







文章目录
1. es框架
Elasticsearch 是一个兼有搜索引擎和NoSQL数据库功能的开源系统,基于Java/Lucene构建,可以用于全文搜索,结构化搜索以及近实时分析。
2. es相关术语
2.1 相关概念
es和数据库作用类似,所以我们这里对es相关术语的学习和关系型数据库进行对比便于读者理解学习
| es概念 | 数据库概念 |
|---|---|
| index 索引 | 数据库表 |
| type 类型(es 7版本弃用) | 表逻辑类型 |
| Document 文档 | 表的一行记录 |
| filed 字段 | 记录对应的字段(字段名、类型、长度等) |
| mapping 映射 | 表结构定义 |
| NRT 近实时 | 一秒或者一秒内延迟(Near real time 近乎实时) |
| Node 节点 | 集群部署情况下的每一个服务节点 |
| shard replica | 数据分片和备份 |
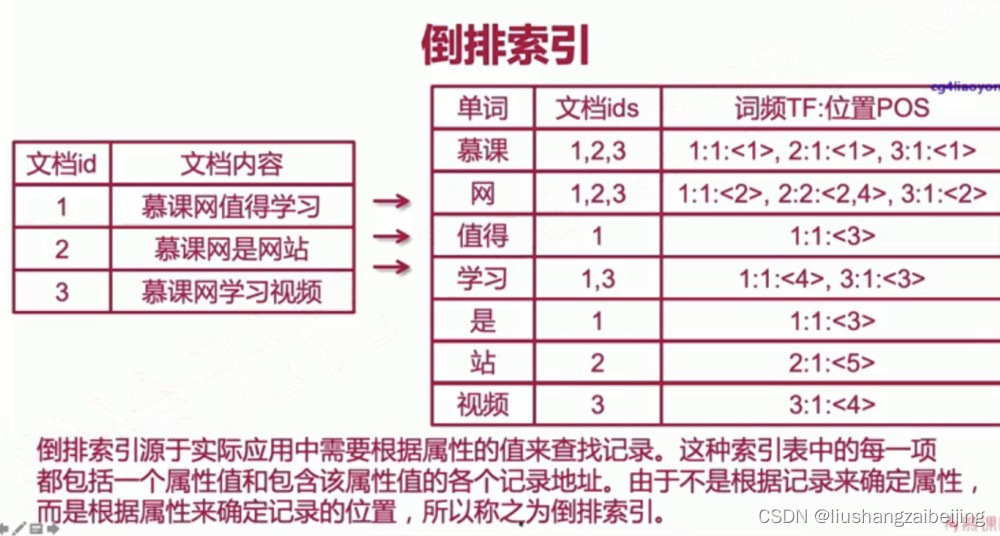
2.2 倒排索引
es最核心的两个概念为索引和搜索,这里的建立的索引即为倒排索引,在说到倒排索引之前 我们需要先了解一下何为正排索引
正排索引:所谓正排是针对记录都有一个唯一标识,我们通过唯一标识来搜索对应的记录信息,比如数据库主键查询 key=>value,但是对于文档类型关键字查询可以需要扫描全部文档记录找到匹配的记录类似于数据库的like模糊查询性能低下。
倒排索引:与正排索引不同会将文档通过分词形成一个个词组,建立词组和文档唯一标识的记录,value(分词后)=》key 同时这样处理还可以记录词组在文档出现的频次和词组位置,便于我们更好更快的搜索。
3. es安装部署
#下载es
wget
https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-7.4.1-linux-x86_64.tar.gz
#解压项目
tar -zxvf elasticsearch-7.4.1.tar.gz -C /usr/local
#修改配置elasticsearch.yml,jvm.options
scp username@servername:/path/远程目录 /path/本地目录
#因为es服务不能直接使用root用户启动
#所以这里需要新建用户es 并为该用户赋予es使用权限
adduser es
chown -R es /usr/local/
#启动es 切换到es用户
su es
./bin/elasticsearch &
9200发布端口 9300集群节点之间的内部通讯
#
# ---------------------------------- Cluster -----------------------------------
#
# Use a descriptive name for your cluster:
# 设置集群名称 不设置默认分配
cluster.name: xiu-es
#
# ------------------------------------ Node ------------------------------------
#
# Use a descriptive name for the node:
# 设置单服务节点信息
node.name: xiu-node-1
#
# ----------------------------------- Paths ------------------------------------
#
#设置es数据存储路径
path.data: /usr/local/elasticsearch/elasticsearch-7.4.1/data
#
# Path to log files:
#设置es日志存储路径
path.logs: /usr/local/elasticsearch/elasticsearch-7.4.1/logs
#
# ---------------------------------- Network -----------------------------------
#
# Set the bind address to a specific IP (IPv4 or IPv6):
# 设置可以远程访问的地址 0.0.0.0表示所有主机都可远程访问
network.host: 0.0.0.0
