










Mapreduce 教程
--大数据基本功
一.mapreduce概念
mapreduce定义:是hadoop的处理层,将整个任务拆分成各个独立的子任务并行处理的大规模数据编程模型。整个任务被用户提交到master主节点上然后被拆分成子任务并分配给各个从节点。mapreduce编程模型是函数式构造的类型风格。
1.1了解mapreduce
了解hadoop的mapreduce从以下几个问题入手,hadoop看起来像什么,what,why and mapreduce 怎样工作?
Map-Reduce将处理的任务分为几个小部分,每个部分都可以在服务器群集上并行完成。 一个问题被分为许多较小的问题,每个问题都经过处理以提供单独的输出。 这些单独的输出将被进一步处理以提供最终输出。Hadoop Map-Reduce具有可伸缩性,还可以在许多计算机上使用。许多小型机器可用于处理大型机器无法处理的作业。
MapReduce Job或“完整程序”是跨数据集执行Mapper和Reducer的过程。 它是2个处理层(即mapper和reducer)的执行。MapReduce作业是客户端要执行的工作。 它由输入数据,MapReduce程序和配置信息组成。
什么是Map Reduce中的任务?
MapReduce中的任务是在数据切片上执行Mapper或Reducer。
什么是任务尝试?
任务尝试是尝试在节点上执行任务的特定实例。 任何时候任何机器都有可能崩溃。 例如,在处理数据(如果任何节点出现故障)的同时,框架会将任务重新安排到其他某个节点。 任务的重新安排不能是无限的。 也有一个上限。 任务尝试的默认值为4。如果任务(映射程序或化简器)失败4次,则该作业被视为失败的作业。 对于高优先级工作或繁重的工作,此任务尝试的价值也可以增加。
1.2 mapper抽象
介绍MapReduce中Map的抽象形式,MapReduce范式的第一阶段,什么是mapper,mapper的输入是什么,mapper如何处理数据,mapper的输出是什么?
mapper将键/值对作为输入。 无论数据是结构化还是非结构化格式,框架都会将传入的数据转换为键和值。
- 键是对输入值的引用。Key is a reference to the input value.
- 值是要操作的数据集 Value is the data set on which to operate.
Map处理过程:
1.用户定义的功能-用户可以根据需要编写自定义业务逻辑来处理数据。
2.适用于值输入中的每个值。Applies to every value in value input.
Map会生成一个新的键/值对列表:
1.Map的输出称为中间输出。
2.可以是与输入对不同的类型。
3.映射的输出存储在本地磁盘上,从那里对其进行shuffle到rdeuce节点数。
