







 本文概述了后端领域的关键概念,包括web框架、分布式中间件、分布式数据系统和云原生。重点讨论了分布式系统的构建思想,如冗余设计、水平扩展、最简单原则和微服务化。还提到了RPC实现的关键技术,以及大数据处理与分析的重要性。
本文概述了后端领域的关键概念,包括web框架、分布式中间件、分布式数据系统和云原生。重点讨论了分布式系统的构建思想,如冗余设计、水平扩展、最简单原则和微服务化。还提到了RPC实现的关键技术,以及大数据处理与分析的重要性。
init
background
这一部分我们学习后端的基础工作梳理,通过对比知道后端的各个模块都在做什么。
Content
后端领域的综述
| theme | 传送地址或者参照 | 概述 |
|---|---|---|
| 后端 | ++++++++++++++++++++++++++++ | ++++++++++++++++++++++++++++++++++++++++++ |
| – | – | – |
| 后端的整体认知 | 后端项目基本上就是这套结构, 大部分项目都逃不掉。 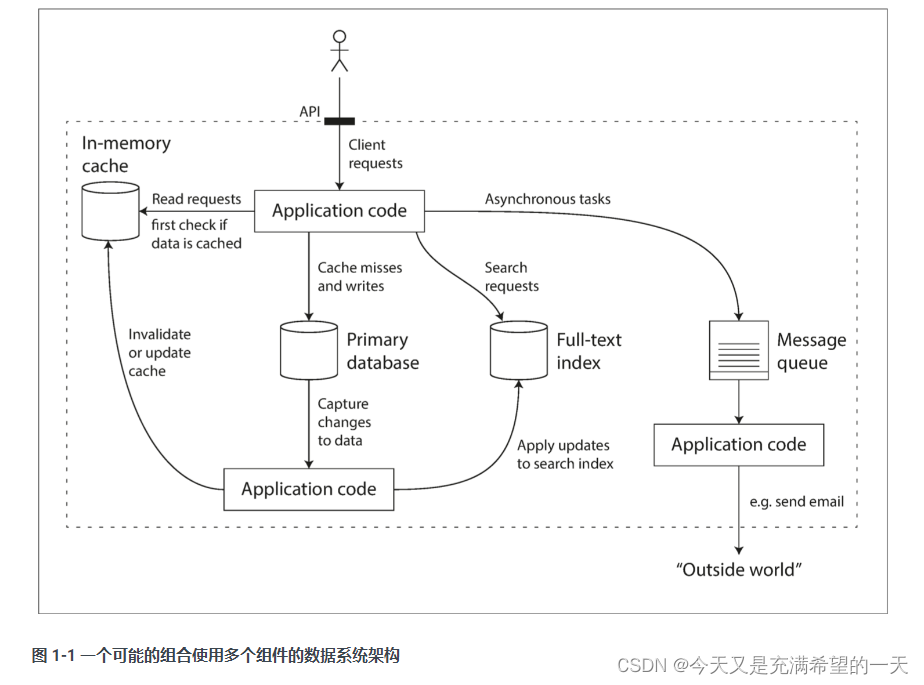 这个项目中, 先访问缓存, 缓存没有的话访问磁盘数据库, 然后数据库内容更新到索引查询和redis中, 然后数据通过异步分发出去。 在这个框架中, 不论什么redis, mysql都是在抽象我们日常后端的工作。 要么访问之前存储过的数据, 这个过程要加速可以用缓存, 要么模糊访问之前的数据(索引和搜索), 要么往其他进程中发送数据通信(流处理)和定时的任务大批量处理(批处理)。 所有的后端都是在做对数据的各种场景处理,于是有了各种mysql, redis等东西。 但是这些东西现在功能你会发现都有重叠, 例如redis现在能永久存储了。 但是普通后端和分布式后端的区别在于分布式是为了将多个多个机器合并到一个机器, 为了解决单机存储的问题, 弄了分布式存储hdfs, 为了解决大数据的结构存储在hdfs之上弄了hbase做数据的存储。 为了解决分布式计算的话用了mapreduce, 为了解决 各种分布式节点的数据交互问题, 用了rpc或者http隔离了语言的不同, 为了解决同种类型数据节点一致问题用了zookeeper, 为了解决数据大量复杂交互的问题用了kafka。 可以看到过去单机上的知识其实已经不太够了,对于单机web, 其实就会一些网络框架的使用, 然后学一些数据结构算法, 单机的业务分层, 最多业务模块多布置几个的技术开发。 但是现在分布式不能这样了, 你需要理解同个任务被很多节点消费或者处理的场景, 他们共同形成了一个超级服务, 共同提供服务, 而且分布式的话一般不是web而是web调用的业务接口后面的子模块, web服务这边不会弄成分布式吧, 他就是在整合分布式的结果, 算是业务层。 这个项目中, 先访问缓存, 缓存没有的话访问磁盘数据库, 然后数据库内容更新到索引查询和redis中, 然后数据通过异步分发出去。 在这个框架中, 不论什么redis, mysql都是在抽象我们日常后端的工作。 要么访问之前存储过的数据, 这个过程要加速可以用缓存, 要么模糊访问之前的数据(索引和搜索), 要么往其他进程中发送数据通信(流处理)和定时的任务大批量处理(批处理)。 