




一、简介
我们上文简单实现了一下如何加载文本,如何切分文本,如何向量化,并且简单测试了一下检索。
这里我们来实现如何基于我们构建好的向量知识库来进行大模型的chat功能。
二、代码实现
1、第一版:手写prompt
我们其实之前已经玩烂了这部分内容,我们重新回顾一下如何交互。
1、构建prompt template
2、填充模板
3、prompt提交llm对象
其余的无外乎就是一些python语法。
from langchain_ollama import OllamaEmbeddings
from langchain_elasticsearch import ElasticsearchStore
from langchain_ollama import ChatOllama
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser
# 构建llm对象
llm = ChatOllama(
base_url = "http://127.0.0.1:11434",
model = "huihui_ai/deepseek-r1-abliterated:14b",
temperature = 0.5,
num_predict = 10000
)
# question问题
query = "请告诉我潍坊的美食有哪些?"
# 构建向量库检索
embed = OllamaEmbeddings(model="llama3.2:latest")
elastic_vector_search = ElasticsearchStore(
es_url="http://localhost:9200",
index_name="langchain_index",
embedding=embed,
)
# 检索器,执行相似度检索,k=1
retriever = elastic_vector_search.as_retriever(
search_type="similarity",
search_kwargs={"k":1}
)
# 执行相似性检索,把与问题相关的文档全部获取
retrieved_docs = retriever.get_relevant_documents(query)
# 遍历获取的文档,组合成为上下文
context_text = "\n\n".join([doc.page_content for doc in retrieved_docs])
# 上下文+问题=prompt
prompt_template = ChatPromptTemplate.from_template(
"""
你是一个AI助手,你将要使用以下的上下文来回答我的问题。
如果你不知道答案,请向我道歉,并且告诉我你不知道答案。
"context:{context}\n\n"
"question:{question}\n\n"
"AI助手回答如下:"
"""
)
# 构建chain
chain = prompt_template | llm | StrOutputParser()
# 执行问答
response = chain.invoke({"context":context_text,"question":query})
print(response)
此外就是启动ollama和es
我们执行一下代码看到结果为:

整体来说还是没问题的。
2、第二版:prompt hub
我们上面的代码的prompt是我们自己写的。
prompt_template = ChatPromptTemplate.from_template(
"""
你是一个AI助手,你将要使用以下的上下文来回答我的问题。
如果你不知道答案,请向我道歉,并且告诉我你不知道答案。
"context:{context}\n\n"
"question:{question}\n\n"
"AI助手回答如下:"
"""
)
众所周知,prompt的构建对于大模型问答的效果至关重要。我们主观手动去写往往没有那么高的质量。
好在langchain为我们提供了一个prompt仓库,我们可以在仓库里面获得各种类型的prompt。prompt hub
然后来到这里就好。
然后点击左下角的这里。
最终位于hub
我们直接找到我们需要的rag prompt即可。
点击进去看到。
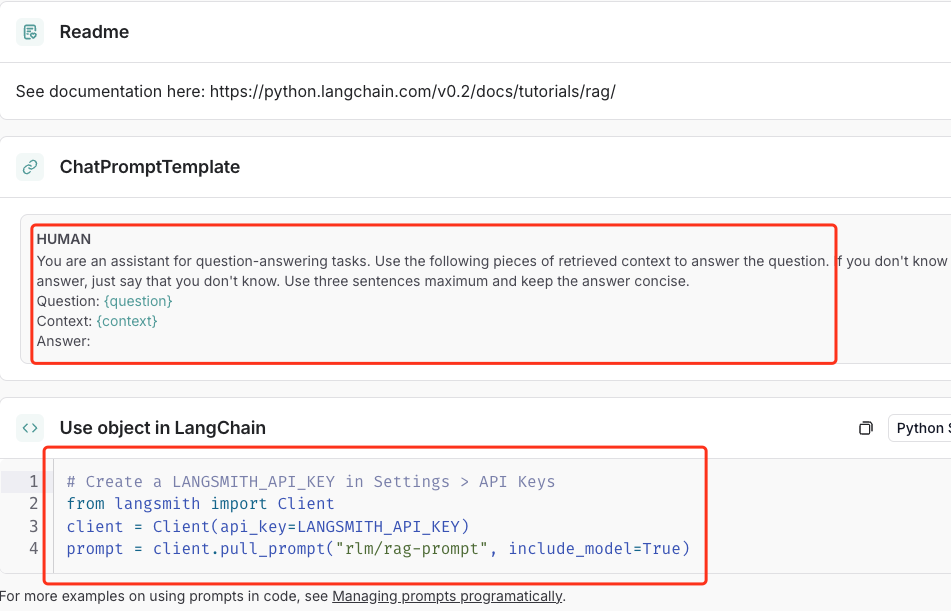
你其实能看到他的结构和我们上面差不多,只不过人家写的更好一点,然后我们直接使用api集成就可以了。
from langchain_ollama import OllamaEmbeddings
from langchain_elasticsearch import ElasticsearchStore
from langchain_ollama import ChatOllama
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser
from langsmith import Client
# 构建llm对象
llm = ChatOllama(
base_url = "http://127.0.0.1:11434",
model = "huihui_ai/deepseek-r1-abliterated:14b",
temperature = 0.5,
num_predict = 10000
)
# question问题
query = "请告诉我潍坊的美食有哪些?"
# 构建向量库检索
embed = OllamaEmbeddings(model="llama3.2:latest")
elastic_vector_search = ElasticsearchStore(
es_url="http://localhost:9200",
index_name="langchain_index",
embedding=embed,
)
# 检索器,执行相似度检索,k=1
retriever = elastic_vector_search.as_retriever(
search_type="similarity",
search_kwargs={"k":1}
)
# 执行相似性检索,把与问题相关的文档全部获取
retrieved_docs = retriever.get_relevant_documents(query)
# 遍历获取的文档,组合成为上下文
context_text = "\n\n".join([doc.page_content for doc in retrieved_docs])
# 使用prompt hub来构建prompt,然后我们没有api-key,所以我们传入空
client = Client()
prompt = client.pull_prompt("rlm/rag-prompt", include_model=True)
# 构建chain
chain = prompt | llm | StrOutputParser()
# 执行问答
response = chain.invoke({"context":context_text,"question":query})
print(response)
执行效果差不多,似乎比我们自己手写的prompt更加简洁一些,并且他不是md格式的返回,我们自己写的格式控制了md返回,没毛病。而且他限制了不超过三句话。

