









Hadoop案例之倒排索引
"倒排索引"是文档检索系统中最常用的数据结构,被广泛地应用于全文搜索引擎。它主要是用来存储某个单词(或词组)在一个文档或一组文档中的存储位置的映射,即提供了一种根据内容来查找文档的方式。由于不是根据文档来确定文档所包含的内容,而是进行相反的操作,因而称为倒排索引(Inverted Index)。
1 实例描述
通常情况下,倒排索引由一个单词(或词组)以及相关的文档列表组成,文档列表中的文档或者是标识文档的ID号,或者是指文档所在位置的URL,如图1所示。
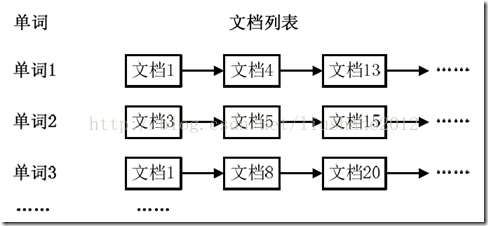
图1倒排索引结构
从图1可以看出,单词1出现在{文档1,文档4,文档13,……}中,单词2出现在{文档3,文档5,文档15,……}中,而单词3出现在{文档1,文档8,文档20,……}中。在实际应用中,还需要给每个文档添加一个权值,用来指出每个文档与搜索内容的相关度,如图2所示。
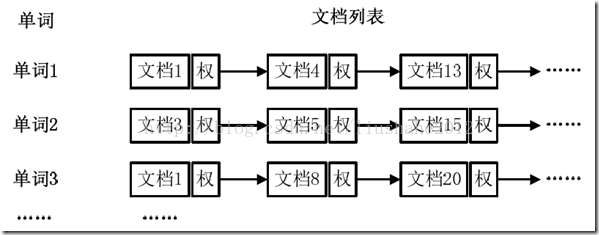
图2 添加权重的倒排索引
最常用的是使用词频作为权重,即记录单词在文档中出现的次数。以英文为例,如图6.1-3所示,索引文件中的"MapReduce"一行表示:"MapReduce"这个单词在文本T0中出现过1次,T1中出现过1次,T2中出现过2次。当搜索条件为"MapReduce"、"is"、"Simple"时,对应的集合为:{T0,T1,T2}∩{T0,T1}∩{T0,T1}={T0,T1},即文档T0和T1包含了所要索引的单词,而且只有T0是连续的。
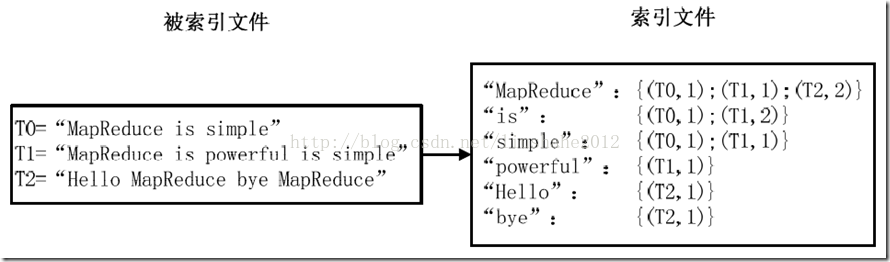
图3 倒排索引示例
更复杂的权重还可能要记录单词在多少个文档中出现过,以实现TF-IDF(Term Frequency-Inverse DocumentFrequency)算法,或者考虑单词在文档中的位置信息(单词是否出现在标题中,反映了单词在文档中的重要性)等。
样例输入如下所示。
1)file1:
MapReduce is simple
2)file2:
MapReduce is powerful issimple
3)file3:
Hello MapReduce byeMapReduce
样例输出如下所示。
MapReduce file1.txt:1;file2.txt:1;file3.txt:2;
is file1.txt:1;file2.txt:2;
simple file1.txt:1;file2.txt:1;
powerful file2.txt:1;
Hello file3.txt:1;
bye file3.txt:1;
2 设计思路
实现"倒排索引"只要关注的信息为:单词、文档URL及词频,如图3-11所示。但是在实现过程中,索引文件的格式与图6.1-3会略有所不同,以避免重写OutPutFormat类。下面根据MapReduce的处理过程给出倒排索引的设计思路。
1)Map过程
首先使用默认的TextInputFormat类对输入文件进行处理,得到文本中每行的偏移量及其内容。显然,Map过程首先必须分析输入的<key,value>对,得到倒排索引中需要的三个信息:单词、文档URL和词频,如图4所示。
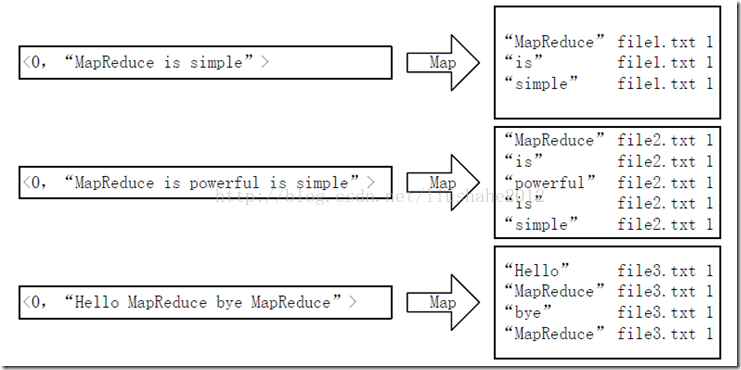
图4 Map过程输入/输出
这里存在两个问题:第一,<key,value>对只能有两个值,在不使用Hadoop自定义数据类型的情况下,需要根据情况将其中两个值合并成一个值,作为key或value值;第二,通过一个Reduce过程无法同时完成词频统计和生成文档列表,所以必须增加一个Combine过程完成词频统计。
这里讲单词和URL组成key值(如"MapReduce:file1.txt"),将词频作为value,这样做的好处是可以利用MapReduce框架自带的Map端排序,将同一文档的相同单词的词频组成列表,传递给Combine过程,实现类似于WordCount的功能。
2)Combine过程
经过map方法处理后,Combine过程将key值相同的value值累加,得到一个单词在文档在文档中的词频,如图5所示。如果直接将图5所示的输出作为Reduce过程的输入,在Shuffle过程时将面临一个问题:所有具有相同单词的记录(由单词、URL和词频组成)应该交由同一个Reducer处理,但当前的key值无法保证这一点,所以必须修改key值和value值。这次将单词作为key值,URL和词频组成value值(如"file1.txt:1")。这样做的好处是可以利用MapReduce框架默认的HashPartitioner类完成Shuffle过程,将相同单词的所有记录发送给同一个Reducer进行处理。
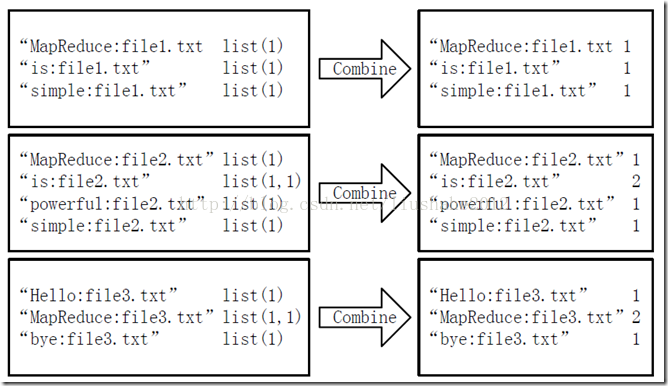