所有的后端都是在做对数据的各种场景处理,于是有了各种mysql, redis等东西。 但是这些东西现在功能你会发现都有重叠, 例如redis现在能永久存储了。 但是普通后端和分布式后端的区别在于分布式是为了将多个多个机器合并到一个机器, 为了解决单机存储的问题, 弄了分布式存储hdfs, 为了解决大数据的结构存储在hdfs之上弄了hbase做数据的存储。 为了解决分布式计算的话用了mapreduce, 为了解决 各种分布式节点的数据交互问题, 用了rpc或者http隔离了语言的不同, 为了解决同种类型数据节点一致问题用了zookeeper, 为了解决数据大量复杂交互的问题用了kafka。 可以看到过去单机上的知识其实已经不太够了,对于单机web, 其实就会一些网络框架的使用, 然后学一些数据结构算法, 单机的业务分层, 最多业务模块多布置几个的技术开发。 但是现在分布式不能这样了, 你需要理解同个任务被很多节点消费或者处理的场景, 他们共同形成了一个超级服务, 共同提供服务, 而且分布式的话一般不是web而是web调用的业务接口后面的子模块, web服务这边不会弄成分布式吧, 他就是在整合分布式的结果, 算是业务层。 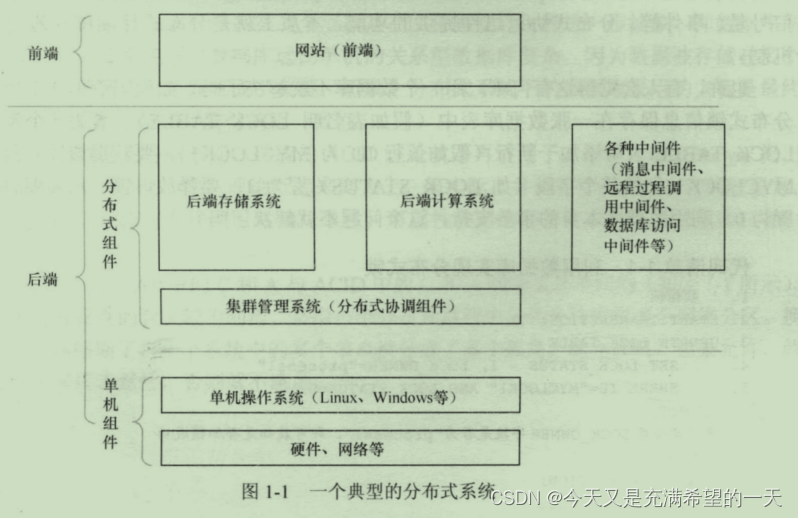 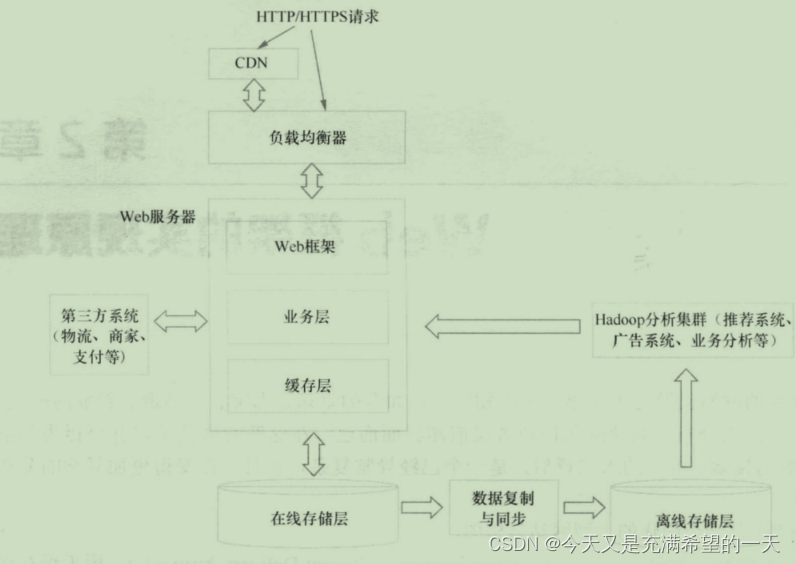 此外分布式业务一般就是这样的。 和上面类似, 通过上面的技术栈来形成类似的架构, 这里离线层和在线存储层通过数据同步是为了避免大量数据处理分析影响到线上服务。 此外分布式的知识差不多如下: 整体围绕拆分、调用、协同、计算、存储、调度、高性能高可用、监控几个问题进行设计。 首先就是拆分, 业务的拆分不能太细节也不能太广, 太细节调度非常繁琐、太广起不到分布式的作用。 因此应用的服务划分一般都是专家根据经验和方法论搞的,他们是根据业务进行划分的。 ddd就是实现这个,具体我们到时候看。 服务拆分后, 调用就不是很方便了, 这里面就需要解决服务注册和发现以及rpc, 他们一个是为了感知服务一个是为了传输服务; 然后协同的话就是各种节点能够干成一件事情, 这里面就是用zk还有背后的原理; 然后海量数据就需要计算, 这种对各种节点的计算就是mapreduce和strem等; 然后就是数据存储了, 分为各种干西行数据库、非关系型数据库等; 为了让服务更好的调用和利用就用到了k8s; 然后为了服务高可用就是各种应用策略设计方案 ; 然后最后就是服务的监控等 。 这些东西做好了, 分布式自然效果会好。 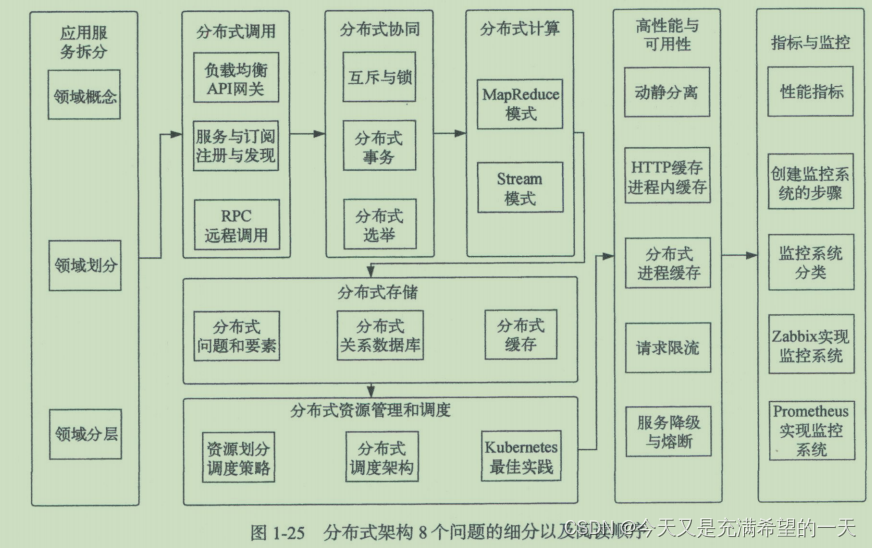 | |
| 分布式架构的发展过程 | 最开始是单机应用和数据在一起; 然后应用和数据分开,数据存放到另外一个机器上; 然后开始加了数据缓存解决热点访问问题; 然后加了负载均衡解决大并发的访问问题; 然后加了数据库读写分离让多个库读少量库解决写解决写性能慢的问题; 然后通过反向代理和cdn解决缓存和各种网络隐藏信息等;然后为了解决数据越来越多问题,开始了分库分表; 然后解决业务复杂问题, 将应用进行拆分, 分为各种业务和核心组件, 并且对核心组件设置了水平拓展。 