






http://blog.csdn.net/majinlei121/article/details/53870433
目标检测方法系列——R-CNN, SPP, Fast R-CNN, Faster R-CNN, YOLO, SSD
从传统方法到R-CNN
从R-CNN到SPP
Fast R-CNN
Faster R-CNN
YOLO
SSD
14年以来的目标检测方法(以R-CNN框架为基础或对其改进)
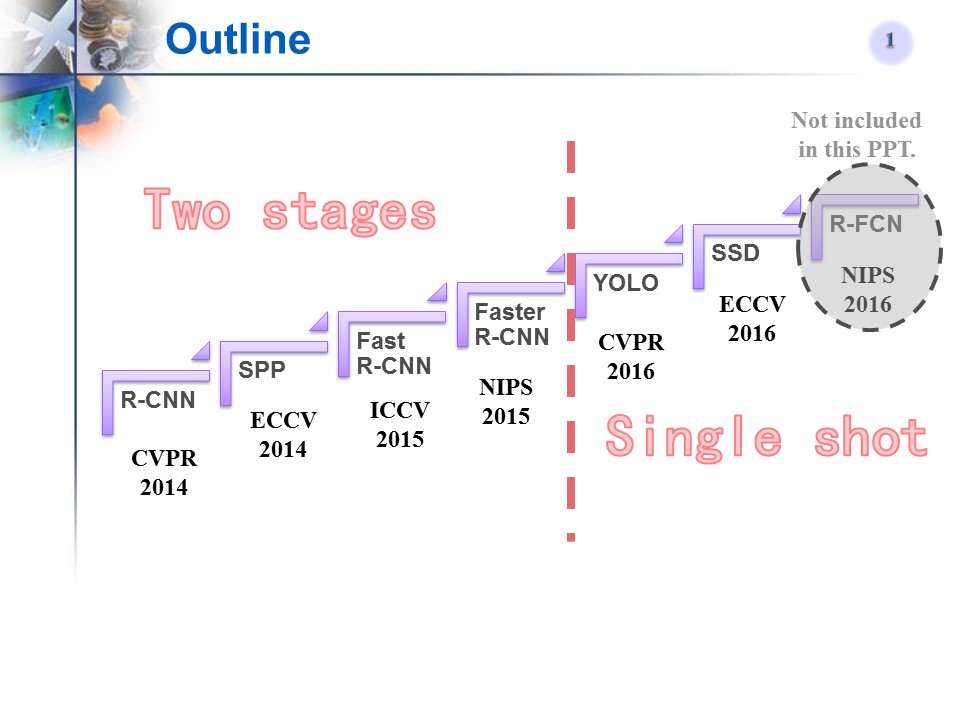
1、公布的模型主要有6个,是在COCO上训练的网络。
网络结构分别是:
1)SSD+MobileNet
2)SSD+Inception
3)R-FCN+ResNet101
4)Faster RCNN+ResNet101
5)Faster RCNN+Inception_ResNet
6)Faster RCNN+NAS
下面这些都是卷积网络模型
如:AlexNet、VGG16、VGG19、Inception、ResNet这些比较经典的卷积网络模型
还有Google自己搞的Inception-Resnet,MobileNets等。
MobileNets是基于一个流线型的架构,它使用深度可分离的卷积来构建轻量级的深层神经网络。我们引入两个简单的全局超参数,在延迟度和准确度之间有效地进行平衡。这两个超参数允许模型构建者根据问题的约束条件,为其应用选择合适大小的模型。我们进行了资源和精度权衡的广泛实验,与ImageNet分类上的其他流行的网络模型相比,MobileNets表现出很强的性能。
如何使用其他模型呢?
