









你是不是经常看到索引失效或者不走索引的话语。你是不是觉得mysql这个东西怎么动不动就不走我的索引了。
甚至我看到一句话:mysql的优化器一思考,上帝都发愁。
种种迹象都说明,mysql的索引是真TMD不好控制。有时候都让人怀疑,mysql底层到底有没有索引控制这一说。
是不是完全放飞了自我,凭心情给你走索引啊。
但是用屁股想想也不可能,mysql是个开源的数据库,它敢这么做,不是找死吗。所以事情的真相,我们在看了《mysql是怎样运行的》这本书之后,得到了一个答案。
mysql先生给出的回复是:索引,谁控制不住,我把她控制的死死的。
一、知识前置
MYSQL中的成本是由两部分组成的,一个是IO成本,一个是CPU成本。
IO成本:innodb中的数据都是放在磁盘里面的,需要我们读取或者处理的时候才会从磁盘加载到内存中。而且这个加载是以mysql中的一个页为单位的。大小innodb默认是16KB。这个从磁盘加载的内存中的过程中的时间消耗就是IO成本。
CPU成本:数据加载到内存后需要读取以及检测数据记录是不是满足你sql中的对应条件,以及要是涉及到排序的时候需要进行排序这些操作的消耗就是cpu成本。
innodb中对于成本是如下规定,读取一个数据页的成本打分是1.0分,一个cpu成本是0.2分。
并且,在读取记录的时候,即使不需要检测记录是不是符合条件这个步骤,成本打分也是0.2。
OK,至此算是一个前置知识。
二、数据准备
创建一个数据表:
CREATE TABLE `single_table` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`key1` varchar(100) DEFAULT NULL,
`key2` int(11) DEFAULT NULL,
`key3` varchar(100) DEFAULT NULL,
`key_part1` varchar(100) DEFAULT NULL,
`key_part2` varchar(100) DEFAULT NULL,
`key_part3` varchar(100) DEFAULT NULL,
`common_field` varchar(100) DEFAULT NULL,
PRIMARY KEY (`id`),
UNIQUE KEY `uk_key2` (`key2`) USING BTREE,
KEY `idx_key1` (`key1`) USING BTREE,
KEY `idx_key3` (`key3`) USING BTREE,
KEY `idx_key_part` (`key_part1`,`key_part2`,`key_part3`) USING BTREE
) ENGINE=InnoDB AUTO_INCREMENT=10001 DEFAULT CHARSET=utf8;
这个表,有主键id,唯一索引key2,以及三个普通的二级索引。表里面我用mybais插了一万数据,id是自增的,其余都是随机数。
select * from single_table where key2 > 900 and key2 < 9000;
我们先以这个简单的sql来分析一下。到底他是怎么计算的,啥时候走索引,啥时候不走呢。
三、成本计算
上面那个sql涉及到一个检索条件,就是在key2这个唯一索引上。
1、全表的代价
innodb中,全表扫描就是把聚簇索引中的记录都一次和给定的搜索条件做对比。然后把结果返回。所以全表扫描需要把聚簇索引所有的数据页都加载的内存中。而计算成本=IO成本+CPU成本。所以计算全表的代价需要先计算两个因子。
