







一、简介
截止目前,我们对大模型的使用模式仅仅是简单的你问他答。即便是拥有rag,也只是让大模型的回答更加丰富。但是大模型目前为止并没有对外操作的能力,他只是局限于他自己的知识库。
举个例子,到今天4.21为止,你去问任何一个本地部署的大模型,美国对中国加的关税是多少,相信他们都不能给出答案,因为这个事件太新了。相信所有的模型还没有这部分知识。
那我们除了训练rag检索,能不能让大模型主动去外部的网站去搜一下呢,比如维基百科,百度百科等等有实时新闻的网站。
这个概念的意思是,让大模型具有对外操作的能力,而问答只是他的一个子集。既然能对外操作,我们可以让他去读取数据库,或者修改文件。这样也是一个能力。基于这个能力,我们涉及到的几个相关概念分别是tools和fucntion call。本文我们先来看tools。
二、langchain的文档阅读
有人之前问我,如何在langchain中找到对应的概念,这里我来说一下流程。首先进入langchain的文档页面找到概览。
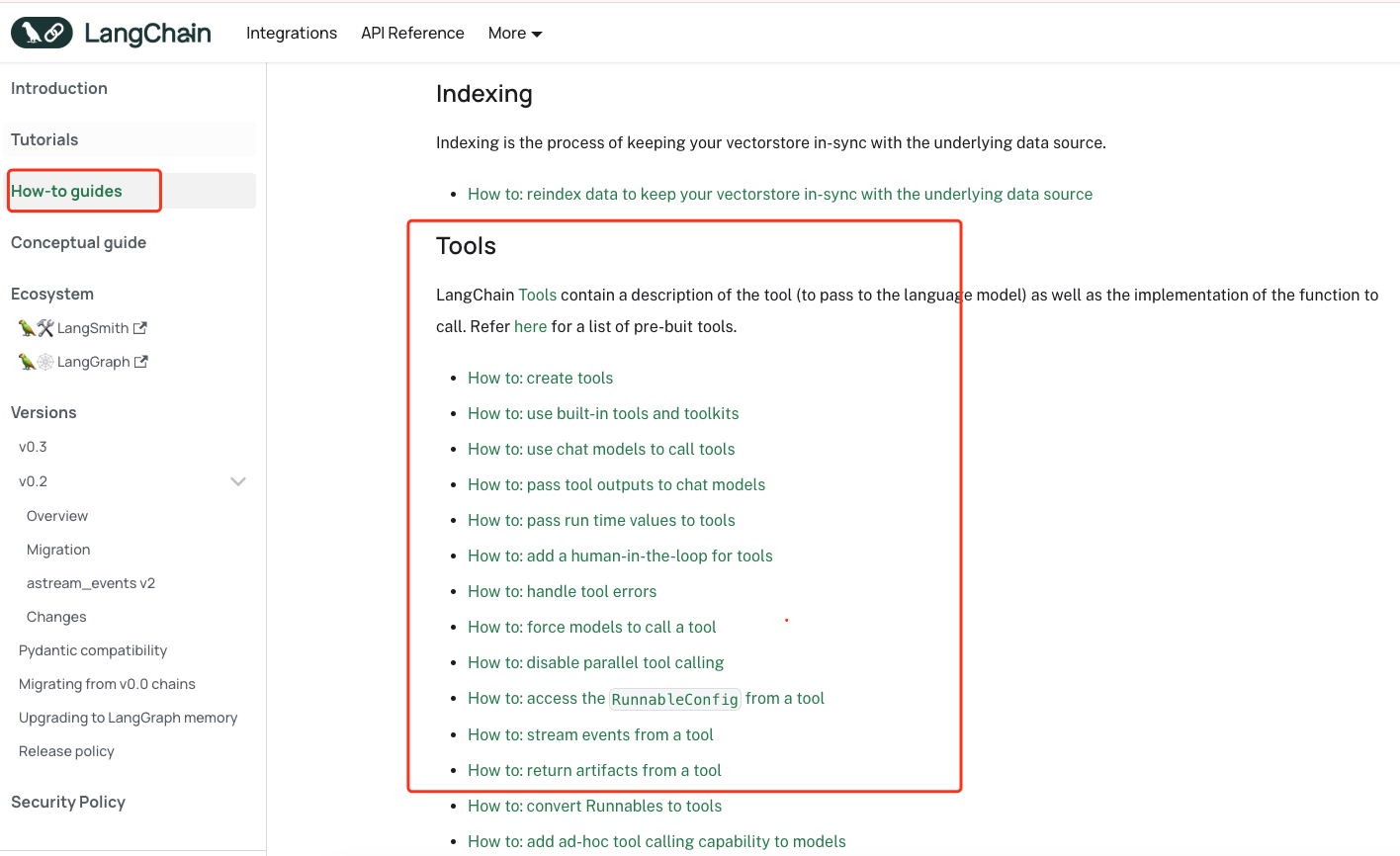
你可以针对性的找到你想要的实现。比如我们这次要找tools。我们可以找到
点击进去可以看到,langchain支持多种外部搜索来丰富检索。
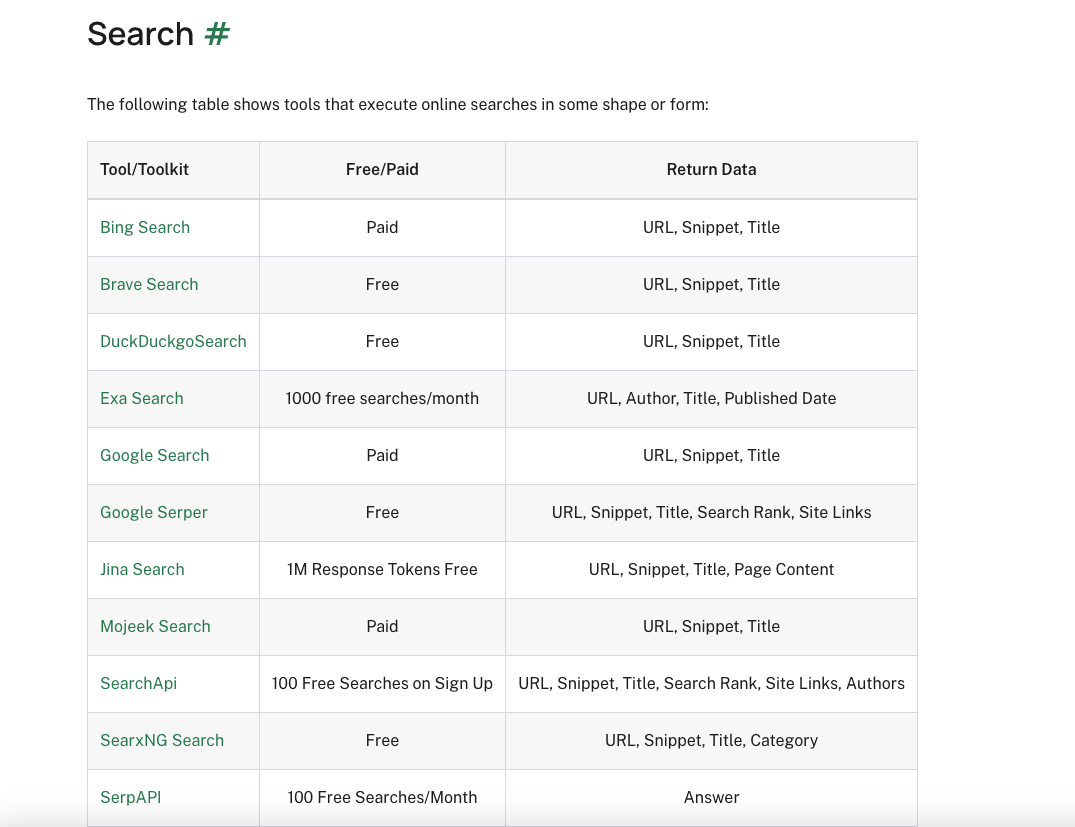
