










文章目录
Hive基础
伪分布式与完全分布式
伪分布式用一个虚拟机安装并启动hadoop集群,通常来说集群有多个节点,但伪分布式只有一个节点,我还想启动hadoop,我就把所有的服务(6个服务:9857 DataNode,10038 SecondaryNameNode,10374 NodeManager,9721 NameNode,10857 Jps,10205 ResourceManager)放在这一个节点上,正常来说这几个服务应该分布在不同的机器上,单独一台机器的压力会小很多。正常来说resourseManager与namenode是在不同的机器上的,在一台机器上会很消耗内存。这样造成的后果是在数据量大的时候你任务还没有执行完,机器就挂了。
完全分布式通常是三个节点以上,hadoop除了运行hive,还会运行zookeeper(这个服务通常要求节点为奇数).hbase,spark,kylin
- 首先启动hadoop集群,启动hadoop在哪个目录都能起来
start-all.sh,jps一共六个进程,五个hadoop的进程,一个jps - 注意启动Hive的时候,正常情况下,你的hive只能在hive安装目录下启动。如果hive的元数据是存在derby中,只能在hive安装目录中启动;如果元数据在mysql中可以在任何目录下启动。

- 启动HIve 在hive的bin目录下输入
bin/hive - 退出:
quit或者ctrl_c
一、hive是什么?——数据仓库

hive处理一条sql语句,先进行解析与转换,生成多个任务,这些任务的多少取决于sql处理表格的复杂度
二、hive与mysql的区别
他们都是实现了sql的标准,一些具体语法有区别,hive是处理海量数据的,mysql处理的数据小

执行引擎:可以是MapReduce(最慢)、tez(中间)、Spark(最快)
三、Hive的优势
数据存储在hadoop集群上导致他可以无限制的存储数据:因为hadoop集群是可以横向扩展,比如现在有一千台机器,想在加入500台完全是可以的,只需要改一下配置文件,就可以服役了;当你不需要的时候就可以退役其中的一些节点

四、Hive的数据类型
基本数据类型

注意:所有的数据类型都是对Java接口的实现,因此这些类型的具体行为细节和Java中对应的类型是完全一致的。例如,string类型实现的是Java中的string,float实现的是Java中的float。
复杂数据类型


五、Hive数据定义与操作(重点)
数据库相关操作
1 创建数据库
CREATE (DATABASE/SCHEMA) [IF NOT EXISTS] database_name
[COMMENT database_comment] # comment是注释
[LOCATION hdfs_path]
[WITH DBPROPERTIES (property_name=property_value,...)];
-- 创建一个数据库
create database if not exists my_test_database;
-- 拓展:在hive中使用hadoop的dfs命令,一定要在hive里执行
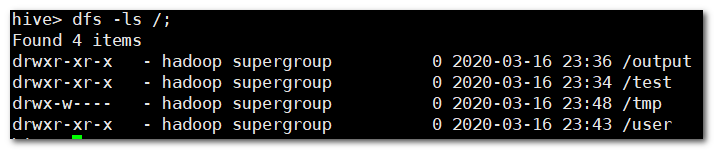
hive> dfs -ls /; # 这里可以进入文本页面确认一下是不是hadoop里的东西
-- 拓展:在hive中查看本地文件系统
hive> !ls /opt/module;

2 查看数据库信息
desc database extended 数据库名;
3 删除数据库
drop database if exists my_test_database; -- 空的可以删除,如果里面有表执行下面的命令
drop database if exists my_test_database cascade; -- 强制删除数据库
4 修改数据库
ALTER (DATABASE/SCHEMA) database_name SET LOCATION hdfs_path;
数据表相关
1 创建数据表

2 查看数据表结构
desc formatted table_name;
3 内部表与外部表的区别(面试必考)
内部表既会删除Hadoop中的数据,也会删除MySQL中的元信息,内部表通常都是一些中间表,利用它来计算其他的一些结果。
外部表首先需要加入关键字external来声明,外部表只会删除表的元信息,数据不会删除
比如有多个部门都要用到这个数据,但每个部门建立的表是不一样的,里面的数据指向同一个位置;某个部门要删除表了,肯定不能让数据给删除了呀,其他部门还要用呀。

