







抽象与接口
- 接口的字段只能是public static final类型


-
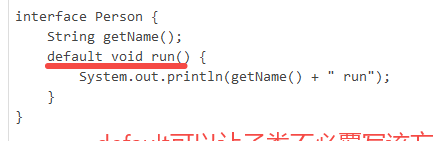
protected、private public、final作用域
- protected作用于继承关系。定义为protected的字段和方法可以被子类访问,以及子类的子类
- private不能被外部访问
- public都可以访问
- 被final修饰当作不变值,不能被修改
StringBuilder&StringBuffer&String
- string:https://www.cnblogs.com/hadoop‑dev/p/6908660.html
- StringBuffer可变字符串,线程安全
- 线程安全原因:在内部方法中直接synchronized关键字修饰,进行加锁操作
- StringBuilder可变字符串,线程不安全,不能并行
- 线程不安全:append方法中count+=len进行了加法操作,不能保持原子性,多线程会抢占该资源
- 执行速度:StringBuilder>StringBuffer>String
异常处理

- Exception分为两类:
- RuntimeException:不需要捕获的异常
- 非RuntimeException:需要捕获的异常
- throws 向调用层抛出可能存在的异常,低层调用没有捕获异常,顶层调用必须捕获异常try...catch
- throw new 。。。抛出异常
注解
集合
1、集合优势:
数组初始化后大小不可变
数组只能按索引顺序存取
2、List:
List中的contains方法中使用object.equals()方法判断两个实例的值是否相等【包括String以及包装类已经覆写了equals方法】,但是自定义的类未覆写equals方法,若要判断两个实例中值相等,需要通过覆写equals方法
(1)ArrayList
(2)LinkedList

3、Map
:空间换时间,用一个大数组存储所有value,并根据key直接计算出value应该存储在哪个索引
Map的实现类中的map.get(key)方法获取value值或者map.put(key,value)首先会比较是否有相等的key,该方法是通过object.equals()方法来判断两个key是否相等,但是map中定位value值是通过计算hashcode值进行定位的,因此两个实例可以判断值相等,但是不能保证hashcode一定相等,因此可以通过覆写object.hashcode()方法。
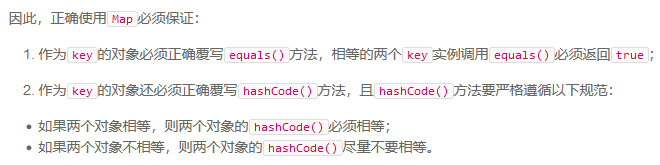
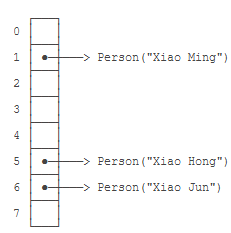
遍历方式:


(1)HashMap
HashMap扩容机制:

JDK8之后,HashMap采用“桶+链表/红黑树”存储方式:如果数组容量大于64且链表的长度大于等于8时,其内部便会将链表转化为红黑树的结构。红黑树的查询时间是O(log n)。
HashMap源码:
JDK1.7和JDK1.8区别:
JDK1.7:头插法、先扩容在计算、无红黑树
JDK1.8: 尾插法、先计算在扩容、扩容后的hash=原位置+原容量
初始化:HashMap在初始化时会创建一个Entity的数组。其个数为16