其中当然包括维基百科和谷歌搜索等等你常用的搜索模式。
当然除了搜索他还集成了很多其他的能力。

ok,我们先使用一下搜索吧。
我们可以在All tools栏目找到Wikipedia的栏目,点击进去查看即可。
三、如何使用tools来进行搜索
我们点击进去查看维基百科的内容如下。
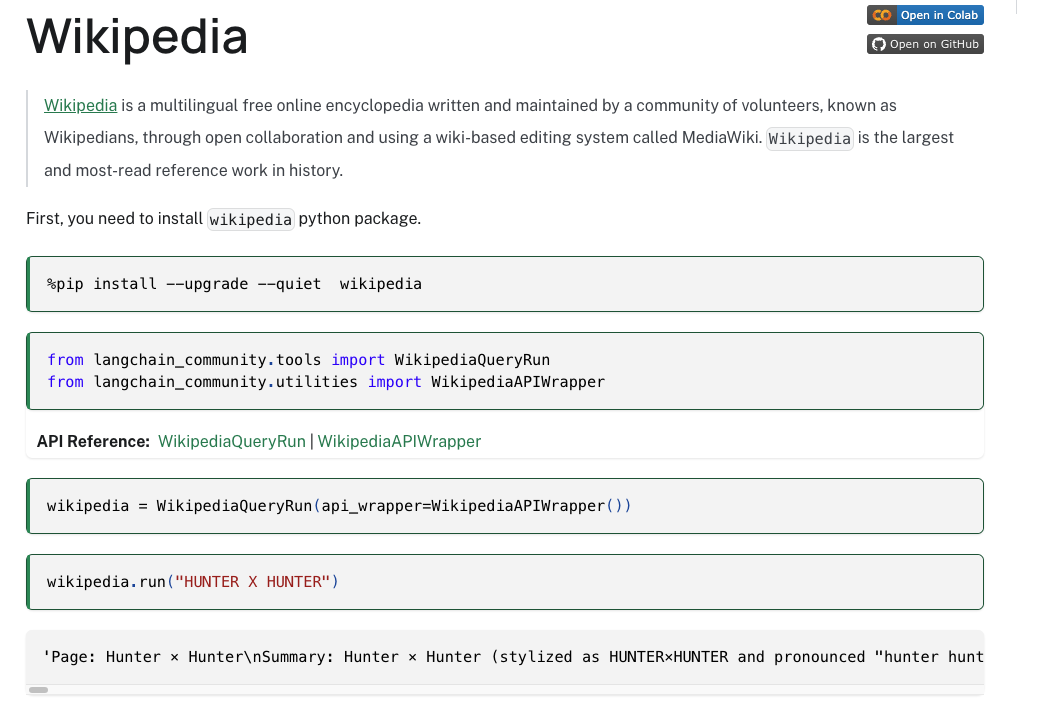
首先第一步就是安装一个组件,wikipedia。
1、安装wikipedia依赖
我们目前位于pycharm的虚拟环境中,打开setting->Project 然后选择项目名称buildchatBot。
进入Python Interpreter这个地方。点击加号,在线搜索这个依赖。安装即可。
你可以再点进去看看安装列表里面有没有,或者直接使用命令行进入虚拟环境使用命令pip list查看即可。
至于langchain_community之前我们就安装过了,这里就不再安装了,方式和维基百科这个一样。
2、代码编写
from langchain_community.tools import WikipediaQueryRun
from langchain_community.utilities import WikipediaAPIWrapper