4 修改表

5 删除表
drop table if exists table_name;
6 清空表(只会删除表中的数据)
truncate table employee;
7 分区表(重点)
分区表:文件非常大,我想将它分成不同的区。分区就是分成了不同的文件夹,比如说我有一个文件夹叫做日志,每天会产生不同的日志。如果不分区,日志就放在了一个文件夹中;分区了你可以按照年月日等将日志存储在不同的文件夹当中。
静态分区需要手动指定;动态分区是你在执行sql的时候判断的

partitioned就是指定分区的意思,按照国家进行分区,静态分区我们显示的指定



8 数据的导入与导出

9、严格模式:
set hive.mapred.mode=strict; – 设置严格模式
设置严格模式后下面的语句将会报异常,应该加上分区条件
select * from user_trade limit 6;
– 加上分区条件
select * from user_trade where dt=‘2017-01-12’;
– 退出严格模式
set hive.mapred.mode=nonstrict;
严格模式建议都设置,查询时加上分区条件,有助于保护机器,它限制了三种查询,他所有的限制条件都是为了防止数据量太大
查询不出来(笛卡尔积你几天都查不完,limit 不也是限制数据量的吗)
1、分区表在查询时必须写分区条件
2、笛卡尔积不能查询(进行表关联的时候不写关联条件没办法查询)
3、使用order by进行排序时候必须加limit语句
10、方便的小技巧
.hiverc
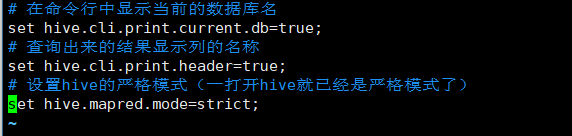
# 在命令行中显示当前的数据库名
set hive.cli.print.current.db=true;
# 查询出来的结果显示列的名称,但是效果有点乱,不太美观,不加了吧
set hive.cli.print.header=true;
# 设置hive的严格模式(一打开hive就已经是严格模式了)
set hive.mapred.mode=strict;
步骤:首先在hadoop的家目录中创建一个文件.hiverc
vim .hiverc
附件
在hdfs上创建hive数据存放目录
hadoop fs -mkdir /tmp # tmp目录其实已经存在了,在刚刚跑任务的时候就已经出现了
hadoop fs -mkdir -p /user/hive/warehouse
#给予权限
hadoop fs -chmod g+w /tmp
hadoop fs -chmod g+w /user/hive/warehouse
1.在hadoop的家目录下新建一个目录datas:
mkdir datas
2.通过xftp将数据源文件传到datas中
3.hadoop fs -mkdir /datas
4.hadoop fs -chmod g+w /datas 赋予权限
将本地Hadoop的数据上传到集群上去
5.hadoop fs -put /home/hadoop/datas/* /datas