图5 Combine过程输入/输出
3)Reduce过程
经过上述两个过程后,Reduce过程只需将相同key值的value值组合成倒排索引文件所需的格式即可,剩下的事情就可以直接交给MapReduce框架进行处理了。如图6所示。索引文件的内容除分隔符外与图3解释相同。
4)需要解决的问题
本实例设计的倒排索引在文件数目上没有限制,但是单词文件不宜过大(具体值与默认HDFS块大小及相关配置有关),要保证每个文件对应一个split。否则,由于Reduce过程没有进一步统计词频,最终结果可能会出现词频未统计完全的单词。可以通过重写InputFormat类将每个文件为一个split,避免上述情况。或者执行两次MapReduce,第一次MapReduce用于统计词频,第二次MapReduce用于生成倒排索引。除此之外,还可以利用复合键值对等实现包含更多信息的倒排索引。
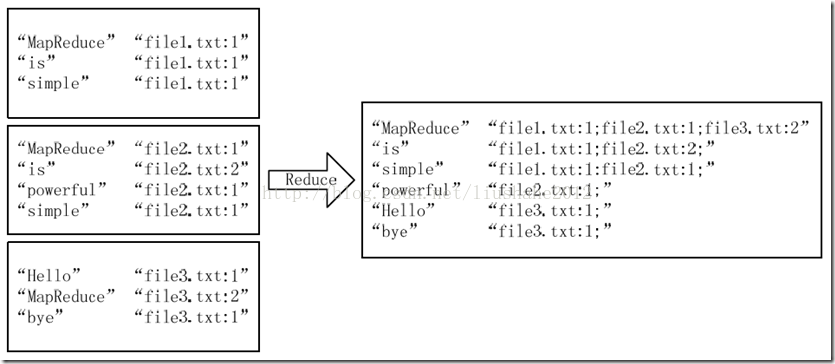
图6 Reduce过程输入/输出
3.程序代码
package Hadoop_InvertedIndex;
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.FileSplit;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
public class InvertedIndex {
public static class Map extends Mapper<Object, Text, Text, Text>
{
private Text keyInfo = new Text();
private Text valueInfo = new Text();
private FileSplit split;
@Override
protected void map(Object key, Text value, Context context)
throws IOException, InterruptedException {
//简单起见,只获取文件名
split = (FileSplit)context.getInputSplit();
int index = split.getPath().toString().indexOf("file");
String fileName = split.getPath().toString().substring(index);
StringTokenizer st = new StringTokenizer(value.toString());
while(st.hasMoreTokens())
{
//单词:文件名 作为key
//1 为 value
keyInfo.set(st.nextToken()+":"+fileName);
valueInfo.set("1");
context.write(keyInfo, valueInfo);
}
}
}
//combine
public static class Combine extends Reducer<Text, Text, Text, Text>
{
@Override
protected void reduce(Text key, Iterable<Text> values, Context context)
throws IOException, InterruptedException {
// 统计词频
int sum = 0;
for(Text temp : values)
{
sum+= Integer.parseInt(temp.toString());
}
int index = key.toString().indexOf(":");
// 重新设置key值为单词
String sKey = key.toString().substring(0, index);
Text outKey = new Text(sKey);
// 重新设置value值由URL和词频组成
String sValue = key.toString().substring(index+1);
Text outValue = new Text(sValue+":"+sum);
context.write(outKey, outValue);
}
}
//reduce
public static class Reduce extends Reducer<Text, Text, Text, Text>
{
@Override
protected void reduce(Text key, Iterable<Text> values,Context context)
throws IOException, InterruptedException {