put()方法:首先计算key的hashcode,然后根据hashcode确定该Entity应该存放在数组的哪个位置,若出现hash碰撞,然后equals比较是否相等,若相等,则更新,若不相等,则连接已有Entity之前。
什么时候发生扩容:capacity 即容量,默认16。,loadFactor 加载因子,默认是0.75,threshold 阈值。阈值=容量*加载因子。默认12。当元素数量超过阈值时便会触发扩容。(每次扩容是之前容量的2倍)
hash位置计算:(n-1)&hash
hash实现,JDK1.8实现中,通过hashCode()的高16位异或低16位实现的:(h = k.hashCode()) ^ (h >>> 16),高低位混合运算,增加散列程度主要是从速度、功效、质量来考虑的,只需要关心扩容的那一位的hash值是0,则位置保持不变,是1那么hash=原位置+原容量
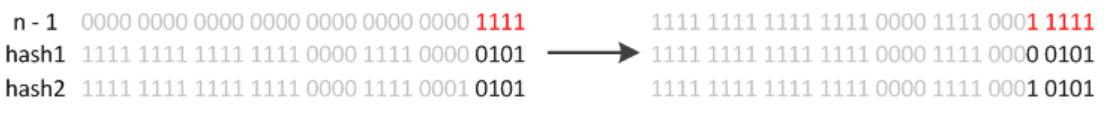
JDK8扩容机制:
- 首次put时,先会触发扩容(算是初始化),然后存入数据,然后判断是否需要扩容;
- 不是首次put,则不再初始化,直接存入数据,然后判断是否需要扩容;
线程不安全原因:
- JDK7:扩容函数transfer中头插链表可能会出现数据丢失问题
- JDK8:putval函数中,线程A判断完是否发生碰撞后,时间片用完,线程B插入数据,轮到A执行,由于之前判断过是否发生碰撞,不在进行判断,A插入数据可能会覆盖B的数据,而且++size不能保持原子性
(2)Hashtable(线程安全)
HashTable线程安全的策略实现代价大,get/put所有相关操作都是synchronized的,这相当于给整个哈希表加了一把大锁
(3)CurrentHashMap(线程安全,局部加锁)
- JDK7使用分段锁机制(Segment继承了ReentrantLock)
第一次Hash定位到Segment,第二次Hash定位到元素所在的链表的头部。
坏处:hash时间比HashMap长

- JDK8:使用volatile value保持可见性,putval 存储数据CAS进行重试,判断是否有其他线程并发,当hash位置是头节点,则使用 synchronized锁住该位置链表
初始化数组,首先判断是否有其他线程进行初始化,若无,则使用CAS设置某个值为-1,表示抢到锁,进行初始化

synchronized+CAS+HashEntry+红黑树
CurrentHashMap扩容机制:(JDK1.8)

- Set
- HashSet
IO操作

1、字节流(InputStream,OutputStream抽象类)
缓冲:返回的int是-1表示无缓冲数据执行
2、字符流(Reader、Writer接口)
多线程
1、线程创建方式
自定义类继承Thread,覆写run方法;
Runnable
Callable
//Thread
Thread t1 = new Thread();
t1.start();
t1.getName()
//Runnable
Runnable r = new MyRunnable();
Thread t2 = new Thread(r);
t2.currentThread.getName();
//Callnable, call方法可返回值
FutureTask task = new FutureTask(new Callable<V>(){
@Override
public Integer call() throws Exception {
// TODO Auto-generated method stub
return null;
}
});2、
网络编程
网络号=IP&子网掩码(两台主机网络号一致,说明处于同一网络)
Socket=IP+端口号 ,可以进行两个进程之间的通信
1、TCP编程
服务端:
ServerSocket ss = new ServerSocket(6666);//指定服务端端口号
Socket socket = ss.accept();//表示当有客户端连接进来后,返回Socket实例
socket.getRemoteSocketAddress();//获取客户端的IP+端口号
InputStream input = this.socket.getInputStream();//获取Socket中的输入输出流
OutputStream output = this.socket.getOutputStream();
客户端:
Socket socket = new Socket("localhost",6666);//客户端创建Socket流,连接指定的IP+端口号
InputStream input = sock.getInputStream();//socket的输入输出数据,根据输入输出数据进行进程通信
OutputStream output = sock.getOutputStream();2、UDP编程
服务端
DatagramSocket ds = new DatagramSocket(6666); // 监听指定端口
// 数据缓冲区:
byte[] buffer = new byte[1024];
DatagramPacket packet = new DatagramPacket(buffer, buffer.length);
ds.receive(packet); // 收取一个UDP数据包
// 收取到的数据存储在buffer中,由packet.getOffset(), packet.getLength()指定起始位置和长度
// 将其按UTF-8编码转换为String:
String s = new String(packet.getData(), packet.getOffset(), packet.getLength(), StandardCharsets.UTF_8);
// 发送数据:
byte[] data = "ACK".getBytes(StandardCharsets.UTF_8);
packet.setData(data);
ds.send(packet);客户端:
DatagramSocket ds = new DatagramSocket();
ds.setSoTimeout(1000);
ds.connect(InetAddress.getByName("localhost"), 6666); // 连接指定服务器和端口
ds.disconnect();














 1107
1107











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