1.3 reducer抽象
在MapReduce中 MapReduce的第二阶段– Reducer,reducer的输入是什么,reducer的工作是什么,reduceer在哪里写输出?
reduce处理中间过程的key/value对作为输入和处理mapper过程的输出。在reduce 阶段通常是做聚合和求和排序计算 (aggregation or summation sort)
1.通过map生成的输出作为输入给到reduce
2.Key/value对提供给reduce通过key来排序
Input given to reducer is generated by Map (intermediate output)
Key / Value pairs provided to reduce are sorted by key
Reduce处理过程:
用户定义的功能–用户还可以在此处编写自定义业务逻辑并获得最终输出。
迭代器将给定键的值提供给Reduce函数。
Reduce最后输出一系列key/value对
- 输出是最后结果输出
- 可能和输入对不同
- 输出存储在hdfs上
1.4 map和reduce 是怎样协同工作
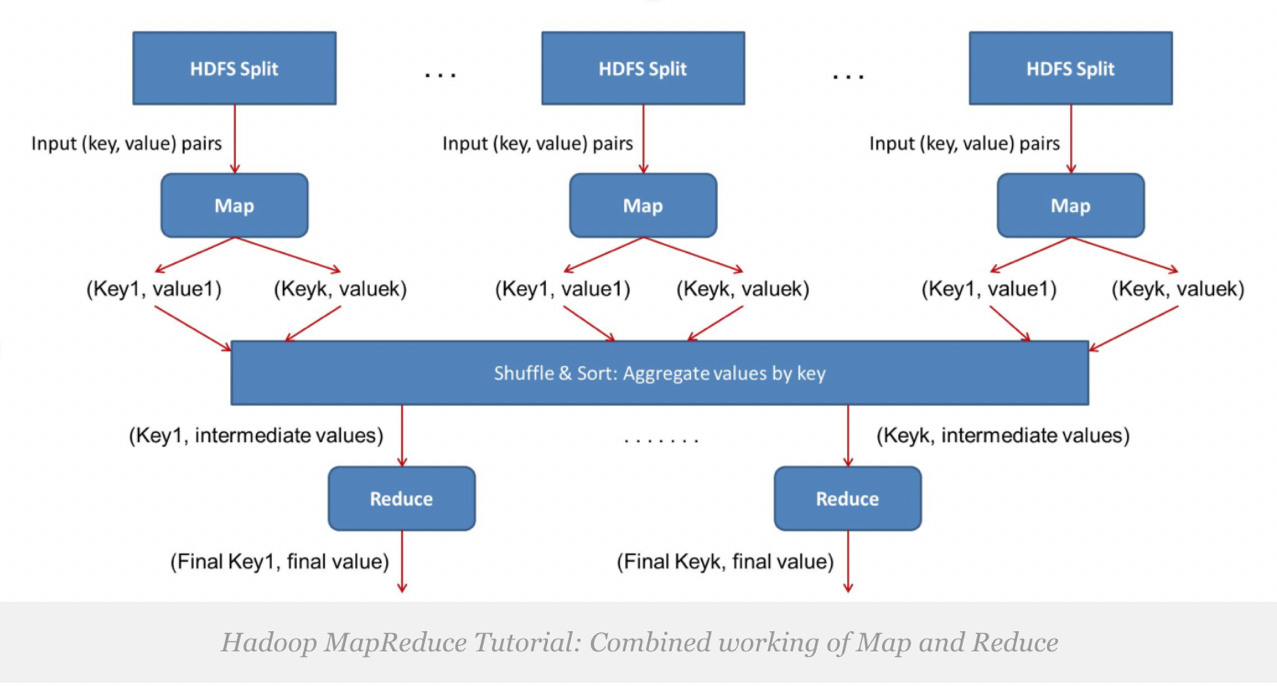
给mapper的输入数据是在mapper端通过用户自定义函数进行处理。
所有必需的复杂业务逻辑都是在mapper端实现的,由于映射器的数量远远多于缩减器的数量,因此mapper端并行大量的处理任务。 mapper生成一个输出,该输出是中间数据,并且该输出作为输入到reducer。
然后,该中间结果由编写在reducer上的用户定义函数进行处理,并生成最终输出。 通常,在reducer中进行非常轻的处理。 最终输出存储复制在HDFS中。
Mapreduce Dataflow
Hadoop mareduce 是怎样完成端到端的的data flow :数据怎样从mapper 输入,mapper 怎样处理数据,mapper在哪里写入数据,数据是如何shuffle从mapper到reducer的各个节点,reduce在哪里运行,什么类型的流程才能在reducer处理。
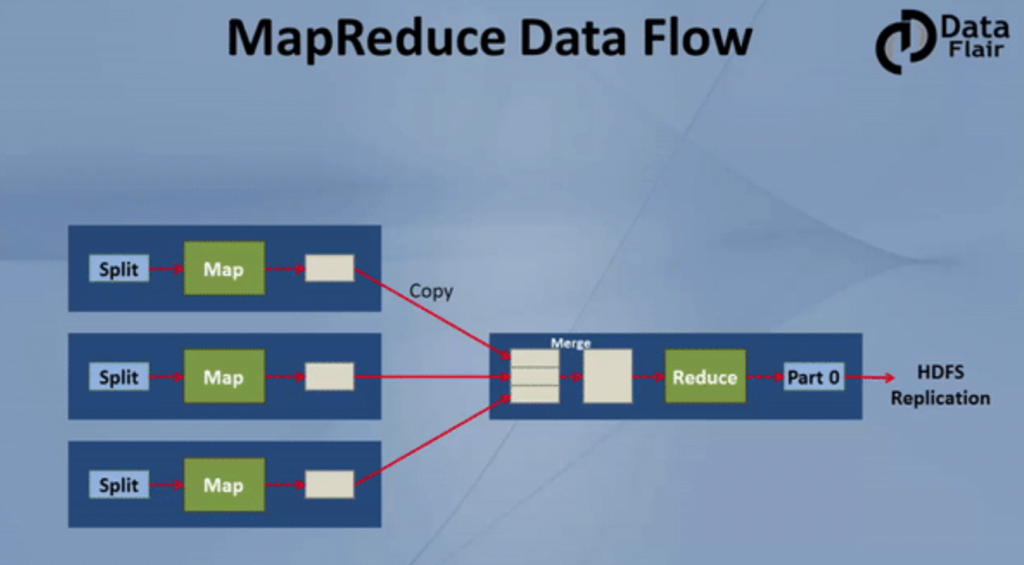
Hadoop MapReduce Tutorial: Hadoop MapReduce Dataflow Process
上图有三个slaves从mapper的节点,和一个reducer从节点,为了简化过程把reducer放在不同的机器上,但是实际上运行在仅仅在mapper节点上运行。
Map的过程:
一个mapper在一个时间段内是输入一个block,默认拆分。Mapper的输出是写入到mapper正在运行的本地磁盘中,map阶段结束后中间结果流转到reducers 节点。