String fileList = new String();
for(Text temp : values)
{
fileList += temp.toString() + ";";
}
context.write(key, new Text(fileList));
}
}
//main
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
String[] otherArgs = new GenericOptionsParser(conf,args).getRemainingArgs();
if (otherArgs.length != 2) {
System.err.println("Usage:InvertedIndex <in> <out>");
System.exit(2);
}
Job job = new Job(conf, "InvertedIndex");
job.setJarByClass(InvertedIndex.class);
job.setMapperClass(Map.class);
job.setCombinerClass(Combine.class);
job.setReducerClass(Reduce.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
FileInputFormat.addInputPath(job, new Path(otherArgs[0]));
FileOutputFormat.setOutputPath(job, new Path(otherArgs[1]));
System.exit(job.waitForCompletion(true)? 0 : 1);
}
}
4.程序执行
root@node1:/usr/local/hadoop/hadoop-2.5.2/myJar#hadoop jar InvertedIndex.jarHadoop_InvertedIndex.InvertedIndex /usr/local/hadooptempdata/input/inverted/usr/local/hadooptempdata/output/inverted
16/12/29 23:29:04 INFO client.RMProxy:Connecting to ResourceManager at node1/192.168.233.129:8032
16/12/29 23:29:07 INFOinput.FileInputFormat: Total input paths to process : 3
16/12/29 23:29:07 INFOmapreduce.JobSubmitter: number of splits:3
16/12/29 23:29:08 INFOmapreduce.JobSubmitter: Submitting tokens for job: job_1483024810031_0001
16/12/29 23:29:09 INFO impl.YarnClientImpl:Submitted application application_1483024810031_0001
16/12/29 23:29:10 INFO mapreduce.Job: Theurl to track the job: http://node1:8088/proxy/application_1483024810031_0001/
16/12/29 23:29:10 INFO mapreduce.Job:Running job: job_1483024810031_0001
16/12/29 23:29:55 INFO mapreduce.Job: Jobjob_1483024810031_0001 running in uber mode : false
16/12/29 23:29:55 INFO mapreduce.Job: map 0% reduce 0%
16/12/29 23:34:16 INFO mapreduce.Job: map 22% reduce 0%
16/12/29 23:34:25 INFO mapreduce.Job: map 44% reduce 0%
16/12/29 23:34:31 INFO mapreduce.Job: map 56% reduce 0%
16/12/29 23:34:32 INFO mapreduce.Job: map 78% reduce 0%
16/12/29 23:34:35 INFO mapreduce.Job: map 89% reduce 0%
16/12/29 23:34:46 INFO mapreduce.Job: map 100% reduce 0%