找到Tensorflow detection model zoo(地址:detection_model_zoo),根据里面模型的下载地址,我们只要分别把MODEL_NAME修改为以下的值,就可以下载并执行对应的模型了:
# What model to download.
MODEL_NAME = 'ssd_mobilenet_v1_coco_11_06_2017'
MODEL_NAME = 'ssd_inception_v2_coco_11_06_2017'
MODEL_NAME = 'rfcn_resnet101_coco_11_06_2017'
MODEL_NAME = 'faster_rcnn_resnet101_coco_11_06_2017'
MODEL_NAME = 'faster_rcnn_inception_resnet_v2_atrous_coco_11_06_2017'
MODEL_NAME = 'faster_rcnn_nas_coco_24_10_2017'- 2、各网络模型简介:
深度学习涉及到图像就少不了CNN模型,前面我做过几个关于图像的练习,使用的CNN网络也不够”Deeper”。我在做对象检测练习( Object Detection)时,需要用到更复杂的网络结构。本帖就使用TensorBoard看看Inception V3模型的网络结构。
Inception V3模型源码定义:tensorflow/contrib/slim/python/slim/nets/inception_v3.py
训练大的网络模型很耗资源,幸亏TensorFlow支持分布式:
- 把计算任务Distribution到服务器集群
- 把计算任务Distribution到多个GPU