Reducer 是第二个阶段的过程,用户可以自定义业务逻辑,reduce的output是写入到hdfs上。
默认情况下,在slaves节点上,一次运行2个mapper,也可以根据要求增加它们。 它再次取决于各种因素数据节点硬件,块大小,机器配置等因素。不应将映射器的数量增加到超过特定限制的范围,因为这会降低性能。
在hadoop 的Mapper阶段,会输出结果到其正在运行机器的磁盘上,相当于临时数据。所有mapper 的输出都是临时输出数据。每一个mapper 的输出结果都会输出到磁盘上,当第一个mapper 任务完成把数据流转到reducer.this movement of output from mapper node to reducer node is called shuffle.
Reducer也仅部署在任何一个数据节点上。来自所有mapper的输出将进入reduce。 不同mapper的所有输出被合并以形成reduce的输入。可以自定义逻辑处理,是处理的第二阶段,通常是聚合和求和操作。Reducer的输出在hdfs上。
Map和reduce处理阶段是一个先后顺序过程,mapper 完成之后,reducer开始启动。
尽管默认情况下3个不同位置存在1个块,但是框架仅允许1个mapper处理1个块。 因此,只有1个mapper将处理3个副本中的1个特定块。 每个mapper的输出都将发送到群集中的每个reducer,即每个reducer都从所有mapper接收输入。 因此,框架指示reducer映射器已经处理了整个数据,现在reducer可以处理数据了。
Mapper的输出数据都会被分区器过滤和分区。
1.5 mapreduce中的局部数据
“Move computation close to the data rather than data to computation”. 将计算移到数据附近,而不是数据移到计算中。 如果应用程序所请求的计算在其所操作的数据附近执行,则效率会高得多。 当数据量非常大时尤其如此。 这样可以最大程度地减少网络拥塞并增加系统的吞吐量。 假设通常是将计算移动到更靠近数据的位置,而不是将数据移动到应用程序正在运行的位置。 因此,HDFS为应用程序提供了接口,以使它们自己更靠近数据所在的位置。
由于Hadoop处理大量数据,因此无法通过网络移动此类数据。 因此,它提出了将算法移至数据而非将数据移至算法的最具创新性的原理。 这称为数据局部性data locality.
链接:
https://data-flair.training/blogs/hadoop-mapreduce-tutorial/















 2340
2340











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









