







平常我们需要很多的高清无损图片,但是手动下载工作量太大,这时候python就发挥了很大的作用了,我们需要构思一下写代码的流程,首先确定是在那个网站是上爬取图片,然后根据代码的规范,去获取网页的相关信息,最后就是编码了,具体的教程已经放到下面了,可自行复制,别忘了点个关注,会持续更新技术!!!
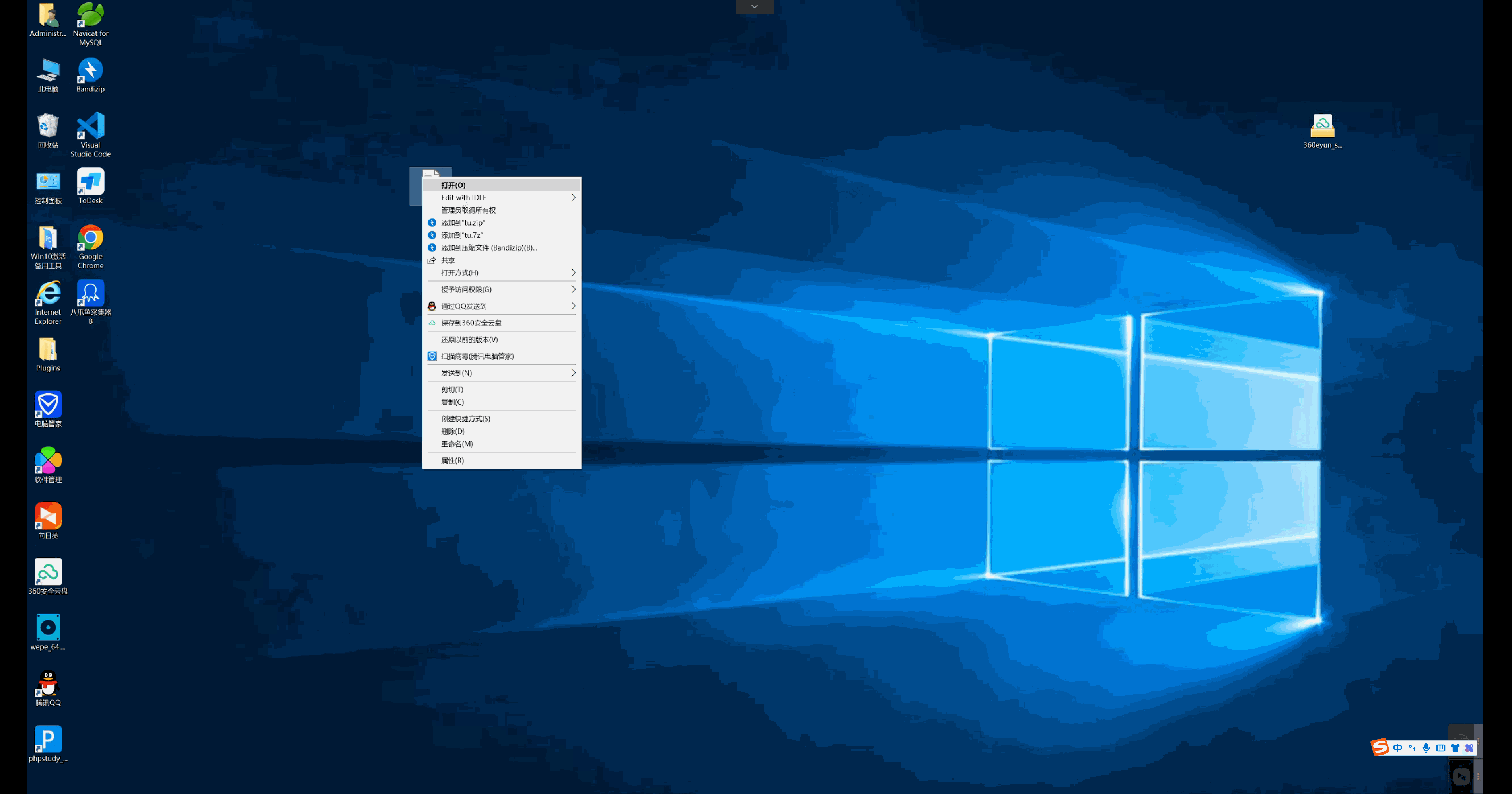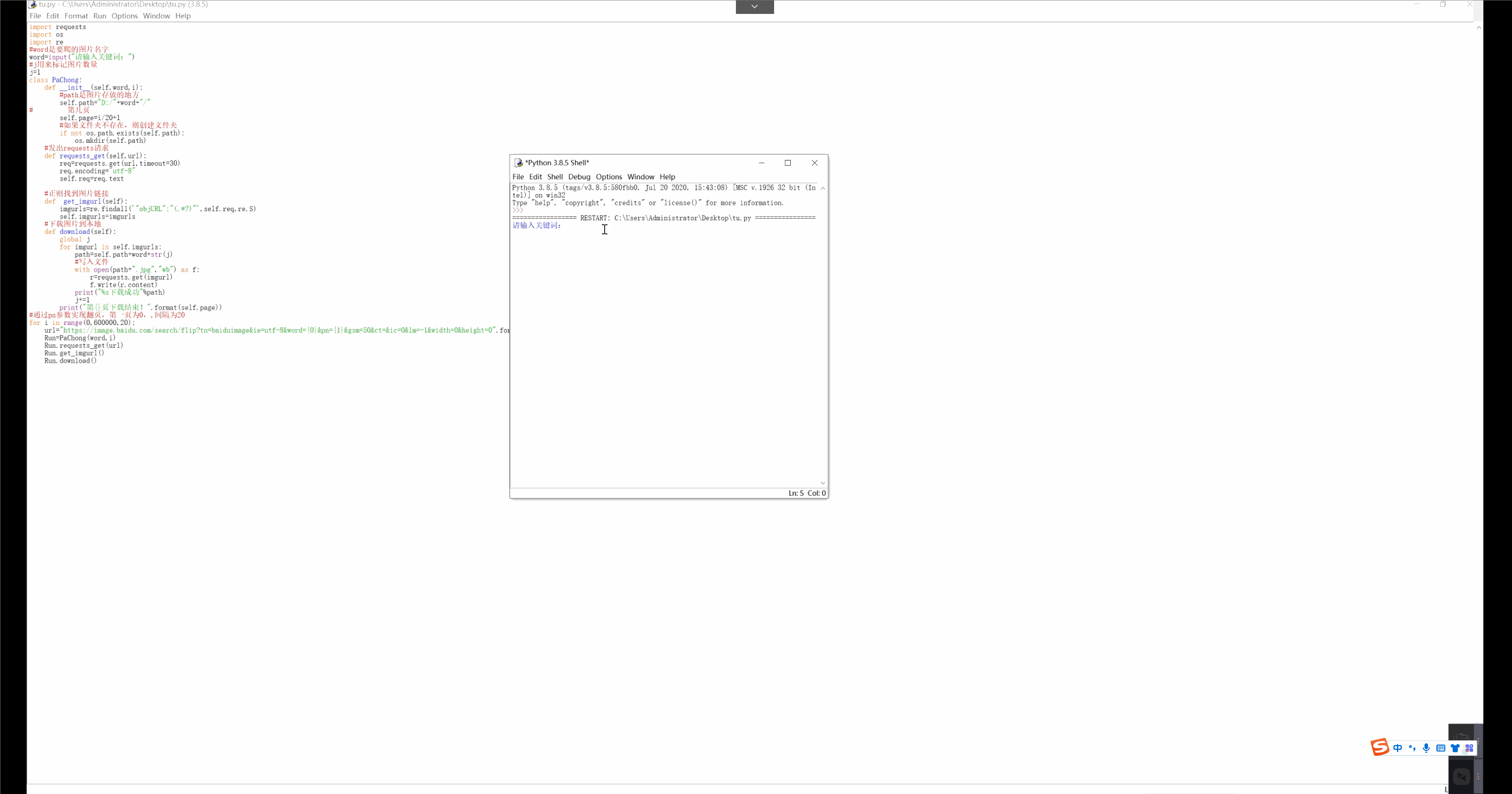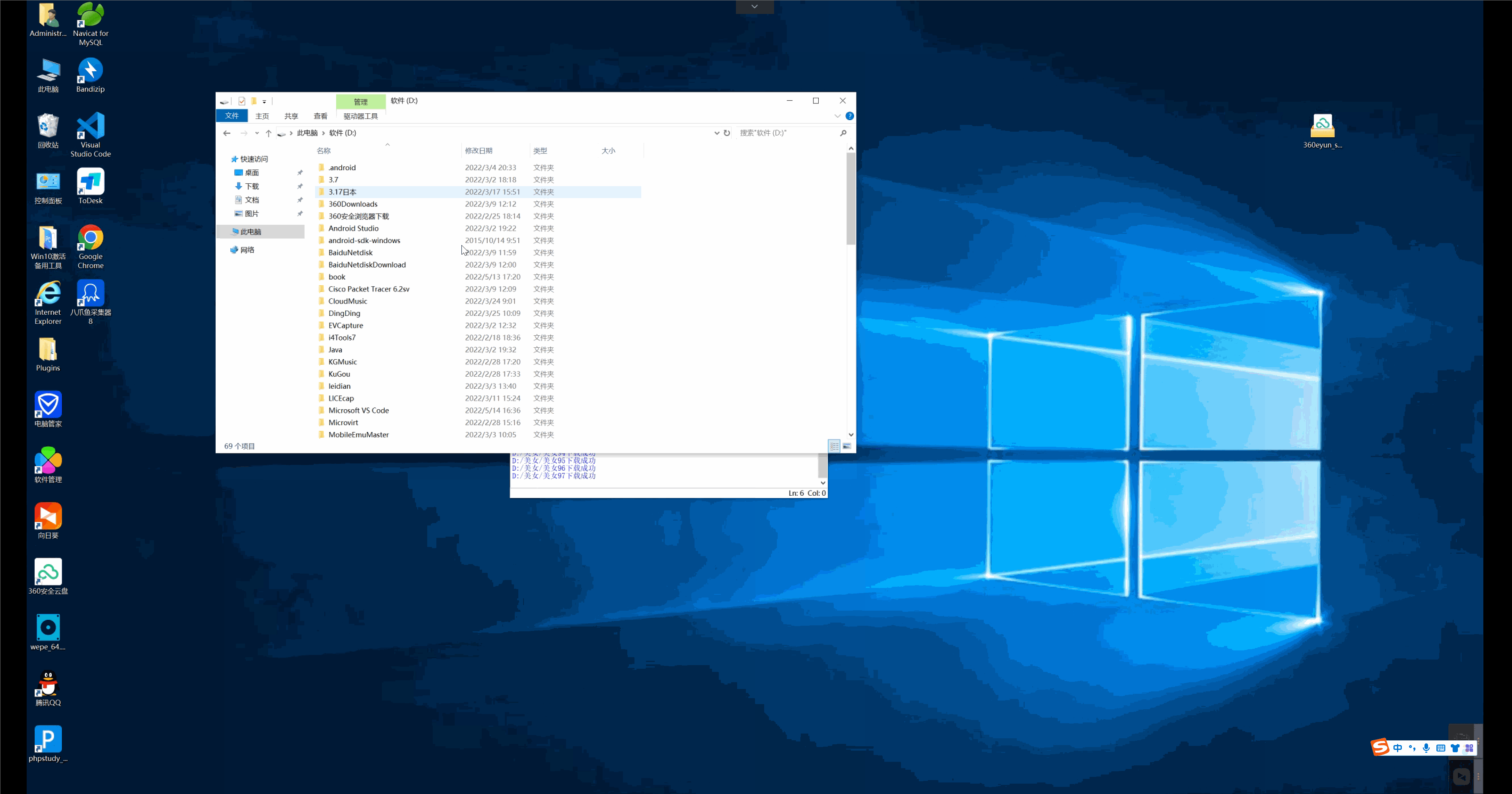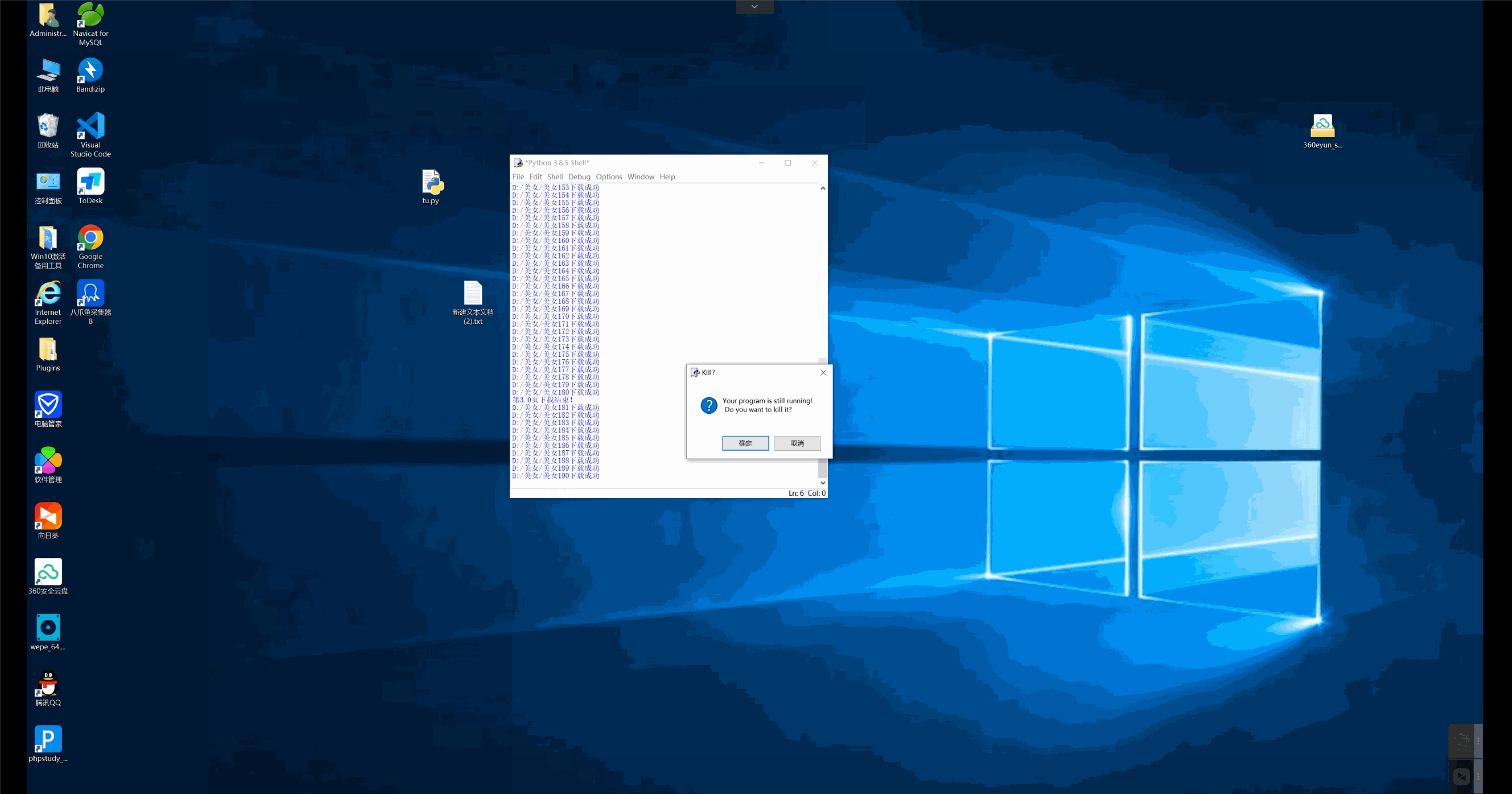
import requests
import os
import re