1、聚簇索引的页面数。
2、表中的记录数(读取比较需要做cpu成本的计算)。
这个两个信息可以从一个语句中获取。
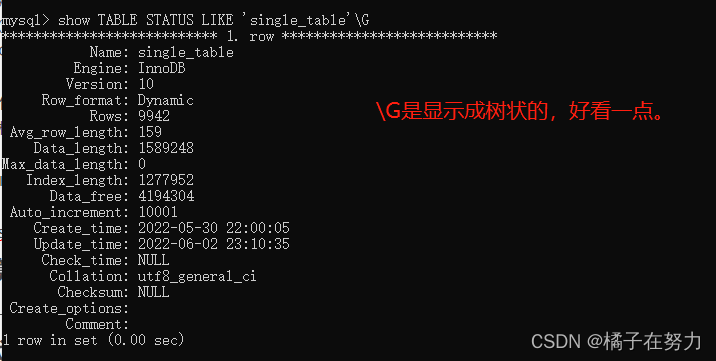
这个查询结果里面有两个重要信息,
Rows:就是Innodb引擎给你计算统计的表里面的数据总数,不准确,我插了一万行的。myisam是准确的,Innodb是估计值。这里就估计了9942行。
Data_length:表示的是占用空间的字节数,对于innodb就是聚簇索引占了多大空间在磁盘上。
Data_length=聚簇索引页面数 * 页面大小
已知页面大小是16KB,所以我们可以计算出总共的页面数是:1589248 / 1024 / 16 = 97
所以总共的聚簇索引占的页面总共是97个数据页。
所以到了这一步,我们结合前置知识就能算出全表扫描的时候,需要的成本了。
IO成本:97 * 1.0 + 1.1 = 98.1就是97个页,每个页1分,后面那个1.1不影响大局,不知道是个啥。
CPU成本:9942 * 0.2 + 1.0 = 1989.4 就是9942行,每一行在内存里面做读取然后比对条件,每一个是0.2分,后面那个1.0无所谓了。
所以到这里我们计算出总成本就是 98.1 + 1989.4 = 2087.5
可能你会问了,数据都在叶子节点上,你算页面把树上的内节点的页面也算了,这不是不精确了吗,是的本来ROWS就不精确,这里也是挺放飞自我的。
2、走索引的代价
我们上面说了,存在一个唯一索引key2,所以mysql还会计算一下这个索引的成本,然后去和全表做对比,这个对比结果成本低的就是最后mysql的选择了。
key2的条件是key2 > 900 and key2 < 9000,形成的扫描区间是(900,9000)。
二级索引的查询方式是,索引树上查到,再去聚簇索引树回表查询完整的(我们查的就是*)。
所以mysql需要两部分操作,一个是key2树上的扫描行数,以及需要回表的行数。
1、扫描区间的数量
这里和全表那里不一样,这里有扫描区间,mysql底层认为,一个区间就是一个数据页的成本,我们这里就一个扫描区间(900,9000),所以这里的打分就是1.0。
2、回表的记录数
这里的计算规则涉及数据页的个数之类的。都是底层在算,我们是数据库使用者一下就知道了,我这个表里面是用的自增数,所以900-9000这个区间一共数据就是8100条数据。这8100条数据的cpu成本就是8100 * 0.2 + 0.01 = 1620.01
3、回表操作
我们有了回表的记录数,接下来就是要回表了。
Mysql约定,回表的时候,回表一条数据相当于访问一次页面,也就是io打分为1.
我们这里8100条数据,8100 * 1.0 = 8100分。
回表之后在局促索引上读取数据,然后做条件对比,条件就是900-9000,所以这个对比就是对应的cpu成本0.2分,总共是8100 * 0.2 = 1620分
所以最后的成本加起来就是:
IO成本:1.0 + 8100 = 8101分
CPU成本:1620.01 + 1620 = 3240.1
所以这个索引的打分就是11341.1
所以我们看到了全表是2087.5 key2索引是11341.1,所以恕我直言,这个查询必走全表查询。
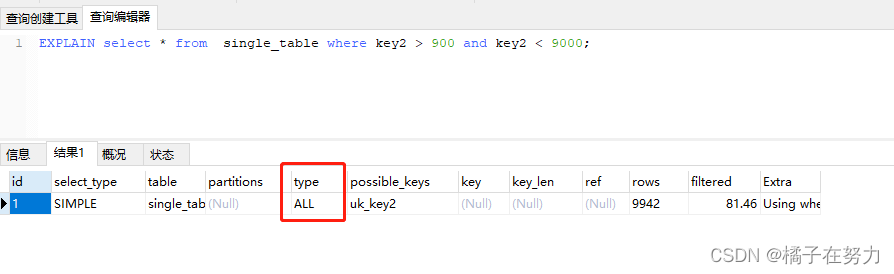
可见是对的。
那都已经到了这一步了,我们来做个测试吧。
3、手动调整一下
我们知道了计算规则,其实列个不等式就能知道走key2索引的边界条件在哪里?