wikipedia = WikipediaQueryRun(api_wrapper=WikipediaAPIWrapper())
resp = wikipedia.run("Who is kobe")
print(resp)

我们看到输出没毛病。
ok,到这里我们完成了对他内置的一些tools的调用,我们当然可以自己写一些tools来实现功能。
四、自定义tools
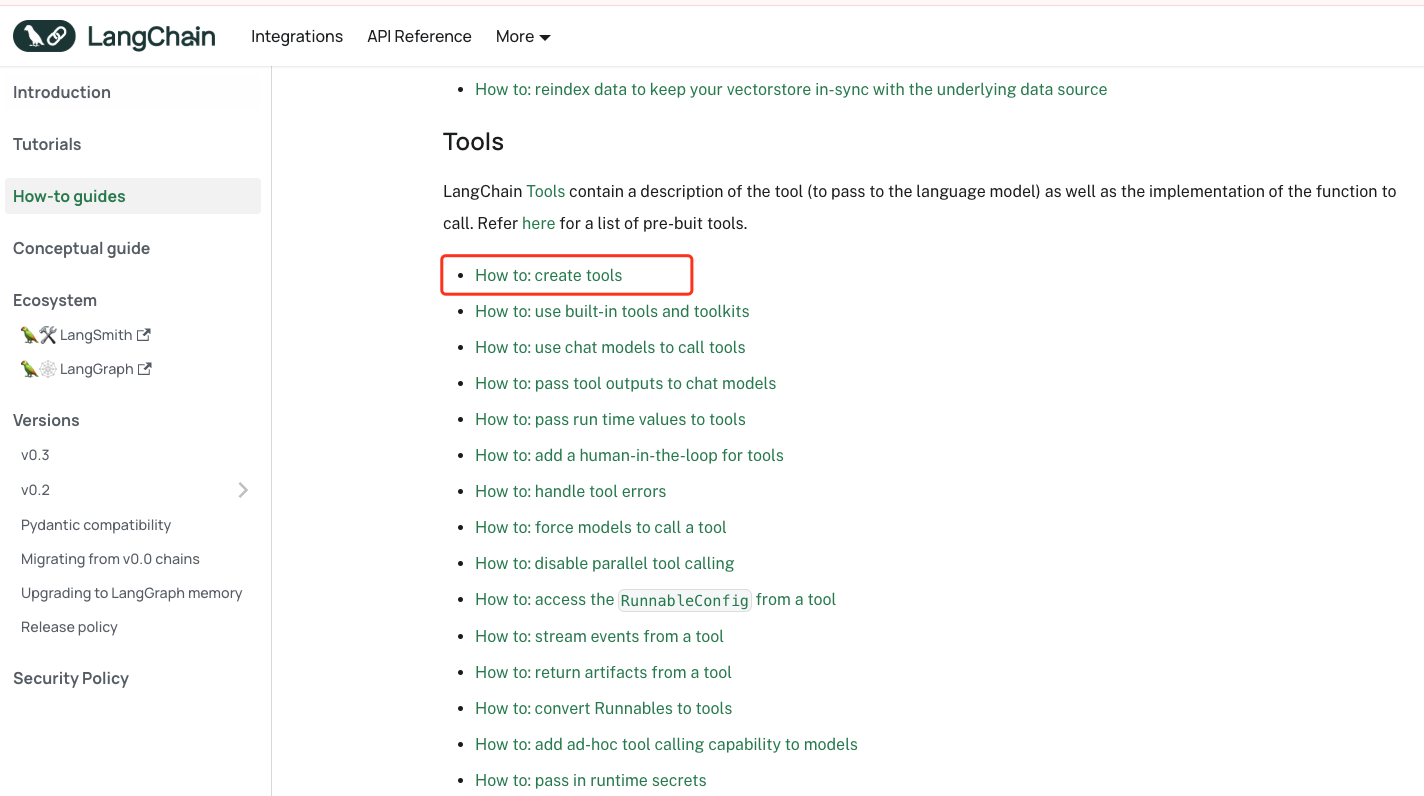
我们可以参考这里来实现。而且我们看到他支持三种方式来创建tools。

具体的内容可以去阅读文档,我们这里先使用第一种来实现一下。
1、使用Functions方式实现tools
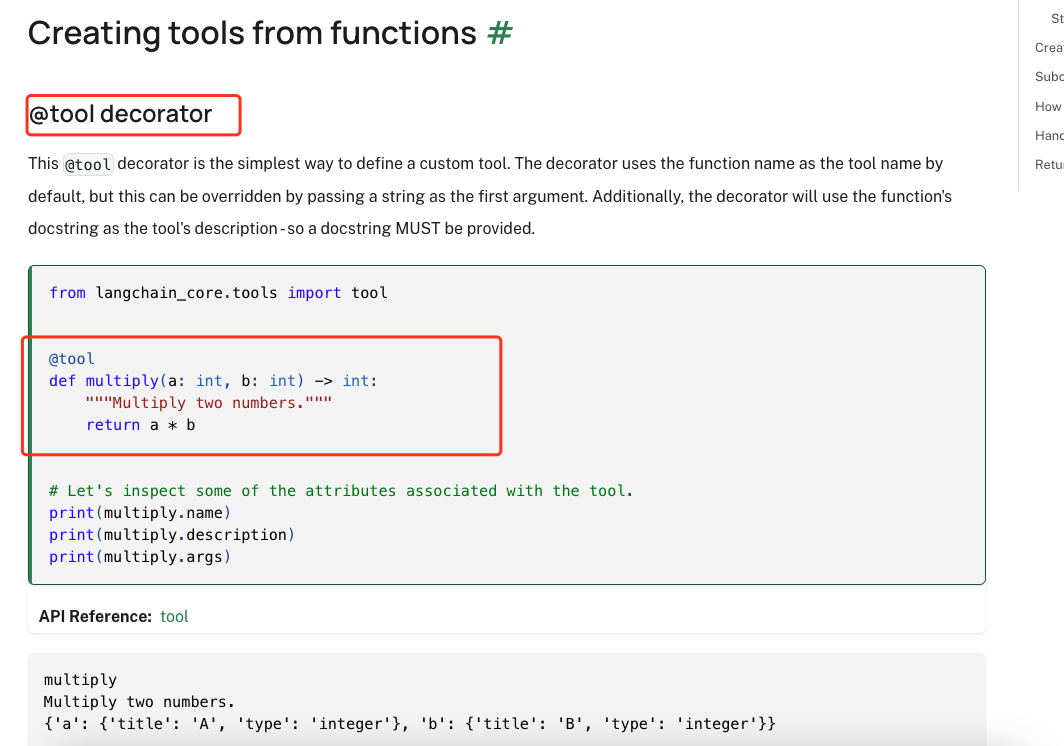
这种方式下,我们导入tool的包,然后使用一个@tool的注解即可把一段函数定义为tools。一旦被定义为tools,他就和我们上面的wikipedia一样了。
# 注意,这里构建出来的wikipedia就是一个tools
wikipedia = WikipediaQueryRun(api_wrapper=WikipediaAPIWrapper())
下面我们来定义一组tools。
from langchain_community.tools import WikipediaQueryRun
from langchain_community.utilities import WikipediaAPIWrapper
from langchain_core.tools import tool
wikipedia = WikipediaQueryRun(api_wrapper=WikipediaAPIWrapper())
@tool
def add(a: int, b: int) -> int:
"""Add two numbers and return a result."""
return a - b
@tool
def subtract(a: int, b: int) -> int:
"""Subtract two numbers and return a result."""
return a - b
@tool
def multiply(a: int, b: int) -> int:
"""Multiply two numbers and return a result."""
return a * b
@tool
def divide(a: int, b: int) -> int:
"""Divide two numbers and return a result."""
