






文章目录
前言
这是一个希望能持续更进的项目。
基于mysql数据库的深度学习框架封装
1.项目的研究背景与目的
1.1研究背景
数据库系统(DataBase System,DBS)是指一个完整的、能为用户提供信息服务的系统。数据库系统是引进数据库技术后的计算机系统,它实现了有组织地、动态地储存大量相关数据的功能,提供了数据处理和信息资源共享的便利手段,。而数据库技术是一门研究数据库结构、存储、管理和使用的软件技术。
机器学习通过从历史数据和行为中分析、学习 找到更好的设计方案,可以解放很多繁杂的手工工作。因此机器学习技术已经被广泛的运用到多个科研和生产领域。机器学习也为数据库技术带来了新的机遇。传统机器学习模型,如线性感知器、随机森林、支持向量机和集成学习等,能够在历史数据中积累“经验”,提高模型解决复杂问题的能力。
1.2研究目的
目前大多数深度学习实验数据基于文件夹或者csv格式存储,实验的数据预处理阶段会耗费大量的时间在文件数据和模型连接上。因此将一些常用的深度学习框架和数据库进行高级的封装具有一定的实践价值。通过数据库的方式来管理数据,在此数据封装的基础上再提供一些高级API,快速的搭建新的模型,进一步节约了检验算法和数据的有效性的时间,提高了实验生产力。
本项目希望在mysql数据库基本语句的基础上封装python的高级API,通过调用封装API快速搭建各种深度学习算法实验。
2.项目内容
2.1软件基本架构
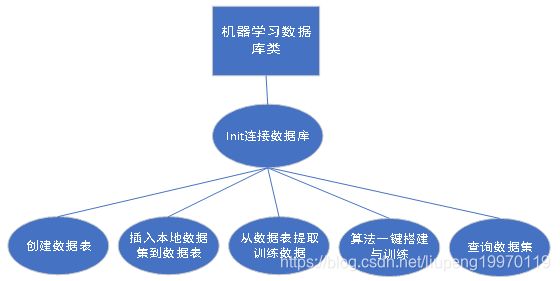
本项目旨在设计多个机器学习数据库类,由于时间的问题目前只设计了一个简单的基本架构类。
类:
机器学习数据库类class PyMysql():该类包含了初始化,创建表,删除表,数据集插入,训练数据集提取,算法训练,查询数据集。
方法:
初始化__init__:传入本地ip,账号,密码连接mysql数据库。
创建表CreatTable:创建一个数据表用于存储数据。
删除表DelTable:删除创建的数据表。
查询数据AcquireData:查找表中所有数据。
插入本地数据到数据表InsertData2Table:将数据按照固定格式放入文件夹,该方法自动将数据存入数据表中。
从数据表提取训练数据DrawData2Numpy:将数据表中的数据和标签转换成numpy格式数据,作为模型训练数据。
算法搭建ChoseModel:通过传入的参数一键配置算法和训练过程。
2.2软件实现步骤
Step1: 安装mlsql,学习基本用法
参考https://blog.csdn.net/liupeng19970119/article/details/106586495
Step2: 安装pymysql和keras深度学习框架:
Pip install pymysql,keras,tensorflow等。
Step3: 从github中下载手写数字集(小型):
Setp4: 构思封装类的方法:连接,创建表,删除表,查询表,导入数据,提取数据,搭建算法。
**Setp4.1:**构建init函数
def __init__ (self, host="127.0.0.1", user="root", password="192218", db="minist"):
self.connection = pymysql.connect(host=host,
user=user,
password=password,
db=db)
类初始化函数负责连接服务器,默认自动连接本地的minist数据库。
**Setp4.2:**创建表
def CreatTable(self,tableName="test",size=20):
cur = self.connection.cursor()
tempCmd = "CREATE TABLE " + tableName + "(lable INT NOT NULL, picdata BLOB,datasize INT)"
print(tempCmd)
cur.execute(tempCmd)
self.connection.commit()
self.connection.close()
默认创建test表,将数据表分成三个字段,第一个字段存放数据的标签,第二字段存放图像的数据,第三个字段存放图片的大小(默认图片长宽一致)
**Setp4.3:**向表里插入数据
def InsertData2Table(self,filePath ="NULL",tableName ="NULL",size=20):
picDirs = os.listdir(filePath)
cur = self.connection.cursor()
for picdir in picDirs:
lable = picdir
print(lable)
picdirs = filePath+picdir+'/'