16/12/29 23:35:44 INFO mapreduce.Job: map 100% reduce 100%
16/12/29 23:35:49 INFO mapreduce.Job: Jobjob_1483024810031_0001 completed successfully
16/12/29 23:35:50 INFO mapreduce.Job:Counters: 49
FileSystem Counters
FILE:Number of bytes read=215
FILE:Number of bytes written=396231
FILE:Number of read operations=0
FILE:Number of large read operations=0
FILE:Number of write operations=0
HDFS:Number of bytes read=478
HDFS:Number of bytes written=165
HDFS:Number of read operations=12
HDFS:Number of large read operations=0
HDFS:Number of write operations=2
JobCounters
Launchedmap tasks=3
Launchedreduce tasks=1
Data-localmap tasks=3
Totaltime spent by all maps in occupied slots (ms)=902667
Totaltime spent by all reduces in occupied slots (ms)=33136
Totaltime spent by all map tasks (ms)=902667
Totaltime spent by all reduce tasks (ms)=33136
Totalvcore-seconds taken by all map tasks=902667
Totalvcore-seconds taken by all reduce tasks=33136
Totalmegabyte-seconds taken by all map tasks=924331008
Totalmegabyte-seconds taken by all reduce tasks=33931264
Map-ReduceFramework
Mapinput records=4
Mapoutput records=12
Mapoutput bytes=226
Mapoutput materialized bytes=227
Inputsplit bytes=393
Combineinput records=12
Combineoutput records=10
Reduceinput groups=6
Reduceshuffle bytes=227
Reduceinput records=10
Reduceoutput records=6
SpilledRecords=20
ShuffledMaps =3
FailedShuffles=0
MergedMap outputs=3
GCtime elapsed (ms)=82879
CPUtime spent (ms)=14870
Physicalmemory (bytes) snapshot=474574848
Virtualmemory (bytes) snapshot=7537999872
Totalcommitted heap usage (bytes)=382656512
ShuffleErrors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
FileInput Format Counters
BytesRead=85
FileOutput Format Counters
BytesWritten=165
5.输出结果
root@node1:/usr/local/hadoop/hadoop-2.5.2/myJar#hdfs dfs -cat/usr/local/hadooptempdata/output/inverted/*
Hello file3.txt:1;
MapReduce file3.txt:2;file1.txt:1;file2.txt:1;
bye file3.txt:1;
is file1.txt:1;file2.txt:2;
powerful file2.txt:1;
simple file2.txt:1;file1.txt:1;















 846
846

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









