







Zookeeper选举机制
一、选举机制介绍
zookeeper是按照Paxos算法进行选举的,这个算法也称之为半数选举机制。
所有节点都有投票权,当一个几点票数过半,这个节点就是leader。
zookeeper机制规定,当有新的节点加入时,没有选举出leader时之前票数作废,重新投票。
leader产生后,其他节点投票给leader。
1)半数机制:集群中半数以上机器存活,集群可用。所以Zookeeper适合安装奇数台服务器。
2)Zookeeper虽然在配置文件中并没有指定Master和Slave。但是,Zookeeper工作时,是有一个节点为Leader,其他则为Follower,Leader是通过内部的选举机制临时产生的。
二、全新(第一次启动)的集群选举机制
第一次启动的集群,无数据状态下的选举
举个例子:假设有五台服务器组成的Zookeeper集群,它们的myid从1-5,同时它们都是最新启动的,也就是没有历史数据,在存放数据量这一点上,都是一样的。选举流程如下:
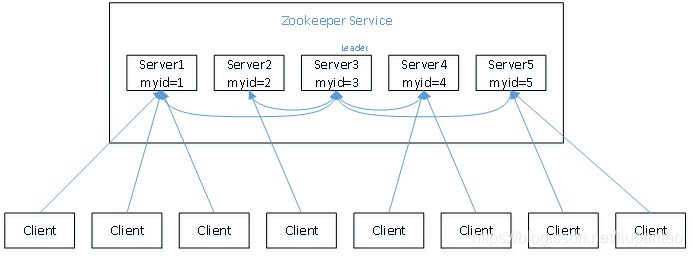
共五人参加选举,第一轮只能选自己,获得选票大于半数时或者为半数以上时,
成为leader.(5的半数是2.5,半数以上是3,所以投票结果=3时,就胜出,成为leader)
回合一:
A启动,开始第一轮选举,A选择自己.
第一轮投票结果:[(A-->A)]
A只获得一票,此时只有它一台服务器启动了,它发出去的报文没有任何响应,,进入LOOKING(竞选状态)。
回合二:
B启动起来,投票给自己,告诉其他人,并接收到A的(第一回合)投票信息;
此时,A接收到B的(第二回合)投票信息,A知道进入第二回合了,重新投票,由于B的myid大,所以A投给了B.
第二轮投票结果:[(A-->B),(B-->B)]
B获得两票,但是仍小于3,所以A,B进入LOOKING(竞选状态)。
回合三:
C启动起来,投票给自己,告诉其他人,并接收到了A和B的(第二回合)投票信息
此时,AB也接收到了C的投票信息,一看第三回合了,重新投票,由于C的myid最大,
A,B就将自己的一票都给了C.
第三轮投票结果:[(A-->C),(B-->C),(C-->C)]
C获得三票,3为半数以上,所以C称为leader.
剩下回合,由于C获得的票数已经超过半数,已经称为leader,所以D和E的投票是不能改变现实的,只能成为跟随者.
=============有人可能会疑问,D的leader比C大啊,他们应该都选D啊?=================
不要误解了,当集群中没有leader的时候,大家在新的回合会将自己的一票投给myid大的节点,
但是如果已经有了leader,那在新的回合将不会改变他们的投票信息
三、非全新(数据恢复)的集群启动
初始化的时候,是按照上述的说明进行选举的,但是当zookeeper运行了一段时间之后,有机器down掉,重新选举时,选举过程就相对复杂了。
需要加入数据id、leader id和逻辑时钟。
数据id(zxid):数据新的id就大,数据每次更新都会更新id。
myid:就是我们配置的myid中的值,每个机器一个。
逻辑时钟(epoch):这个值从0开始递增,每次选举对应一个值,也就是说: 如果在同一次选举中,那么这个值应该是一致的 ; 逻辑时钟值越大,说明这一次选举leader的进程更新.
选举的标准就变成:
1. 逻辑时钟小的选举结果被忽略,重新投票
2. 统一逻辑时钟后,数据id大的胜出
3. 数据id相同的情况下,leader id大的胜出
根据这个规则选出leader。














 2472
2472











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