Inception (GoogLeNet)是Google 2014年发布的Deep Convolutional Neural Network,其它几个流行的CNN网络还有QuocNet、AlexNet、BN-Inception-v2、VGG、ResNet等等。
利用Tensorflow训练图像分类的模型
Inceptionv3(http://arxiv.org/abs/1512.00567)。在2012年的imageNet上进行训练,并在2012ImageNet上取得了3.4%的top-5准确率(人类的只有5%)
这么一个复杂的网络若是直接自己训练,起码需要几天甚至十几天的时间。所以这里我采用迁移学习的方法。即前面的层的参数都不变,而只训练最后一层的方法。最后一层是一个softmax分类器,这个分类器在原来的网络上是1000个输出节点(ImageNet有1000个类),所以需要删除网络的最后的一层,变为所需要的输出节点数量,然后再进行训练。
Tensorflow中采用的方法是这样的:将自己的训练集中的每张图像输入网络,最后在瓶颈层(bottleneck),就是倒数第二层,会生成一个2048维度的特征向量,将这个特征保存在一个txt文件中,再用这个特征来训练softmax分类器。
二 Inception结构引出的缘由
先引入一张CNN结构演化图:2012年AlexNet做出历史突破以来,直到GoogLeNet出来之前,主流的网络结构突破大致是网络更深(层数),网络更宽(神经元数)。所以大家调侃深度学习为“深度调参”,但是纯粹的增大网络的缺点:
//1.参数太多,容易过拟合,若训练数据集有限; //2.网络越大计算复杂度越大,难以应用; //3.网络越深,梯度越往后穿越容易消失(梯度弥散),难以优化模型- 1
- 2
- 3