#
# Set a custom port for HTTP:
#设置http远程访问端口 9300是集群内部通讯端口
http.port: 9200
#
# --------------------------------- Discovery ---------------
# 设置集群节点地址
#discovery.seed_hosts: ["127.0.0.01"]
#
# Bootstrap the cluster using an initial set of master-eligible nodes:
#设置集群节点
cluster.initial_master_nodes: ["xiu-node-1“]
4. header 插件安装
elasticsearch-header是es的可视化访问页面,由于head插件本质上还是一个nodejs的工程,因此需要安装node,使用npm来安装依赖的包。node环境安装参考
# 下载head项目
git clone https://github.com/mobz/elasticsearch-head.git
# 安装
cnpm install
# 运行
npm run start
5. es相关api使用
5.1 集群api
# 查看集群状态
http://xxx.xx.x.xxx:9200/_cluster/health
#查看所有节点信息
http://xxx.xx.x.xxx:9200/_nodes
#查看节点的状态信息 (ip 端口)
http://xxx.xx.x.xxx:9200/_nodes/stats
5.2 索引相关
5.2.1 创建索引
PUT请求: http://xxx.xx.x.xxx:9200/{index_name}
PUT: http://xxx.xx.x.xxx:9200/singer
请求参数
{
"settings": {
"index": {
//分片数(每个分片只存储一部分数据 所有分片共同)
"number_of_shards": "5",
//副本数 每一个主分片都设置
"number_of_replicas": "0"
}
}
}
响应参数
{
"acknowledged": true,
"shards_acknowledged": true,
//索引名
"index": "singer"
}
5.2.2 查看索引库
GET请求: http://xxx.xx.x.xxx:9200/{index_name}
GET: http://xxx.xx.x.xxx:9200/singer
响应信息
{
//索引名(相当于数据库 表 库名)
"my-index-test": {
//索引别名
"aliases": {
},
//映射关系(数据表 字段类型) 此时还没有映射关系
//我们在后面创建
"mappings": {
},
//索引设置信息 分片和副本、版本等信息
"settings": {
"index": {
"creation_date": "1641371223528",
"number_of_shards": "5",
"number_of_replicas": "0",
"uuid": "NaMpmAlzQJO3r0Bmr_QJmQ",
"version": {
"created": "6000199"
},
"provided_name": "singer"
}
}
}
}
5.2.3 创建映射关系
索引有了,接下来肯定是添加数据但在添加数据之前必须定义映射。
**映射**是定义文档的过程,文档包含哪些字段,这些字段是否保存,是否索引,是否分词,字段类型等
| 字段 | 描述 |
|---|---|
| 类型名称 | 数据库中的不同表的字段名:任意填写 ,可以指定许多属性 |
| type | 类型 es支持如text、long、short、date、integer、object等多种 字符串 text:可分词,不可参与聚合 keywordÿ |
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 300
300











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