这样就衍生了分布式rpc、消息中间件,kafka等工具; 然后这样拆分各个节点调用关系复杂,而且之前基本是基于业务进行划分, 插接的不够合理, 并且管理复杂。 因此微服务就是docker + 更符合业务设计的拆分。 举个例子就是电商系统, 用户访问一个cdn和反向代理做一层缓存和过滤。 然后进入到分布式的API网关层 , 将请求打入真正的分布式服务中, 在这里先调用商品系统, 商品系统访问数据库和缓存返回商品。 用户点击下单之后调用订单服务去执行数据的修改, 然后下单成功发送一个后台消息mq。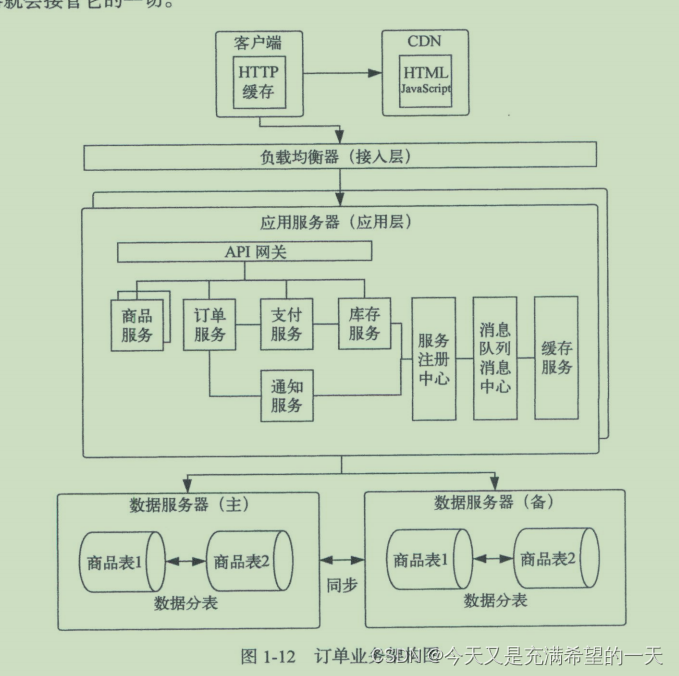 | |
| 分布式案例架构之google搜索 |  | 淘宝的架构可以看到前面cdn, 后台先是web这种业务层, 然后将通用的业务搞成服务层,让各种业务层通过rpc客户端来回调用。 然后还有数据库层的封装和各种其他分布式常用的模块。 需要注意这个每个模块里面可能是分布式的,但是功能不同。 |
| 分布式案例之淘宝的阿里云 | 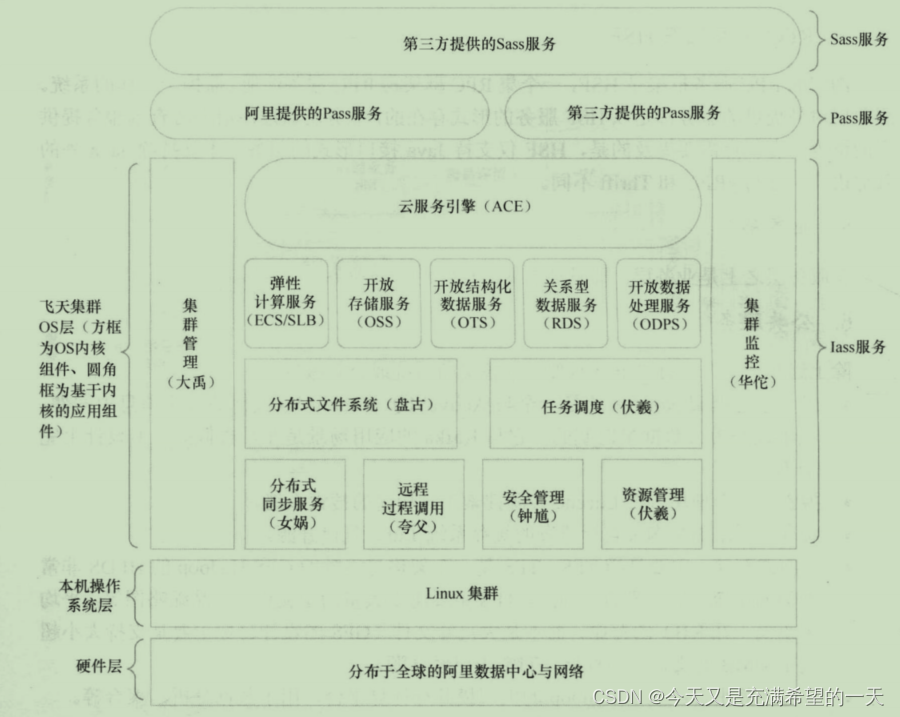 | 阿里云提供了他们的分布式节点使用权限和操作。 分布式同步系统、远程调用、集群任务管理和操作、文件系统、 |
| 分布式案例之linkin | 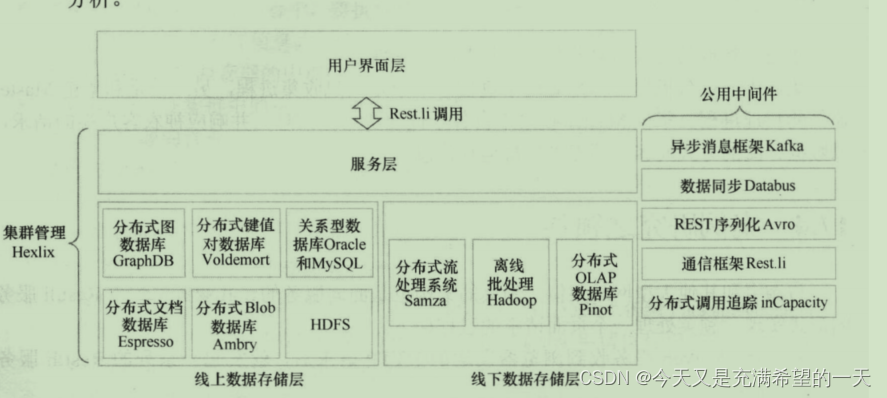 | 首先用用户的请求发送过来后, 业务层以rpc的方式访问服务层, 这些服务层各自负责不同功能, 但是最终会调用其他服务的rpc, 底层服务就从缓存、sql、nosql中获取数据, 新数据离线放到数据仓库并继续填充到线上数据上。 我们先来看下分布式文档数据库是存放用户资料的,底层是将单个mysql当成了分布式数据存储节点, 上面zk和master服务器,数据更新后会通过databus。 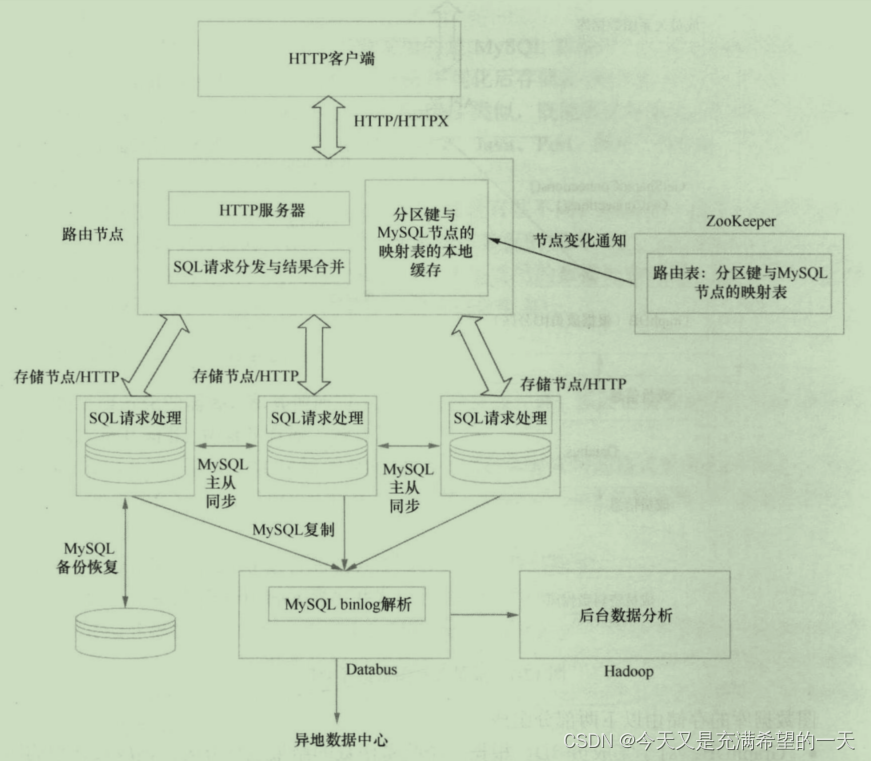 存放成员关系的图数据库, 数据从之前的成员资料数据库中传过来。 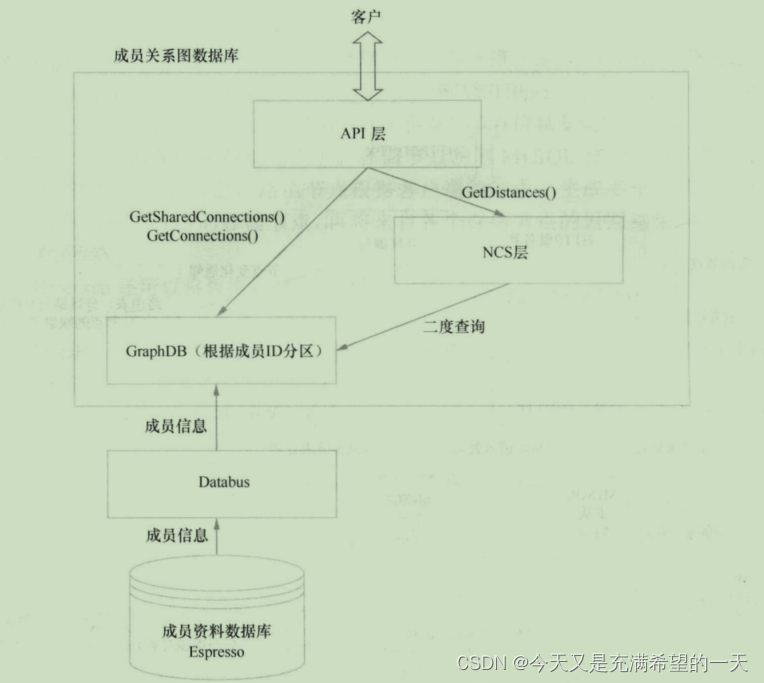 还有就是离线的数据仓库, 里面存了大量历史数据和消息都放到这里, 然后在这里可以进行数据分析等操作。 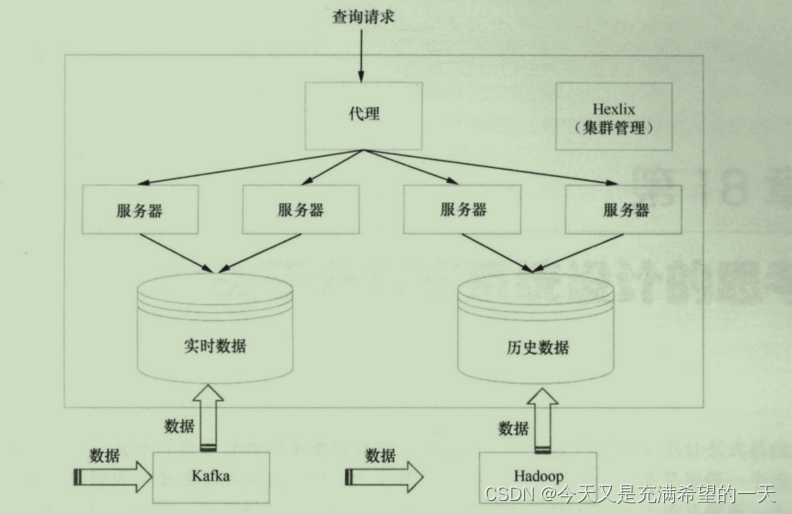 其他的服务监控、集群管理等东西就不说了, 也是自研的。 其他的服务监控、集群管理等东西就不说了, 也是自研的。 |
| 如果你的项目不需要分布式, 就不要用, 过度设计是原罪 | Blog: | 分布式会有很多细节问题是单机遇不到的, 学习可以, 但是一般项目不要用, 谢谢。此外单机的优势 |
| 数据系统的可靠性, 可伸缩性, 可维护性 | Blog: | 数据系统的三大属性, 可靠性就是错误的时候还能工作。 这时候需要避免人为操作失误,机器故障,软件bug等。 这些可以通过单元测试, 最小化模块, 告警等解决。 可扩展性就是可以通过横向扩展和纵向扩展提升服务的负载,但是需要注意这里要考虑业务场景,不同场景有不同的架构。虽然不同, 但是基本分为几种类型。 可维护性 : 首先就是复杂度降低,可以通过抽象和简单性去避免。 |