那么解决上述问题的方法当然就是增加网络深度和宽度的同时减少参数,Inception就是在这样的情况下应运而生。
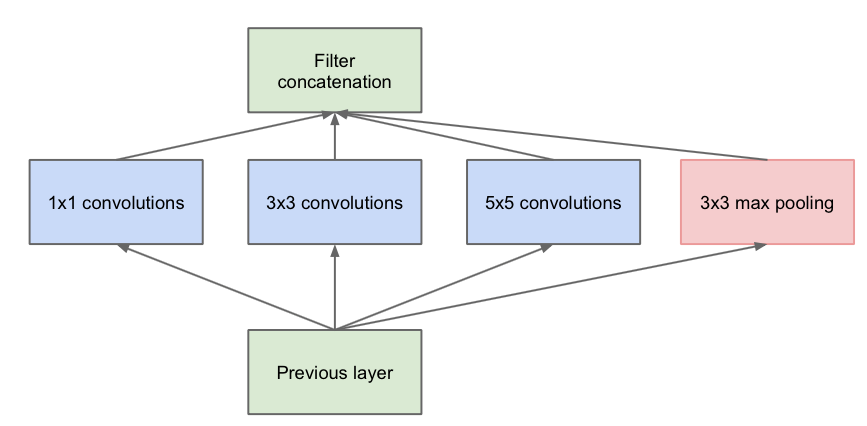
三 Inception v1模型
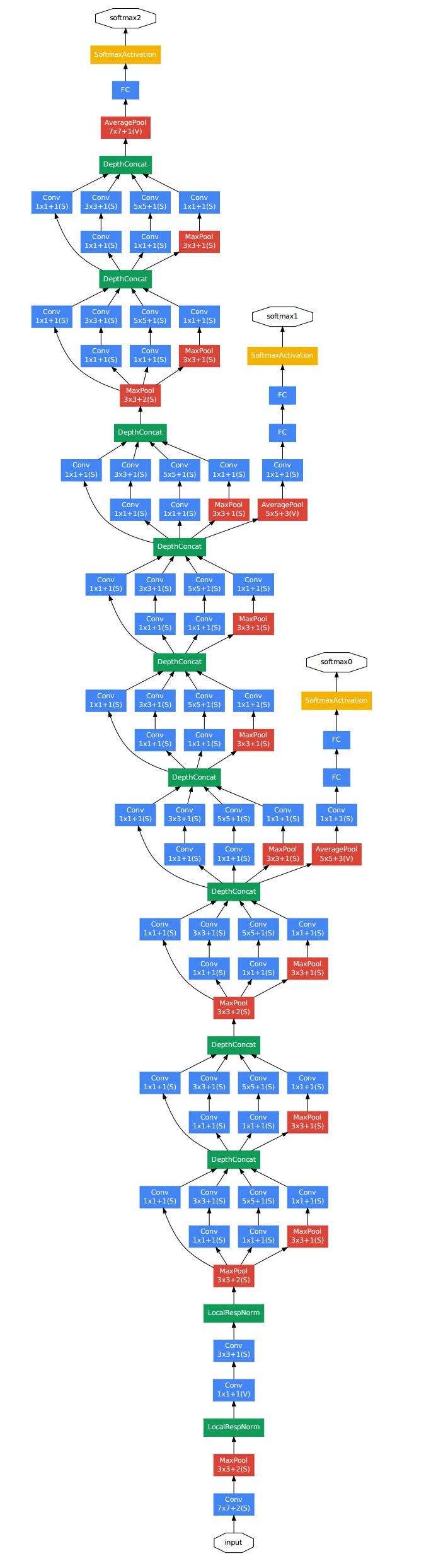
Inception v1的网络,将1x1,3x3,5x5的conv和3x3的pooling,堆叠在一起,一方面增加了网络的width,另一方面增加了网络对尺度的适应性;
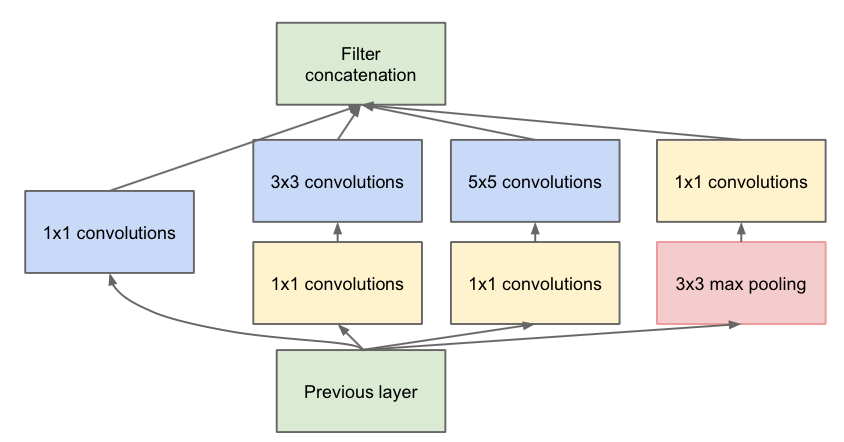
第一张图是论文中提出的最原始的版本,所有的卷积核都在上一层的所有输出上来做,那5×5的卷积核所需的计算量就太大了,造成了特征图厚度很大。为了避免这一现象提出的inception具有如下结构,在3x3前,5x5前,max pooling后分别加上了1x1的卷积核起到了降低特征图厚度的作用,也就是Inception v1的网络结构。
下面给出GoogLeNet的结构图:三 Inception v2模型
一方面了加入了BN层,减少了Internal Covariate Shift(内部neuron的数据分布发生变化),使每一层的输出都规范化到一个N(0, 1)的高斯;
另外一方面学习VGG用2个3x3的conv替代inception模块中的5x5,既降低了参数数量,也加速计算;
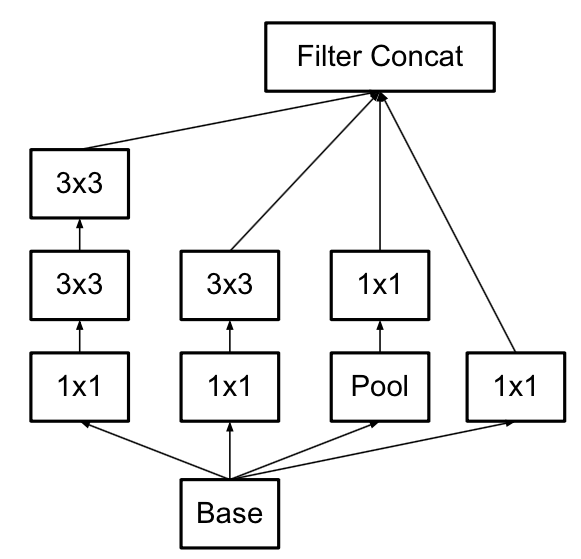
使用3×3的已经很小了,那么更小的2×2呢?2×2虽然能使得参数进一步降低,但是不如另一种方式更加有效,那就是Asymmetric方式,即使用1×3和3×1两种来代替3×3的卷积核。这种结构在前几层效果不太好,但对特征图大小为12~20的中间层效果明显。