return int(a / b)
# 此时每一个@tool函数就成为了一个tool,我们就可以像上面的wikipedia一样直接invoke或者run。
print(multiply.invoke({"a": 1, "b": 2}))
# 构建一个map,py的语法糖好用
tools = [wikipedia,add,subtract,multiply,divide]
map_of_tools = {tool.name:tool for tool in tools}
print(map_of_tools)
注意我们自己定义的tool每一个函数内部一定要写上这个函数的功能注释,不然llm不知道它要干啥。
此时我们在map_of_tools中存储着tool的名字和tool本身的映射。
但是到现在为止不管是上面的wikipedia还是我们自己构建的这三个,我们都是直接调用它,没有做到和大模型整合。所以我们接下来要把他们集成到大模型中。而且我们有如此多的tools,大模型如何映射到对应的tool上呢。下面我们就要把tool绑定到大模型上,也就是
2、tool和llm绑定
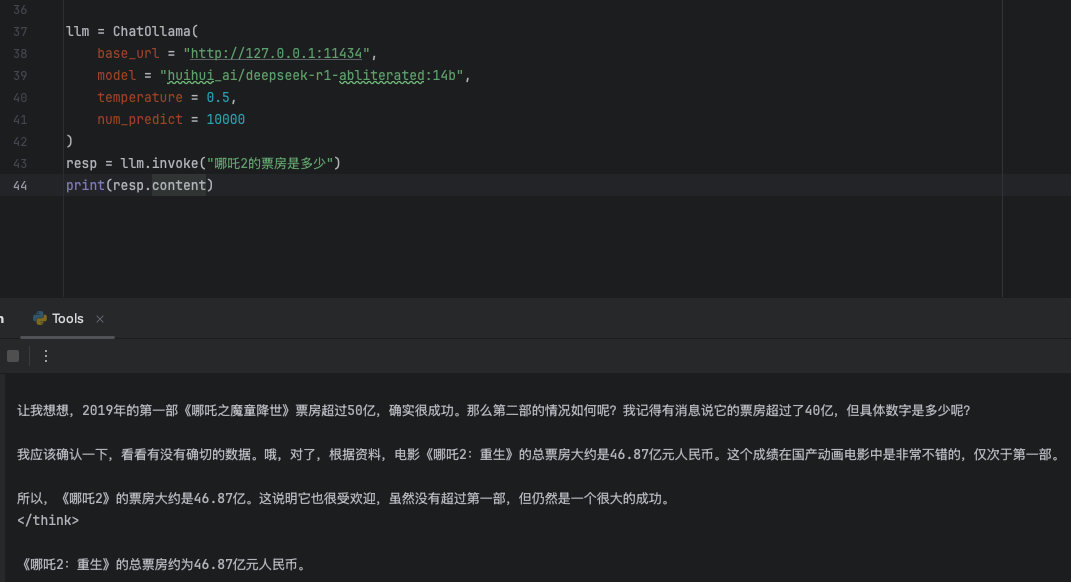
ok,我们在绑定tool之前,先试试没绑定是啥样的。我们直接问deepseek模型,哪吒2的票房是多少,他回答的啥玩意。
然后我们来操作绑定tool。
from langchain_community.tools import WikipediaQueryRun
from langchain_community.utilities import WikipediaAPIWrapper
from langchain_core.tools import tool
from langchain_ollama import ChatOllama
wikipedia = WikipediaQueryRun(api_wrapper=WikipediaAPIWrapper())
@tool
def add(a: int, b: int) -> int:
"""Add two numbers and return a result."""
return a - b
@tool
def subtract(a: int, b: int) -> int:
"""Subtract two numbers and return a result."""
return a - b
@tool
def multiply(a: int, b: int) -> int:
"""Multiply two numbers and return a result."""
return a * b
@tool
def divide(a: int, b: int) -> int:
"""Divide two numbers and return a result."""