| 分布式本身是一次次的演化, 但不是银弹, 怎么理解分布式的演化 | 分布式本身 不是一门技术, 而是一种道理, 对于道的学习, 不同级别的人理解不一样, 需要从需求点和问题上出发。 分布式的演化趋势就是可以犯错。 从大型单机开始, 这种改动一个功能, 所有服务都要暂停,而且不容许节点犯错。 但是大型单机的优势就是通信成本低, 是函数级别的, 开发速度快; 之后为了能犯错, 就开始了soa模式探索,soa之前 有三种拆分的方式, 烟囱方式的忽略了交互, kernel插件方式的忽略了插件级别的交互, 事件驱动方式的以一个事情一串行动去做。之后是soa提供了一种严格的标准去保证交互。 之后就提出了微服务,是一种soa的应用, 微服务相比较soa最大的就是自由, 你看一个rpc调用就有很多种,并且用到什么就加什么框架, 但是自由的弊端就是对自己的设计要担责任,可能会设计的不好。 后微服务时代就是云原生,开始用docker和k8s去编排软件应用, 各种节点阶段的治理。 云原生之后还有一个升级就是服务网格, 管理单个节点的动态变化,将服务之间的管理和交互再一层抽象。 最终目的就是像本地调用一样只关注业务, 让框架做这些服务注册、服务交互等东西。 |
web框架相关的
| theme | 传送地址或者参照 | 概述 |
|---|---|---|
| 后端 | ++++++++++++++++++++++++++++ | ++++++++++++++++++++++++++++++++++++++++++ |
| – | – | – |
| web框架的综述 | Blog: | web框架基本上都是epoll + 消息队列+ 任务分发。 一般是MVC方式来操作的。 一般框架还提供了各种对中间件的操作等等。在刚开始的时候, 其实我对各种框架并不理解, 总觉得他们是各种孤立的个体, 例如我知道java要学习spring boot ssm这些, python要学习django flask 等等这些。 但是我其实并不知道他们的关系, 直到我开始工作前看了一个webserver和muduo才明白这些东西都是一个套东西。 他们都是各自语言根据自己的对应操作系统的socket接口加上线程接口和epoll等等, 搭建了一套带有池化的请求服务, 并且在这个基础上, 将很多通用的功能通过模板设计模式搞成了模板, 然后开放给大家使用。 关于这部分其实我不想说太多, 基本就是epoll 通过一个红黑树管理 上千个socket, 同步请求的话拿到有相应的socket放到一个队列中, 然后让缓存好的线程池进行消费。 参照这个大佬的博客讲解或者施磊老师的课程就行, https://blog.csdn.net/shenmingxueIT/article/details/113806437?spm=1001.2014.3001.5502, webserver怎么实现的就参照牛客网的那个课程, 学习一下基本就差不多了。 如果想要做项目, 就做牛客网的那个课程哈。 |
| django的开发使用 | Blog: | |
| spring boot的开发使用 | Blog: | |
| vue的开发使用 | Blog: | dd |