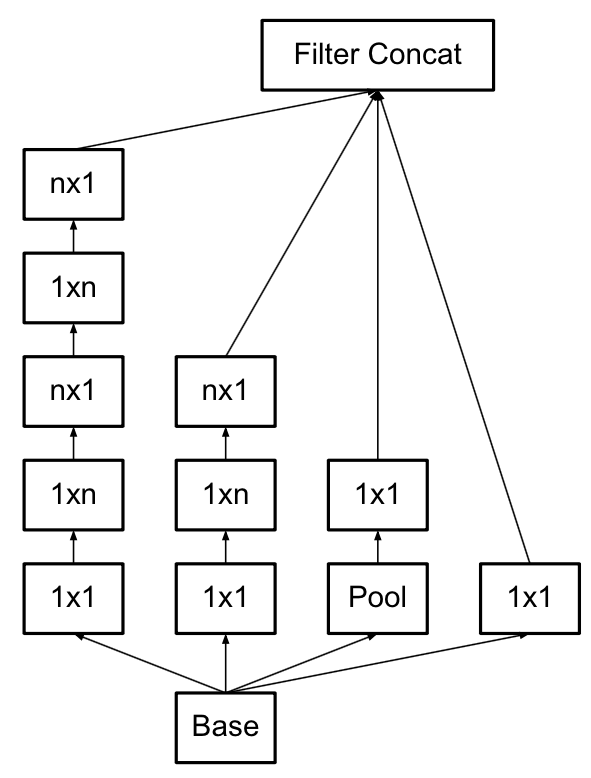
四 Inception v3模型
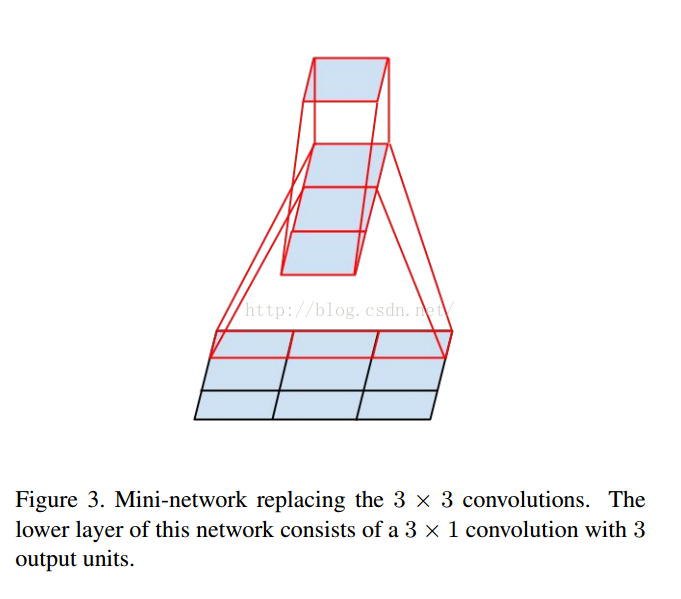
v3一个最重要的改进是分解(Factorization),将7x7分解成两个一维的卷积(1x7,7x1),3x3也是一样(1x3,3x1),这样的好处,既可以加速计算(多余的计算能力可以用来加深网络),又可以将1个conv拆成2个conv,使得网络深度进一步增加,增加了网络的非线性,还有值得注意的地方是网络输入从224x224变为了299x299,更加精细设计了35x35/17x17/8x8的模块。
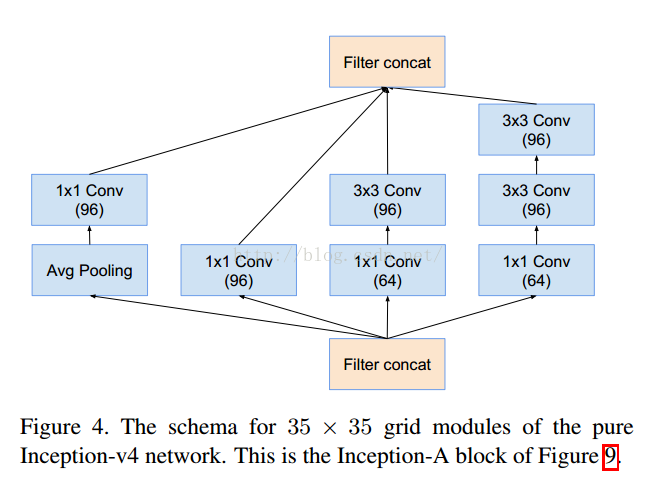
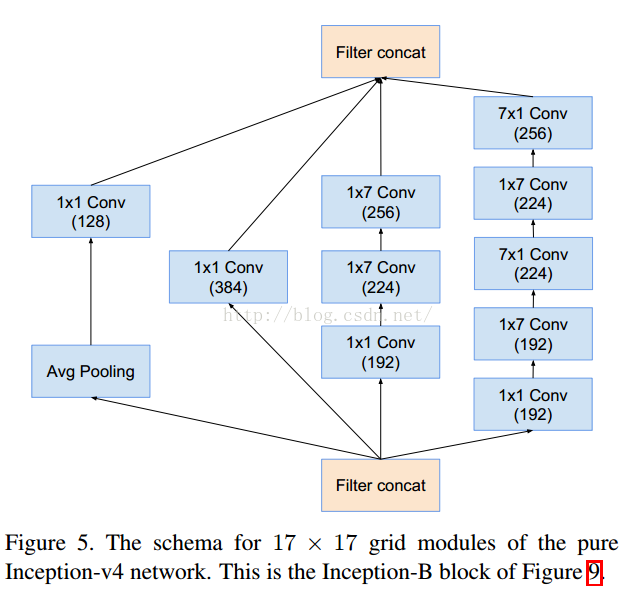
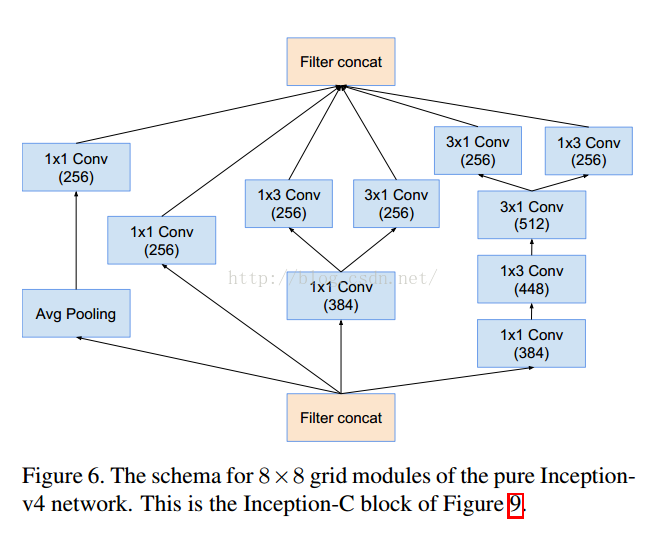
五 Inception v4模型
v4研究了Inception模块结合Residual Connection能不能有改进?发现ResNet的结构可以极大地加速训练,同时性能也有提升,得到一个Inception-ResNet v2网络,同时还设计了一个更深更优化的Inception v4模型,能达到与Inception-ResNet v2相媲美的性能。
一个5x5的网格等于两个3x3的降级
一个3x3的可以降维成一个由3x1的卷积的3个输出网络
35降维可以理解为1+9+25
17降维理解为每次降7个点,17=>11=>5
8降维可以理解为8=>6=>4=>2
这个是V1对应的3个Inception结构,V2添加相应的BN就可以。

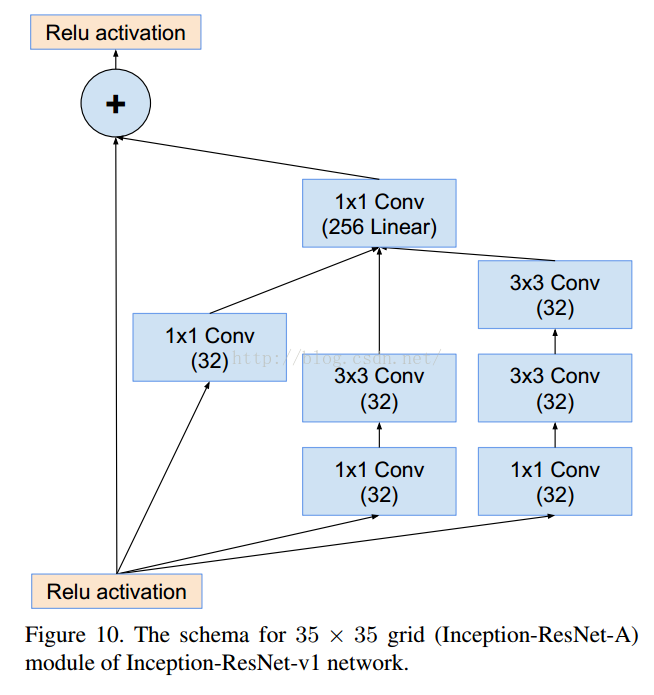