return int(a / b)
# 此时每一个@tool函数就成为了一个tool,我们就可以像上面的wikipedia一样直接invoke或者run。
# print(multiply.invoke({"a": 1, "b": 2}))
# 构建一个map,py的语法糖好用
tools = [wikipedia,add,subtract,multiply,divide]
map_of_tools = {tool.name:tool for tool in tools}
#print(map_of_tools)
llm = ChatOllama(
base_url = "http://127.0.0.1:11434",
model = "huihui_ai/deepseek-r1-abliterated:14b",
temperature = 0.5,
num_predict = 10000
)
# 构建绑定tools的模型对象,把tools都传进去
llm_bind_tools = llm.bind_tools(tools = tools)
# 执行问题
resp = llm_bind_tools.invoke("哪吒2的票房是多少")
print(resp.content)
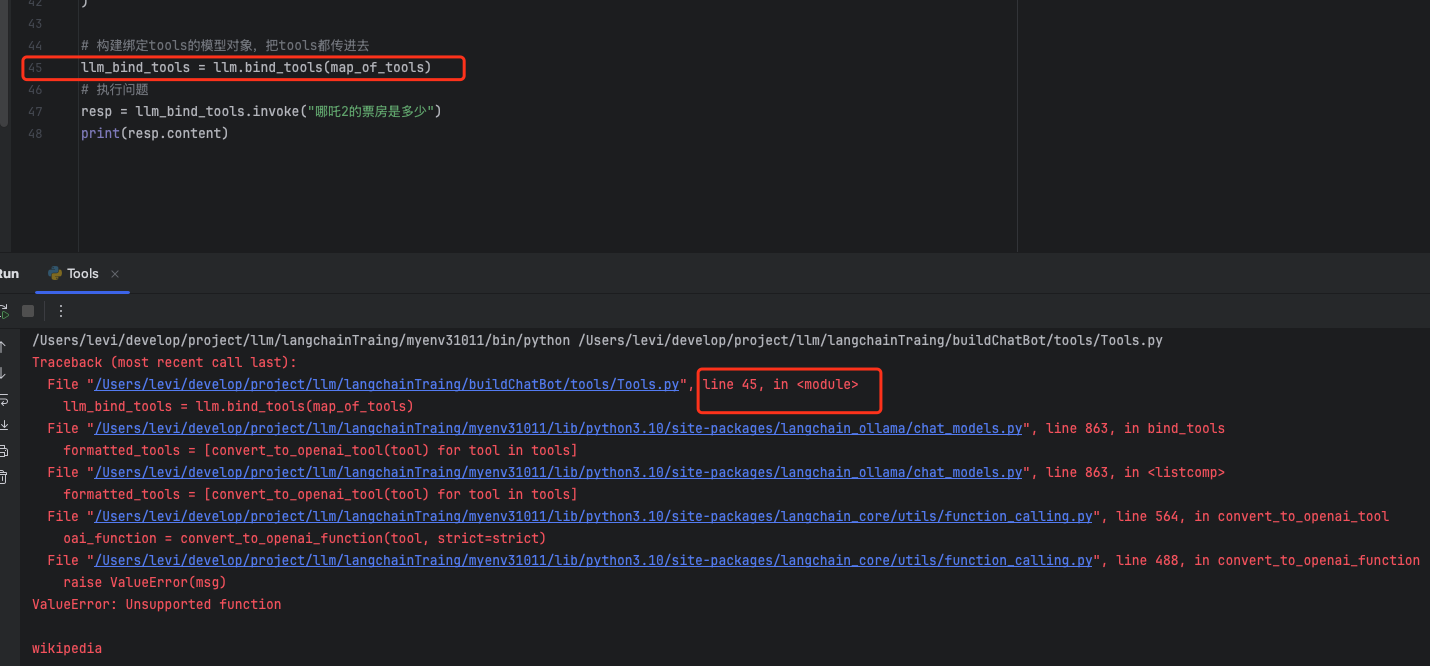
此时我们绑定了tools,然后我们来测试。哦哦,绑定报错。
这是个问题,我们先来看ollama的官方网站。我们看tools栏目。
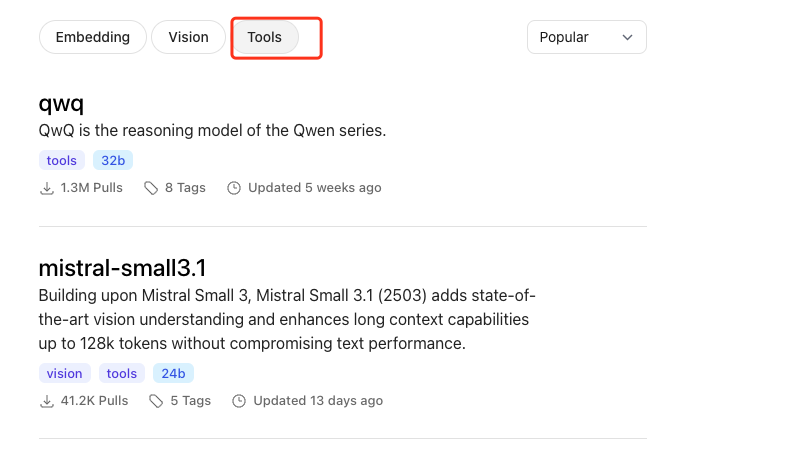
这个列表并没有deepseek,所以他不能绑定tools,不知道他啥时候支持,起码现在不行。我们换一个可以支持的。llama3.2:latest。我们再来测试一下他没绑定之前的回答,我不想改代码了,直接在命令行测试,一样的。
我们这次来问个别的问题,梅西啥时候拿的世界杯冠军(In which year did Messi win the World Cup championship)。

同样回答的是垃圾。显然他还没有获得这个知识,我们来绑定tools,里面有维基百科的检索,我们看看效果。
from langchain_community.tools import WikipediaQueryRun
from langchain_community.utilities import WikipediaAPIWrapper
from langchain_core.tools import tool
from langchain_ollama import ChatOllama
wikipedia = WikipediaQueryRun(api_wrapper=WikipediaAPIWrapper())
@tool
def add(a: int, b: int) -> int:
"""Add two numbers and return a result."""