| 反向代理和负载均衡 | Blog: | 反向代理就是影响后端的信息,用niginx 负载均衡分为dns端设置多个ip的均衡、 还有硬件负载均衡, 还有就是软件的负载均衡。 负载均衡分为两种, 一种应用层的, 一种网络itcp层的。 |
分布式中间件
| theme | 传送地址或者参照 | 概述 |
|---|---|---|
| 后端 | ++++++++++++++++++++++++++++ | ++++++++++++++++++++++++++++++++++++++++++ |
| – | – | – |
| 分布式协同中间件zookeeper | 服务发现接口一般用zk或者dns, 然后套一些平衡啊什么的。 | 分布式服务之间, 一个服务可能有和很多分布式节点来处理, 并且告诉处理结果。 那么这些节点有些机器可能因为网络或者延时问题,算出来的结果和其他的分布式节点不一样, 这时候就是zookeeper等内部通过zab或者paxos协议来做,一般常见的zk做分布式节点做法是分布式任务节点调度。 首先分布式节点要有一个管理者master, 这个master要在zk上创建一个master目录, 谁能创建谁就是master。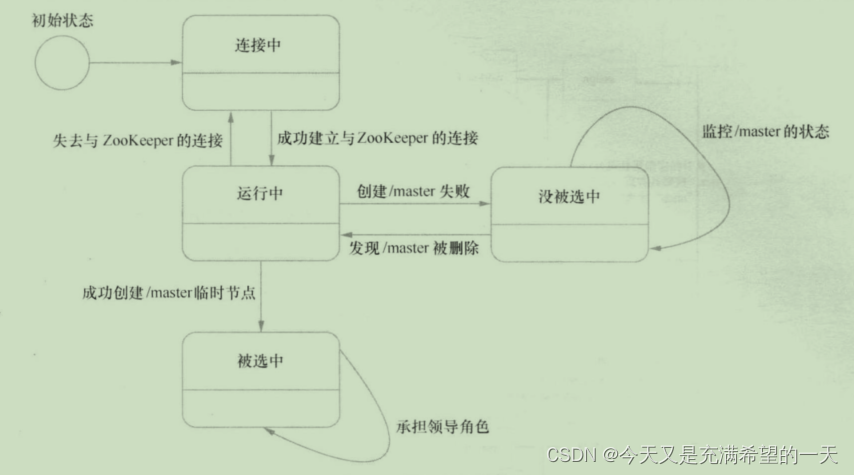 然后各个工作节点在zk上注册, 任务也要注册到上面, master对任务进行分配, worker完成具体的任务后在zk上提交状态,客户端通过zk状态回调感知任务的完成状态。 然后各个工作节点在zk上注册, 任务也要注册到上面, master对任务进行分配, worker完成具体的任务后在zk上提交状态,客户端通过zk状态回调感知任务的完成状态。 |
| 数据访问中间件mycat | 可以通过中间件去访问分布式的数据库, 这些数据库提前根据业务分成多个节点。 或者调整业务的权重。 例如访问中间件背后查询服务发送到10个机器, 写入服务只用一个机器。 这些机器相互同步。 | |
| 分布式远程调用中间件 | 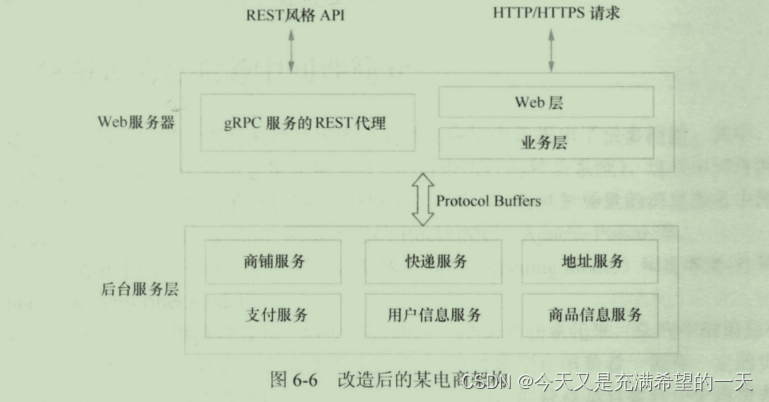 | 远程服务定义就是互不重合的内存空间中两个程序以同步的方式和有限网络带宽去传输数据。 可以看到, 一个集中式的业务可以通过分布式拆分成这样的。 他们之间的拆分就是通过rpc。 常见的rpc有brpc, dubbo,grpc等。 其中dubbo是支持分布式注册和治理的。 如果你要用brpc的好像是要自己管理注册和治理(当然他内部也有 实现, 但是很基本简单), 而且brpc是解决内部服务之间的相互调用, epoll + pb实现的, 不对外。 grpc是在pb里面封装了http协议,虽然http2端口可以复用,但是还是比较浪费的。 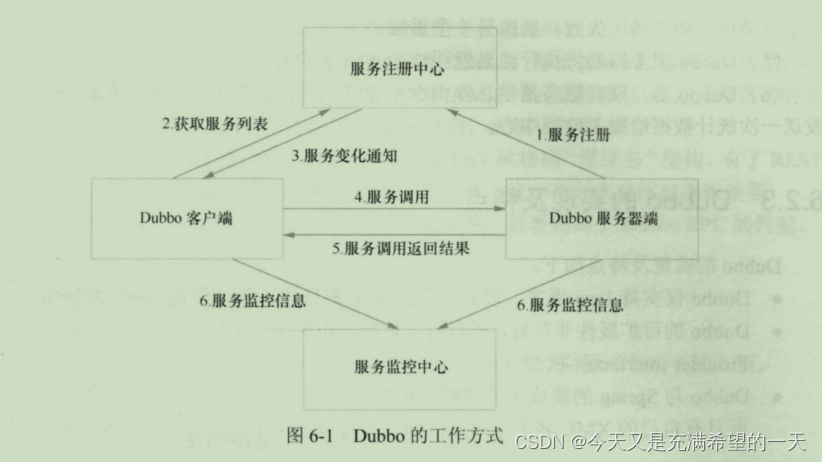 rpc需要有三个功能: 数据表达,序列化就是为了不同程序和硬件上数据保持一致性的中间产物。数据传输: 一般就是http和tcp等;如何传输方法(uuid) |
| rest设计风格 | 他是一种http以资源为中心的接口设计规范, 很人性化。 但是这种面向资源的编程思想只适合cudr, 面向过程或者对象才能处理复杂业务。 而且不适合高性能和批量事务场景。 | |