这种方式更加简单,但是不灵活,我们在他无法满足需求的时候还是要自己去写。
3、文档来源RetrievalQA
相信你在使用各类大模型rag产品的时候,见到这类功能。在回答问题之后,他还能把问题的来源文档地址返回给你,让你可以去下载该文档。我们来完成这个功能。该功能的实现主要位于RetrievalQA功能下。
retrievers
RetrievalQA 文档
RetrievalQA API
我们先来看下retrievers的介绍。
我们看到他可以获取到任意元数据。
然后我们按照文档来构建检索
更进一步我们使用这个方法这个方法是把结果可以当成chain来执行的。
from langchain.chains import RetrievalQA
from langchain_ollama import OllamaEmbeddings
from langchain_elasticsearch import ElasticsearchStore
from langchain_ollama import ChatOllama
llm = ChatOllama(
base_url = "http://127.0.0.1:11434",
model = "huihui_ai/deepseek-r1-abliterated:14b",
temperature = 0.5,
num_predict = 10000
)
embed = OllamaEmbeddings(model="llama3.2:latest")
elastic_vector_search = ElasticsearchStore(
es_url="http://localhost:9200",
index_name="langchain_index",
embedding=embed,
)
retriever = elastic_vector_search.as_retriever(
search_type="similarity",
search_kwargs={"k":1}
)
# 构建检索,并且制定return_source_documents为true,因为我们要获取元信息,里面有文档来源
qa_chain = RetrievalQA.from_chain_type(llm,retriever=retriever,return_source_documents=True)
response = qa_chain.invoke("请告诉我潍坊的美食有哪些?")
# 遍历结果集,封装为set集合,去重
sources = set(doc.metadata.get("source","Unknown") for doc in response["source_documents"])
print(response['result'])
print("\n 引用来源:")
for source in sources:
print(f"{source}")
输出结果如下:展示出了文档的地址,一般生产上我们这个文档地址是文件服务器的地址,前端展示可以下载,这里我们就是项目目录下的一个相对地址。

三、RetrievalQA源码解读
我们的代码入口是这里
qa_chain = RetrievalQA.from_chain_type(llm,retriever=retriever,return_source_documents=True)
我们借助ide点进去from_chain_type这个方法。选择重载参数最多的那个。
你会看到这个函数。
@classmethod
def from_chain_type(
cls,
llm: BaseLanguageModel,
app_name: str,
description: str,
owner: str,
chain_type: str = "stuff",
chain_type_kwargs: Optional[dict] = None,
api_key: Optional[str] = None,
classifier_url: Optional[str] = None,
classifier_location: str = "local",
**kwargs: Any,
) -> "PebbloRetrievalQA":
但是你惊讶的发现并没有我们指定的那些参数,py这个真的很难受,不像java,参数是啥就是啥,他用了一个**kwargs: Any来表示可变长度参数列表,来初始化。具体有哪些参数你可以在这个方法的这个类下面找到。
我们可以看到当前类下面的参数就是这些可变类型。可变类型之外的我们都能在这个方法直接看到。
class PebbloRetrievalQA(Chain):
"""
Retrieval Chain with Identity & Semantic Enforcement for question-answering
against a vector database.
"""
# 是否返回源数据,默认不返回
return_source_documents: bool = False
"""Return the source documents or not."""
# 检索器
retriever: VectorStoreRetriever = Field(exclude=True)
......其他的可以看注释即可
于是你就知道该如何使用这个方法了。
于是我们就完成了这个文档来源检索的问答功能。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