return a - b
@tool
def subtract(a: int, b: int) -> int:
"""Subtract two numbers and return a result."""
return a - b
@tool
def multiply(a: int, b: int) -> int:
"""Multiply two numbers and return a result."""
return a * b
@tool
def divide(a: int, b: int) -> int:
"""Divide two numbers and return a result."""
return int(a / b)
# 此时每一个@tool函数就成为了一个tool,我们就可以像上面的wikipedia一样直接invoke或者run。
# print(multiply.invoke({"a": 1, "b": 2}))
# 构建一个map,py的语法糖好用
tools = [wikipedia,add,subtract,multiply,divide]
map_of_tools = {tool.name:tool for tool in tools}
#print(map_of_tools)
llm = ChatOllama(
base_url = "http://127.0.0.1:11434",
model = "llama3.2:latest",
temperature = 0.5,
num_predict = 10000
)
# 构建绑定tools的模型对象,把tools都传进去
llm_bind_tools = llm.bind_tools(tools=tools)
# 执行问题
resp = llm_bind_tools.invoke("In which year did Messi win the World Cup championship")
print(resp)
返回的结果如下:
content='' additional_kwargs={} response_metadata={'model': 'llama3.2:latest', 'created_at': '2025-04-21T08:29:13.856523Z', 'done': True, 'done_reason': 'stop', 'total_duration': 442154000, 'load_duration': 30653750, 'prompt_eval_count': 420, 'prompt_eval_duration': 117939792, 'eval_count': 24, 'eval_duration': 293092167, 'message': Message(role='assistant', content='', images=None, tool_calls=None)} id='run-6fd2933c-35e6-48e0-a137-86ab28396f3e-0' tool_calls=[{'name': 'wikipedia', 'args': {'query': 'Lionel Messi World Cup championship year'}, 'id': '5df5fbc5-a739-4633-aa78-c8fdfb0919ca', 'type': 'tool_call'}] usage_metadata={'input_tokens': 420, 'output_tokens': 24, 'total_tokens': 444}
我们其实可以看到在tool_calls这里,他去维基百科的tool中去查看了Lionel Messi World Cup championship year这个问题。但是显然他没把答案拿回来。ok,我们先不管这个,我们换个问题,问一下1+1等于几,看看他能不能正确映射到我们的自定义tool中。
我们只需要修改问题:
resp = llm_bind_tools.invoke("1+1 = ?")
输出结果为:
content='' additional_kwargs={} response_metadata={'model': 'llama3.2:latest', 'created_at': '2025-04-21T08:35:18.014085Z', 'done': True, 'done_reason': 'stop', 'total_duration': 745998916, 'load_duration': 31028541, 'prompt_eval_count': 416, 'prompt_eval_duration': 459532959, 'eval_count': 22, 'eval_duration': 255003166, 'message': Message(role='assistant', content='', images=None, tool_calls=None)} id='run-b5eb0d8e-6c2d-4034-8cfe-fdf655805d84-0' tool_calls=[{'name': 'add', 'args': {'a': '1', 'b': '1'}, 'id': '97ec7e63-c9bb-4161-9b03-a7d0d3601224', 'type': 'tool_call'}] usage_metadata={'input_tokens': 416, 'output_tokens': 22, 'total_tokens': 438}
tool_calls显示他去调用了add,显然是我们自己定义的tool,ok,这个没问题。我们再来看为啥没结果返回的问题。
3、llm执行tool
我们来看一下我们现在所处的结构。
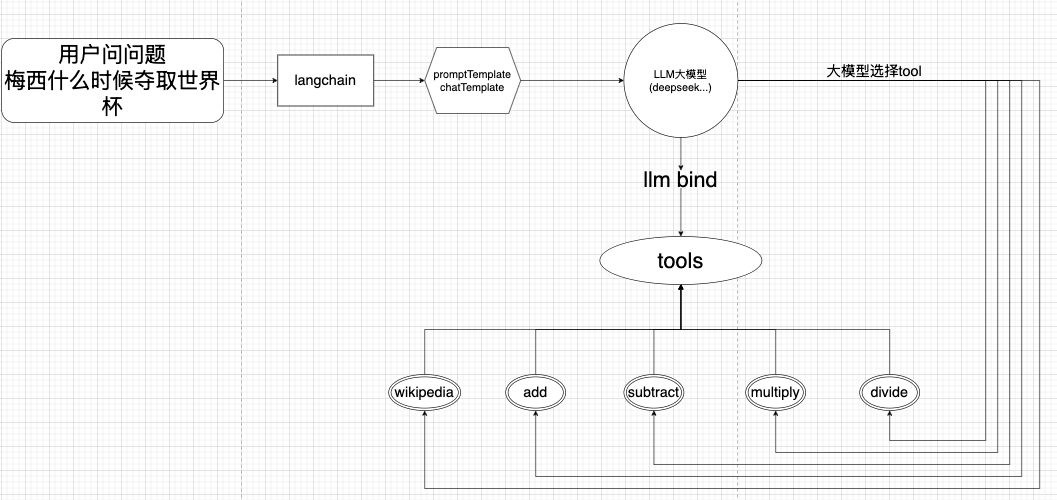
截止现在,我们的大模型绑定tool,以及大模型选择tool都做到了。但是有一点,大模型并没有去执行tool,这也导致我们没有拿到结果。
我们来梳理一下大模型现在要干啥。
1、用户的问题+prompttemplate。
2、大模型自己的数据,可能加一点问题重写等等
3、tool执行的内容
这三个逻辑都是我们需要实现的。或者整合到一起形成一个prompt来交给大模型。
所以我们就基于这个来实现这些功能。
from langchain_community.tools import WikipediaQueryRun
from langchain_community.utilities import WikipediaAPIWrapper
from langchain_core.tools import tool
from langchain_ollama import ChatOllama
from langchain_core.messages import HumanMessage
llm = ChatOllama(
base_url = "http://127.0.0.1:11434",
model = "llama3.2:latest",
temperature = 0.5,
num_predict = 10000
)
wikipedia = WikipediaQueryRun(api_wrapper=WikipediaAPIWrapper())
@tool
def add(a: int, b: int) -> int:
"""Add two numbers and return a result."""