| ***事务相关的知识 | 主要分为4种, 一种是单个服务单个数据源、单服务多数据源、多服务单个数据源、多服务多数据源。事务太复杂了, 先跳过。。。。 但是解决事务的过程还是非常重要的, 它是给出了所有数据一致性和交互问题的解决方案, 而且取决于业务的需求来设计。 | |
| 各种性能优化点 | 之前讲过, 参照以前的一些图片吧,这里太多了。 | |
| 分布式共识算法 | 让一堆节点工作时候能够容忍暂时的不同状态, 但是最终保持一致性, 外部还看不出来。 这就是分布式共识算法, 和事务那种一致性不一样, 分布式共识一致性是解决节点的之间的一致, 事务是数据交互时候的一致性。 最开始就是paxos, 说的是如果一次提议, 如果超过半数人同意, 就全局生效, 其他节点无条件接收。 | |
| 分布式消息中间件kafka | 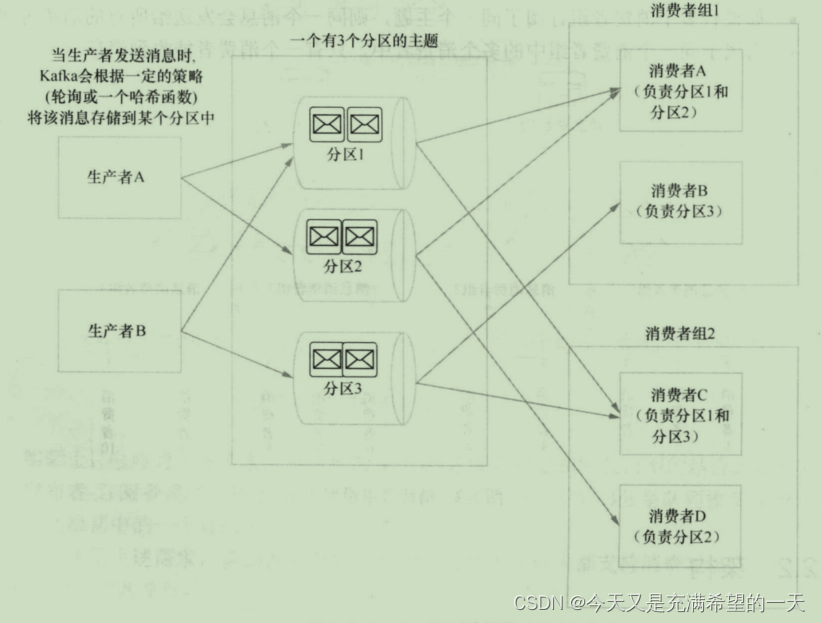 kafka通过消费组实现了发布订阅, 通过消费者实现队列执行, 实现消息中间件的功能。 他能够解耦其他系统,或者削减流量或者定时触发任务。 例如手机充钱后写kafka触发短信提示功能。 kafka通过消费组实现了发布订阅, 通过消费者实现队列执行, 实现消息中间件的功能。 他能够解耦其他系统,或者削减流量或者定时触发任务。 例如手机充钱后写kafka触发短信提示功能。 | |
| 分布式服务追踪中间件 | 这个就是解决电商等系统上服务节点的走向, 看看到底走到了哪里。 |
分布式数据系统
| theme | 传送地址或者参照 | 概述 |
|---|---|---|
| 后端 | ++++++++++++++++++++++++++++ | ++++++++++++++++++++++++++++++++++++++++++ |
| – | – | – |
| 分布式文件系统, 和分布式存储的区别 | 普通的mysql等关系型数据系统因为强一致性要加锁, 水平扩展很难。而且支持的数据量有限, 因此 产生了nosql。 数据可以存到nosql中(nosql底层不少是分布式系统), 或者分布式文件系统中,或者存到搜索系统中(这个查找很快)。 下面先介绍分布式文件系统底层如下, 数据节点是存放块数据的。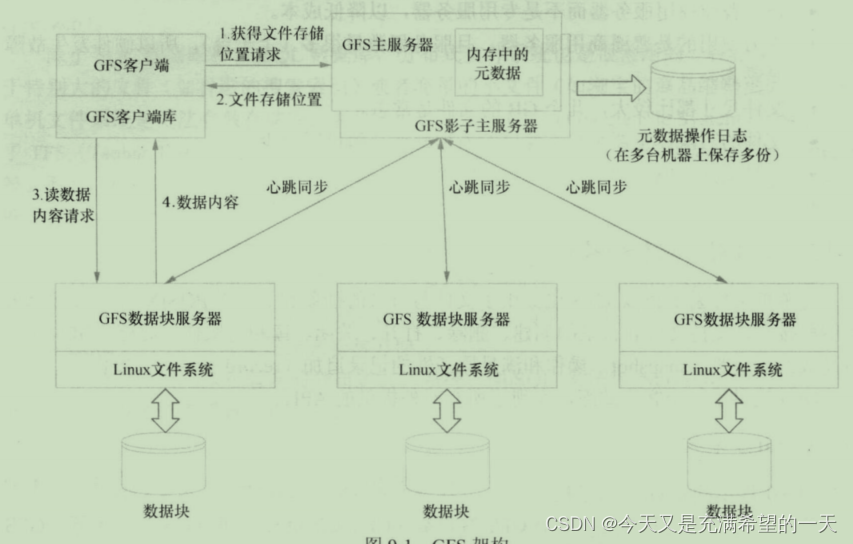 一般分布式文件系统用来存储视频, 还有一些数量很多的小文件, 普通的单机文件系统磁盘查找这些文件很慢, 而分布式的话会将小文件放到一个磁盘块。分布式存储类似于分布式数据库, 相比较文件系统有提取分析数据的能力。 此外你还要注意cfs和oss和这个不一样, 他们属于网络交互共享的一种文件系统或者对象存储系统。 一般分布式文件系统用来存储视频, 还有一些数量很多的小文件, 普通的单机文件系统磁盘查找这些文件很慢, 而分布式的话会将小文件放到一个磁盘块。分布式存储类似于分布式数据库, 相比较文件系统有提取分析数据的能力。 此外你还要注意cfs和oss和这个不一样, 他们属于网络交互共享的一种文件系统或者对象存储系统。 | |