#word是要爬的图片名字
word=input("请输入关键词:")
#j用来标记图片数量
j=1
class PaChong:
def __init__(self,word,i):
#path是图片存放的地方
self.path="D:/"+word+"/"
# 第几页
self.page=i/20+1
#如果文件夹不存在,则创建文件夹
if not os.path.exists(self.path):
os.mkdir(self.path)
#发出requests请求
def requests_get(self,url):
req=requests.get(url,timeout=30)
req.encoding="utf-8"
self.req=req.text
#正则找到图片链接
def get_imgurl(self):
imgurls=re.findall('"objURL":"(.*?)"',self.req,re.S)
self.imgurls=imgurls
#下载图片到本地
def download(self):
global j
for imgurl in self.imgurls:
path=self.path+word+str(j)
#写入文件
with open(path+".jpg","wb") as f:
r=requests.get(imgurl)
f.write(r.content)
print("%s下载成功"%path)
j+=1
print("第{}页下载结束!".format(self.page))
#通过pn参数实现翻页,第一页为0,,间隔为20
for i in range(0,600000,20):
url="https://image.baidu.com/search/flip?tn=baiduimage&ie=utf-8&word={0}&pn={1}&gsm=50&ct=&ic=0&lm=-1&width=0&height=0".format(word,i)
Run=PaChong(word,i)
Run.requests_get(url)
Run.get_imgurl()
Run.download()

















 742
742











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