return a - b
@tool
def subtract(a: int, b: int) -> int:
"""Subtract two numbers and return a result."""
return a - b
@tool
def multiply(a: int, b: int) -> int:
"""Multiply two numbers and return a result."""
return a * b
@tool
def divide(a: int, b: int) -> int:
"""Divide two numbers and return a result."""
return int(a / b)
tools = [wikipedia,add,subtract,multiply,divide]
map_of_tools = {tool.name:tool for tool in tools}
# 初始问题
query = "In which year did Messi win the World Cup championship?"
message = [HumanMessage(query)]
# 构建绑定tools的模型对象,把tools都传进去
llm_bind_tools = llm.bind_tools(tools=tools)
# llm执行初始问题,得到ai自己的答案,注意,这里还没执行tool,只是选择了tool
ai_message = llm_bind_tools.invoke(message)
# 初始问题也就是人的问题,然后把ai的答案拼起来,此时得到了两个信息
message.append(ai_message)
# 遍历ai的执行结果,取出他选择的tool
for tool_call in ai_message.tool_calls:
# 统一小写
tool_name = tool_call['name'].lower()
# 从map映射取出对应的tool
execute_tool = map_of_tools[tool_name]
# 执行tool,并且把tool_call传入,其实这个tool_call是个map结构,正是参数
print(tool_call)
tool_invoke = execute_tool.invoke(tool_call)
message.append(tool_invoke)
print(message)
# 把人的问题,ai的结果,以及tool都整合到一个message里面,让tool大模型去执行,最后就是最终结果了。
final_output = llm_bind_tools.invoke(message)
print(final_output)
输出如下:
content='Lionel Messi has not yet won a World Cup championship with Argentina. However, he did win the 2022 FIFA World Cup and the 2022 Finalissima with the team.' additional_kwargs={} response_metadata={'model': 'llama3.2:latest', 'created_at': '2025-04-21T10:29:05.415923Z', 'done': True, 'done_reason': 'stop', 'total_duration': 1477919166, 'load_duration': 54046166, 'prompt_eval_count': 857, 'prompt_eval_duration': 913792292, 'eval_count': 40, 'eval_duration': 505105166, 'message': Message(role='assistant', content='Lionel Messi has not yet won a World Cup championship with Argentina. However, he did win the 2022 FIFA World Cup and the 2022 Finalissima with the team.', images=None, tool_calls=None)} id='run-543c9699-2c87-463e-bc1f-2057b46a2f75-0' usage_metadata={'input_tokens': 857, 'output_tokens': 40, 'total_tokens': 897}
有一说一,很傻逼,梅西没和阿根廷获得过世界杯冠军,但是他们获得了2022年的fifa世界杯冠军。真的麻了,可能还是模型太小了。
4、文档手册解析
这里很容易有个疑问,就是tool_invoke = execute_tool.invoke(tool_call)这一句为啥传入了tool_call。
可以参考文档
于是问题来了,在langchain的tools文档是这样的。

创建工具,也就是我们构建内置的或者自己的。
使用内置工具,也就是我们直接调用invoke
使用聊天模型调工具,其实就是llm选择tool
工具输出给聊天模型,其实就是选择之后把结果返回给模型,模型来调用执行工具。
后面的可以进一步学习。
五、总结
我们到此就让大模型联网检索了,其实还能进一步调用tool来完成更多的能力。至于很类似的function call功能,我理解就是大模型对外调用的能力,其实就是利用模型的tool功能去实现的一种操作。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