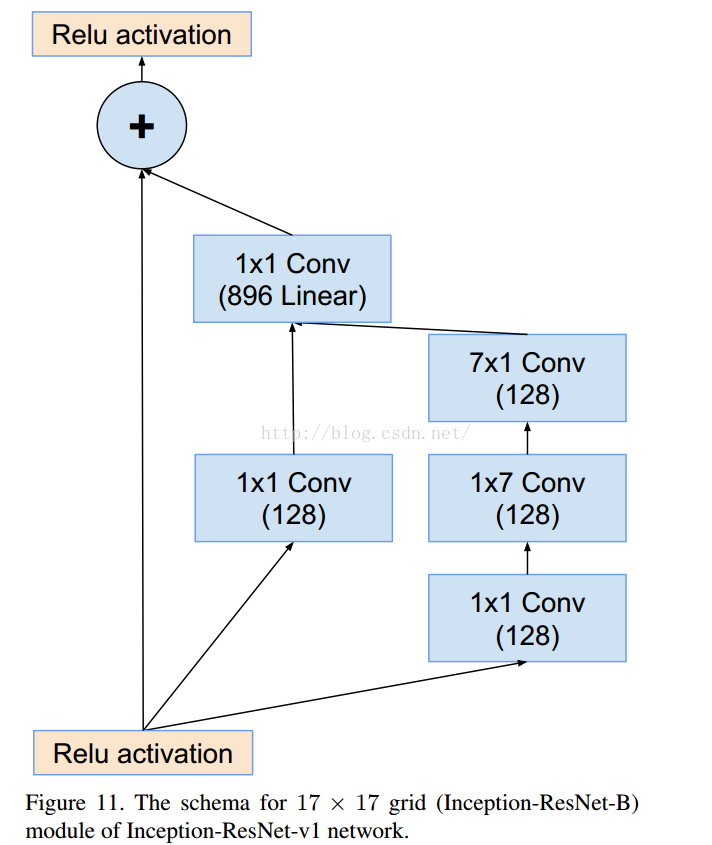
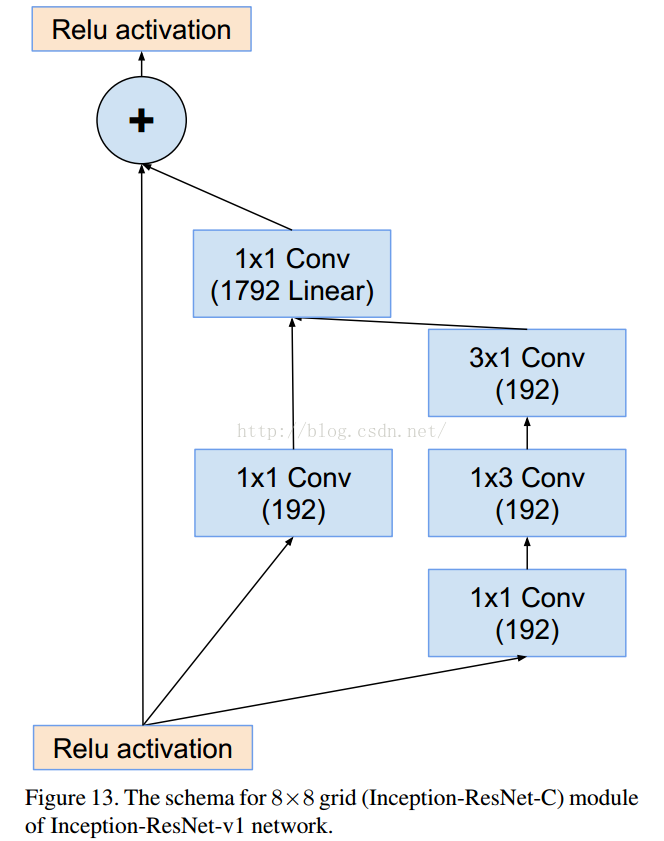
结果对比:
SSD+Mobile:

SSD+Inception:

RFCN+Resnet:

Faster+RCNN+Resnet:

Faster+RCNN++Inception+Resnet:

二、算法解析
1. R-CNN:Rich feature hierarchies for accurate object detection and semantic segmentation
技术路线:selective search + CNN + SVMs

Step1:候选框提取(selective search)
训练:给定一张图片,利用seletive search方法从中提取出2000个候选框。由于候选框大小不一,考虑到后续CNN要求输入的图片大小统一,将2000个候选框全部resize到227*227分辨率(为了避免图像扭曲严重,中间可以采取一些技巧减少图像扭曲)。
测试:给定一张图片,利用seletive search方法从中提取出2000个候选框。由于候选框大小不一,考虑到后续CNN要求输入的图片大小统一,将2000个候选框全部resize到227*227分辨率(为了避免图像扭曲严重,中间可以采取一些技巧减少图像扭曲)。
Step2:特征提取(CNN)
训练:提取特征的CNN模型需要预先训练得到。训练CNN模型时,对训练数据标定要求比较宽松,即SS方法提取的proposal只包含部分目标区域时,我们也将该proposal标定为特定物体类别。这样做的主要原因在于,CNN训练需要大规模的数据,如果标定要求极其严格(即只有完全包含目标区域且不属于目标的区域不能超过一个小的阈值),那么用于CNN训练的样本数量会很少。因此,宽松标定条件下训练得到的CNN模型只能用于特征提取。
