred-site.xml, yarn-site.xml 三个配置文件复制到Java项目的Resource目录下,目录如下
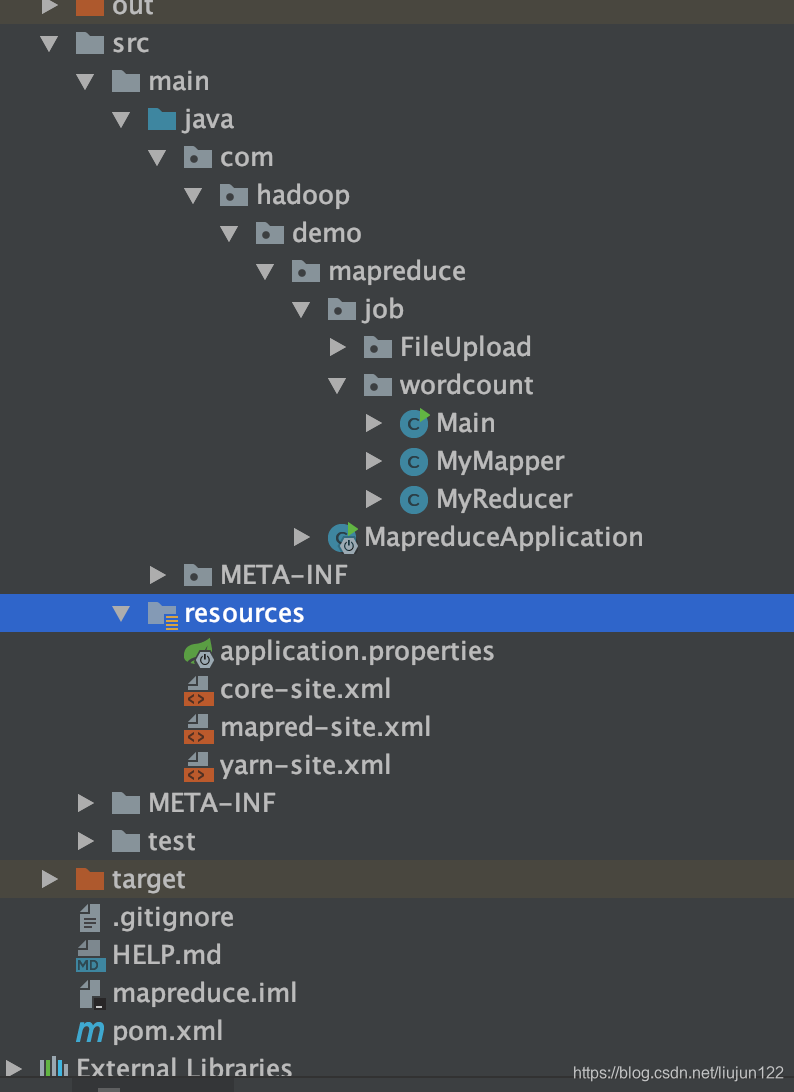
6). 修改core-site.xml<configuration> <property> <name>fs.defaultFS</name> <value>hdfs://192.168.0.2:9000</value> <!-- 集群 hdfs 地址--> </property> <property> <name>hadoop.tmp.dir</name> <value>file:/usr/local/src/hadoop/hadoop-2.10.0/tmp</value> <!-- 运行job时数据临时存放区 --> </property> <property> <name>mapred.jar</name> <value>/Users/liujun/Documents/javaPro/mapreduce/out/artifacts/mapreduce/mapreduce.jar</value> <!-- 本地项目打包地址,远程提交需要将本地项目打成jar包上传到hdfs,让datanode可以使用这个jar运行程序处理数据 --> </property> </configuration>7). 修改 mapred-site.xml
<configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> <property> <name>mapred.remote.os</name> <value>Linux</value> </property> <property> <name>mapreduce.app-submission.cross-platform</name> <value>true</value> </property> <!--如果远程集群有开启历史任务服务,则继续配置如下参数,以使得你在本地递交的job,在远程YARN web管理界面也能查询到--> <property> <name>mapreduce.jobhistory.address</name> <value>192.168.0.2:10020</value> <!--配置为远端服务地址--> </property> <property> <name>mapreduce.jobhistory.webapp.address</name> <value>192.168.0.2:19888</value> <!--配置为远端服务地址--> </property> <property> <name>mapreduce.jobhistory.intermediate-done-dir</name> <value>/mr-history/tmp</value> <!--该目录为远端HDFS上的实际存放历史作业的目录地址,按实际配置--> </property> <property> <name>mapreduce.jobhistory.done-dir</name> <value>/mr-history/done</value> <!--该目录为远端HDFS上的实际存放历史作业的目录地址,按实际配置--> </property> </configuration>8). 修改 yarn-site.xml ,以下ip均为集群主节点ip地址,自行修改为自己的即可
<configuration> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name> <value>org.apache.hadoop.mapred.ShuffleHandler</value> </property> <property> <name>yarn.resourcemanager.address</name> <value>192.168.0.2:8032</value> </property> <property> <name>yarn.resourcemanager.scheduler.address</name> <value>192.168.0.2:8030</value> </property> <property> <name>yarn.resourcemanager.resource-tracker.address</name> <value>192.168.0.2:8035</value> </property> <property> <name>yarn.resourcemanager.admin.address</name> <value>192.168.0.2:8033</value> </property> <property> <name>yarn.resourcemanager.webapp.address</name> <value>192.168.0.2:8088</value> </property> </configuration>9). 项目配置打包,这里使用idea, eclipse的打包配置自行百度
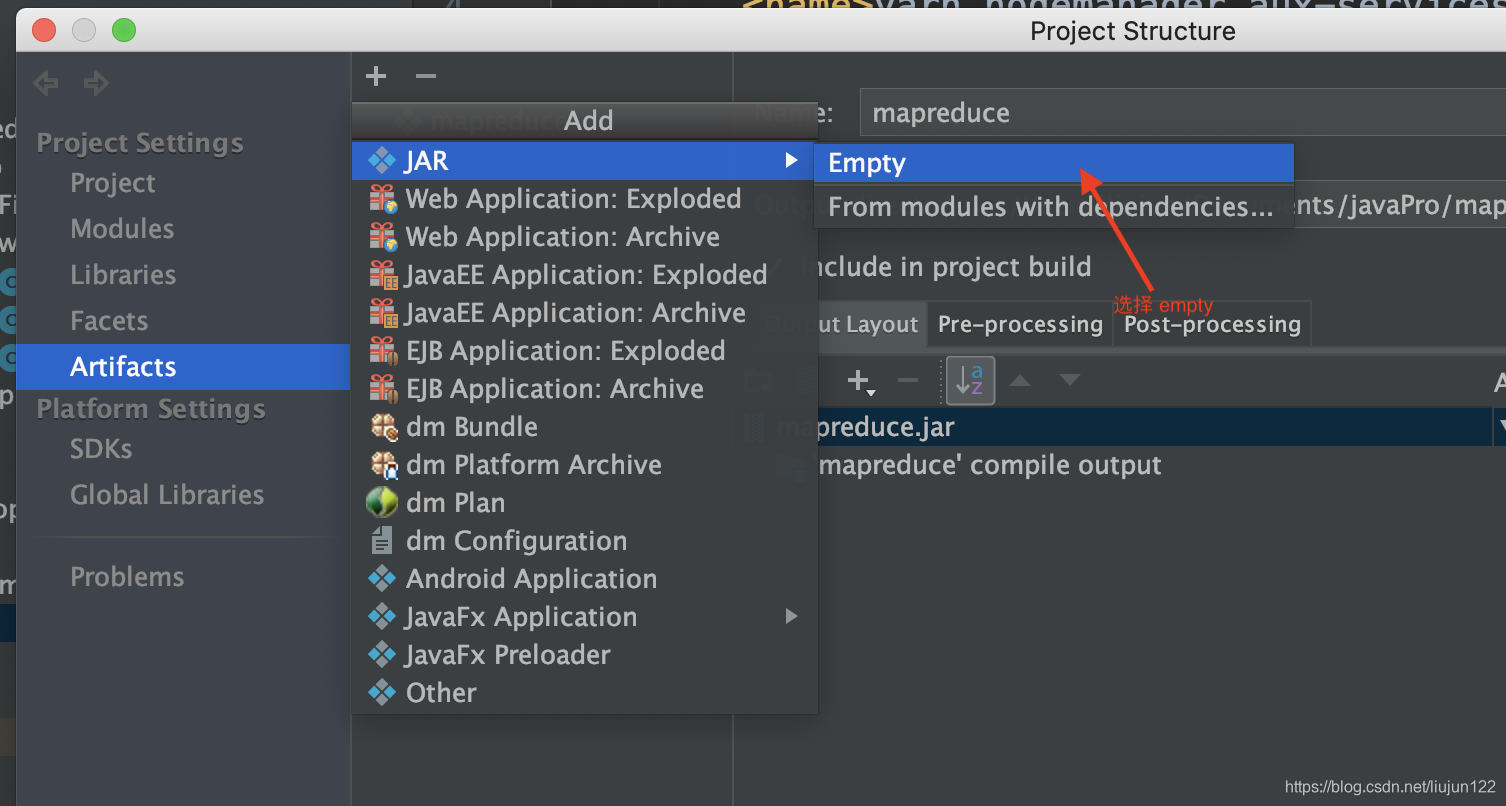
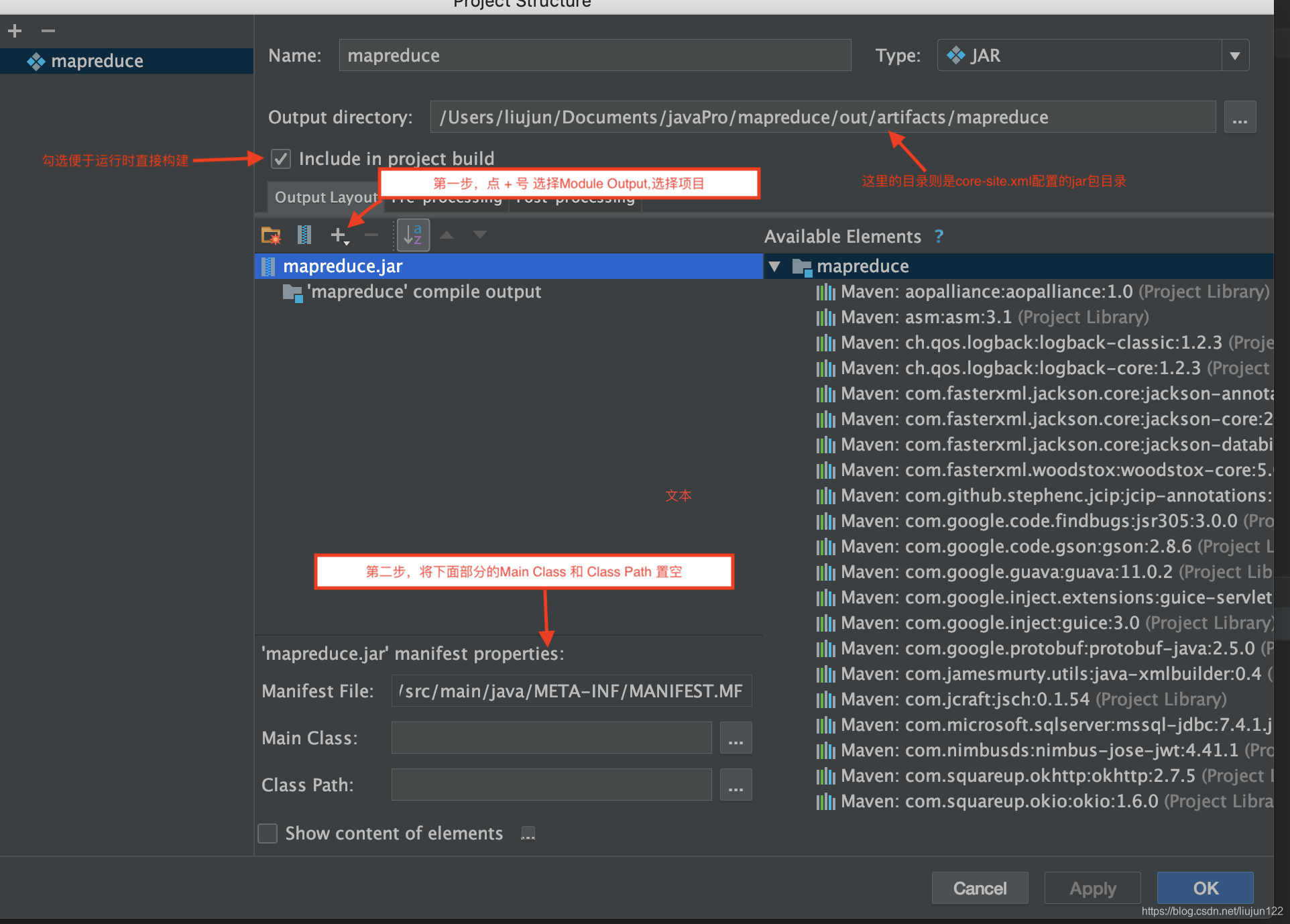
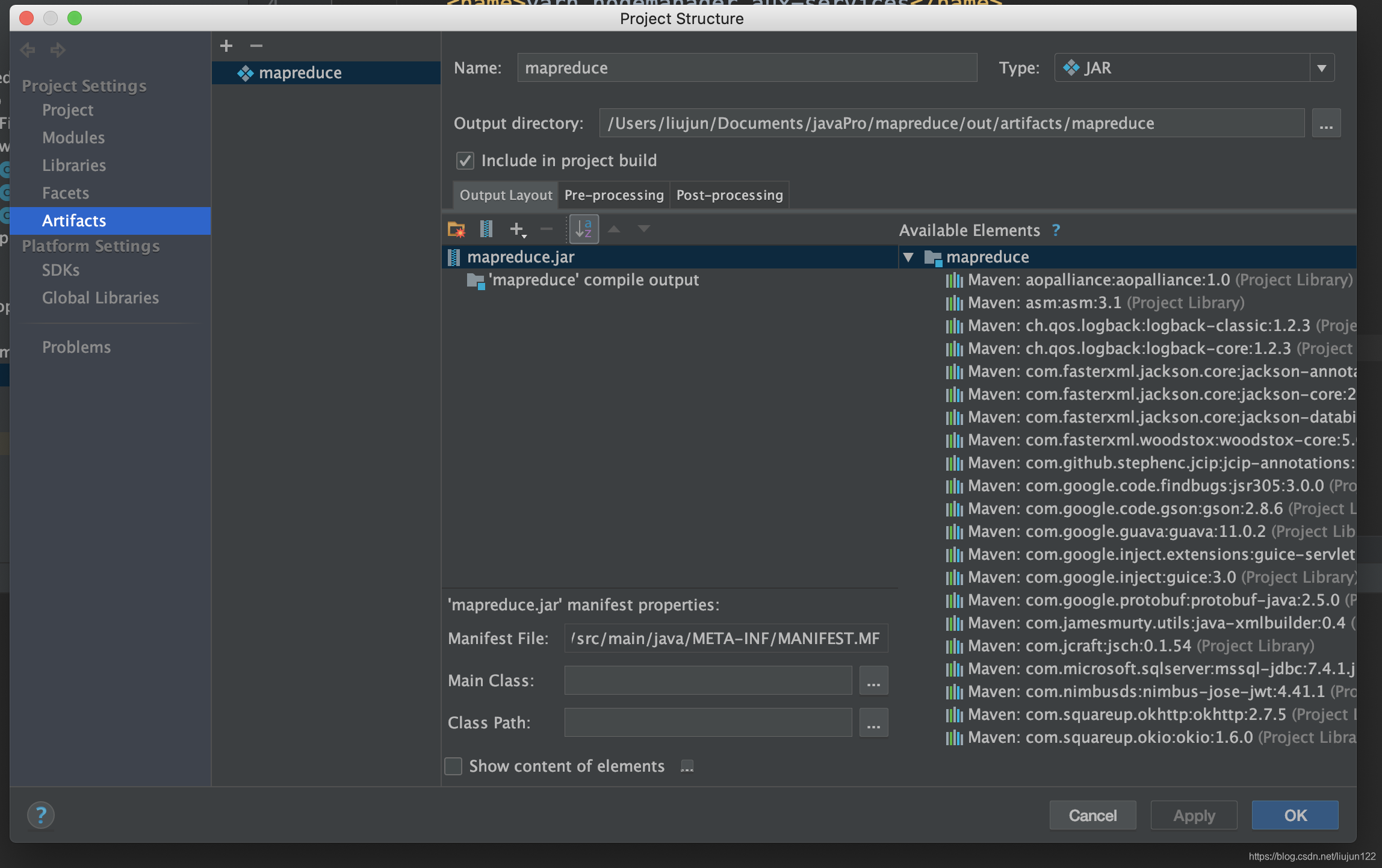
10). 直接运行启动类,即可完成mapreduce的任务提交,可以在集群中查看输出文档,也可以在 http://192.168.0.2:8088/cluster 下查看job运行状态
java 项目远程提交方式demo的github地址
- https://github.com/mrLjun/mapreduce.git
- demo 包含更多例如远程提交文件到hdfs等代码例子














 345
345











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