做个二年级数学题吧。
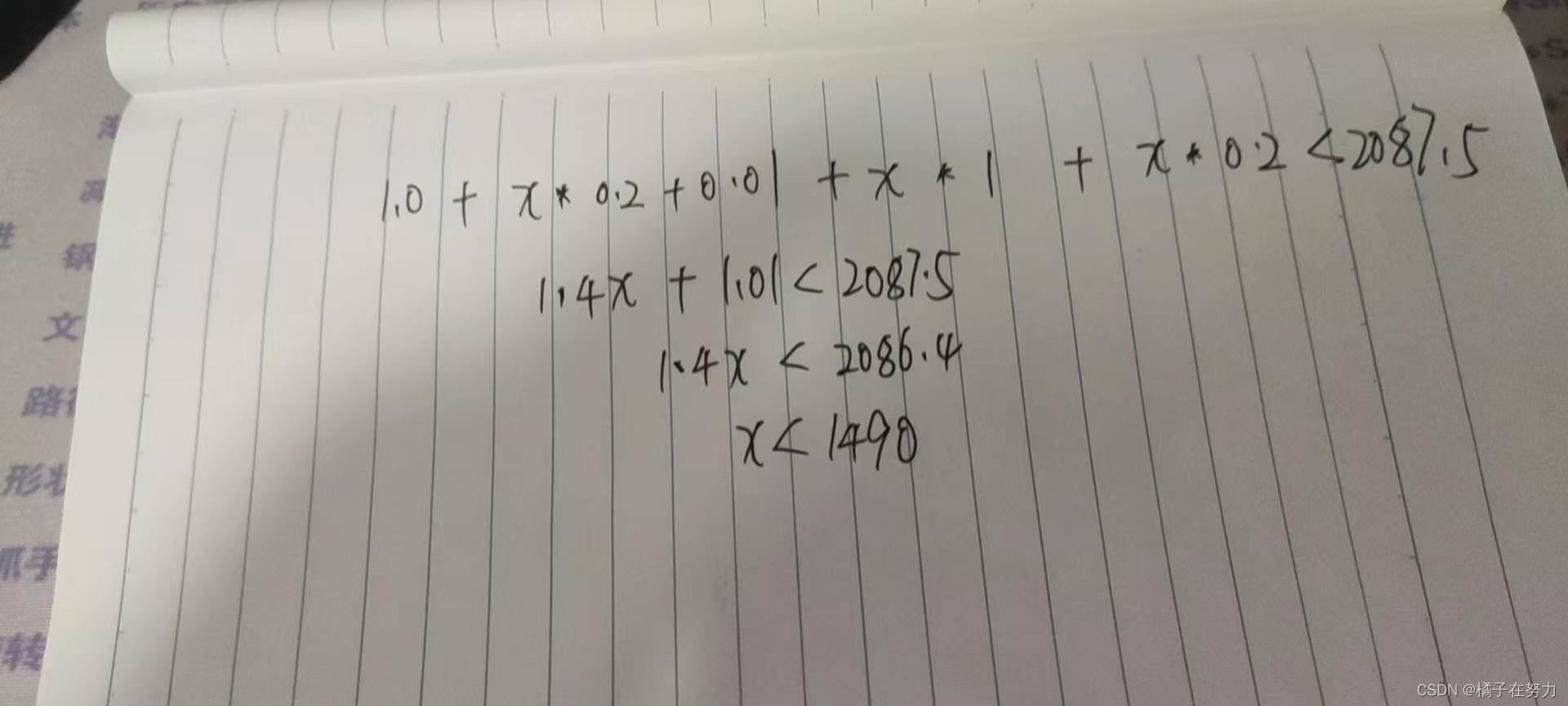
我们算出来当扫描行数超过1490行的时候,二级索引的成本低于全表,我们做个测试。
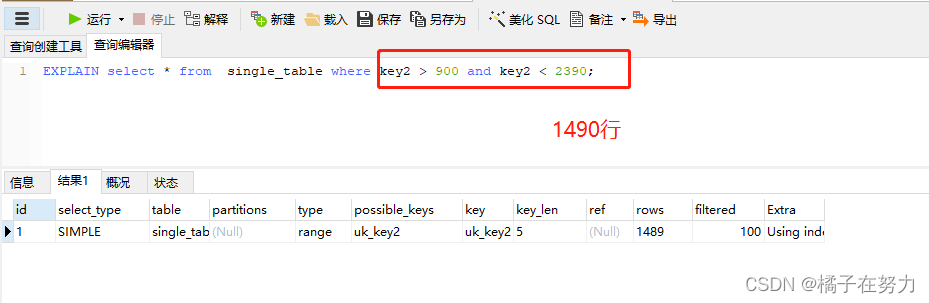
可见1490确实会走二级索引,但是实际上我测试到1690的时候才是个分界线,但是200行数据对于mysql真是洒洒水,本来就是估算。
四、规避误差
我们上面看到了她的计算方式,其实是有误差的,也就是这个误差,可能有时候你写的sql你想让他走索引,结果他没走,最后你就麻了。
所以生产上,你要是想规避这种问题,可以使用force index强行指定索引。














 703
703











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