| 基于键值对的nosql | 这个就是根据key来读写的。 leveldb底层是一个lsm树, 适合将数据存储到磁盘, 并且热数据更新到内存中。rockdb改进了他对固态硬件的操作,提升了性能。 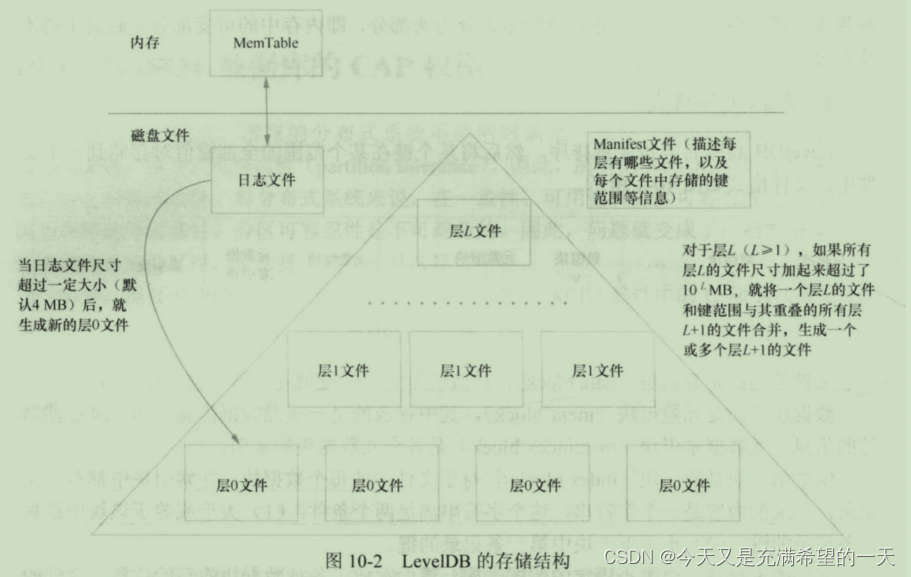 阿里巴巴的tair就是基于此做成了分布式的,搞了如下的分布式nosql数据库。 阿里巴巴的tair就是基于此做成了分布式的,搞了如下的分布式nosql数据库。 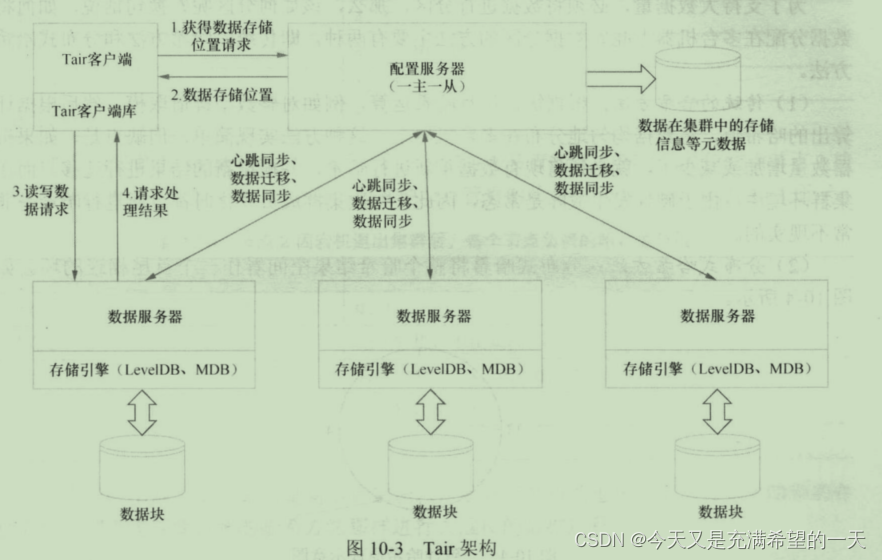 此外,还有一些内存式的nosql kv类型数据库例如redis。 你可以用 redis做session信息, leveldb搭建分布式存储系统(我理解就是分布式kv系统),或者使用leveldb做本地的存储, 反正数据是落地到磁盘的。 此外,还有一些内存式的nosql kv类型数据库例如redis。 你可以用 redis做session信息, leveldb搭建分布式存储系统(我理解就是分布式kv系统),或者使用leveldb做本地的存储, 反正数据是落地到磁盘的。 | |
| 列式存储的数据库 | 列存储最大的好处就是列存储可以对同类型数据进行存储压缩。 还有行键可以是任意的字符串由于按照字典序排序的, 可以对表进行水平切分。 本质他就是一个稀疏的哈希表,key是行列时间戳组成的三元组, value是内部的值。 列存储可以解决关系型数据库表达一种复杂关系时候要建立很多表的问题。例如一个商品, 要各种外键关联各种表中的某个字段。 bigtable基本结构如下, 以分布式文件系统作为基础, 在上面再做一层分布式, 主服务器存储元数据, tablet存储具体的数据。 hbase就是他的开源版本, 中间各个节点的同步用zookeeper来做。 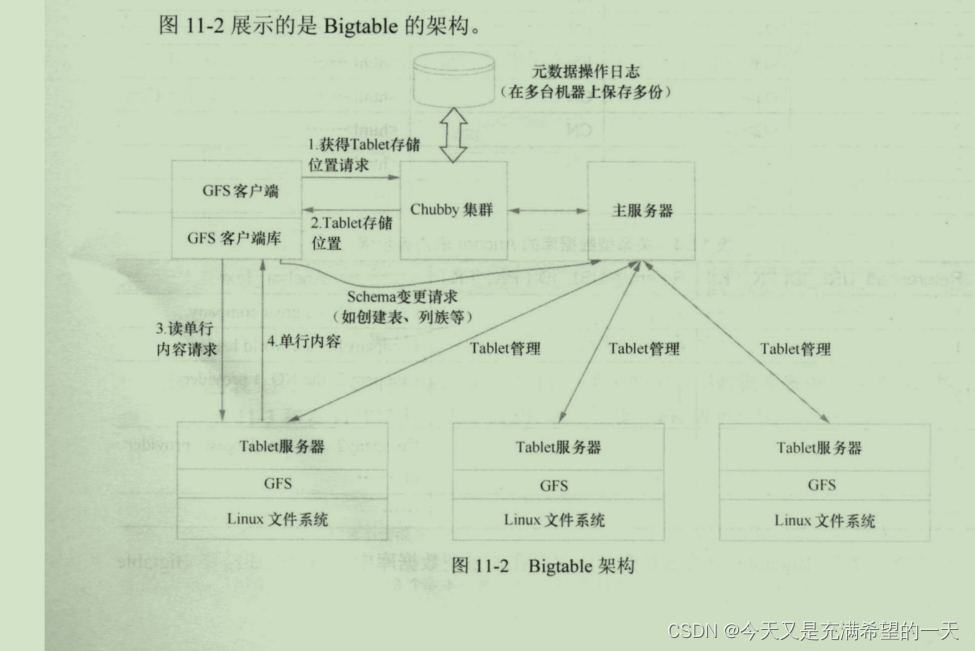 应用: 一般收录各种数据源的数据统一合并到hbase中, 然后通过sqoop等数据管道或者hive等工具, 将数据抽取到线上存储层或者缓存层, 或者进行分析。HBase写快读慢,HBase的读取时长通常是几毫秒,而Redis等读取时长通常是几十微秒。性能相差非常大。 table底层也是用了lsm树做的存储落地, 每次存储了一片的数据。 应用: 一般收录各种数据源的数据统一合并到hbase中, 然后通过sqoop等数据管道或者hive等工具, 将数据抽取到线上存储层或者缓存层, 或者进行分析。HBase写快读慢,HBase的读取时长通常是几毫秒,而Redis等读取时长通常是几十微秒。性能相差非常大。 table底层也是用了lsm树做的存储落地, 每次存储了一片的数据。 | |
| 文档数据库, 图数据库 | - mongodb 是文档类型, 这种适合存储更为完整的一套业务数据, 例如一个订单数据, 里面包含了各种商品, 送货地址等。 - 此外还有图数据库用来处理那种关系网数据, 时间序列数据库存储股票等数据, 都是nosql的。 - 此外还有newsql, 结合mysql等关系型和nosql的特性, 解决mysql的扩展问题, 还有nosql的一致性不好的问题。 | |
| newsql的使用 | 有谁可以详细解释一下NewSQL吗? - Jack的回答 - 知乎 | |