测试:得到统一分辨率227*227的proposal后,带入训练得到的CNN模型,最后一个全连接层的输出结果---4096*1维度向量即用于最终测试的特征。
Step3:分类器(SVMs)
训练:对于所有proposal进行严格的标定(可以这样理解,当且仅当一个候选框完全包含ground truth区域且不属于ground truth部分不超过e.g,候选框区域的5%时认为该候选框标定结果为目标,否则位背景),然后将所有proposal经过CNN处理得到的特征和SVM新标定结果输入到SVMs分类器进行训练得到分类器预测模型。
测试:对于一副测试图像,提取得到的2000个proposal经过CNN特征提取后输入到SVM分类器预测模型中,可以给出特定类别评分结果。
结果生成:得到SVMs对于所有Proposal的评分结果,将一些分数较低的proposal去掉后,剩下的proposal中会出现候选框相交的情况。采用非极大值抑制技术,对于相交的两个框或若干个框,找到最能代表最终检测结果的候选框(非极大值抑制方法可以参考:http://blog.csdn.net/pb09013037/article/details/45477591)
R-CNN需要对SS提取得到的每个proposal进行一次前向CNN实现特征提取,因此计算量很大,无法实时。此外,由于全连接层的存在,需要严格保证输入的proposal最终resize到相同尺度大小,这在一定程度造成图像畸变,影响最终结果。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