print(picdirs)
piclist=os.listdir(picdirs) # get lable's dir
#print(len(piclist))
for pic in piclist:
oldPath=picdirs+pic # pic dir
fp = open(oldPath, 'rb')
img = fp.read()
fp.close()
sql = "INSERT INTO test1 VALUES (%s, %s, %s);"
args = (lable,img,str(size))
cur.execute(sql, args)
self.connection.commit()
self.connection.close()
使用遍历方式将项目的固定位置的数据插入到数据表中。
**Setp4.4:**提取表中数据
def DrawData2Numpy(self,tableName ="NULL",size=20):
cur = self.connection.cursor()
X =[]
Y =[]
try:
.....
将表中数据和标签遍历存储到X,Y中.
**Setp4.5:**训练数据:
def ChoseModel(self,name="simple_CNN",optimizers="adam",validation_splits=0.1,epoch=10 ,batch=64,saveModel=False,size=20):
input_shape = (size, size, 1)
...........
该部分工作量最大,在此之前我添加了5个modle的搭建,从简单的simple_CNN到复杂的xception,更换模型只需要将名字换成预先定义好的模型name即可。此外我通过多个if调整训练的超参数,例如epoch,batch,输入大小等。
**Setp4.6:**实例化类并调用方法:
test = PyMysql()
test.CreatTable("test",20)
test.InsertData2Table("./filedata/",'test',20)
test.DrawData2Numpy('test1',20)
test.ChoseModel("simple_CNN","adam",0.1,50,64,True,20)
创建test实例之后依次调用上面定义好的方法,简单完成框架封装。
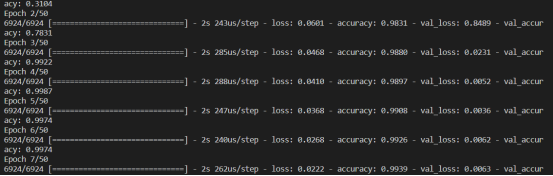
训练过程:
2.3软件运行环境
本项目在window下运行、mysql服务器采用8.0.20版本、在anaconda中管理python3.7并安装python支持包,需要注意由于源访问限制,需要将包源更换为国内的镜像。python第三方包的版本参照conda生成的.yml文件。
3.问题分析
在完成项目的过程中由于作者自身水平有限,仍然存在以下问题:
1.在设计过程中发现有时表名变量无法使用 str类型表示,网上参照了部分方法仍然没有得到解决,因此本项目暂时不能控制表的变化,理论上是可以的,但是需要时间debug。
2.目前封装的方法不够,数据表的一些增删改查方法并没有封装成对整个数据集操作的API,需要进一步完善。
3.方法的传入参数需要进一步完善,可以让用户更充分使用深度学习框架原生的接口。
4.没有添加特征工程的一些接口,增加特征工程接口可以让类的方法更完善。
5.代码存在一定不规范,变量和函数需要严格定义,便于后期继续设计。
4.总结与思考
4.1总结:
本项目简单实现了一些深度学习算法和数据库的整合,使用单个类完成整个训练过程,该方法初衷是减轻算法工程师在数据处理和特征提取时间成本,让算法工程师和研究者将更多的时间放在理论研究中。(一个深度学习的项目百分之七十时间都在改数据,选特征。。。。)目前只是实现了最基础的功能,有的实现功能还得持续完善。为了督促自己,我将整个project放到github:https://github.com/liupeng678/Database4Ml,笔记上传到我的博客:https://blog.csdn.net/liupeng19970119/article/details/106596460。希望我在有精力的情况下持续跟进。
4.2思考:
如果这个工作有价值的话,是不是可以继续跟进?例如将工作部署到web中,我们通过数据库整合一些常用的数据集,并支持用户按照固定形式上传自己的数据集,通过简单的WEB界面交互将用户想要选择算法和训练配置传入后端,后端根据用户选择的参数设置脚本自动从数据库中训练数据,自动生成相应的简洁算法代码。














 2319
2319











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