--1.创建kaikeba库
create database if not exists kaikeba;
--2.使用kaikeba库
use kaikeba;
--3.创建user_info表
create table if not exists user_info (
user_id string,
user_name string,
sex string,
age int,
city string,
firstactivetime string,
level int,
extra1 string,
extra2 map<string,string>)
row format delimited fields terminated by '\t'
collection items terminated by ','
map keys terminated by ':'
lines terminated by '\n'
stored as textfile;
加载数据源
load data inpath '/datas/user_info/user_info.txt' overwrite into table user_info;
--4.创建user_trade表
create table if not exists user_trade (
user_name string,
piece int,
price double,
pay_amount double,
goods_category string,
pay_time bigint)
partitioned by (dt string)
row format delimited fields terminated by '\t';
执行如下命令以设置动态分区:
set hive.exec.dynamic.partition=true;
set hive.exec.dynamic.partition.mode=nonstrict;
set hive.exec.max.dynamic.partitions=10000;
set hive.exec.max.dynamic.partitions.pernode=10000;
将数据源文件上传到HDFS上
"hdfs dfs -put /home/hadoop/datas/user_trade/* /user/hive/warehouse/kaikeba.db/user_trade"
修复分区的作用是
修复分区表:新增加一个分区,将分区文件上传好之后需要重新检查一下分区是否增加,不修复分区的话查不到新增加的分区。
msck repair table user_trade;
查询:select * from user_trade limit 6;
严格模式:
set hive.mapred.mode=strict; -- 设置严格模式
设置严格模式后下面的语句将会报异常,应该加上分区条件
select * from user_trade limit 6;
-- 加上分区条件
select * from user_trade where dt='2017-01-12';
-- 退出严格模式
set hive.mapred.mode=nonstrict;
严格模式建议都设置,查询时加上分区条件,有助于保护机器,它限制了三种查询,他所有的限制条件都是为了防止数据量太大
查询不出来(笛卡尔积你几天都查不完,limit 不也是限制数据量的吗)
1、分区表在查询时必须写分区条件
2、笛卡尔积不能查询(进行表关联的时候不写关联条件没办法查询)
3、使用order by进行排序时候必须加limit语句
--5.创建trade_2017表
create table if not exists trade_2017 (
user_name string,
amount double,
trade_time string)
row format delimited fields terminated by '\t';
load data inpath '/datas/trade_2017/000000_0' overwrite into table trade_2017;
--6.创建trade_2018表
create table if not exists trade_2018 (
user_name string,
amount double,
trade_time string)
row format delimited fields terminated by '\t';
load data inpath '/datas/trade_2018/000000_0' overwrite into table trade_2018;
--7.创建trade_2019表
create table if not exists trade_2019 (
user_name string,
amount double,
trade_time string)
row format delimited fields terminated by '\t';
load data inpath '/datas/trade_2019/000000_0' overwrite into table trade_2019;
--8.创建user_list_1表
create table if not exists user_list_1(
user_id string,
user_name string)
row format delimited fields terminated by '\t'
collection items terminated by ','
map keys terminated by ':';
load data inpath '/datas/user_list_1/list1' overwrite into table user_list_1;
--9.创建user_list_2表
create table if not exists user_list_2(
user_id string,
user_name string)
row format delimited fields terminated by '\t'
collection items terminated by ','
map keys terminated by ':';
load data inpath '/datas/user_list_2/list2' overwrite into table user_list_2;
--10.创建user_list_3表
create table if not exists user_list_3(
user_id string,
user_name string)
row format delimited fields terminated by '\t'
collection items terminated by ','
map keys terminated by ':';
load data inpath '/datas/user_list_3/list3' overwrite into table user_list_3;
--11.创建user_fefund表
create table if not exists user_refund(
user_name string,
refund_piece int,
refund_amount double,
refund_time string)
partitioned by (
dt string)
row format delimited fields terminated by '\t';
执行如下命令以设置动态分区:
set hive.exec.dynamic.partition=true;
set hive.exec.dynamic.partition.mode=nonstrict;
set hive.exec.max.dynamic.partitions=10000;
set hive.exec.max.dynamic.partitions.pernode=10000;
将数据源文件上传到HDFS上
分区表使用的是put,这个是hadoop的命令,分区表里面会有好多文件夹,不是分区表直接load就好了
put是把本地的文件上传到hive里,然后在执行修复分区表
"hdfs dfs -put /home/hadoop/datas/user_refund/* /user/hive/warehouse/kaikeba.db/user_refund"
修复分区表:
msck repair table user_refund;
--12.创建user_trade_bak表
create table user_trade_bak(
user_name string,
piece int,
price double,
pay_amount double,
goods_category string,
pay_time timestamp)
partitioned by(
dt string)
row format delimited fields terminated by '\t';
执行如下命令以设置动态分区:
set hive.exec.dynamic.partition=true;
set hive.exec.dynamic.partition.mode=nonstrict;
set hive.exec.max.dynamic.partitions=10000;
set hive.exec.max.dynamic.partitions.pernode=10000;
将数据源文件上传到HDFS上
"hdfs dfs -put /home/hadoop/datas/user_trade_bak/* /user/hive/warehouse/kaikeba.db/user_trade_bak"
修复分区表:
msck repair table user_trade_bak;
--13.创建user_goods_category表
create table user_goods_category(
user_name string,
category_detail string)
row format delimited fields terminated by '\t';
load data inpath '/datas/user_goods_category/000000_0' overwrite into table user_goods_category;
id name
1 zhangsan
2 lisi
3 wangwu
4 zhaoliu
.....
















 138
138











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