| https://www.zhihu.com/question/52919568/answer/2382985993 | 这个好像就是tidb, oceanbase等, 因为kv分布式数据库优点是可以分布式扩展, 缺点难以支持多行的事务。 因此在分布式kv之上, 加了一些sql语句的操作, 让你看起来像在使用sql操作一个大型mysql。 | |
| 数据系统的基石之数据模型和查询语言 | Blog: | 作者说了最开始数据是层级别的, 适合一对多。 但是有些数据是一对一的, 所以用kv或者nosql更好, 有些是多对多的关系复杂的用图数据库。 |
| 大数据下的数据分析处理工具都有哪些 | 为了对分布式存储系统的数据分析或者数据操作, 一般就是使用hdoop全家桶对其操作, 得到结果, 不能使用简单的mysql等操作了, 一个简单sql查询都要搞成mapreduce去各个节点查询结果。 |
分布式系统的构建思想
-
云虚拟机让一个硬件能够运行多种操作系统。 docker让一个操作系统之上可以运行各种进程, 这些进程之间操作系统是一个, 但是进程等非内核信息不共享, 然后通过编排等工具让资源最大化部署。
-
目前各种分布式系统, gfs、hbase、rpc集群等都是可以解决很大并发量的数据访问和处理。 他们在设计过程中有很多优秀的思想。
-
- 一切都可能失败与冗余的思想, 例如一个hdfs文件存储了3份副本, 就是为了防止失败而产生的冗余。 而为了解决冗余数据的一直性, 有了zookper这种paxos协议的实现。任何组件都是要有冗余的, 用来解决出现问题时候快速切换。 切换的方式,也是zookpeer 集群或者主从等冗余。 主要有问题就加冗余, 用一致性管理冗余在出问题的时候安全顶上。 如何避单点出问题呢? 1 文件系统出错的话就用有备份的hdfs 2 数据库出错用主从, 还有最好是异地的。 3, 后台服务出问题的话就用zookper放多个服务节点, 出问题会自动从zookeeper中下线。
-
- 水品扩展而不是垂直扩展, 能通过加数量的方式就先不通过质量。 就是提升硬件质量不如加数量。 对于数据的水平扩展就是按照字段范围或者哈希分片。 服务的水平扩展是使用zookeeper的方式加服务节点。
-
- 最简单原则, 复杂意味着容易犯错。 最小表达力度的设计。 实用主义, 用到什么学什么。
-
- 根据自己的数据样式选择合适存储。 依赖第三方任务影响自身任务线性执行的话异步化。 最终一致性来保证cap就行, 实在出问题也没办法, 互联网对ca更看重。
-
- 业务微服务化, 每个服务工作单一。
-
- 池化思想和服务追踪思想。
- 设计时候可以考虑用内部服务上报代替服务监控 |
- epoll + 任务队列 + 服务注册治理 = rpc
- 插件方式加载动态的非主线业务。
- docker下要采用静态链接,减少部署难度。
- 定制linux, mysql, java虚拟机提升性能。
workflow
reference()
- 分布式系统设计
- 分布式架构原理与实践
- 凤凰架构: 构建可靠的大型分布式系统


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









